Python机器学习库——Sklearn
目录
简介
常规使用模式
sklearn中的数据展示
sklearn model中常用属性与功能
数据标准化
交叉验证
过拟合问题
保存模型
小结
-
简介
Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression)、降维(Dimensionality Reduction)、分类(Classfication)、聚类(Clustering)方法。
常用的回归:线性、决策树、SVM、KNN ;集成回归:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
常用的分类:线性、决策树、SVM、KNN,朴素贝叶斯;集成分类:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
常用聚类:k均值(K-means)、层次聚类(Hierarchical clustering)、DBSCAN
常用降维:LinearDiscriminantAnalysis、PCA
-
常规使用模式
sklearn自带数据集,我们通过对自带数据集选择相应的机器学习算法进行训练。
from sklearn import datasets #导入数据集
from sklearn.model_selection import train_test_split #将数据分为测试集和训练集
from sklearn.neighbors import KNeighborsClassifier #利用近邻点方式训练数据
iris=datasets.load_iris() #加载鸢尾花数据
iris_X=iris.data #特征
iris_y=iris.target #目标变量
#将数据集分成训练集和测试集两部分,测试集占比30%
X_train,X_test,y_train,y_test=train_test_split(iris_X,iris_y,test_size=0.3)看看y_train都有啥:
[2 0 2 1 0 2 1 2 1 0 1 0 1 2 2 2 0 1 2 1 1 1 0 1 2 1 0 0 0 0 0 1 0 1 1 2 2 1 2 2 1 0 2 1 0 1 0 0 2 2 2 1 2 2 0 0 0 2 0 0 0 2 2 2 0 0 2 1 0 2 1 2 1 1 2 2 2 0 2 1 0 0 1 2 2 0 1 0 1 1 0 2 0 1 1 2 0 1 0 1 2 1 2 0 1]
训练数据:
knn=KNeighborsClassifier() #引入训练方法
knn.fit(X_train,y_train) #队训练数据进行拟合测试数据:
y_pred=knn.predict(X_test)
# y_predprob=knn.predict_proba(X_test)[:,1]查看一下测试数据的预测类别:
[1 1 1 1 1 0 0 0 0 0 1 2 0 1 2 2 1 0 0 0 2 1 2 2 2 0 2 0 0 2 1 2 2 0 1 2 0 2 1 2 1 1 1 2 0]
一般,我们参加比赛会把最后的模型结果写入.csv文件,提交。
生成一个样本对应ID,假设是1-45的序号:
ind=[]
for i in range(45):
ind.append(i+1)回顾Pandas中的数据框:
import pandas as pd
dic={'id':ind,'pred':y_pred}
test_pred=pd.DataFrame(dic)
test_pred.head()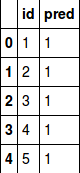
将数据框写入.csv文件中:
test_pred.to_csv('knn_iris.csv',index=False)
-
sklearn中的数据展示
from sklearn import datasets
X,y=datasets.make_regression(n_samples=100,n_features=1,n_targets=1,noise=1) #生成本地数据集
#n_samples:样本数 n_features:特征数,n_targets:输出y的维度
#对构造数据绘图
import matplotlib.pyplot as plt
plt.figure()
plt.scatter(X,y)
plt.show()
-
sklearn model中常用属性与功能
对于线性回归模型,最后训练的模型,可以输出拟合直线的系数和截距,同时可以获得训练模型所使用的参数,以及对训练模型进行打分。
from sklearn import datasets
from sklearn.linear_model import LinearRegression #导入线性回归模型
#加载数据
load_data=datasets.load_boston()
data_X=load_data.data
data_y=load_data.target
print(data_X.shape) #样本个数和样本特征数
#训练数据
model=LinearRegression()
model.fit(data_X,data_y)
model.predict(data_X[:4,:]) #预测前四个数据
#查看模型的一些属性和功能
w=model.coef_ #拟合直线的系数
b=model.intercept_ #拟合直线的截距
param=model.get_params() #模型训练参数
print(w)
print(b)
print(param)(506, 13)
[-1.07170557e-01 4.63952195e-02 2.08602395e-02 2.68856140e+00
-1.77957587e+01 3.80475246e+00 7.51061703e-04 -1.47575880e+00
3.05655038e-01 -1.23293463e-02 -9.53463555e-01 9.39251272e-03
-5.25466633e-01]
36.49110328036181
{'copy_X': True, 'fit_intercept': True, 'n_jobs': 1, 'normalize': False}
对于线性回归如此,对与其他的模型同样如此,根据官方文档查看模型的属性跟方法,使用起来非常方便。
-
数据标准化
许多学习算法中目标函数的基础都是假设所有的特征都是零均值并且具有同一阶数上的方差(比如径向基函数,支持向量机以及L1L2正则化项等)。如果某个特征的方差比其他特征大几个数量级,那么他就会在学习算法中占据主导位置,导致学习器对其他特征有所忽略。
标准化先对数据进行中心化,再除以特征的标准差进行缩放。
在sklearn中,我们可以通过Scale将数据缩放,达到标准化的目的。
from sklearn import preprocessing
import numpy as np
a=np.array([[10,2.7,3.6],
[-100,5,-2],
[120,20,40]],dtype=np.float64)
