前言
好久不见。
从这篇文章开始,我将带大家走进消息中间件的世界。
消息中间件本质上就是一种很简单的数据结构——队列,但是一条队列肯定是当不成中间件的,你必须要考虑性能、容灾、可靠性等等因素。这也给我的写作提供了一些思路,我将从队列开始,给你演示一条队列是如何进化成一个靠谱的中间件的。
消息中间件的实现有很多,有新贵Kafka、RocketMq,也有老牌劲旅RabbitMq和ActiveMq,不过我最后选择了Nsq来讲解,因为它极简、清爽,用起来舒服,讲起来也好理解,更重要的是,通过对Nsq的学习,我们很容易扩展到消息中间件的通用层面,对学习其他Mq,乃至优化和设计自己的Mq都有很大帮助。
这一系列的文章,将有以下这些topics:
- 为什么要使用消息中间件
- 如何从一条队列,进化成一个靠谱的消息中间件:这一节,将带你从演化的视角,认识Nsq的各个组件
- Bringing It All Together:从微观层面了解完Nsq后,我们再从宏观的视角,把上一节学的东西串起来,看一条消息,是如何从生产到被消费的
- 一些实现细节:从近到远的看完了Nsq,现在让我们再一次把镜头拉近,看看Nsq在处理一些细节问题上的智慧,这对我们理解消息中间件,将有很大帮助
- 如何设计一个消息中间件:由近到远,由远及近,我们已经把Nsq看了个遍,是时候尝试总结一下,如何设计一个消息中间件了
- Nsq的不足:作为一个极简的Mq,Nsq肯定做不到的面面俱到,那么Nsq有哪些不足呢?
- Nsq vs Kafka:Nsq的那些不足,Kafka几乎都给解决了,毕竟人家是重量级Mq,功能自然强大的多。虽然大多数业务,使用Nsq已经可以解决问题,但还是了解一下,Kafka是怎么解决那些Nsq不屑于解决的问题吧~
- 有赞自研版Nsq:基于Nsq的一些不足,和对Kafka实现思路的借鉴,有赞对Nsq进行了自研开发,这一节,让我们了解一下有赞的改进思路
- ...
为什么要使用消息中间件
假设我们在淘宝下了一笔订单后,淘宝后台需要做这些事情:
- 消息通知系统:通知商家,你有一笔新的订单,请及时发货
- 推荐系统:更新用户画像,重新给用户推荐他可能感兴趣的商品
- 会员系统:更新用户的积分和等级信息
- ...
于是一个创建订单的函数,至少需要取调用三个其他服务的接口,就像这样:
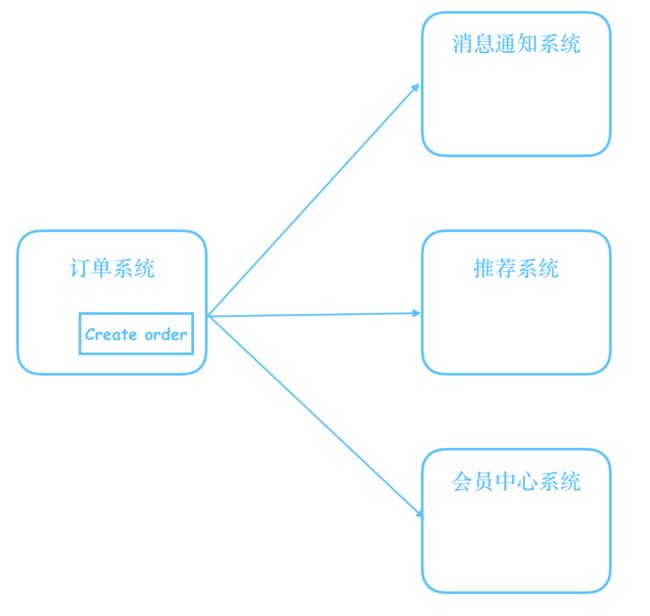
写成伪码:
createOrder(...) {
doCreateOrder(...);
// 调用其他服务接口
sendMsg(...);
updateUserInterestedGoods(...);
updateMemberCreditInfo(...);
}
这样的做法,显然很挫,至少有两个问题:
- 过度耦合:如果后面创建订单时,需要触发新的动作,那就得去改代码,在原有的创建订单函数末尾,再追加一行代码
