感知机模型
假设输入空间\(\mathcal{X}\subseteq \textbf{R}^n\),输出空间是\(\mathcal{Y}=\{-1,+1\}\).输入\(\textbf{x}\in \mathcal{X}\)表示实例的特征向量,对应于输入空间的点;输出\(y\in \mathcal{Y}\)表示实例的类别。有输入空间到输出空间的如下函数:
称为感知机,其中\(\textbf{w}\)和\(b\)为感知机模型参数,\(\textbf{w}\in \textbf{R}^n\)叫做权值(weight)或权值向量(weight vector),
\(b \in \textbf{R}\)叫做偏置(bias),\(\textbf{w}\cdot \textbf{x}\)叫做\(\textbf{w}\)和\(\textbf{x}\)的内积。\(g\)是表示激活函数。理想中的中的激活函数是“阶跃函数”,即
它将输入值映射为输出值0或1,显示“1”对应于神经元兴奋,“0”对应于神经元抑制。然而,阶跃函数具有不连续、不光滑等不太好的性质(
函数不连续时无法求梯度。在Pytorch/Tensorflow中体现为梯度将一直保持初值\(0\),你可以试一试)
,因而实际常用下面这个\(\text{Sigmoid}\)函数做为激活函数,它把可能在较大范围内变化的输入值挤压到\((0,1)\)输出值范围内,因而有时也被称为“挤压函数”(squashing function)。
感知机是一种线性分类模型,属于判别模型。感知机模型的假设空间是定义在特征空间的所有线性分类模型(linear classification model)
或线性分类器(linear classifier),即函数集合\(\{ f|f(\textbf{x})=\textbf{w}\cdot \textbf{x}+b\}\)。
异或问题
我们将感知机用于学习一个简单的\(\text{XOR}\)函数。我们将其建模为二分类问题,这里我们采用上一章讲过的对数损失函数,并使用梯度下降法进行训练。
import numpy as np
import random
import torch
# batch_size表示单批次用于参数估计的样本个数
# y_pred大小为(batch_size, )
# y大小为(batch_size, ),为类别型变量
def log_loss(y_pred, y):
return -(torch.mul(y, torch.log(y_pred)) + torch.mul(1-y, torch.log(1-y_pred))).sum()/y_pred.shape[0]
# 前向函数
def perceptron_f(X, w, b):
z = torch.add(torch.matmul(X, w), b)
return 1/(1+torch.exp(-z))
# 之前实现的梯度下降法,做了一些小修改
def gradient_descent(X, w, b, y, n_iter, eta, loss_func, f):
for i in range(1, n_iter+1):
y_pred = f(X, w, b)
loss_v = loss_func(y_pred, y)
loss_v.backward()
with torch.no_grad():
w -= eta*w.grad
b -= eta*b.grad
w.grad.zero_()
b.grad.zero_()
w_star = w.detach()
b_star = b.detach()
return w_star, b_star
# 本模型按照二分类架构设计
def Perceptron(X, y, n_iter=200, hidden_size=2, eta=0.001, loss_func=log_loss, optimizer=gradient_descent):
# 初始化模型参数
# 注意,各权重初始化不能相同
w = torch.tensor(np.random.random((hidden_size, )), requires_grad=True)
b = torch.tensor(np.random.random((1)), requires_grad=True)
X, y = torch.tensor(X), torch.tensor(y)
# 调用梯度下降法对函数进行优化
# 这里采用单次迭代对所有样本进行估计,后面我们会介绍小批量法
w_star, b_star = optimizer(X, w, b, y, n_iter, eta, log_loss, perceptron_f)
return w_star, b_star
