论文中文版:
http://www.apachecn.org/bigdata/spark/112.html
http://alexlei.com/2015/12/18/RDD-paper/
内存集群计算平台
hadoop提供了一种对分布式系统资源的抽象, spark意在提供对分布式存储空间资源的抽象. spark对比mapreduce都是一种计算引擎. 因此spark最重要的一个概念是RDD
RDD
描述:
RDD是一个只读, 被分区的数据集. 意思就是说, 一个RDD可能被分成了好几个partition, 分布在不同的机器上. 如果需要操作RDD, 对这个RDD的每一个partition都会起一个task. 这样的话task就跟local的数据对接上了, 不然要远程pull的话, 就会浪费网络资源, 造成latency.
lazy特性:
RDD不需要被具体化, 一个RDD有足够的信息知道自己是从哪个数据集计算而来的, 即使这个RDD的信息丢失了, 也能对它进行重建.
RDD在进行transaction的时候并不会被实际计算出来, 而在进行action的时候才会真正的触发计算, 这称之为RDD的lazy特性. 因此我们可以先构建pipeline, 然后再计算.
RDD的四个关键变量:
1> 源数据分割之后的数据库, 源代码中的splits变量
2> 关于"血统" 的信息, 即这个RDD所依赖的父亲RDD以及2者之间的关系
3> 一个计算函数, 即这个RDD如何通过父亲RDD计算得到
4> 一些关于如何分块和数据所放位置的元信息
RDD的cache
RDD转换过程中, 并不是每个RDD都会存储, 如果需要对某个RDD复用, 那么可以通过对这个RDD的cache()方法, 把这个RDD存储下来.
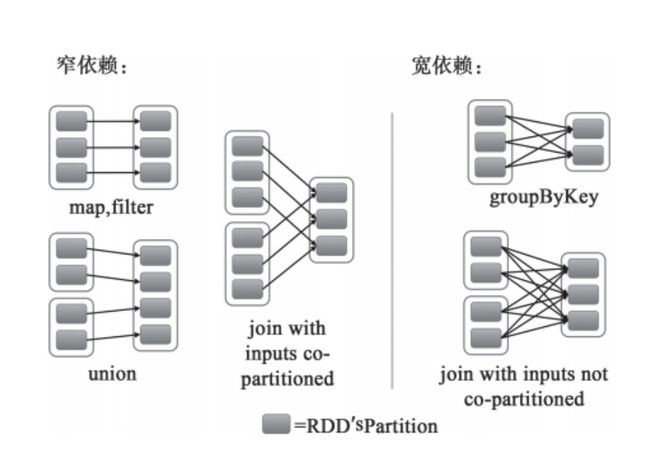
宽依赖和窄依赖:
narrow dependencies: where each partition of the parent RDD is used by at most one partition of the child RDD, wide dependencis, where multiple child partitions may depend on it.
- 计算方面:
计算窄依赖的子RDD:RDD的每个Partition,仅仅依赖于父RDD中的一个Partition.
计算宽依赖的子RDD:子RDD某一块数据的计算必须等到它的父RDD所有数据都计算完成之后才可以进行(子RDD的某个partition依赖于>=2个父RDD的partition),而且需要对父RDD的计算结果进行hash并传递到对应的节点之上; - 容错方面:
窄依赖: 父RDD的某个partition丢失时, 只有丢失那一块数据需要被重新计算
宽依赖: 当父RDD的某partition丢失时, 需要把父RDD的所有分区重新计算一次 - 关于函数:
窄依赖的函数有:
map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues
宽依赖的函数有:
groupByKey, join(父RDD不是hash-partitioned ), partitionBy
RDD的shuffle
在Spark编程时,不仅仅只有reduce才会产生shuffle过程,RDD提供的groupByKey,countApproxDistinctByKey等操作都会生成shuffle。Spark中shuffle的实现与MapReduce的shuffle有比较大的差别,首先是map阶段,map的输出不再需要排序,直接写到文件中,一个map会把属于不同reduce的数据分别输出到不同的文体中,而reduce则通过aggregator处理所有shuffle fetch获取的partition。
Spark 运行机制
I/O上, 数据以数据库的形式管理, 存储在内存, 磁盘上
通信上, 采用了AKKA通信框架, 在集群机器中传递命令和状态信息
容错上, 采用了lineage和che'c来保证容错性
spark应用
spark application是用户提交的应用程序. 模式分为:local, standalone, YARN, Mesos. 根据spark application的driver program又可以分为cluster模式和client模式.