- 缺少缓冲:如果创建订单时,会员系统恰好处于非常忙碌或者宕机的状态,那这时更新会员信息就会失败,我们需要一个地方,来暂时存放无法被消费的消息
我们需要一个消息中间件,来实现解耦和缓冲的功能。
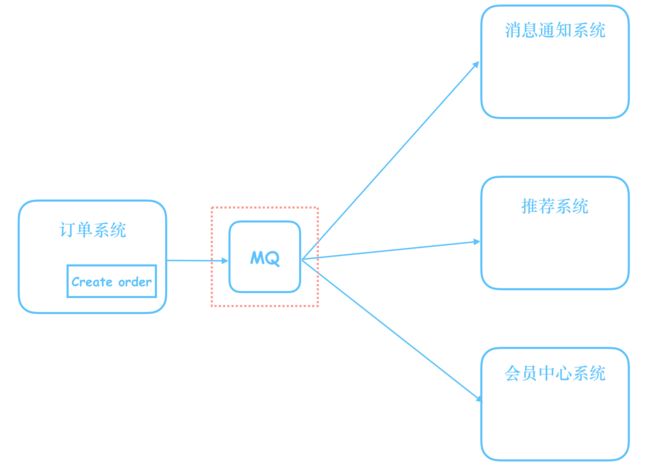
消息中间件的实现很多,比较常见的有kafka、rocketmq以及我们今天要讲的nsq。
相比于前面两个mq,nsq可以说是非常轻量级的,理解了它,也有助于学习kafka和rocketmq。所以本文以Nsq为例,来讲解消息中间件的一些实现细节。
首先,让我们从消息中间件的最原始形态开始,一种常见的数据结构 —— 队列。
Nsq 1.0 —— 我是一条队列
我们在订单系统和其他系统的中间,引入了一个消息中间件,或者说,引入了一条队列。
当订单系统创建完订单时,它只需要往队列里,塞入(push)一条topic为“order_created”的消息。
接着,我们的nsq1.0,会把这条消息,再推送给所有订阅了这个topic的消息的机器,告诉他们,“有新的订单,你们该干嘛干嘛”。
这样一个简单的队列,就解决了上面的两个问题:
- 解耦:如果后面有新的动作,需要在创建订单后执行,那么只需要让新同学自己去订阅topic为“order_created”的消息即可
- 缓冲:如果会员系统现在很忙,没空处理消息,那么只需跟nsq说,“我很忙,不要再发消息过来了”,那么nsq就不会给它推送消息,或者会员系统出了故障,消息虽然推送过去了,但是它给处理失败了,那么也只需给nsq回复一个“requeue”的命令,nsq就会把消息重新放入队列,进行重试。
Nsq 2.0 —— channel
作为一个靠谱的中间件,你必须做到:高效、可靠、方便。
上面这个使用一条简单的队列来实现的消息中间件,肯定是不满足这三点的。
首先,假设我的会员系统,部署了三台实例,他们都订阅了topic为“order_created”的消息,那么一旦有订单创建,这三台实例就都会收到消息,并且去更新会员积分信息,而其实我只需要更新一次就ok了。
这就涉及到一个消费者组(Comsumer Group)的概念。消费者组是Kafka里提到的,在Nsq,对应的术语是channel。
会员系统的三个实例,当它们收到消息时,要做的事情是一样的,并且只需要有有一个实例执行,那么它们就是一个消费者组里面的,要标识为同一个channel,比如说叫“update_memeber_credit”的channel,而短信系统和推荐系统,也要有自己的channel,用来和会员系统作区分,比如说叫“send_msg”和“update_user_interesting_goods”
当nsq收到消息时,会给每个channel复制一份消息,然后channel再给对应的消费者组,推送一条消息。消费者组里有多个实例,那么要推给谁呢?这就涉及到负载均衡,比如有一个消费者组里有ABC三个实例,这次推给了A,那么下次有可能是推送给B,再下次,也许就是C ...
