1、Handler:
1):系统Handler的创建过程及相关对象的创建:在ActivityThread的main方法中调用getHandler方法创建,getHandler方法的实现是直接new了一个Handler的子类H来创建Handler对象的。创建完Handler对象后进行Looper对象的创建。Looper对象是通过调用Looper.prepareMainLooper()方法,该方法会调用prepare方法,创建Looper对象并且存储在sThreadLocal中,此方法只能调用一次,超过会抛出一个线程只能创建一个Looper对象的异常。Looper对象只能创建一次然后通过Looper.myLooper()方法获取(其实就是调用sThreadLocal.get()获取)。在Looper的构造方法中进行MessageQueue的初始化工作,到此为止,Handler的对象完成创建,Looper对象完成创建,MessageQueue对象完成创建,最后一步是在ActivityThread的main方法的最后进行Looper的Loop方法的调用,此方是一个死循环方法。到此Handler的初始化工作全部结束。
2):在子线程中创建Handler的方法,直接进行new一个Handler出来(此种方法容易引起内存泄漏问题),如果没有传入Looper对象参数,默认使用mainLooper对象,如果需要使用自己本线程的Looper对象,需要在参数中调用Looper.myLooper方法来实现子线程Looper对象的初始化工作。一个线程只能有一个Looper对象,意味着一个线程也只能有一个MessageQueue对象,因为MessageQueue对象是在Looper对象的构造方法中进行创建的。
3):Handler是怎么实现延迟消息的?Handler的延迟消息的实现是通过延迟发送来进行实现的,在发送延迟消息时,Handler会将延迟消息进行入队操作并添加延迟时间,在等待期间如果有新的及时消息进入会排在延时消息的前面并开始进行消息的发送,发送结束后再判断延迟消息的等待时间是否到达,如果未达到再进行新的等待时间计算。其实及时消息和延迟消息的实现是一样的,只是及时消息的等待时长为0而已。
4):Handler导致内存泄漏的原因及处理办法?在Java中,非静态内部类和匿名内部类都会隐式持有当前外部类的引用。Handler发送一个延迟消息,此时Message会在messageQueue里面存活一段时间,这段时间,message持有Handler的引用,Handler又持有当前Activity的引用,当我们finish当前Activity时,GC无法对这个Activity对象进行回收,导致内存泄漏。处理方式一般在当前Activity的内部写一个静态的内部类重写handlerMessage方法,并在此静态内部类中使用WeakReference
2、Android中事件传递机制:如下图所示
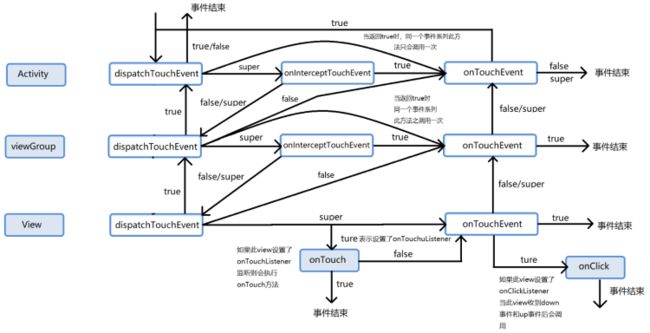
滑动冲突的解决方法:
- 外部拦截法
点击事件都先经过父容器进行拦截处理。需要重写父容器的onInterceptTouchEvent方法。ACTION_DOWN事件必须返回false,否则后续事件都会交给父容器处理,子元素无法收到事件。ACTION_MOVE事件如果父容器需要进行拦截就返回true,不拦截的话就返回false。ACTION_UP事件必须返回false,如果返回true,子元素就无法收到UP事件,子元素设置的onclick事件就无法触发。
- 内部拦截法
所有事件都传递给子元素,如果子元素需要处理,就直接处理消耗掉,否则就交给父容器进行处理。需要重写子元素的dispatchTouchEvent方法。在需要拦截的地方调用parent.requestDisallowInterceptTouchEvent(true)方法,不需要拦截的时候调用parent.requestDisallowInterceptTouchEvent(false)方法。父元素需要重写onInterceptTouchEvent方法,默认拦截除了ACTIONG_DOWN以外的其它事件(MotionEvent事件为ACTION_DOWN时返回ture),这样子子元素在调用了parent.requestDisallowInterceptTouchEvent(false)方法时,父元素才能继续拦截所有的事件。
3、Activity、Window、ViewGroup、View的关系:
Activity--->Window(唯一的实现类PhoneWindow)--->DecorView--->setContentView中的ViewGroup--->ViewGroup--->View
4、Activity的生命周期:
onCreate()-->[ onReStart() ]-->onStart()-->onResume()-->onPause()-->onStop()-->onDestroy();
A跳转至B生命周期执行顺序:A-->onPause--->B-->onCreate-->B-->onStart-->B-->onResume-->A-->onStop;耗时操作不能再onPause里面操作,这样才能快速打开新的Activity。
界面横竖屏切换生命周期顺序(没有配置android:configChanges):onPause-->onSaveInstanceState-->onStop-->onDestroy-->onCreate-->onStart-->onRestoreInstanceState -->onResume;其中onSaveInstanceState和onPause没有既定的先后顺序即可前课后,onRestoreInstanceState是在onStart之后进行调用,只有Activity有可能被恢复的情况下才会调用onSaveInstanceState方法,此方法将之前Activity的参数保存在Bundle中,我们可以在onRestoreInstanceState和onCreate中进行数据的恢复,不过一般建议在onRestoreInstanceState方法中进行操作,无需判空,在onCreate方法中需要判断Bundle的空值情况。当只设置Activity的android:configChanges="orientation"时,切屏还是会重新调用各个生命周期。而设置Activity的android:configChanges="orientation|keyboardHidden"时,切屏不会重新调用各个生命周期,只会执行onConfigurationChanged方法。
A界面资源内存不足导致优先级低的Activity被kill:其恢复数据的方式是一样的,同样会调用onSaveInstanceState和onRestoreInstanceState方法。
如何让A界面不重新创建:需要在manifests中添加Activity的configChanges属性,一般常用的属性有orientation(屏幕旋转)、locale(本地设置该变,一般指切换了系统语言)、keyboardHidden(键盘的可访问性,用户调出键盘)。Activity的跳转有显示和隐式两种,显示就是我们平时用得到,隐式跳转需要在manifests中的Activity中配置intent-filter标签,一个Activity标签中可以有多个intent-filter标签,intent-filter标签中可以有多组action、category、data属性,只有完全匹配其中的一个intent-filter中的一组属性才能完成隐式跳转。
5、自定义View及View的工作流程:
自定义View的三个重要方法执行顺序:onMeasure-->onLayout-->onDraw,分别功能是---测量自身的大小宽高-->确定自己在父容器中的位置-->进行自身内容的绘制。
onMeasure(int widthMeasureSpec,int heightMeasureSpec);方法中的两个参数是一个由32位的int值,高两位代表SpecMode,低30位代表SpecSize。