基本概念:
sparkcontext: spark应用程序的入口, 负责调度各个运算资源, 协调各个worker node上的executor.
driver program: 运行application的main()函数并创建spark context.
RDD: 核心数据结构. 当遇到action算子时, 将之前所有算子形成一个有向无环图, 在spark中转化为Job, 提交到集群执行.
worker node: 集群中任何可以运行application代码的结点. 运行一个或者多个executor进程.
executor: 是worker node上的一个进程, 负责运行task, 并且负责将数据存在内存或者磁盘上. 每个application都会申请各自的executor来处理任务.
application执行过程中各个组件的概念:
task: RDD中的每一个分区对应一个task, task是单个分区上最小的处理流程单元
taskset: 相互关联的, 但是相互之间没有shuffle依赖关系的task集合
stage: 一个taskset对应的调度阶段. 每个Job会根据rdd的宽依赖关系被切分成很多stage, 每个stage都包含一个taskset. 划分stage有2种依据. 第一种是当触发rdd的action的时候, 第二种是触发rdd的shuffle的时候.
Job: 由action算子出发生成的由一个或多个stage组成的计算作业
application: 应用程序, 由一个或多个Job组成. 提交到spark之后, spark为application分配资源, 并做执行
DAGscheduler: 根据Job构建基于stage的DAG, 并提交给stage给task scheduler.
task scheduler: 将task set提交给worker node集群运行并返回结果
容易混淆的概念
spark比Hadoop快在2个地方. 1个是他的DAG计算模型, 相比于mapreduce模型来说, 在大多数情况下可以减少shuffle次数. 如果计算不涉及与掐结点进行数据交换, spark可以在内存中一次性完成这些操作. 即中间结果无须经过磁盘, 减少了IO的开销.
自己想的例子: 对一些数据进行filter + map + ....无须shuffle的操作, 这样的操作都是窄依赖, 不需要有shuffle过程. 因此也不需要写入磁盘, 但是如果是用mapreduce模型, 想象, 不可能在一个mapreduce里做完(假如先要进行filter, 是要把所有record都过一遍), 那么在多个mapreduce中, 就涉及中间反复的磁盘读写.
需要注意的式, 计算过程中如果涉及数据交换, spark也是会把shuffle的数据写到磁盘的.
另外需要注意的是, spark是基于内存的计算这句话的误区. 要对数据做计算, 肯定是要把数据加载到内存中去的, mapreduce也是一样. 只是spark可以将反复要用到的数据给cache到内存中, 减少数据加载耗时. 因此它也更适合做需要反复迭代的计算类型.
data skew: 根源是key的hash不均匀
1把 key 进行 salt 处理
2减少shuffle
使用reduceByKey rather than 4GroupByKey(前者会做local的combiner)
- SerDe. 设计shuffle和cache时, 需要存储, 数据都是在被序列化后才可以存储. 可以使用高效的serde形式.
关于spark的shuffle:
首先知道shuffle发生在某些特定的操作里. 比如groupByKey
然后shuffle的大致过程是这样:
- 假设mapper的数量是M, reducer的数量是R, 那么每个mapper在shuffle的过程中都会创建R个bucket, 这个bucket是一个容器(实现可以是一个文件). 因此, 每一条record都可能进入R个bucket里. 共有M * R个bucket. reducer需要拉取数据的时候, 从相应的mapper id已经bucket id中去拿数据, 或者是从本地的block manager那取得相应的数据.
相关源码:
val bucketId = dep.partitioner.getPartition(pair._1)
可以看出bucket的数量是 == partition的数量的, 每一个bkt是一个ArrayBuffer, 即就是说, map的输出结果会先放在内存里.
shuffle具体分为2个, 一个是shuffle write, 一个是shuffle fetch.
shuffle write:
早期shuffle write的策略:
早期(0.6-0.7版本)shuffle write的问题:
1.map的输出必须先全部存储到内存里, 然后写入磁盘. 这对内存是一个非常大的开销. 当内存不足的时候会出现OOM.
