1.Mahout介绍
1.1概述
根据百度的解说,Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。
1.2发展历史
mahout一直伴随Hadoop发展的,从一开始能够帮助我们在Hadoop上实现很多机器学习,到后来发现它的效率越来越慢,于是放弃使用了一段时间,在一年之后,大概14年开始宣布(0.9版本),截止14年底,mahout不再接受任何MapReduce开发的算法,转向spark。我们知道,Hadoop也是经历了从1.0到2.0时代的变迁,而mahout也是跟着这样一个变化而变化的。到了15年,mahout开始更新,更新到0.10、0.12版本后,mahout就开始使用基于Spark/Flink/H2O这样一些平台来去开发数据挖掘/机器学习库。虽然改变了开发平台,但也不是完全不支持了MapReduce的开发,只是不再接受新的MapReduce算法开发。
1.3特点
扩展性:mahout本身只是一个机器学习库,并不是一个平台,不像H2O,H2O是完整的做机器学习,预测分析的平台,而MapReduce只是一个库,它底层的存储还是基于HDFS,它的调度还是使用了Hadoop平台上的 YARN ,HDFS本身就给mahout带来了存储和计算
容错性:是基于MapReduce/Spark/Flink这些计算引擎来实现的,而MapReduce/Spark/Flink本身具有非常好的容错性,包括它的推送和执行和失败容错机制等。
1.4组件
属于Hadoop生态系统重要组成部分:如果Hadoop是一头大象,而mahout就是一个训象师,引导它往什么方向走,做什么样的事。它也是Hadoop的一个重要组件,伴随Hadoop成长。
1.5实现的大部分常用的数据挖掘算法
聚类算法

分类算法

其他算法

1.6Mahout后端计算引擎
支持mr,后来转向spark并包含原来的mr,spark最大特点是基于内存、基于图调度的方式、算子简单易用和适用的语言(底层有实现)
H2O本身是一个适用于做机器学习和预测分析的平台,自身有一套算法支持的库 ,H2O也可以在Hadoop中集成
Flink:支持流处理和批处理
有些不同的算法支持不同的计算引擎。
1.7Mahout架构
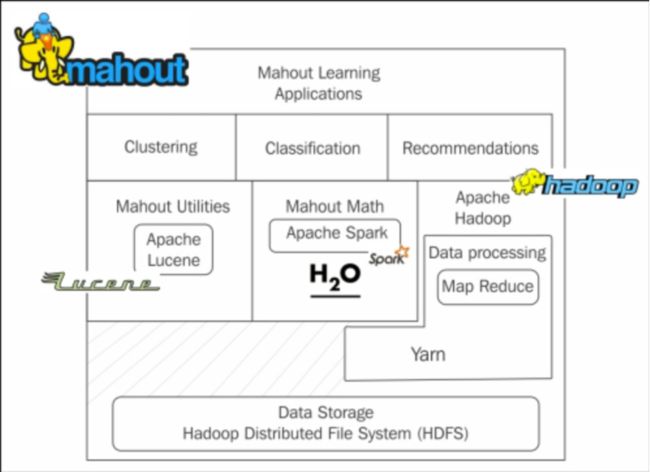
Mahout架构:low-level

Mahout提供的算法架构

2.mahout推荐算法介绍
2.1Mahout推荐系统介绍
协同过滤框架一
使用历史数据(打分,点击,购买等)作为推荐的依据
User-based: 通过发现类似的用户推荐商品。由于用户多变的特性,这种方法很那扩展;
Item-based:通过计算item之间相似度推荐商品。商品不易变化,相似度矩阵可离线计算得到。(诞生于Amazon)
MF-based:通过将原始的user-item矩阵分解成小的矩阵,分析潜在的影响因子,并以解释用户的行为。(诞生于Netflix Prize)
协同过滤框架二
SVD(Singular Value Decomposition)因式分解实现协同过滤
基于ALS(alternating least squares)的协同过滤算法
2.2Mahout推荐系统架构