SpecMode有三种模式:UNSPECIFIED-->父容器不对View有任何限制,要多大给多大。EXACTLY-->父容器已经检测出view的精确大小。AT_MOST-->父容器制定一个可用大小,View的大小不能超过这个值,具体情况看View自身的情况。普通View的大小需要根据父容器的MeasureSpec和子元素的LayoutParams共同决定。子元素的LayoutParams根据父元素的MeasureSpec类型决定。总结一条规律:如果子元素是精确模式,子元素的LayoutParams的值就是精确值,不管父容器是什么模式,其他情况都是取父容器中LayoutParams中的值。如果自定义view是继承View,需要在设置wrap_content时在onMeasure方法中做特殊处理。一般情况是给一个默认的值。
在测量的时候可以调用setMeasuredDimension(width,height)方法设置测量的值。
ViewGroup位置确定后通过onLayout方法遍历所有的子元素并调用其layout方法确定其位置。Layout方法通过setFrame方法设定view的四个顶点位置确定子元素的位置。
Draw过程:
绘制背景
绘制自己
绘制children
绘制装饰
自定义View分类
继承View重写onDraw方法
继承ViewGroup派生特殊的layout
继承特定的Veiw(比如TextView)
继承特定的ViewGroup(比如LinearLayout)
自定义View需要注意的地方
让View支持wrap_content属性,需要在onMeasure中处理,传入一个默认的宽高。
注意paddding属性的支持,需要在onDraw方法中对padding值进行处理(宽度的话就要减去左右padding值)
尽量不要在View中使用到Handler,直接用post方法代替handler
View中有动画或者线程需要及时停止。
6、动画的种类及区别:
三种动画:View动画、帧动画、属性动画
View动画:平移动画(TranslateAnimation)、缩放动画(ScaleAnimation)、旋转动画(RotateAnimation)、透明度动画(AlphaAnimation)。它只移动了View的内容,没有改变View在布局中的位置,做的只是影像动画。View动画的使用可以在XML中创建动画文件也可以在java中直接new出相对应的动画并传递参数再开启动画即可。View动画的使用场景-->ListView的item入场动画,在ListView布局中加入layoutAnimation 属性,也可以在java代码中创建LayoutAnimationController来使用。Activity进出动画主要使用overridePendingTransition方法来实现Activity的专场动画。
自定义View动画:写一个类继承Animation,重写它的initialize()和applyTransformation()方法。在initialize方法中做一些初始化的工作,在applyTransformation方法中做一些矩阵变换的操作。
帧动画:顺序播放一组预先定义好的图片。
属性动画:ValueAnimator、ObjectAnimator、AnimatorSet;ObjectAnimator继承自ValueAnimator,AnimatorSet是一个动画集合,里面可以包含多个ObjectAnimator和animator。属性动画还提供了两个监听属性动画播放的监听接口-->AnimatorUpdateListener 和 AnimatorListener,AnimatorListener需要实现4个方法,onAnimationStart、onAnimationEnd、onAnimationCancel、onAnimationRepeat,开始、结束、取消、重复。AnimatorUpdateListener只需要实现一个方法,onAnimationUpdate方法。其中AnimatorListener还提供了AnimatorListenerAdapter,里面有6个方法,多了onAnimationPause、onAnimationResume方法。
属性动画原理:根据外界传入的属性的初始值和最终值,以动画的效果多次去调用set方法,来达到动画效果。所以必须提供该动画作用对象属性值的set方法。属性动画可以配置差值器和估值器实现非匀速动画。
使用动画需要注意的问题:在Activity退出时需要及时关闭,不然会导致内存泄漏。使用帧动画容易导致OOM内存溢出。View动画后会出现setVisibility方法无效的问题,需要调用view.clearAnimation方法清除View的动画即可。View动画点击事件还是在动画原位置,而不是移动后的位置。
7、Android四大组件:Activity、Service、BroadcastReceiver、ContentProvider;
Activity耗时无响应是5s,BroadcastReceiver是10s,Service是20s
除了BroadcastReceiver外其他的三种组件都必须在Manifest中进行注册,对于BroadcastReceiver来说,可以在AndroidManifest中注册也可以在代码中进行注册。在调用方式上来说,Activity、Service、BroadcastRevceiver都需要借助Intent来调用,而ContentProvider无需借助Intent。
BroadcastReceiver注册方式:静态注册-->在AndroidManifest中进行注册,这中注册方式APP在安装的时候就会被系统解析,无需启动就可以接收到相关的广播(8.0版本后广播需要动态注册,不然可能没有效果)。动态注册-->需要通过Context.registerReceiver来实现,并且在不需要的时候需要通过Context.unRegisterReceiver来解除广播。这种注册方式需要开启APP才能接收到广播。BroadcastReceiver一般不需要停止,也没有停止的概念。广播的类型有普通广播、有序广播、粘性广播三种。有序广播需要在AndroidManifest中设定广播的优先级priority,优先级大的先接收到广播,后面的再接收到,中途也可以拦截,发送广播一般是全局广播,要发送本地广播需要借助LocalBroadcastManager来注册广播和发送广播。
ContantProvider时一种数据共享型组件,用于向其他组件乃至其他应用共享数据。无法直接被用户感知。对于ContentProvider组件来说需要实现增删改查这四种操作,在它的内部维持着一份数据集合。这四种方法需要保证线程安全,ContentProvider组件也不需要手动停止。
Service是运行在主线程的,Service中不能进行耗时操作,如有耗时操作需要创建子线程来进行执行。Service中的Binder对象调用的方法是运行在Binder线程池中。
启动方式:startService和bindService。结束方式:stopService和unBindService。
startService和stopService一一对应,一个开启一个结束。
Service的生命周期:(startService)-->onCreate--->onStartCommand--->(stopService)--->onDestroy。
bindService和unbindService一一对应,一个开始一个结束。
Servicec的生命周期:(BindService)-->onCreate--->onBind--->(UnbindService)--->onUnbind--->onDestroy。
start和stop只能开启和关闭,无法操作service。bind和unbind可以操作service。
start开启的service,调用者退出后service仍然存在。bind开启的service,调用者退出后,随着调用者销毁。
在整个生命周期内,只有startCommand()能被多次调用。其他方法只能被调用一次。(即只能绑定和解绑一次)
绑定后没有解绑,无法使用stopService()将其停止
如果service已经启动,那么调用startService()将只调用startCommand()方法
如果是以bindService开启,那么使用unbindService时就会自动调用onDestroy销毁
8、线程与线程池:
线程sleep和wait的区别?什么情况下会出现线程阻塞?有几种锁?