nsq官网上的一张动图,非常好的解释了这个过程:
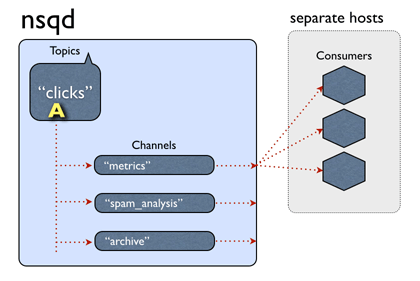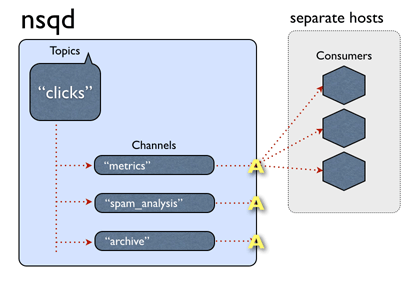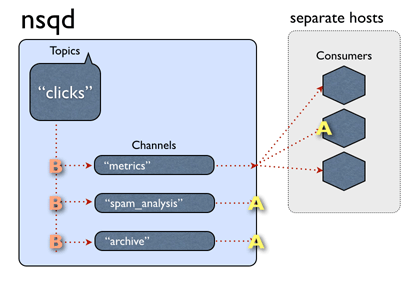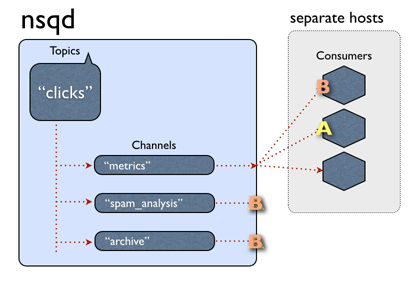
稍微解释一下,图中,nsq上有一个叫”clicks“的topic,”clicks“下面有三条channel,也就是三个消费者组,其中channel名称为”metrics“的,有三个实例。消息A来到nsq后,被复制到三条channel,接着,在metrics上的那个A,被推送到了第二个实例上。接着,又来了一个叫B的消息,这一次,B被推送给了第一个实例进行处理。
Nsq 3.0 —— nsqlookup
上面讲过,nsq收到生产者生产的消息后,需要将消息复制多份,然后推送给对应topic和channel的消费者。
那么,nsq怎么知道哪些消费者订阅了topic为“order_created”的消息呢?
总不能在配置文件里写死吧?ip为10.12.65.123的,端口8878,这个消费者的topic是xxx,channel是xxx,...
因此,我们需要一个类似于微服务里头的注册中心的模块,来实现服务发现的功能,这就是nsqlookup.
nsqlookup提供了类似于etcd、zookeeper一样的kv存储服务,里面记录了topic下面都有哪些nsq。
nsqlookup提供了一个/lookup接口,比如你想知道哪些nsq上面,有topic为test的消息,那么只需要调一下:
curl 'http://127.0.0.1:4161/lookup?topic=test'
nsqlookup就会给你返回对应topic的nsq列表:
{
"channels": [
"xxx"
],
"producers": [
{
"remote_address": "127.0.0.1:52796",
"hostname": "hongzeyangdeMacBook-Pro",
"broadcast_address": "127.0.0.1",
"tcp_port": 4150,
"http_port": 4151,
"version": "1.0.0-compat"
}
]
}
接着消费者只需要遍历返回的json串里的producers列表,把broadcast_address和tcp_port或者http_port拼起来,就可以拿到要建立连接的url地址。
消费者会和这些nsq,逐个建立连接。nsq收到对应topic的消息后,就会给和他们建立连接的消费者,推送消息。
