一、简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算
二、下载
下载地址 https://hadoop.apache.org/releases.html

选择下面tsinghua的下载链接会快一些

下载后得到hadoop-3.2.1.tar.gz,把它放入soft共享文件夹
三、安装
切换到ubuntu
检查一下/mylab/soft目录是否存在,以及是否属于hadoop用户和hadoop组,要是不存在的话,先按如下步骤创建之
sudo mkdir -p /mylab/soft
sudo chown -R hadoop:hadoop /mylab
解压缩hadoop压缩包(假设hadoop-3.2.1.tar.gz放于~/soft,~代表用户的主目录,这里指/home/hadoop)
cd ~/soft
tar zxvf hadoop-3.2.1.tar.gz -C /mylab/soft
ls /mylab/soft
到目前为止,应该有了以下内容

四、配置
1.配置前准备
本章只讲述伪分布式方式的安装,所以只需要一台master主机
修改主机名
由于在安装时给主机起了一个hadoop的名字,现在需要把它改成master
sudo vi /etc/hostname
将文件的内容改为master,保存即可
sudo reboot
重启动后,打开terminal,提示符变成了hadoop@master
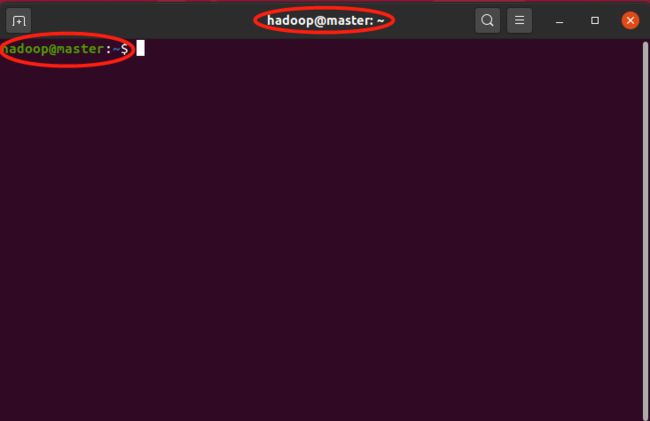
修改DNS
为了方便将来完全分布式部署的方便,我把官方文档中伪分布式配置中建议用localhost的地方,都将填为master,相应的,在DNS中将master配置为10.1.13.73(我的虚拟机IP地址)
查看本机ip
ifconfig

sudo vi /etc/hosts
加入一行
10.1.13.73 master
然后测试一下修改结果
ping master

2.修改环境变量
修改~/.bashrc
vi ~/.bashrc
#hadoop-3.2.1
export HADOOP_HOME=$MYLAB_BASE_HOME/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bashrc
env
检查一下环境变量是否正确
到目前为止,~/.bashrc中加入的内容如下

先小试一下,看看hadoop和jdk安装有没有问题
hadoop version
应该能够看到如下信息

3.修改hadoop配置文件
a) 创建工作目录
配置过程中,会用到一些目录信息,这里提前创建一下
rm -r $HADOOP_HOME/working/*
mkdir -p $HADOOP_HOME/working/namenode
mkdir -p $HADOOP_HOME/working/datanode
mkdir -p $HADOOP_HOME/working/logs
mkdir -p $HADOOP_HOME/working/tmp
ll $HADOOP_HOME/working

b) core-site.xml
这里好像只能用绝对路径,不能用系统变量名
c) mapred-site.xml
d) yarn-site.xml
/mylab/soft/hadoop-3.2.1/etc/hadoop:/mylab/soft/hadoop-3.2.1/share/hadoop/common/lib/*:/mylab/soft/hadoop-3.2.1/share/hadoop/common/*:/mylab/soft/hadoop-3.2.1/share/hadoop/hdfs:/mylab/soft/hadoop-3.2.1/share/hadoop/hdfs/lib/*:/mylab/soft/hadoop-3.2.1/share/hadoop/hdfs/*:/mylab/soft/hadoop-3.2.1/share/hadoop/mapreduce/lib/*:/mylab/soft/hadoop-3.2.1/share/hadoop/mapreduce/*:/mylab/soft/hadoop-3.2.1/share/hadoop/yarn:/mylab/soft/hadoop-3.2.1/share/hadoop/yarn/lib/*:/mylab/soft/hadoop-3.2.1/share/hadoop/yarn/*
注:yarn.application.classpath可以用hadoop classpath命令生成
e) hdfs-site.xml
f) workers
master
4.格式化namenode
hdfs namenode -format