sleep()方法 和wait()方法的区别:
1、这两个方法来自不同的类,sleep()来自Thread,而wait()来自Object类。
2、sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。
3、wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用(使用范围)。
4、sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常。
5、sleep是Thread类的静态方法。sleep的作用是让线程休眠制定的时间,在时间到达时恢复,也就是说sleep将在接到时间到达事件事恢复线程执行。wait是Object的方法,也就是说可以对任意一个对象调用wait方法,调用wait方法将会将调用者的线程挂起,直到其他线程调用同一个对象的notify或者notifyAll方法才会重新激活调用者。
Sleep状态是指自身调用了sleep方法或者中途有别的线程join到当前线程导致的睡眠状态,要解除这种状态要么是睡眠时间结束,要么是join的线程执行完毕,还可以通过调用interrupt方法来结束睡眠。Sleep不会释放锁。
Wait状态,主要是在多个线程执行同步方法中出现,要唤醒wait状态的线程只能通过别的线程调用notify()或者notifyAll()方法来唤醒wait状态的线程。Wait状态也可以是因为执行当前线程的条件不够,wait也可以设置等待的时间,当时间到达后进行自己唤醒。调用wait方法后会释放锁持有的锁,Sleep不会释放锁。Notify和notifyAll不能指定唤醒某一个线程。Notify和notifyAll只能在被锁的方法块内进行调用,否则会抛异常。
线程阻塞,当有别的线程join到当前线程时,该线程会处于阻塞状态,CPU时间轮换机制也会导致线程阻塞。
锁的种类:
隐式锁 synchronized (我们看不到synchronized获取锁和释放锁的过程,此过程不能被中断)synchronized是可重入锁,内部实现是非公平锁。也称为排它锁。
显示锁 Lock(需要我们自己手动的获取锁和释放锁,此过程可以被中断,即可以尝试去获取锁,在锁和释放锁之间执行语句,有可能抛出异常,抛出异常后就不会执行释放锁,所以一般需要在finally中进行释放锁),Lock锁是一个接口,我们一般使用的是它的实现ReentrantLock(可重入锁),默认的实现是非公平锁,公平锁和非公平锁的区别是按顺序获取锁和非按顺序获取锁。非公平锁的效率比公平锁高,这个涉及到线程的挂起,线程的挂起涉及到CPU的上下文切换。ReentrantLock也是排它锁。
读写锁,写锁是排它锁,读锁不是排它锁。
线程隔离:ThreadLocal进行线程隔离,当有多个线程对一个变量进行访问时,可以通过ThreadLock来进行隔离,即初始化一个ThreadLock并传入初始值,在各个线程调用完后将变化二点值设置进去。
开始一个线程--thread.start();(同一个线程只能调用一次start方法,调用两次会报错)。当我们创建一个线程,直接使用这个线程的实例进行run方法的调用时,此时调用在创建线程实例的线程一般是主线程。只有调用start方法后,run方法的执行才是在我们创建的线程中执行的。
Join();方法的理解,就是加入当前线程,A线程总的需要执行5分钟,B在A执行了2分钟后join进去,B线程执行3分钟,当B线程执行完后再继续执行A线程。
终止一个线程:
thread.stop(立马杀死线程,不管线程的事情有没有做完,不管占据的资源是否释放)
thread.suspend(挂起一个线程,并不会释放资源,拿到锁的话也不会释放锁)
thread.resume(将挂起的线程重新运行起来)
以上几种方法都不建议使用,真正要终止一个线程有如下几种方法,
inturrupt();(中断线程,协作式不是立马中断,在线程内部需要判断isInturrupted()的信号)
Thread.interrupted();(静态方法,判断线程是否被中断了,会同时将中断标识位改写为false)
isInterrupted();(线程是否中断)。
中断一个线程的操作是在线程外部调用Thread类中的inturupt()方法,在线程内部接收isInturrupted信号,通过此信号来结束自身的运行代码。
Android中的线程有:Thread、Runnable、Callback(Callback需要借助FutureTask来包装再交给Thread执行,可以有返回值,返回值通过FutureTask.get()来获取)、AsyncTask、IntentService、HandlerThread。
AsyncTask:的底层是使用线程池(所使用的线程是Callable和FutureTask的结合,内部使用了2个线程池,第一个线程池保证所有的任务都是串行执行,第二个线程池是执行具体的任务),底层也封装了Handler,AsyncTask的四个主要方法,onPreExecute-->doInBackground-->onProgressUpdate-->onPostExecute,这四个方法除了doInBackground在线程池中执行,其他的三个方法都在主线程执行,AsyncTask方法的三个参数分别是要执行任务的输入参数、后台任务执行进度类型、后台任务返回的结果类型。在异步任务执行之前onPreExecute方法会被调用,可以在此方法做一些初始化的工作,onPostExecute是任务执行结果返回回调方法,onProgressUpdate是任务执行进度回调方法,doInBackground是后台执行任务线程。AsyncTask还提供了onCancelled的方法,当任务被取消时会回调此方法,但不会回调onPostExecute方法。AsyncTask必须在主线程创建,AsyncTask的execute方法必须在主线程执行。一个AsyncTask只能执行一次即只能调用一次execute方法,否则会报运行时异常。
AsyncTask优缺点:
优点:AsyncTask是一个轻量级的异步任务处理类,轻量级体现在,使用方便、代码简洁上,而且整个异步任务的过程可以通过cancel()进行控制;
缺点:不适用于处理长时间的异步任务,一般这个异步任务的过程最好控制在几秒以内,如果是长时间的异步任务就需要考虑多线程的控制问题;当处理多个异步任务时,UI更新变得困难。
使用注意事项:
AsyncTask不与任何组件绑定生命周期,在Activity 或 Fragment中使用 AsyncTask时,最好在Activity 或 Fragment的onDestory()调用 cancel(boolean);
若AsyncTask被声明为Activity的非静态内部类,当Activity需销毁时,会因AsyncTask保留对Activity的引用 而导致Activity无法被回收,最终引起内存泄露,最好将AsyncTask声明为Activity的静态内部类
IntentService:是一个服务,系统对其进行封装可以更方便的执行后台任务,内部采用HandlerThread来执行任务,当任务执行完毕后会自动退出。
HandlerThread:是一种具有消息循环的线程,在它的内部可以使用Handler。使用:一个UI线程的Handler、一个HandlerThread、一个使用了HandlerThread线程的Looper对象的内部Handler并重写其handlerMessage方法,在此方法内部进行耗时操作,耗时操作结束后再使用UI线程的Handler发送消息回调到UI线程的handlerMessage方法进行UI方面的操作。
线程池ThreadPoolExecute:
优点:1、重复使用线程池中的线程,避免因线程的创建和销毁所带来的性能开销。
2、能有效控制线程池的最大并发数,避免大量的线程之间相互抢占系统资源导致的阻塞现象。
3、能够对线程进行简单的管理,并提供定时执行及指定时间间隔循环执行。
4种线程池:FixedThreadPool、CachedThreadPool、ScheduledThreadPool、SingleThreadPool,这四种线程池都是直接或间接的通过配置ThreadPoolExecute来实现自身的功能特性。
FixedThreadPoole只有核心线程即核心线程数和最大线程数是一样的,没有超时机制,任务队列也没有大小限制,核心线程是不会被回收的,可以快速响应外界的请求。
CachedThreadPool没有核心线程,最大线程数是int的最大值,空闲线程存活60秒会被回收,队列基本不会满,一有请求就执行了。
ScheduledThreadPool核心线程数是固定的,而非核心线程是没有限制的,非核心线程存活0秒。
SingleThreadPool只有一个核心线程,非核心线程也只有一个,就相当于没有非核心线程,意义在于帮外界处理需要线程同步的问题,将外界的任务统一到一个线程中,使得这些任务之间不需要处理线程同步的问题
自定义线程池其实就是自己去配置ThreadPoolExecute里面的参数从而达到自定义的效果。
当最大线程数已满队列已满时线程池的4种策略:
1、DiscardOldestPolicy:接收新的任务,丢弃阻塞队列中最靠前的任务即最新放入的队列的任务。
2、AbortPolicy:直接抛出异常(默认策略)。
3、CallerRunsPolicy:用调用者所在的线程来执行任务,如果在UI线程出现这种情况会导致ANR的出现。
4、DiscardPolicy:直接丢弃所提交的任务。
线程池的配置:
CPU密集型---配置CPU核心数N+1个核心线程数。
IO密集型----配置CPU核心数2*N个核心线程数。
混合型----尽可能的进行分离。
CPU核心数的获取:Runtime.getRuntime().availableProcessors()
9、进程间的通讯----IPC:
进程间通讯的方式:Intent传递数据、共享文件、SharedPreferences、基于Binder的Messenger和AIDL、ContentProvider、Socket。
序列化和反序列化的方式:Java 实现Serializable接口 Android 实现Parcelable接口
1、通过Intent的进行跨进程数据传输,在Intent中添加Bundle来进行数据的传输,Bundle自身实现了序列化接口,Bundle中的数据类型也必须是实现了序列化的对象。如果A进程的数据经过转换了不能通过Bundle进行传输,则可以在B进程创建一个Service(可以使用IntentService),A进程绑定这个Service,将原始数据交给Service,在Service中进行数据的转换,之后将结果直接交给B进程处理。
2、通过共享文件,A进程将实现了序列化的对象通过输出流写入到一个文件中,文件的格式没有特定的要求,可以是普通文件也可以是XML类型文件,B进程通过输入流去读取这个文件即反序列化从而达到跨进程数据传输的目的。共享文件需要考虑线程同步的问题,在并发中会有问题。
3、SharedPreferences是使用XML文件形式来进行数据存储,系统对他有一定的缓存策略,会存在一个副本,在多进程的情况下会存在多个副本,在此情况下进行数据传输不可靠。