这个过程,可以从nsq的消费者客户端实现的代码中,很清楚的看出来。
我这里用nsq的Java 客户端实现brainlag/JavaNSQClient作为例子。
首先,调用/lookup接口,获取拥有对应topic的nsq列表。注意看代码,里面是遍历了nsqlookup的列表,然后把所有lookup的返回结构,进行合并。
com.github.brainlag.nsq.lookup.DefaultNSQLookup#lookup:
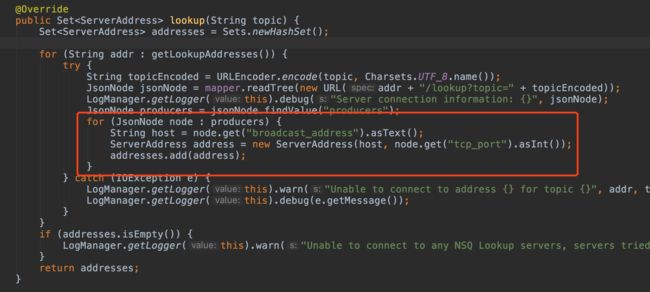
画红框的地方,正是之前讲的拼凑逻辑。
接着和旧的nsq列表比较,进行删除和新增,保证本地的nsq列表数据是最新的。
com.github.brainlag.nsq.NSQConsumer#connect:
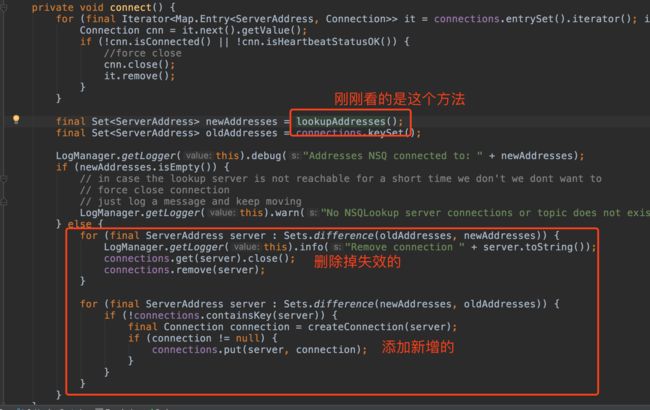
当然,这个过程不会只在消费者启动时才执行,而是定期去执行,不断去获取最新的nsq列表。

Nsq 4.0 —— nsqd集群
作为一个靠谱的中间件,你必须支持集群部署,这样才能实现可靠、高效。
nsq的集群部署非常简单,官方推荐一个生产者对应的部署一个nsqd:
What is the recommended topology for nsqd?
We strongly recommend running an nsqd alongside any service(s) that produce messages.
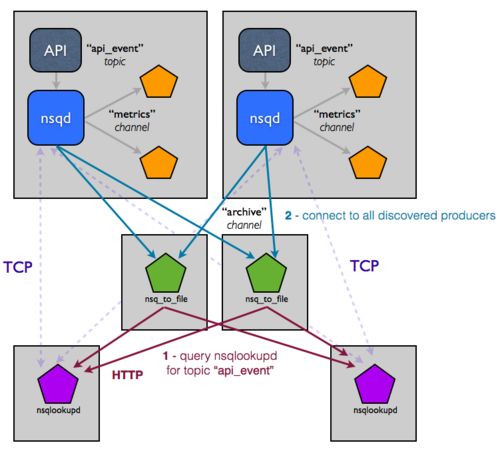
这也能解释,为什么上面的/lookup接口,返回的属性是叫producers,而不是叫nsqs,因为nsq认为一个producer,就对应一个nsq。
当然这样的做法有不少坏处,如果生产者对应的nsq挂掉了,那它就生产不了消息了。而且每个生产者都要部署一个nsq,未免有些奢侈。
不过对于大多数业务来说,这样的nsq已经够用。如果你像有赞一样,拥有一群Go语言大神,那也不妨对nsq做一下改造。一个简单的思路,就是模仿消费者侧的代码,通过nsqlookup来动态获取有效的nsq地址,然后往其中一个nsq发布消息。
小结
这篇文章主要从一个演化的视角,介绍了一条队列,如何逐步进化成一个消息中间件,也介绍了Nsq的几大模块:
- nsq: 存储消息的地方,每个topic可以有一个或者多个的channel
- nsqlookup:实现服务发现的模块
- nsqadmin:文章中没有提及,主要是进行可视化管理的web ui工具
下一讲,我将把这一次学到的东西串起来,了解一下,一条消息,是如何从生产到被消费的。
参考
- Nsq官方文档