【机器学习sklearn】支持向量机SVM
支持向量机SVM
- 一、SVM是什么?
- 二、算法原理
-
- 1.超平面
- 2.几何间隔
- 3.支持向量机
- 4.对偶问题
- 三、软间隔与支持向量回归
-
- 1. 软间隔
- 2. 支持向量回归(Support Vector Regression,SVR)
- 四、核函数(kernel function)
- 实例
一、SVM是什么?
支持向量机(Support Vector Machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
二、算法原理
SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。
1.超平面
在样本空间中,划分超平面线性方程为: w T x + b = 0 w^Tx+b=0 wTx+b=0。
其中, w = ( w 1 , w 2 , . . . , w d ) w=(w_1,w_2,...,w_d) w=(w1,w2,...,wd)为法向量,决定超平面方向; b b b为位移项,决定超平面与原点之间的距离。记为 ( w , b ) (w,b) (w,b)。
样本空间中任意点 x x x到超平面 ( w , b ) (w,b) (w,b)的距离为:
r = w T x i + b ∣ ∣ w ∣ ∣ r=\frac{w^Tx_i+b}{||w||} r=∣∣w∣∣wTxi+b
- 超平面方程不唯一
- 法向量 w w w和位移项 b b b确定一个唯一的超平面
- 法向量 w w w垂直于超平面
- 法向量 w w w指向的空间一半为正空间,一半为负空间
2.几何间隔
给定数据集 X X X和超平面 w T x + b = 0 w^Tx+b=0 wTx+b=0,定义数据集 X X X中的任意一个样本点 ( x i , y i ) , y i ∈ − 1 , 1 , i = 1 , 2 , . . . , m (x_i,y_i),y_i\in{-1,1},i=1,2,...,m (xi,yi),yi∈−1,1,i=1,2,...,m,关于超平面的几何间隔为:
r i = y i ( w T x + b ) ∣ ∣ w ∣ ∣ r_i=\frac{y_i(w^Tx+b)}{||w||} ri=∣∣w∣∣yi(wTx+b)
数据集 X X X中所有样本点的几何间隔最小值:
r i = m i n i = 1 , 2 , . . . , m r i r_i=\underset{i=1,2,...,m}{min}r_i ri=i=1,2,...,mminri
3.支持向量机
假设超平面 ( w , b ) (w,b) (w,b)将训练样本正确分类:
{ w T x i + b ≥ + 1 , y i = + 1 w T x i + b ≤ − 1 , y i = − 1 \begin{cases} w^Tx_i+b\geq+1, & \text {$y_i=+1$} \\ w^Tx_i+b\leq-1, & \text{$y_i=-1$} \end{cases} {wTxi+b≥+1,wTxi+b≤−1,yi=+1yi=−1
距离超平面最近的几个训练样本点使得 w T x i + b = 1 w^Tx_i+b=1 wTxi+b=1, w T x i + b = − 1 w^Tx_i+b=-1 wTxi+b=−1,则称为“支持向量”(support vector)。
间隔(margin),即两个异类支持向量到超平面距离之和:
r = 2 ∣ ∣ w ∣ ∣ r=\frac{2}{||w||} r=∣∣w∣∣2
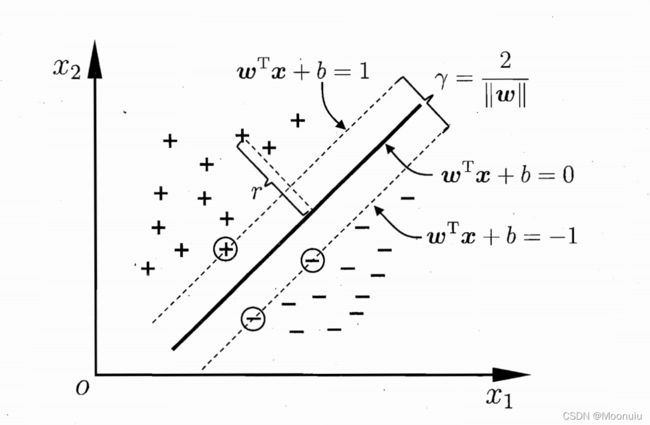
支持向量机就是找距离正负样本都最远的超平面。
将找“最大间隔”(maximum margin)的划分超平面转化为带约束条件的优化问题,找到约束参数 w w w和 b b b,使得 r r r最大,即为:
m a x w , b 2 ∣ ∣ w ∣ ∣ s . t . y i ( w T x i + b ) ≥ 1 , i = 1 , 2 , . . . , m \underset{w,b}{max} \; \frac{2}{||w||} \quad s.t. \; y_i(w^Tx_i+b)\geq1,i=1,2,...,m w,bmax∣∣w∣∣2s.t.yi(wTxi+b)≥1,i=1,2,...,m
等价于
m i n w , b 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y i ( w T x i + b ) ≥ 1 , i = 1 , 2 , . . . , m \underset{w,b}{min} \; \frac{1}{2} ||w||^2\quad s.t. \; y_i(w^Tx_i+b)\geq1,i=1,2,...,m w,bmin21∣∣w∣∣2s.t.yi(wTxi+b)≥1,i=1,2,...,m