4、Messenger的底层实现也是AIDL,具体使用方法,在B进程创建一个Service,在Service内部写一个静态内部类MessengerHandler实现Handler并重写handlerMessage方法,在Service内部创建一个Messenger对象mMessenger,参数传入MessengerHander对象,在Service的onBind方法中返回通过mMessenger.getBinder();的Binder对象。在A进程进行Service的绑定,通过B进行返回的Binder对象创建Messenger对象,再创建一个Message对象,再Message对象中放入需要传递的数据,再通过Messenger对象进行Message数据的发送。通过Messenger进行跨进程数据传输,数据必须放入Message中。如果需要回复客户端,服务端通过接收到的Message对象的replyTo方法获取客户端的Messenger对象,再通过客户端的Messenger对象发送Message消息,客户端同样需要准备一个Messenger和Handler对象,和服务端的Messenger一样的实现,用来接收服务端的回复消息,此Messenger对象需要在客户端给服务端发送消息的时候放入Message对象的replyTo参数中。
5、AIDL,创建AIDL接口文件、创建AIDL接口方法中使用到的变量AIDL文件并申明为parcelable 类型、创建服务端进程Service对象,并创建AIDL接口的实现类,将AIDL接口实现类在onBind方法中返回给客户端、客户端绑定服务端的Service并通过返回的Binder(AIDL接口实现类)对象调用AIDL接口方法、如果需要服务端给客户端回调还需要进行注册与反注册操作,需要用到一个特殊的容器RemoteCallbackList进行监听器的保存、如果是耗时操作发起调用的方法都能不能在UI线程中发起、AIDL接口中所有用到的包需要显示导入、服务端和客户端所有和AIDL文件有关的类需要放在包名相同的路径下,这样才能保证反序略化成功、保证服务的安全还需要权限的验证,可以在onBind的方法中进行验证也可以在AIDL接口中的onTransact方法中验证包名类名,权限需要进行自定义。
6、ContentProvider底层实现也是Binder,写一个类继承ContentProvider,重写onCreate、query、insert、delete、update、getType总共6个方法。ContentProvider需要在Manifest中配置,配置name、authorities(uri)、permission、process配置信息。客户端通过getContentResolver获取ContentProvider的代理对象(类似代理模式)调用其里面的增删改查方法,传入Uri参数。
7、Socket是基于TCP链接来实现的,在服务端创建一个Service,在Service中开启一个线程用于创建服务端的ServerSocket用于接收客户端的请求链接,监听相关的端口和host地址,通过accept接收到客户端的Socket对象,再通过此Socket对象的输入输出流来读取客户端的消息和发送消息给客户端。客户端创建Socket对象,再去链接服务端的Socket地址,再通过自己的Socket对象的输入输出流获取服务端返回的信息和发送消息给服务端。最后都需要进行流的关闭和Socket链接的关闭操作。
8、Binder连接池:使用Binder连接池可以有效的实现一个Service完成N个AIDL接口对应的IBinder对象的处理。共有A、B、IBinderPool三个AIDL接口,一个Service,一个BinderPool处理类,在IBinderPool的AIDL接口中定义一个返回IBinder对象参数为binderCode的接口方法,Service中返回IBinderPool类型的IBinder对象,在BinderPool处理类中进行Service的绑定,客户端拿到BinderPool管理类的实例,调用其查询IBinder对象的方法获取对应的IBinder对象,通过此IBinder对象调用asInterface方法获得对应的AIDL接口对象,再调用相应的AIDL接口方法。
10、Activity的启动模式:
Standard:这个模式是默认的启动模式,即标准模式,在不指定启动模式的前提下,系统默认使用该模式启动Activity,每次启动一个Activity都会重写创建一个新的实例,不管这个实例存不存在,这种模式下,谁启动了该模式的Activity,该Activity就属于启动它的Activity的任务栈中。这个Activity它的onCreate(),onStart(),onResume()方法都会被调用。
SingleTop:如果此 Activity 还未启动,则开启这个 Activity 时会执行的生命周期方法和 Standard 的模式是一样的。如果此 Activity 已经启动,并且在其栈的栈顶,则再次开启这个 Activity 时会执行此 Activity 的 onPause、onNewIntent、onResume 方法,如果此 Activity 已经启动,但不再其栈的栈顶,则再次开启这个 Activity 时会执行的生命周期方法和 Standard 的模式是一样的。
SingleTask:如果此 Activity 还未启动,则开启这个 Activity 时会执行的生命周期方法和 Standard 的模式是一样的。如果此 Activity 已经启动,并且在其栈的栈顶,则再次开启这个 Activity 时会执行此 Activity 的 onPause->onNewIntent->onResume 方法。如果此 Activity 已经启动,但不再其栈的栈顶,则再次开启这个 Activity 时,会将压在此 Activity 上面的同一个栈的 Activity 全部清除(除了栈顶的Activity,都执行其onDestroy方法)并执行 :(栈顶Activity的onPause)-> onRestart->onStart->onNewIntent->onResume ->(栈顶的onStop->onDestroy) 生命周期方法。注意点:谁启动它,它将和它在同一个栈中(前提条件它们属于同一种类型的栈,standard singleTop singleTask 按照我的理解他们是同一种类型的栈)singleInstance 是别的一种栈,并且它全局只会有一个实例。
SingleInstance:此启动模式是 singleTask 的加强版,拥有 singleTask 的所有特性,新增的特性是具有此种模式启动的 Activity 只能单独的位于一个任务栈中,栈内复用,此后均不会重新创建此 Activity 的实例,除非此栈被销毁,再次启动此 Activity 会执行的生命周期方法为onPause、onNewInstance、onResume。
A启动B :A.onPause->B.onCreate->B.onStart->B.onResume->A.onStop->A.onSaveInstanceState
B返回A:B.onPause->A.onRestart->A.onStart->A.onResume->B.onStop->B.onDestroy
11、Fragment生命周期:
onAttach()-->onCreate()-->onCreateView()-->onActivityCreated()-->onStart()-->onResume()
-->onPause()-->onStop()-->onDestroyView()-->onDestroy()-->onDetach()。
12、Java的四种引用:
强引用、软引用、弱引用、虚引用。
强引用:Object obj =new Object();
属于不可回收的资源,垃圾回收器绝不会回收它。当内存空间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠回收具有强引用的对象,来解决内存不足的问题。
软引用: Object obj = new Object();
ReferenceQueue queue = new ReferenceQueue();
SoftReference reference = new SoftReference(obj, queue);
//强引用对象滞空,保留软引用
obj = null;
如果一个对象只具有软引用,那么它的性质属于可有可无的那种。如果此时内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的告诉缓存。软引用可以和一个引用队列联合使用,如果软件用所引用的对象被垃圾回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中。当内存不足时,软引用对象被回收时,reference.get()为null,此时软引用对象的作用已经发挥完毕,这时将其添加进ReferenceQueue 队列中。
弱引用:Object obj = new Object();
ReferenceQueue queue = new ReferenceQueue();
WeakReference reference = new WeakReference(obj, queue);
//强引用对象滞空,保留软引用
obj = null;
如果一个对象具有弱引用,那其的性质也是可有可无的状态。而弱引用和软引用的区别在于:弱引用的对象拥有更短的生命周期,只要垃圾回收器扫描到它,不管内存空间充足与否,都会回收它的内存(弱引用没有被使用就会被回收)。同样的弱引用也可以和引用队列一起使用。
虚引用:Object obj = new Object();
ReferenceQueue queue = new ReferenceQueue();
PhantomReference reference = new PhantomReference(obj, queue);
//强引用对象滞空,保留软引用
obj = null;
虚引用和前面的软引用、弱引用不同,它并不影响对象的生命周期。如果一个对象与虚引用关联,则跟没有引用与之关联一样,在任何时候都可能被垃圾回收器回收。虚引用必须和引用队列关联使用,当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会把这个虚引用加入到与之关联的引用队列中程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。如果程序发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
13、TCP和Socket
TCP是面向连接的,全双工的,可靠的流协议,面向字节流。属于传输层协议
UDP是面向无连接的,不可靠的,面向报文,没有拥塞控制的通讯协议
应用层->传输层->网络层->数据链路层
TCP的三次握手:
客户端发送请求建立连接 SYN=1,seq=J
服务端响应确认应答,并且请求建立连接 SYN=1,ACK=1,ack=J+1,seq=K
客户端对服务器请求确认应答 ACK=1,ack=k+1
ack 表示序列号,ACK表示标记位
TCP为什么是三次握手?