if __name__ == '__main__':
X = np.array([
[0, 0],
[0, 1],
[1, 0],
[1, 1]
], dtype=np.float64)
# 标签向量
y = np.array([0, 1, 1, 0], dtype=np.int64)
# 迭代次数
n_iter = 2000
# 学习率
eta = 2 #因为每轮所求的梯度太小,这里增大学习率以补偿
w, b = Perceptron(X, y, n_iter, hidden_size, eta, log_loss, gradient_descent)
# 代入
print(perceptron_f(torch.tensor(X), w, b))
我们数据代入所学的的模型,我们发现模型的输出结果如下。我们可以发现\(4\)个样本的预测值都是\(0.5\),不能拟合原本给定的\(4\)个样本点。如果你有兴趣可以将\(\bm{w}\)的梯度进行打印,可以发现\(\bm{w}\)的梯度来回震荡,这也就导致了权重\(\bm{w}\)无法稳定,最终导致模型最终无法收敛。
tensor([0.5000, 0.5000, 0.5000, 0.5000], dtype=torch.float64)
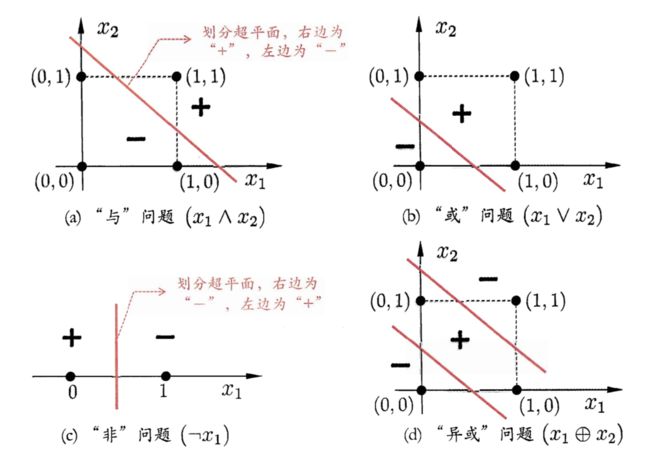
看来,普通的感知机无法解决亦或问题。那这是为什么呢?我们前面说了,感知机的模型是一个线性分类模型,只能处理线性可分问题(你可以试试让其学习与、或、非等线性可分问题)。可以证明,若两类模式是线性可分的,即存在一个线性超平面能将他们分开,如下图中的\((a)-(c)\)所示,则感知机的学习过程一定会收敛(converge)而求得适当的权向量\(\bm{w}\);否则感知机学习过程将会发生振荡(fluctuation),\(\bm{w}\)难以稳定下来,不能求得合适解。亦或问题就是一种非线性可分问题。如图\((d)\)所示,我们无法用线性超平面去将正负样本分隔开。
人工智能奠基人之一的Marvin Minsky与1969年出版了《感知机》一书,书中指出,单层神经网络无法解决非线性问题,而多层神经网络的训练算法尚看不到希望,这个论断直接使神经网络研究进入了“冰河期”,这就是神经网络的第一次低谷。直到后来BP算法的走红,才掀起了神经网络的第二次高潮。
多层感知机
单层的感知机无法解决亦或问题,那多层的呢?我们接下来考虑一个多层神经网络,但相比前面的感知机多了一个隐藏层\(\bm{h}\)。设该网络第一层的权重矩阵为\(\textbf{W}\)(表示\(\bm{x}\)到\(\bm{h}\)的映射),第二层的权重向量为\(\textbf{w}\)(表示\(\textbf{h}\)到中间变量\(z\))的映射,然后通过\(\text{Sigmoid}\)函数将\(z\)其映射到\(y\)这样神经网络包括两个嵌套在一起的函数\(\textbf{h} = f^{(1)}(\textbf{x};\textbf{W})\)和\(y=f^{(2)}(\textbf{h}; \textbf{w})\)。注意:此处为了简化起见,两层的偏置已经合并到权重\(W\),\(w\)
中去了。这样整个神经网络可以表示成一个复合函数\(f(\textbf{x};\textbf{W}, \textbf{w})=f^{(2)}f^{(1)}(x)\)
\(f^{(1)}\)应该采用那种函数?如果我们仍然采用线性函数,那么前馈网络作为一个整体仍然是线性分类器。故我们要用非线性函数,而这可以通过仿射变换后加一个非线性变换实现
(不知道仿射变换的可以回顾线性代数),而这个非线性变换可以用我们在\(f^{(2)}\)中所包括的激活函数实现。
还有一个工程上需要注意的是,如果我们有多层网络,那么我们不能将所有网络层权重都初始化为相同的值,这样会造成所有网络层权重梯度变化方向一样,最终像单层感知机一样无法学习。我们可以将所有网络层权重初始化为\([0, 1)\)之间的随机数(注意,神经网络的输入及权重一般初始时都是归一化到\([0, 1)\)之间了的)。后面我们会介绍更科学的\(\text{golort}\)权重初始化法。对于偏置,初始化为随机数或是常量(如\(0\)或\(1\))不影响,我们这里仍然采取将其初始化为\([0, 1)\)之间的随机数。
我们在原本的网络中多加一层。
import numpy as np
import random
import torch
# batch_size表示单批次用于参数估计的样本个数
# y_pred大小为(batch_size, )
# y大小为(batch_size, ),为类别型变量
def log_loss(y_pred, y):