print("标准化前的数据:",a)
print("标准化后的数据:",preprocessing.scale(a))标准化前的数据: [[ 10. 2.7 3.6] [-100. 5. -2. ] [ 120. 20. 40. ]] 标准化后的数据: [[ 0. -0.85170713 -0.55138018] [-1.22474487 -0.55187146 -0.852133 ] [ 1.22474487 1.40357859 1.40351318]]
下边来看一下数据不做标准化处理跟做了标准化处理有什么区别:
from sklearn.model_selection import train_test_split
from sklearn.datasets.samples_generator import make_classification
from sklearn.svm import SVC
import matplotlib.pyplot as plt
#生成数据可视化如下
plt.figure()
X,y=make_classification(n_samples=300,n_features=2,n_redundant=0,n_informative=2,
random_state=22,n_clusters_per_class=1,scale=100)
plt.scatter(X[:,0],X[:,1],c=y)
plt.show()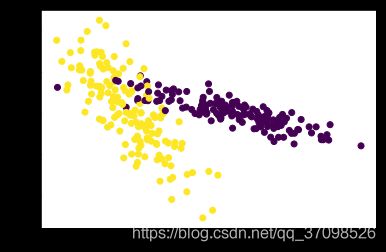
X_pre=X
y_pre=y
X_train_pre,X_test_pre,y_train_pre,y_test_pre=train_test_split(X_pre,y_pre,test_size=0.3)
clf=SVC()
clf.fit(X_train_pre,y_train_pre)
print(clf.score(X_test_pre,y_test_pre))0.5222222222222223
利用minmax方式对数据进行规范化:
X=preprocessing.minmax_scale(X) #feature_range=(-1,1) #可设置重置范围
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3)
clf=SVC()
clf.fit(X_train,y_train)
print(clf.score(X_test,y_test))
0.9111111111111111
可以看到数据规范化之前模型分数为0.52222,数据规范化之后模型分数为0.91111
-
交叉验证
交叉验证的思想就是重复的使用数据,把得到的样本数据进行切分,组合成为不同的训练集和验证集,用训练集来训练模型,用验证集评估模型预测的好坏。
(1)简单的交叉验证:
随机的将样本数据分为两部分(如70%训练,30%测试),然后用训练集来训练模型,在验证集上验证模型及参数;接着再把样本打乱,重新选择训练集和验证集,重新训练验证,最后选择损失函数评估最优的模型和参数。
(2)k折交叉验证:
随机将样本数均分为K份,每次随机选择其中的k-1份作为训练集,剩下的1份做验证集。当这一轮完成后,重新随机选择k-1份来训练数据,若干轮后选择损失函数评估最优的模型和参数。
(3)留一交叉验证:
留一交叉验证是k折交叉验证的一种特例,此时k=n(样本的个数),每次选择n-1个样本进行训练,留一个样本进行验证模型的好坏。
这种方法适合样本量非常少的情况。
(4)Boostrapping自助采样法:
这种方法也是随机森林训练样本采用的方法。
在n个样本中随机有放回抽样m个样本作为一颗树的一个训练集,这种采用会大约有1/3的样本不被采到,这些不被采到的样本就会被作为这棵树的验证集。
如果只是对数据做一个初步的模型建立,不需要做深入分析的话,简单的交叉验证就可以了,否则使用k折交叉验证,在样本量很小时,可以选择使用留一法。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score #导入交叉验证
#加载数据
iris=load_iris()
X=iris.data
y=iris.target
#训练数据
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3)
knn=KNeighborsClassifier(n_neighbors=5)#选择邻近的5个点
scores=cross_val_score(knn,X,y,cv=5,scoring='accuracy')#5折交叉验证,评分方式为accuracy
print(scores)#每组的评分结果
print(scores.mean())#平均评分结果[0.96666667 1. 0.93333333 0.96666667 1. ] 0.9733333333333334
调整模型参数,采用k近邻方法中k=5:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score#引入交叉验证
import matplotlib.pyplot as plt
#加载数据
iris=datasets.load_iris()
X=iris.data
y=iris.target
#设置n_neighbors的值为1到30,通过绘图来看训练分数
k_range=range(1,31)
k_score=[]
for k in k_range:
knn=KNeighborsClassifier(n_neighbors=k)
scores=cross_val_score(knn,X,y,cv=10,scoring='accuracy')#10折交叉验证
k_score.append(scores.mean())
plt.figure()
plt.plot(k_range,k_score)
plt.xlabel('Value of k for KNN')
plt.ylabel('CrossValidation accuracy')
plt.show()K过大会带来过拟合问题,我们可以选择12-18之间的值。

另外我们可以选择2-fold cross validation,leave-one-out cross validation等方法来分割数据,比较不同的方法和参数得到最优结果。
改变评分函数“neg_mean_squared_error”:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score#引入交叉验证
# from sklearn.model_selection import LeaveOneOut
import matplotlib.pyplot as plt
#加载数据
iris=datasets.load_iris()
X=iris.data
y=iris.target
print(len(X))
#设置n_neighbors的值为1到30,通过绘图来看训练分数
k_range=range(1,31)
k_score=[]
for k in k_range:
knn=KNeighborsClassifier(n_neighbors=k)