TCP是一个可靠的传输协议,主要是为了交换通信的初始序列号 ISN,2次的话无法确认双方的系列号,4次的话第二次和第三次是重复的,可以进行合并。tcp是全双工,为保证传输的可靠性,需要给每次传输的数据段添加序号,那么初始的序列号就是tcp三次握手真正的意义所在,而为了确保交换双方的初始序号,最少需要三次才行。
TCP三次握手存在漏洞,可以进行SYN洪泛攻击,通过伪造的客户端ip地址向服务器发送请求(第一次握手),服务端进行响应(二次握手),但是得不到真实的客户端响应(三次握手),导致服务端资源消耗,主机资源耗尽无法响应真实的客户端。解决方案:1,无效连接监控释放。2采用防火墙机制。
TCP四次挥手:
客户端发送关闭请求
服务端响应客户端的关闭请求
服务端发送关闭请求
客户端发送关闭请求确认
TCP为什么需要四次挥手?
TCP是全双工通信的,意味着客户端和服务端都可以收发消息,客户端发送关闭请求后,服务端需要进行响应,确认收到该消息,但是这只是客户端往服务端消息发送通到关闭,服务端往客户端的发送消息通道未进行关闭,所以服务端同样也需要发送关闭请求将服务端到客户端的消息通道关闭。
TCP可以通过序列号与确认应答提高数据传输的可靠性,比如A发送数据(1-100),B确认应答(下一个是101),如果中间存在丢包的话就会重发。
TCP中有窗口机制,发送方的窗口大小由接收方确认,可以确保数据不丢失,并且控制数据的发送速度。
Socket:
TCP用主机的IP地址加上端口号作为TCP连接的端点,这个端点就叫套接字Socket。客户端使用Socket主要就是创建一个Socket对象传入服务端的ip和端口号,通过该Socket对象拿到输入输出流,就可以向服务端收发数据了。注意发送数据后需要调用flush()方法进行刷新缓冲区,因为TCP中存在一个输入和输出缓冲区。
Socket保持长连接可以使用心跳机制,每隔一段时间(一般是4分钟,移动和联通超时时间都是5min,电信大于28min)向服务端发送一个自定义信息,确保连接存活和有效通信。也就是常说的心跳包。
14、对称加密,非对称加密,Http与Https:
对称加密:对称加密比较简单,就是客户端和服务器共用同一个密钥,该密钥可以用于加密一段内容,同时也可以用于解密这段内容。对称加密的优点是加解密效率高,但是在安全性方面可能存在一些问题,因为密钥存放在客户端有被窃取的风险。对称加密的代表算法有:AES、DES,3DES,RC5,RC6,IDEA,Blowfish等。
非对称加密:非对称加密则要复杂一点,它将密钥分成了两种:公钥和私钥。公钥通常存放在客户端,私钥通常存放在服务器。使用公钥加密的数据只有用私钥才能解密,反过来使用私钥加密的数据也只有用公钥才能解密。非对称加密的优点是安全性更高,因为客户端发送给服务器的加密信息只有用服务器的私钥才能解密,因此不用担心被别人破解,但缺点是加解密的效率相比于对称加密要差很多。非对称加密的代表算法有:RSA、ElGamal,背包算法等。
常用的加密算法:SHA1、AES、RSA、MD5。
http与https的区别:
http协议传输的数据都是未加密的,明文传输导致隐私信息不安全。默认端口是80,http有三大风险(窃听,篡改,冒充),第三方可以获取,修改内容,冒充身份参与通信。
https是安全的超文本传输协议,使用SSL协议对Http协议传输的数据进行加密,保证了会话过程总的安全性。默认端口是443。https为解决三大风险而设计,加密传输,校验机制,配置身份证书CA。
SSL首先对对称加密的秘钥使用公钥进行非对称加密,对传输内容使用对称加密。CA机构通过网站开发者提供的公钥、域名、有效时长等信息来辅助校验。
http请求传输过程:
发送端:应用层(http数据 + TCP首部) -> 传输层(+ IP首部)->网络层(+以太网首部)->数据链路层 --》接收端从数据链路层一层层反向解析
一次完整的http请求过程:
DNS域名解析
三次握手建立TCP连接
客户端向服务器发送请求命令 (Get/域名/http协议版本)
客户端发送请求头信息
服务器对客户端的响应进行应答(协议版本/状态码200/OK)
服务器返回响应头信息
服务器向客户端发送数据
服务器关闭TCP连接
HTTPS单向认证:
客户端发送协议版本/域名/请求类型等信息给服务端
服务端返回证书,协议版本信息,随机数以及服务器公钥给客户端
客户端校验证书是否合法,合法继续,否则警告
客户端发送自己可支持的对称加密方案给服务端,供其选择
服务端选择加密程度高的加密方式
将选择好的加密方案以明文的方式传给客户端
客户端收到加密方式后,产生随机码,作为后面对称加密的秘钥,使用服务端的公钥进行加密,发送给服务端
服务端使用私钥进行解密,获取对称加密的秘钥
双方使用对称加密进行通信,确保通信安全
HTTPS双向认证就是客户端也有一份CA证书,会发送给服务器,服务器会对证书校验获取其公钥,后面使用客户端的公钥将加密方案进行加密发送给客户端,客户端收到后再进行解密。
HTTP版本区别:
HTTP1.0 支持GET,HEAD,POST方法,支持长连接(默认使用短连接)