以上为支持向量机SVM的基本型。
4.对偶问题
上面提到的支持向量机SVM的基本型公式,本身是一个凸二次规划(convex quadratic programming)问题。对其使用拉格朗日乘子法可得到“对偶问题”(dual problem),该问题的拉格朗日函数为:
L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m α i ( 1 − y i ( w T x i + b ) ) L(w,b,\alpha)= \; \frac{1}{2} ||w||^2+C\sum_{i=1}^{m} \alpha_i(1-y_i(w^Tx_i+b)) L(w,b,α)=21∣∣w∣∣2+Ci=1∑mαi(1−yi(wTxi+b))
其中 α = ( α 1 , α 2 , . . . , α m ) \alpha=(\alpha_1,\alpha_2,...,\alpha_m) α=(α1,α2,...,αm)
对偶问题:
m a x α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j \underset{\alpha}{max} \; \sum_{i=1}^{m}\alpha_i-\frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{m} \alpha_i\alpha_jy_iy_jx_i^Tx_j αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj
s . t . ∑ i = 1 m α i y i = 0 α i ≥ 0 , i = 1 , 2 , . . . , m s.t. \; \sum_{i=1}^{m}\alpha_iy_i=0\\\alpha_i\geq0,i=1,2,...,m s.t.i=1∑mαiyi=0αi≥0,i=1,2,...,m
KKT(Karush-Kuhn-Tucker)条件:
{ α i ≥ 0 ; y i f ( x i ) − 1 ≥ 0 ; α i ( y i f ( x i ) − 1 ) = 0 ; \begin{cases} \alpha_i\geq0; \\ y_if(x_i)-1\geq0; \\ \alpha_i(y_if(x_i)-1)=0; \end{cases} ⎩⎪⎨⎪⎧αi≥0;yif(xi)−1≥0;αi(yif(xi)−1)=0;
三、软间隔与支持向量回归
1. 软间隔
在现实任务中,原始样本空间内也许并不存在一个能正确划分两类样本的超平面,即线性不可分问题。
缓解该问题的一个方法是引入“软间隔”(soft margin)的概念,允许支持向量机犯错,即允许某些样本不满足约束条件。而“硬间隔”(hard margin)则是要求所有样本均满足约束,即所有样本都必须划分正确。

上图为软间隔示意图,红色圈圈为不满足约束 y i ( w T x i + b ) ≥ 1 y_i(w^Tx_i+b)\geq1 yi(wTxi+b)≥1的样本。
优化目标:
m i n w , b 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m l 0 / 1 ( y i ( w T x i + b ) − 1 ) \underset{w,b}{min} \; \frac{1}{2} ||w||^2+C\sum_{i=1}^{m} l_{0/1}(y_i(w^Tx_i+b)-1) w,bmin21∣∣w∣∣2+Ci=1∑ml0/1(yi(wTxi+b)−1)
其中, C > 0 C>0 C>0是一个常数, l 0 / 1 l_{0/1} l0/1是“0/1损失函数”。
三种常见的替代损失(surrogate loss)函数:hinge损失、指数损失、对率损失。

2. 支持向量回归(Support Vector Regression,SVR)
假设能容忍 f ( x ) f(x) f(x)与 y y y之间最多有 ϵ \epsilon ϵ的偏差,即仅当 f ( x ) f(x) f(x)与 y y y之间的差别绝对值大于 ϵ \epsilon ϵ时才计算损失。

红色显示出 ϵ \epsilon ϵ-间隔带,落入其中的样本不计算损失。
四、核函数(kernel function)
对于线性不可分问题,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。

如上图,将原始的二维空间映射到一个合适的三维空间,就能找到一个合适的划分超空间。