2.3利用Mahout构建推荐系统
输入输出
输入:原始数据(user preferences,用户偏好)
输出:用户偏好估计
步骤
Step 1:将原始数据映射到Mahout定义的Data Model中
Step 2: 调优推荐组件
相似度组件,临界关系组件等
Step 3: 计算排名估计值
Step 4:评估推荐结果
2.4Mahout推荐系统组件
Mahout关键抽象是通过Java Interface实现的:
DataModel Interface将原始数据映射成Mahout兼容格式
UserSimilarity Interface计算两个用户间的相关度
ItemSimilarity Interface计算两个商品间的相关度
UserNeighborhood Interface定义用户或商品间的“临近”
Recommender Interface实现具体的推荐算法,完成推荐功能(包括训练,预测等)
推荐系统组件:DataModel

推荐系统组件:UserSimilarity

相似度举例:TanimotoDistance
相似度举例:CosineSimilarity

Pearson vs. Euclidean distance
Pearson vs. Euclidean distance

推荐系统组件:UserNeighborhood
从以上组件可以看出,Mahout提供了大量的基于CF的推荐器:
不同的推荐算法
不同的“邻接”定义
不同的相似度定义
评估不同的算法实现非常耗时
Mahout提供了评估不同算法组合效果的工具
Mahout提供了标准的推荐系统评估接口
2.5推荐系统评估
Mahout提供了大量方法用于评估推荐系统
1.基于Prediction-based measures:
Mean Average Error 平均绝对误差
RMSE (Root Mean Square Error) 均方根误差
Class: AverageAbsoluteDifferenceEvaluator
Method: evaluate()
Parameters:
Recommender implementation
DataModel implementation
TrainingSet size (e.g. 70%)
% of the data to use in the evaluation (smaller % for fast prototyping)
2.基于IR-based measures
Precision, Recall, F1-measure 准确率,召回率,F1混合
NDCG (ranking measure)
Class: GenericRecommenderIRStatsEvaluator
Method: evaluate()
Parameters:
Recommender implementation
DataModel implementation
Relevance Threshold (mean+standard deviation)
% of the data to use in the evaluation (smaller % for fast prototyping)
3.mahout推荐算法实战
实例1:preferences
要求:
创建user-item偏好数据,并输出
实现:
使用GenericUserPreferenceArray创建数据
通过PreferenceArray存储数据
代码如下:
package com.zdd.example;
import org.apache.mahout.cf.taste.impl.model.GenericUserPreferenceArray;
import org.apache.mahout.cf.taste.model.Preference;
import org.apache.mahout.cf.taste.model.PreferenceArray;
public class CreatePreferenceArray {
private CreatePreferenceArray() {
}
public static void main(String[] args) {
PreferenceArray User1Pref = new GenericUserPreferenceArray(2);
User1Pref.setUserID(0, 1L);
User1Pref.setItemID(0, 101L);
User1Pref.setValue(0, 3.0f);
User1Pref.setItemID(1, 102L);
User1Pref.setValue(1, 4.0f);
Preference pref = User1Pref.get(1);
System.out.println(User1Pref);
}
}
运行结果如下:
GenericUserPreferenceArray[userID:1,{101=3.0,102=4.0}]
表示用户ID为1的用户给商品101和102分别打分3.0和4.0
实例2:data model
PreferenceArray存储了单个用户的偏好,所有用户的偏好数据如何保存?HashMap? NO!
Mahout引入了一个为推荐任务优化的数据结构:FastByIDMap
需求:
使用GenericDataModel读入FastByIDMap数据
代码:
package com.zdd.example;
import org.apache.mahout.cf.taste.impl.common.FastByIDMap;
import org.apache.mahout.cf.taste.impl.model.GenericDataModel;
import org.apache.mahout.cf.taste.impl.model.GenericUserPreferenceArray;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.model.PreferenceArray;
public class CreateGenericDataModel {
private CreateGenericDataModel() {
}
public static void main(String[] args) {
FastByIDMap preferences = new FastByIDMap();
PreferenceArray User1Pref = new GenericUserPreferenceArray(2);
User1Pref.setUserID(0, 1L);
User1Pref.setItemID(0, 101L);
User1Pref.setValue(0, 3.0f);
User1Pref.setItemID(1, 102L);
User1Pref.setValue(1, 4.0f);
PreferenceArray User2Pref = new GenericUserPreferenceArray(2);
User2Pref.setUserID(0, 2L);
User2Pref.setItemID(0, 101L);
User2Pref.setValue(0, 3.0f);
User2Pref.setItemID(1, 102L);
User2Pref.setValue(1, 4.0f);
preferences.put(1L, User1Pref);
preferences.put(2L, User2Pref);
DataModel model = new GenericDataModel(preferences);
System.out.println(model);
System.out.println(preferences);
}
}
输出如下:
GenericDataModel[users:1,2]
{1=GenericUserPreferenceArray[userID:1,{101=3.0,102=4.0}],2=GenericUserPreferenceArray[userID:2,{101=3.0,102=4.0}]}
实例3:Recommender
需求:通过User-based协同过滤推荐算法给用户1推荐20个商品
实现:
1.使用FileDataModel读入文件
2.通过PearsonCorrelationSimilarity来计算相似度
3.使用GenericUserBasedRecommender构建推荐引擎
ua.base数据:

代码:
package com.zdd.example;
import org.apache.mahout.cf.taste.impl.model.file.*;
import org.apache.mahout.cf.taste.impl.similarity.*;
import org.apache.mahout.cf.taste.impl.neighborhood.*;
import org.apache.mahout.cf.taste.impl.recommender.*;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.similarity.*;
import org.apache.mahout.cf.taste.neighborhood.*;
import org.apache.mahout.cf.taste.recommender.*;
import java.io.File;
import java.util.List;
public class RecommenderIntro {
public static void main(String[] args) throws Exception{
DataModel model = new FileDataModel(new File("data/ua.base"));
UserSimilarity similarity = new PearsonCorrelationSimilarity(model);
UserNeighborhood neighborhood = new NearestNUserNeighborhood(100, similarity, model);
Recommender recommender = new GenericUserBasedRecommender(model, neighborhood, similarity);
List recommendedItems = recommender.recommend(1, 20);
for (RecommendedItem recommendedItem: recommendedItems){
System.out.println(recommendedItem);
}
}
}
推荐结果如下:

实例4:推荐模型评估(1)
需求:
评估实例3的推荐系统的优劣
实现:
使用AverageAbsoluteDifferenceRecommenderEvaluator和RMSRecommenderEvaluator来评估模型
通过RecommenderBuilder来实现评估模型
实现如下代码:
package com.zdd.example;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.RecommenderBuilder;
import org.apache.mahout.cf.taste.eval.RecommenderEvaluator;
import org.apache.mahout.cf.taste.impl.eval.AverageAbsoluteDifferenceRecommenderEvaluator;
import org.apache.mahout.cf.taste.impl.eval.RMSRecommenderEvaluator;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.*;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
import java.io.File;
public class EvaluatorIntro {
private EvaluatorIntro() {
}
public static void main(String[] args) throws Exception {
final DataModel model = new FileDataModel(new File("data/ua.base"));
RecommenderEvaluator evaluator = new AverageAbsoluteDifferenceRecommenderEvaluator();
RecommenderEvaluator recommenderEvaluator = new RMSRecommenderEvaluator();
RecommenderBuilder recommenderBuilder = new RecommenderBuilder() {
@Override
public Recommender buildRecommender(DataModel model) throws TasteException {
UserSimilarity similarity = new PearsonCorrelationSimilarity(model);
UserNeighborhood neighborhood = new NearestNUserNeighborhood(100, similarity, model);
return new GenericUserBasedRecommender(model, neighborhood, similarity);
}
};
//参数0.7表示评估的训练集为70%,1.0代表所有的用户来参与评估
double score = evaluator.evaluate(recommenderBuilder, null, model, 0.7, 1.0);
double rmse = recommenderEvaluator.evaluate(recommenderBuilder, null, model, 0.7, 1.0);
System.out.println(score);
System.out.println(rmse);
}
}
输出结果如下:
0.8522242111918109
1.0888589811454357
从结果可以看到,平均绝对误差大约为0.85,而均方根误差大约为1.09,在这个不大的数据集中,这个结果还能接受。
我们可以更改第34行代码来比较不同相似度的评分,这里用的相似度计算方式为皮尔森系数:UserSimilarity similarity = new PearsonCorrelationSimilarity(model);
更改为欧几里得:
UserSimilarity similarity = new EuclideanDistanceSimilarity(model);
更改为余弦相似度:
UserSimilarity similarity = new UncenteredCosineSimilarity(model);
实例5:推荐模型评估(2)
需求:
通过IR指标来评估实例3的推荐系统的优劣
实现:
使用RecommenderIRStatsEvaluator来进行评估
实现代码如下:
package com.zdd.example;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.*;
import org.apache.mahout.cf.taste.impl.eval.GenericRecommenderIRStatsEvaluator;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.*;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
import java.io.File;
public class IREvaluatorIntro {
public static void main(String[] args) throws Exception {
final DataModel model = new FileDataModel(new File("data/ua.base"));
RecommenderIRStatsEvaluator evaluator = new GenericRecommenderIRStatsEvaluator();
RecommenderBuilder recommenderBuilder = new RecommenderBuilder() {
@Override
public Recommender buildRecommender(DataModel model) throws TasteException {
UserSimilarity similarity = new PearsonCorrelationSimilarity(model);
UserNeighborhood neighborhood = new NearestNUserNeighborhood(100, similarity, model);