HTTP1.1 默认支持长连接,新增OPTIONS,PUT, DELETE, TRACE, CONNECT方法
HTTP2.0 多路复用(二进制分帧),头部压缩,随时复位。主要是突破上一代标准的性能限制,改进传输性能,实现低延迟和高吞吐量。
15、ANR相关的日志文件名字:
日志文件地址:在data/anr文件下,文件的名称是traces.txt。
出现ANR的情况:0
1.界面操作按钮的点击等待响应时间超过5秒
2.HandleMessage回调函数执行超过10秒
3.BroadcasterReciver里的onRecive()方法处理超过10秒
4.Service 在20s内无法处理完成
16、内存泄漏检测工具:
内存泄漏:长生命周期的对象持有了短生命周期对象的引用,导致短生命周期的对象没法被回收,导致的内存泄漏。GC的主要战场是在共享内存的堆区
检测工具:AndroidStudio 里面的 profile、MAT、DDMS、Finder_Activity(腾讯内部使用,百度找不到),我们常用的是 profile 和 MAT的结合使用。第三发开源库。
具体使用:
使用Profile工具截取一段时间,然后根据下方窗口heap堆内存查看分配的Allocation空间,点击的话右边窗口Instance View可以看到具体在什么地方使用。可以将hprof文件导出,然后使用sdk目录下platform-tools文件夹下hprof-conv.exe工具进行转换(命令行hprof-conv -z 源文件 目标文件.hprof文件)再放入MAT工具中进行分析。Histogram查看当前程序的所有对象,Dominator Tree查看程序中的大对象。右键进行Merge标签下排除除了强引用的对象。从最底部看起看对象的引用链。
17、Java泛型中super 和 extends的区别:
PECS原则:
如果要从集合中读取类型T的数据,并且不能写入,可以使用 ? extends T通配符(Producer Extends)。
如果要从集合中写入类型T的数据,并且不需要读取,可以使用 ? super T通配符(Consumer Super)。
如果既要存又要取,那就不要使用任何通配符。
18、JVM内存结构,堆和栈的理解:
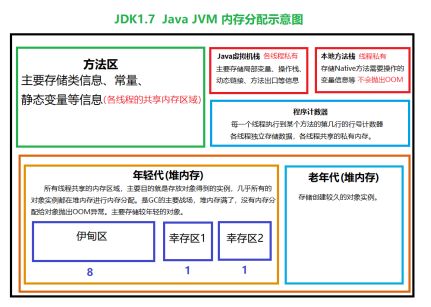
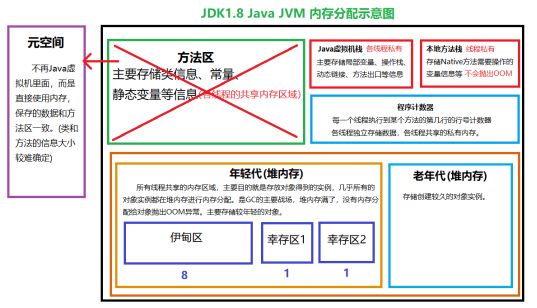
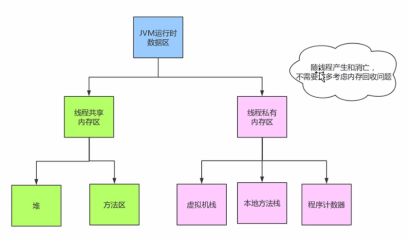
程序计数器:指向当前线程正在执行的字节码指令的地址。为什么需要?Java是多线程的,意味着线程切换,记录地址确保多线程情况下程序的正常执行。
为什么使用栈?栈类似于Java中方法的调用,先进后出FILO,当一个栈帧无限递归调用而没有返回时,超出一定的空间就会报栈内存溢出异常。
每一个方法在执行的同时会创建一个栈帧,栈帧还可以划分为局部变量表,操作数栈,动态连接,返回地址等。如果是在栈上分配,就不需要垃圾回收,线程执行完后就没有了,共享的对象才需要垃圾回收
方法区主要存储静态变量和常量以及类信息(class) 还有即时编译期编译后的代码。
堆:存放几乎所有对象实例以及数组,但是有一种栈上分配,就是开启逃逸分析进行优化之后。
堆可以进一步划分为新生代和老年代,新生代包括Eden空间,From Survivor空间和To Survivor空间。缺省比例为8:1:1
堆内存分配策略:
对象优先在Eden区分配,大对象直接进入老年代,长期存活的对象将进入老年代,动态对象年龄判定,空间分配担保。
GC触发条件:堆内存空间不够了,先进行Minor GC(新生代) 然后是Full GC(老年代)
GC的算法:
1、引用计数法:A===>B,A引用B,B的引用计数就加1,C===>B,B的引用计数就再加1就等于2,当B的引用计数等于0的时候就回收B。
缺点,当A===>B,B===>A当A和B相互引用的时候就不能判断是否能进行回收。
2、可达性算法:对象之间的引用就像一棵树一样,从根节点出发,不可达的对象都是可以回收的。
3、复制回收算法:如果内存有200兆,将其分成两份,第一份进行放对象,当进行GC的时候,将不能被回收的对象复制到第二份中,将第一份中可回收的对象全部回收,不会有内存碎片。缺点:内存只能使用一半。
4、新生代老年代(也属于复制回收算法):新生代的内存空间比例是8:1:1,为什么?90%的对象是不需要进行回收的(朝生夕死),只需要对10%的对象进行回收的,所以用10%的空间来进行新老交替就是复制回收,所以新生代能使用的内存空间就有80%。其中还有一个空间担保机制,就是新生代那边要是放不下了就会放入老年代中。
5、标记清除算法:将内存中能回收的对象进行标记,当GC的时候就直接进行回收,内存使用率能达到100%,不需要进行内存复制。缺点,GC后会导致出现很多不连续的内存块,放不下大的对象,也就会引起内存碎片的问题。
6、标记整理算法:和标记清除算法很相似,只是后面对没有回收的内存进行整理,消除内存碎片的问题,100%内存使用率,需要进行内存复制。效率比标记清除算法低。
哪些对象可以作为GC Root?