令 ϕ ( x ) \phi(x) ϕ(x)表示将 x x x映射后的特征向量,在特征空间中划分超平面所对应的模型可表示为:
f ( x ) = w T ϕ ( x ) + b f(x)=w^T\phi(x)+b f(x)=wTϕ(x)+b
其中, w w w和 b b b是模型参数。
由于特征空间维数可能很高,甚至可能是无穷维,直接计算 ϕ ( x i ) T ϕ ( x j ) \phi(x_i)^T\phi(x_j) ϕ(xi)Tϕ(xj)有难度。所以设计了一个函数:
κ ( x i , x j ) = < ϕ ( x i ) , ϕ ( x j ) > = ϕ ( x i ) T ϕ ( x j ) \kappa(x_i,x_j)=<\phi(x_i),\phi(x_j)>=\phi(x_i)^T\phi(x_j) κ(xi,xj)=<ϕ(xi),ϕ(xj)>=ϕ(xi)Tϕ(xj)
“核技巧”kernel trick,即 x i x_i xi和 x j x_j xj在特征空间的内积等于它们在原始样本空间中通过核函数 κ ( ⋅ , ⋅ ) \kappa(\cdot,\cdot) κ(⋅,⋅) 计算的结果。
模型最优解核函数展开式,“支持向量展式”:
f ( x ) = w T ϕ ( x ) + b = ∑ i = 1 m α i y i ϕ ( x i ) T ϕ ( x ) + b = ∑ i = 1 m α i y i κ ( x , x i ) + b f(x)=w^T\phi(x)+b \\ \quad \quad \quad \quad \quad \quad \quad =\sum_{i=1}^{m}\alpha_iy_i\phi(x_i)^T\phi(x)+b \\ \quad \quad \quad \quad \quad \; =\sum_{i=1}^{m}\alpha_iy_i\kappa(x,x_i)+b f(x)=wTϕ(x)+b=i=1∑mαiyiϕ(xi)Tϕ(x)+b=i=1∑mαiyiκ(x,xi)+b
几种常用的核函数:

其中, d = 1 d=1 d=1时退化为线性核。高斯核亦称为RBF核(Radial Basis Function,径向基函数)。
实例
class sklearn.svm.SVC(*, C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=- 1, decision_function_shape='ovr', break_ties=False, random_state=None)
- C:惩罚系数,防止模型过拟合;
- kernel:核函数,包括{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’};
- degree:多项式核函数的维度;
- gamma:核函数系数,只作用于 rbf、poly、sigmoid 三个核函数;
- coef0:常数项,只作用于poly 和 sigmoid 核函数;
- shrinking:启用启发式收缩;当迭代次数过大时, 启用启发式收缩可以缩短训练时间;
- probability:启用概率估计;
- tol:停止拟合容忍度;
- cache_size:核缓存大小;
- class_weight:类别的权重;
- verbose:启用详细输出日志;
- max_iter:最大迭代次数,-1表示不限制迭代次数;
- decision_function_shape:多分类策略;
- break_ties:启用打破平局,多分类任务时启用;
- random_state:随机数。
- 线性SVM
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
data = np.array([
[0.1, 0.7],
[0.3, 0.6],
[0.4, 0.1],
[0.5, 0.4],
[0.8, 0.04],
[0.42, 0.6],
[0.9, 0.4],
[0.6, 0.5],
[0.7, 0.2],
[0.7, 0.67],
[0.27, 0.8],
[0.5, 0.72]
])
label = [1] * 6 + [0] * 6
# 获取数据值所在的范围
x_min, x_max = data[:, 0].min() - 0.2, data[:, 0].max() + 0.2
y_min, y_max = data[:, 1].min() - 0.2, data[:, 1].max() + 0.2
# 生成网格坐标矩阵
# numpy.meshgrid从坐标向量中生成网格坐标矩阵。对于评估网格上的函数非常有用。
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.002),
np.arange(y_min, y_max, 0.002)) # meshgrid如何生成网格