2.每一个mapper都会产生reducer number个shuffle文件. 例子: 如果mapper的数量是1K, reducer的数量也是1K, 那么就会产生1k * 1K个shuffle文件, 对文件系统是很大的负担.
在0.8版本时, shuffle write采用了与RDD block write不同的方式, 为shuffle write单独创建了ShuffleBlockManager.
具体他实现:
for (elem <- rdd.iterator(split, taskContext)) {
buckets.writers(bucketId).write(pair)
}
map的output的kv pair是逐条写入磁盘而不是先把所有pair都写入内然后再整体flush到磁盘中去.
shuffle的文件管理独立出了 shuffleBlockManager, 而不是与rdd cache文件在一起
问题:
- shuffle文件数量没有解决
- map output对内存的evaluate压力变小了, 但是新引入的DiskObejctWriter的buffer开销又有了. 每一个bucket都有一个write handler负责把bkt的数据写到磁盘.
例子: 加入有1k个mapper, 1k个reducer. 那么有1M个bucket, 同时又1M个write handler, 每个write handler默认需要100KB的内存, 那么总共需要100GB的内存. 这还只是buffer的.
在0.8.1版本里, 改进是, 每个bucket不再是一个独立的文件, 而是一个segment. 例如, 上面的例子里, 第一次运行mapper会申请8个bkt, 产生8个shuffle文件. 第二批mapper运行的时候, 申请的8个bkt不会再产生8个新文件, 而是append到之前的8个文件后面. 这样总共就还是8个shuffle文件, 知识有16个segmentation.
问题: write handler的buffer开销很大没有减少.
shuffle fetch
Shuffle write写出去的数据要被Reducer使用,就需要shuffle fetcher将所需的数据fetch过来,这里的fetch包括本地和远端,因为shuffle数据有可能一部分是存储在本地的。
在Hadoop中reducer的merge sort:
It buffers it up until the buffer is full, sorts that buffer, spills it to disk, and then does a merge sort between the spill files. If you have given the task enough memory, it won't spill at all and your sort will be very fast.
在spark的reducer中, 认为sort不是必须得, 所以不再reducer端做merge sort. 进行reduce是用了aggregator.
aggregator本质是一个hashmap, 以map output的key作为key, 以任意需要的combine的类型作为value的hashmap. (一条一条进来,没有就插入, 有了就更新), 这就省下了外部排序的步骤.
假如是groupByKey, spark因为没有merge sort这一步, 因此需要将key和对应的value全部存放在hashmap中, 并将value合并成一个array. 对内存要求很高(文档建议增加partition的数量防止有大key造成OOM).但是这样一来, bkt的数量就上去了--> write handler的buffer开销就变得更大了. 因此陷入了困境.
来源: http://jerryshao.me/architecture/2014/01/04/spark-shuffle-detail-investigation/
(不管怎么样, 每个mapper都会产生R个bkt, 那么每个reducer都要从M个mapper中去拿相应的bkt, 拿到R个bkt, 这R个bkt需要进行合并. 一定要合并, 但是不一定merge)
总结之前的:
0.8版本以前, hash based shuffle (by hashmap, no sort)
0.8.1 bkt不是每次都生成, 而是append
0.9 在combine的时候, 将数据spill到disk, 在disk进行堆排序
1.1 Sort Based Shuffle, 但是默认还是Hash Based Shuffle
sort based shuffle就跟Hadoop的很像了. 每个mapper只生成一个中间文件, 还生成一个索引文件, reduce端的task通过索引文件获取相关的数据
1.2 默认的shuffle 方式改为Sort Based Shuffle
1.4 引入Tungsten-Sort Based Shuffle(有严格的条件下才能用)
1.6 Tungsten-Sort Based or Sort Based Shuffle, 具体用哪一种, 由sortshuffleManager判断决定
2.0 Hash Based Shuffle不再available. 只有sortbased shuffle