- Class系统类加载器加载的对象
- Thread 活着的线程
- Stack Local -Java方法的local变量或参数
- JNI Local -JNI方法的local变量或参数
Java中可作为GcRoot的对象
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 方法区中的类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中JNI引用的对象
7、JDK1.7之后提出了G1
19、static和static final的区别:
static 和 static final哪个执行得到速度比较快?static final 的执行速度比较快,static final 不需要进行编译,直接以二进制的文件保存在dex文件中可以直接进行调用,并不会在类的初始化申请内存,基本数据变量类型可以写成static final 类型,如果是类型变量最好不要写成这样,这样会增加APK包的大小,static 变量会有编译器调用classinit方法进行初始化。
20、优化:
布局优化:
调试GPU过度绘制,将Overdraw降低到合理范围内;减少嵌套层次及控件个数,保持view的树形结构尽量扁平(使用Hierarchy Viewer可以方便的查看),同时移除所有不需要渲染的view
使用GPU配置渲染工具,定位出问题发生在具体哪个步骤,使用TraceView精准定位代码,进行层级的寻找,看是否有能进行合并的层级。
使用标签,merge减少嵌套层次、viewStub延迟初始化、include布局重用 (与merge配合使用)
过度绘制:在自定义View时可能会出现过度绘制,可以对Canves进行图层的保存、切割、恢复操作,从而达到只绘制可见区域的效果。在控件上添加背景会大概率增加过度绘制的问题,可以在application中的theme主题风style中增加”android:windowBackground”标签进行统一的背景颜色设置,减少在每个Activity布局中进行相关的设置。
性能优化:不要再onMeause()、onLayout()、onDraw()方法中去刷新UI---requestLayout(),不要在这些方法中进行一些对象的创建。避免在循环中创建对象,允许复用的情况下,使用对象池进行缓存。
图片压缩:通过NDK编译libjpeg库生成Android中能使用的静态库或动态库,进行相关的API调用实现图片的压缩。也可以通过SDK中提供的api进行图片的压缩。
Apk瘦身:
使用svg图片
国际化资源的配置 build文件下android defaultConfig节点下配置 resConfigs ‘en’
动态so库打包配置build文件下android defaultConfig节点下配置ndk{abiFilters “armeabi-v7a”}
开启代码(代码混淆 minifyEnabled true)和资源压缩(shrinkResources true)
资源文件混淆 微信开源框架AndResGuard
黑白屏启动优化:
黑白屏,可以在app的风格里面进行设置,可以设置为透明,设置为透明的可能导致桌面上点击了APP图标会有几秒钟没有反应,还有一种是将这个透明的或者黑白的界面设置一张图片上去接着再跳到启动界面。这种是假的优化,要是要做真正的优化需要再application的onCreate方法调用之后和第一个Activity的onCreate的方法调用之前进行优化,再application的onCreate方法执行的最前添加Debug.startMethodTracing();方法,和在onCreate的最后面加上Debug.stopMethodTracing();方法获取application的onCreate方法执行时具体的耗时事件在哪边再进行相关的优化,可以开启子线程优化或者在使用到的时候在进行优化。
长图加载优化:
使用BitmapRegionDecoder进行分块加载,获取指定的Rect区域图片
21、静态代理和动态代理的区别:
静态代理:一个具有抽象方法的抽象类或者接口T、一个实现了接口T的真实对象A,具体的操作在A重写的接口方法中实现、一个实现了接口T的代理对象B,对象B持有A对象的引用、客户端通过代理对象B进行调用接口方法,实际上是代理对象B通过持有的A对象调用A实现得到接口方法,在调用A对象的方法前可以做一些代理对象B想要做的事情。静态代理也体现出Java的多态。一个代理类只能代理一个被代理者。
动态代理:一个具有抽象方法的抽象类或者接口T、一个实现了接口T的真实对象A、一个实现了InvocationHandler接口的类,通过Proxy.NewProxyInstance(被代理对象的ClassLoader,接口T,InvocationHandler)方法来创建代理类,中间必然后使用反射,所有的代理类都是Proxy的子类,其实动态代理和静态代理是一样的,只是静态代理为我们需要自己手动创建代理类,而动态代理使用Proxy结合反射来进行代理类的创建。一个动态代理可以实现N个被代理者的代理对象构建,实现被代理者和代理者之间的解耦。创建动态代理类时,需要实现InvocationHandler接口,实现其唯一的invoke()方法。通过Proxy类来创建动态代理类的实例对象,通过该实例对象调用代理方法。通过动态代理JDK自动生成的类,其父类都是Proxy类。Proxy类中有成员变量InvocationHandler h,而自动生成的类中会实现其抽象角色的接口,在实现该接口的方法中调用h.invoke()方法,来实现被代理类的逻辑
22、Android APP的启动流程
MD风格UI的使用及其原理
recyclerView和listView的区别
数据库升级,表增加删减字段的处理、
WebView 调用 webInterface 方法的内部实现,还有什么方法可以进行通讯,在腾讯内部有使用webView的界面都是单独开进程进行跑的。
24、单例设计:
饿汉式:构造方法私有化,内部提供一个静态变量直接new出对象。
懒汉式:构造方法是优化,内部提供一个静态的同步方法进行对象的创建,第一次调用会慢一下。
双重检测DCL:构造方法私有化,内部提供一个静态方法,在方法内进行两次判空,在两次判空操作中间进行同步锁操作。为什么需要进行两次判空操作?Instance = new Singleton()这行代码的执行实际上并不是一个原子操作,这句代码最终会编译成多条汇编指令,还涉及到JVM指令重排的问题,上局代码可以分为三个原子操作,1--给Singleton的实例分配内存,2--调用Singleton的构造方法,3--将Insatnce对象指向分配的内存空间。当1和3执行完了2并未执行完时,切换到B线程去判断Instance不为空,直接将Instance取走,就会出问题,这就是DCL失效问题,这样的问题可以在申明Instance变量的时候加上volatile修饰符,也可以使用静态内部类的单例方式进行处理。
Volatile关键字修饰的变量表示此变量是非常容易变化的即易变的,当我们使用此关键字进行修饰变量时,虚拟机每次读取都会从主内存中进行读取,当有改变时也会及时的将其存入到主内存中,但volatile并不能保证是原子操作。Java线程在工作中会直接访问工作内存,工作内存的数据从主内存读取,这就是工作内存和主内存的区别。只要的使用场景是一个变量多读一写的情况下。
静态内部类:构造方法私有化,内部提供一个静态内部类,静态内部类中提供一个静态对象直接去new外部类。这种方式不仅线程安全,也能保证单例对象的唯一性。(静态内部类不持有我外部类的引用,非静态内部类持有)
枚举单例:
使用容器实现单例:将单例对象统一保存到容器中,要使用的时候直接在容器中拿。
25、MD风格UI使用:
ConstraintLayout--约束布局,其基本属性介绍https://juejin.im/post/5bac92f2f265da0aba70c1bf、CoordinatorLayout、AppBarLayout、Toolbar、TableLayout、Behavior(自定义Behavior)
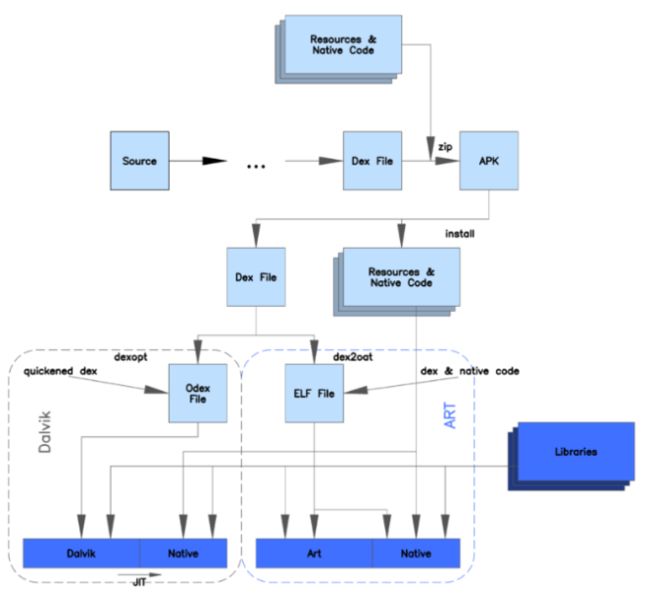
26、ClassLoader:JVM加载的是.class文件,Android的Dalvik加载的是.dex文件,对 dex 文件进行验证和优化的操作,其对dex文件的优化结果变成了odex(Optimized dex)文件,这个文件和dex文件很像,只是使用了一些优化操作码。安卓在5.0以后默认增加了ART(AndroidRunTime安卓预编译机制),在安装时对dex文件执行dexopt优化之后再将odex进行AOT 提前编译操作,编译为OAT(实际上是ELF文件)可执行文件(机器码)。(相比做过ODEX优化,未做过优化的DEX转换成OAT在APP安装的时候要花费更长的时间)。
任何一个 Java 程序都是由一个或多个 class 文件组成,在程序运行时,需要将 class 文件加载到 JVM 中才可以使用,负责加载这些 class 文件的就是 Java 的类加载机制。ClassLoader 的作用简单来说就是加载 class 文件,提供给程序运行时使用。每个 Class 对象的内部都有一个 classLoader 字段来标识自己是由哪个 ClassLoader 加载的。
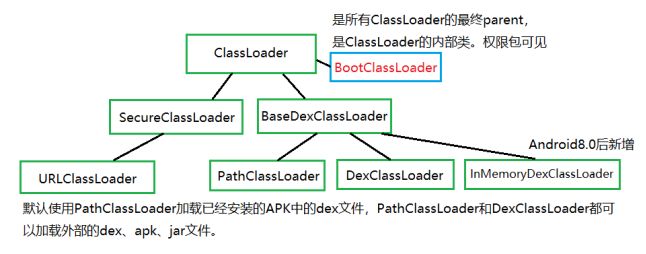
BootClassLoader: 用于加载Android Framework层class文件。