ls $HADOOP_HOME/working/namenode

五、验证
1.查看hadoop版本号
hadoop version
2.启动hadoop
第一次启动
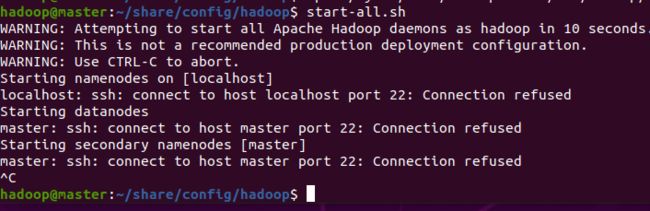
start-all.sh
要是出现这个提示,请参考下一篇《好玩的大数据之05:SSH安装》先安装和配置SSH
第二次启动
start-all.sh
要是出现这个提示,请修改hadoop-env.sh

vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
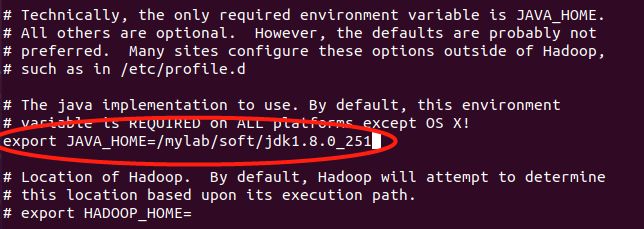
查找“export JAVA_HOME”这串字符(vi中查找用/export JAVA_HOME,找下一个按n键)
找到“#export JAVA_HOME=”这个位置,去掉前面的’#‘(vi中删除一个字符用x)
并修改为以下这个样子‘(vi中进入编辑状态敲i)
export JAVA_HOME=/mylab/soft/jdk1.8.0_251
修改完成先按ESC键,退出编辑状态,然后敲":x!"保存并退出
第三次启动
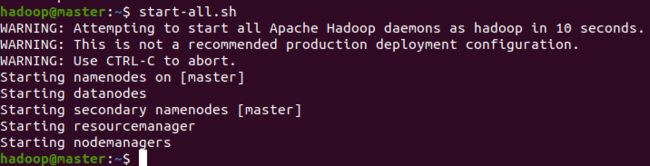
start-all.sh
要是出现这个提示,恭喜你,搞定噻
执行jps(Java Virtual Machine Process Status Tool,是java提供的一个显示当前所有java进程pid的命令,适合在linux/unix平台上简单察看当前java进程的一些简单情况)
jps
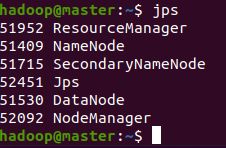
2.启动historyserver
mr-jobhistory-daemon.sh start historyserver
或者
mapred --daemon start historyserver
3.Web界面
1) ResourceManager
http://master:8088

2) NameNode
http://master:9870

1) JobHistoryServer
http://master:19888
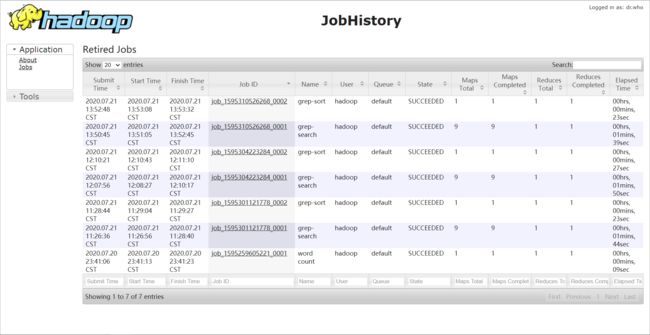
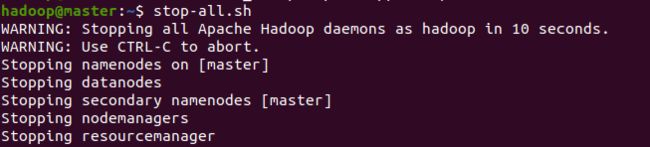
4.停止hadoop
stop-all.sh
正常的化,会出现这个提示
5.运行例子
hadoop fs -mkdir -p /user/hadoop/input
hadoop fs -put $MYLAB_BASE_HOME/hadoop-3.2.1/etc/hadoop/*.xml /user/hadoop/input
hadoop fs -rm -r /user/hadoop/output
hadoop jar $MYLAB_BASE_HOME/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /user/hadoop/input /user/hadoop/output
hadoop fs -ls /user/hadoop/output
https://blog.csdn.net/hitwengqi/article/details/8008203
6.离开/进入安全模式
离开
hadoop dfsadmin -safemode leave
进入
hadoop dfsadmin -safemode enter