loss=-cross_val_score(knn,X,y,cv=10,scoring='neg_mean_squared_error')#10折交叉验证
k_score.append(loss.mean())
plt.figure()
plt.plot(k_range,k_score)
plt.xlabel('Value of k for KNN')
plt.ylabel('CrossValidation accuracy')
plt.show()-
过拟合问题
过拟合的问题是因为模型过于复杂,对于训练数据能很好的拟合,却不能正确的处理测试数据,从一个角度说就是,学到了一些样本数据一些非通用信息。使得模型的泛化效果非常不好。
sklearn.learning_curve中的learning curve可以直观的看出模型学习的进度,对比发现有没有过拟合。
from sklearn.model_selection import learning_curve # 学习曲线
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
#加载数据
digits=load_digits()
X=digits.data
y=digits.target
#train_size表示记录学习过程中的某一步,比如在10%,25%...的过程中记录一下
train_size,train_loss,test_loss=learning_curve(
SVC(gamma=0.1),X,y,cv=10,scoring='neg_mean_squared_error',
train_sizes=[0.1,0.25,0.5,0.75,1]
)
train_loss_mean=-np.mean(train_loss,axis=1)
test_loss_mean=-np.mean(test_loss,axis=1)
plt.figure()
#将每一步进行打印出来
plt.plot(train_size,train_loss_mean,'o-',color='r',label='Training')
plt.plot(train_size,test_loss_mean,'o-',color='g',label='Cross-validation')
plt.legend(loc='best')
plt.show()损失函数的值在10左右停留,便能直观得看出过拟合:

改变gamma的值0.01,会相应的改变loss函数:
from sklearn.model_selection import learning_curve # 学习曲线
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
#加载数据
digits=load_digits()
X=digits.data
y=digits.target
#train_size表示记录学习过程中的某一步,比如在10%,25%...的过程中记录一下
train_size,train_loss,test_loss=learning_curve(
SVC(gamma=0.01),X,y,cv=10,scoring='neg_mean_squared_error',
train_sizes=[0.1,0.25,0.5,0.75,1]
)
train_loss_mean=-np.mean(train_loss,axis=1)
test_loss_mean=-np.mean(test_loss,axis=1)
plt.figure()
#将每一步进行打印出来
plt.plot(train_size,train_loss_mean,'o-',color='r',label='Training')
plt.plot(train_size,test_loss_mean,'o-',color='g',label='Cross-validation')
plt.legend(loc='best')
plt.show()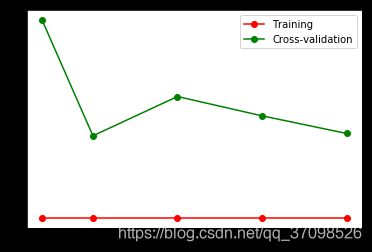
通过改变不同的gamma值可以看到Loss函数的变化情况:
from sklearn.model_selection import validation_curve # 验证曲线
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
#加载数据
digits=load_digits()
X=digits.data
y=digits.target
#改变param来观察loss函数的情况
param_range=np.logspace(-6,-2.3,5)
train_loss,test_loss=validation_curve(
SVC(),X,y,param_name='gamma',param_range=param_range,cv=10,
scoring='neg_mean_squared_error'
)
train_loss_mean=-np.mean(train_loss,axis=1)
test_loss_mean=-np.mean(test_loss,axis=1)
plt.figure()
plt.plot(param_range,train_loss_mean,'o-',color='r',label='Training')
plt.plot(param_range,test_loss_mean,'o-',color='g',label='Cross-validation')
plt.xlabel('gamma')
plt.ylabel('loss')
plt.legend(loc='best')
plt.show()
-
保存模型
from sklearn import svm
from sklearn import datasets
#加载数据
iris=datasets.load_iris()
X,y=iris.data,iris.target
clf=svm.SVC()
clf.fit(X,y)
print(clf.get_params)
导入sklearn中自带的保存模块:
from sklearn.externals import joblib
#保存model
joblib.dump(clf,'sklearn_save/clf.pkl')重新加载model,只有保存一次后才能加载model:
clf3=joblib.load('sklearn_save/clf.pkl')
print(clf3.predict(X[0:1]))[0]
-
小结
对于机器学习任务,一般我们的主要步骤是:
1.加载数据集(自己的数据,或者网上的数据,或者sklearn自带的数据)
2.数据预处理(降维,数据归一化,特征提取,特征转换)
3.选择模型并训练 (直接查看api找到你需要的方法,直接调用即可,其中你可能需要调调参等)
4.模型评分(使用模型自带的score方法,或者使用sklearn指标函数,或者使用自己的评价方法)
5.模型的保存
sklearn官方文档:https://scikit-learn.org/stable/user_guide.html