# 支持向量机(svm)线性模型,SVC为Support Vector Classification支持向量分类器
# kernel='linear' 线性核函数;C:正则化系数,float类型,默认值为1.0,用来防止模型过拟合。C越小,泛化能力越强
model_linear = svm.SVC(kernel='linear', C = 0.001)
model_linear.fit(data, label) # 训练模型
Z = model_linear.predict(np.c_[xx.ravel(), yy.ravel()]) # 预测
# 变形
Z = Z.reshape(xx.shape)
# 绘制三维等高线图(contourf会填充轮廓)
plt.contourf(xx, yy, Z, cmap = plt.cm.ocean, alpha=0.6)
# 散点图
plt.scatter(data[:6, 0], data[:6, 1], marker='o', color='r', s=100, lw=3)
plt.scatter(data[6:, 0], data[6:, 1], marker='x', color='k', s=100, lw=3)
plt.title('Linear SVM')
plt.show()
- 多项式SVM
for i, degree in enumerate([1, 3, 5, 7, 9, 12]):
# C: 惩罚系数,kernel='poly':多项式核函数
model_poly = svm.SVC(C=0.0001, kernel='poly', degree=degree) # 多项式核
model_poly.fit(data, label)
# ravel - flatten
# c_ - vstack
# 把后面两个压扁之后变成了x1和x2,然后进行判断,得到结果在压缩成一个矩形
Z = model_poly.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制多个子图,subpot() 方法在绘图时需要指定位置,subplots() 方法可以一次生成多个,在调用时只需要调用生成对象的 ax 即可
plt.subplot(3, 2, i + 1)
plt.subplots_adjust(wspace=0.4, hspace=0.4)
plt.contourf(xx, yy, Z, cmap=plt.cm.ocean, alpha=0.6) # 等高线图
# 画出训练点
plt.scatter(data[:6, 0], data[:6, 1], marker='o', color='r', s=100, lw=3)
plt.scatter(data[6:, 0], data[6:, 1], marker='x', color='k', s=100, lw=3)
plt.title('Poly SVM with $\degree=$' + str(degree))
- 高斯核SVM
for i, gamma in enumerate([1, 5, 15, 35, 45, 55]):
# C: 惩罚系数,kernel='rbf':高斯核函数,gamma: 高斯核的系数
model_rbf = svm.SVC(kernel='rbf', gamma=gamma, C=0.0001).fit(data, label)
Z = model_rbf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.subplot(3, 2, i + 1)
plt.subplots_adjust(wspace=0.4, hspace=0.4)
plt.contourf(xx, yy, Z, cmap=plt.cm.ocean, alpha=0.6)
# 画出训练点
plt.scatter(data[:6, 0], data[:6, 1], marker='o', color='r', s=100, lw=3)
plt.scatter(data[6:, 0], data[6:, 1], marker='x', color='k', s=100, lw=3)
plt.title('RBF SVM with $\gamma=$' + str(gamma))
参考链接:
[1]: https://zhuanlan.zhihu.com/p/31886934
[2]: 机器学习(西瓜书), 周志华
[3]: https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html
[4]: https://blog.csdn.net/weixin_42279212/article/details/121504641