return -(torch.mul(y, torch.log(y_pred)) + torch.mul(1-y, torch.log(1-y_pred))).sum()/y_pred.shape[0]
# 前向函数
def perceptron_f(X, W, w, b1, b2):
z1 = torch.add(torch.matmul(X, W), b1)
h = 1/(1+torch.exp(-z1))
z2 = torch.add(torch.matmul(h, w), b2)
return 1/(1+torch.exp(-z2))
# 之前实现的梯度下降法,做了一些小修改
def gradient_descent(X, W, b1, w, b2, y, n_iter, eta, loss_func, f):
for i in range(1, n_iter+1):
y_pred = f(X, W, w, b1, b2)
loss_v = loss_func(y_pred, y)
loss_v.backward()
with torch.no_grad():
W -= eta*W.grad
w -= eta*w.grad
b1 -= eta*b1.grad
b2 -= eta*b2.grad
W.grad.zero_()
w.grad.zero_()
b1.grad.zero_()
b2.grad.zero_()
W_star = W.detach()
w_star = w.detach()
b1_star = b1.detach()
b2_star = b2.detach()
return W_star, w_star, b1_star, b2_star
# 本模型按照二分类架构设计
def Perceptron(X, y, n_iter=200, hidden_size=2, eta=0.001, loss_func=log_loss, optimizer=gradient_descent):
# 初始化模型参数
# 注意,各权重初始化不能相同
W = torch.tensor(np.random.random((X.shape[1], hidden_size)), requires_grad=True)
b1 = torch.tensor(np.random.random((1)), requires_grad=True)
w = torch.tensor(np.random.random((hidden_size, )), requires_grad=True)
b2 = torch.tensor(np.random.random((1)), requires_grad=True)
X, y = torch.tensor(X), torch.tensor(y)
# 调用梯度下降法对函数进行优化
# 这里采用单次迭代对所有样本进行估计,后面我们会介绍小批量法
W_star, w_star, b1_star, b2_star = optimizer(X, W, b1, w, b2, y, n_iter, eta, log_loss, perceptron_f)
return W_star, w_star, b1_star, b2_star
if __name__ == '__main__':
X = np.array([
[0, 0],
[0, 1],
[1, 0],
[1, 1]
], dtype=np.float64)
# 标签向量
y = np.array([0, 1, 1, 0], dtype=np.int64)
# 迭代次数
n_iter = 2000
# 学习率
eta = 2 #因为每轮所求的梯度太小,这里增大学习率以补偿
# 隐藏层神经元个数
hidden_size = 2
W, w, b1, b2 = Perceptron(X, y, n_iter, hidden_size, eta, log_loss, gradient_descent)
# 代入
print(perceptron_f(torch.tensor(X), W, w, b1, b2))
你可以将原始样本点带入学得的模型,可以发现拟合结果如下所示,总体效果不错(因为数值精度问题,一般不会完全拟合)
tensor([0.0036, 0.9973, 0.9973, 0.0030], dtype=torch.float64)
更一般地,常见的神经网络是多层的层级结构,每层神经元与下一层神经元全互联,神经元之间不存在同层连接,也不存在跨层连接,这样的神经网络结构通常称为“多层前馈神经网络”(multi-layer feedforward neural)或多层感知机(multi-layer perceptron,MLP)。