return new GenericUserBasedRecommender(model, neighborhood, similarity);
}
};
// 参数值5代表推荐5个商品,参数1.0代表全部用户参与评估
// 参数GenericRecommenderIRStatsEvaluator.CHOOSE_THRESHOLD代表Preference为多少时,两个item时相关的,这个参数值代表
// 我们在计算过程中自动调整这个阈值。
IRStatistics stats = evaluator.evaluate(recommenderBuilder, null, model, null, 5, GenericRecommenderIRStatsEvaluator.CHOOSE_THRESHOLD, 1.0);
System.out.println(stats.getPrecision());
System.out.println(stats.getRecall());
System.out.println(stats.getF1Measure());
}
}
输出结果如下:
0.011523687580025595
0.011523687580025595
0.011523687580025593
从结果可以看到,各项指标比较低。这是因为我们的数据样本还是很小,下一个实例将会使用相对大一些的数据集,电影数据集来进行实践。
实例6:MovieLens推荐系统
需求:
使用MovieLens 1M数据集实现电影推荐系统
步骤:
实现MovieLens数据集的DataModel
实现Item-based和User-based的协同过滤推荐,并保存结果
实现代码分三个代码文件,1.数据预处理,2.Item-based实现,3.User-based实现
1.数据预处理:
package com.zdd.MovieLens;
import org.apache.commons.io.Charsets;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.common.iterator.FileLineIterable;
import java.io.*;
import java.util.regex.Pattern;
public class MovieLensDataModel extends FileDataModel {
private static String COLON_DELIMITER="::";
private static Pattern COLON_DELIMITER_PATTERN=Pattern.compile(COLON_DELIMITER);
public MovieLensDataModel(File ratingsFile) throws IOException{
super(convertFile(ratingsFile));
}
private static File convertFile(File orginalFile) throws IOException{
File resultFile = new File(System.getProperty("java.io.tmpdir"), "ratings.csv");
if (resultFile.exists()){
resultFile.delete();
}
try(Writer writer = new OutputStreamWriter(new FileOutputStream(resultFile), Charsets.UTF_8)) {
for (String line: new FileLineIterable(orginalFile, false)){
int lastIndex = line.lastIndexOf(COLON_DELIMITER);
if (lastIndex < 0 ){
throw new IOException("Invalid data!");
}
String subLine = line.substring(0, lastIndex);
String convertedSubLine = COLON_DELIMITER_PATTERN.matcher(subLine).replaceAll(",");
writer.write(convertedSubLine);
writer.write('\n');
}
} catch (IOException ioe){
resultFile.delete();
throw ioe;
}
return resultFile;
}
}
2.Item-based实现:
package com.zdd.MovieLens;
import org.apache.mahout.cf.taste.impl.recommender.GenericItemBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.LogLikelihoodSimilarity;
import org.apache.mahout.cf.taste.impl.similarity.precompute.FileSimilarItemsWriter;
import org.apache.mahout.cf.taste.impl.similarity.precompute.MultithreadedBatchItemSimilarities;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.ItemBasedRecommender;
import org.apache.mahout.cf.taste.similarity.ItemSimilarity;
import org.apache.mahout.cf.taste.similarity.precompute.BatchItemSimilarities;
import org.apache.mahout.cf.taste.similarity.precompute.SimilarItemsWriter;
import java.io.File;
public class BatchItemSimilaritiesMovieLens {
private BatchItemSimilaritiesMovieLens(){
}
public static void main(String[] args) throws Exception{
if (args.length !=1){
System.err.println("Needs MovieLens 1M dataset as arugument!");
System.exit(-1);
}
File resultFile = new File(System.getProperty("java.io.tmpdir"), "similarities.csv");
DataModel dataModel = new MovieLensDataModel(new File(args[0]));
ItemSimilarity similarity = new LogLikelihoodSimilarity(dataModel);
ItemBasedRecommender recommender = new GenericItemBasedRecommender(dataModel, similarity);
//参数5代表相似物品的数量
BatchItemSimilarities batchItemSimilarities = new MultithreadedBatchItemSimilarities(recommender, 5);
SimilarItemsWriter writer = new FileSimilarItemsWriter(resultFile);
int numSimilarites = batchItemSimilarities.computeItemSimilarities(Runtime.getRuntime().availableProcessors(), 1, writer);
System.out.println("Computed "+ numSimilarites+ " for "+ dataModel.getNumItems()+" items and saved them to "+resultFile.getAbsolutePath());
}
}
运行代码,打印结果如下:
可以看到,在3706个物品中,有18530个相似物品的结果
并且在C:\Users\ADMINI~1\AppData\Local\Temp目录下,会产生ratings.csv和similarities.csv两个文件
similarities.csv数据如下:

3.User-based实现
package com.zdd.MovieLens;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.RecommenderBuilder;
import org.apache.mahout.cf.taste.impl.eval.RMSRecommenderEvaluator;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.CachingRecommender;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.Recommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
import java.io.File;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.List;
public class UserRecommenderMovieLens {
private UserRecommenderMovieLens(){
}
public static void main(String[] args) throws Exception {
if (args.length != 1) {
System.err.println("Needs MovieLens 1M dataset as arugument!");
System.exit(-1);
}
File resultFile = new File(System.getProperty("java.io.tmpdir"), "userRcomed.csv");
DataModel dataModel = new MovieLensDataModel(new File(args[0]));
UserSimilarity similarity = new PearsonCorrelationSimilarity(dataModel);
UserNeighborhood neighborhood = new NearestNUserNeighborhood(100, similarity, dataModel);
Recommender recommender = new GenericUserBasedRecommender(dataModel, neighborhood, similarity);
Recommender cachingRecommender = new CachingRecommender(recommender);
//Evaluate
RMSRecommenderEvaluator evaluator = new RMSRecommenderEvaluator();
RecommenderBuilder recommenderBuilder = new RecommenderBuilder() {
@Override
public Recommender buildRecommender(DataModel dataModel) throws TasteException {
UserSimilarity similarity = new PearsonCorrelationSimilarity(dataModel);
UserNeighborhood neighborhood = new NearestNUserNeighborhood(100, similarity, dataModel);
return new GenericUserBasedRecommender(dataModel, neighborhood, similarity);
}
};
double score = evaluator.evaluate(recommenderBuilder, null, dataModel, 0.9, 0.5);
System.out.println("RMSE score is "+score);
try(PrintWriter writer = new PrintWriter(resultFile)){
for (int userID=1; userID <= dataModel.getNumUsers(); userID++){
List recommendedItems = cachingRecommender.recommend(userID, 2);
String line = userID+" : ";
for (RecommendedItem recommendedItem: recommendedItems){
line += recommendedItem.getItemID()+":"+recommendedItem.getValue()+",";
}
if (line.endsWith(",")){
line = line.substring(0, line.length()-1);
}
writer.write(line);
writer.write('\n');
}
} catch (IOException ioe){
resultFile.delete();
throw ioe;
}
System.out.println("Recommended for "+dataModel.getNumUsers()+" users and saved them to "+resultFile.getAbsolutePath());
}
}
运行代码,结果如下:
RMSE score is 1.0747072266152768
Recommended for 6040 users and saved them to C:\Users\ADMINI~1\AppData\Local\Temp\userRcomed.csv
打开userRcomed.csv文件,如下:
1 : 32:5.0,28:5.0
2 : 2726:5.0,2607:5.0
3 : 2624:5.0,1262:5.0
使用电影数据集,给每个用户推荐了2个打分最高的商品。