PathClassLoader: 用于Android应用程序类加载器。可以加载指定的dex,以及jar、zip、apk中的classes.dex。
DexClassLoader: 用于加载指定的dex,以及jar、zip、apk中的classes.dex。
PathClassLoader和DexClassLoader的区别:两者唯一的区别在于:创建DexClassLoader需要传递一个optimizedDirectory参数,并且会将其创建为File对象传给super,而PathClassLoader则直接给到null。其实optimizedDirectory参数就是dexopt的产出目录(odex)。那PathClassLoader创建时,这个目录为null,就意味着不进行dexopt?并不是,optimizedDirectory为null时的默认路径为:/data/dalvik-cache。
双亲委托机制:某个类加载器在接到加载类的请求时,首先将加载任务委托给父类加载器,依次递归,如果父类加载器可以完成类加载任务,就成功返回,只有父类加载器无法完成此加载任务时,才自己去加载。
热修复:因此实际上,一种热修复实现可以将出现Bug的class单独的制作一份fix.dex文件(补丁包),然后在程序启动时,从服务器下载fix.dex保存到某个路径,再通过fix.dex的文件路径,用其创建Element对象,然后将这个Element对象插入到我们程序的类加载器PathClassLoader的pathList中的dexElements数组头部。这样在加载出现Bug的class时会优先加载fix.dex中的修复类,从而解决Bug。
热修复需要在application中进行修复(一般不能修复application,参照Tinker可以修复,很麻烦,其余的都能修复),Activity加载后的话就不会重新加载了。
在application中启动另外一个进程,然后创建一个Activity在这个进程中运行,达到后台运行的效果,进而下载补丁包,避免ANR。
DexClassLoader中传入的optimizedDirectory参数,是 dex优化为odex之后保存的目录,必须是私有目录,不能是sd卡的目录。
两个classLoader的区别就是存放odex目录不同,PathClassLoader有一个默认的路径,而DexClassLoader 需要指定一个私有目录下的路径
27、Android的打包流程:
28、RecyclerView:
LayoutManager:负责item的布局方向
RecyclerView.Adapter:为RecyclerView承载数据
ItemDecoration:为RecyclerView添加分割线
ItemAnimator:控制RecyclerView中item的动画
29、Lifecycle:
基本使用一:1-->自己新建一个类ActivityLifecycleOwner实现LifecycleObserver接口,创建一个方法并添加@OnLifecycleEvent注解,在注解中添加你需要监听的生命周期参数。
2-->在Activity的onCreate方法中调用getLifecycle().addObserver(new ActivityLifecycleOwner());方法进行生命周期监听的注册。
3-->当你的Activity执行了相关的生命周期方法时,添加注解的方法将会被调用,在此方法内进行相关对象的释放和别的操作。
4-->当你拿到Activity的实例时,可以调用getLifecycle().getCurrentState();方法来获取当前Activity的生命周期状态,此方法在MVP中的P层进行使用(个人理解)。
5-->这样使用的前提条件是,你的Activity继承的父类实现了LifecycleOwner接口,对于旧版本直接继承Activity我们需要手动实现LifecycleOwner接口,便在onCreate方法中创建LifecycleRegister对象,并在Activity得到每个生命周期方法中进行makeState方法的调用,在getLifecycle方法中返回我们创建的LifecycleRegister对象。
基本使用二:直接在BaseActivity中进行LifecycleObserver接口的实现,在进行注册生命周期监听时直接传入this参数,其他的和基本使用一一至。通过Base来统一管理全局的操作。
原理:在AppCompatActivity中实现了LifecycleOwner接口并创建了LifecycleRegister对象,我们在自己的Activity中实现了LifecyclerObserverOwner接口,将自身注册到LifecycleRegister中,最终调用的地方是ClassesInfoCache中的invokeCallbacks方法,在invokeCallbacks方法中进行反射调用Activity中添加了注解的方法,从而起到生面周期监听的效果。
30、ViewModel、LiveData、DataBind:
ViewMode:在Activity创建的时候进行创建,只有当Activity销毁的时候才会进行清除,在Activity横竖屏旋转的时候,Activity会调用onSaveInstanceState方法,在此方法中将ViewMode进行了保存,在Activity恢复的时候调用onRestoreInstanceState();方法时进行取出,确保Viewmodel的实例还存在。ViewModel的实例创建时通过class.newInstance();方法来进行创建。
LiveData:ViewModel可以结合LiveData使用从而达到自动把数据更新的效果,LiveData其实就是一个观察者模式的实现,去观察这个ViewModel,当ViewMode有数据变化并告诉MutableLiveData时,LiveData调用onChanged();方法来告知观察者。
31、容器
List,Set,Map三者的区别:
- List(对付顺序的好帮手): List接口存储一组不唯一(可以有多个元素引用相同的对象),有序的对象
- Set(注重独一无二的性质): 不允许重复的集合。不会有多个元素引用相同的对象。
- Map(用Key来搜索的专家): 使用键值对存储。Map会维护与Key有关联的值。两个Key可以引用相同的对象,但Key不能重复,典型的Key是String类型,但也可以是任何对象。
集合框架底层数据结构总结:
List:
- Arraylist: Object数组
- Vector: Object数组
- LinkedList: 双向链表(JDK1.6之前为循环链表,JDK1.7取消了循环)
Set
- HashSet(无序,唯一): 基于 HashMap 实现的,底层采用 HashMap 来保存元素
- LinkedHashSet: LinkedHashSet 继承与 HashSet,并且其内部是通过 LinkedHashMap 来实现的。
- TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树。)
Map
- HashMap:
JDK1.8之前HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间 - LinkedHashMap: LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。详细可以查看:《LinkedHashMap 源码详细分析(JDK1.8)》
- Hashtable: 数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
- TreeMap: 红黑树(自平衡的排序二叉树)
HashMap 和 Hashtable 的区别
- 线程是否安全: HashMap 是非线程安全的,HashTable 是线程安全的;HashTable 内部的方法基本都经过synchronized 修饰(要保证线程安全的话就使用 ConcurrentHashMap);
- 效率:因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
- 对Null key 和Null value的支持:HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛出NullPointerException。
- 初始容量大小和每次扩充容量大小的不同 : ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小(HashMap 中的tableSizeFor()方法保证)。也就是说 HashMap 总是使用2的幂作为哈希表的大小。
- 底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制
四种线程安全的HashMap:
- HastTable 采用synchronized方法上加锁,使用阻塞同步,效率低。会将整个map加锁
- collections.synchronizedMap(map) 采用synchronized方法上加锁,使用阻塞同步,效率低。
- CopyOnWriteMap (读写分离思想)java本身并没有提供CopyOnWriteMap,可以自己实现
- ConcurrentHashMap 采用锁分段技术,减小锁的粒度,效率高。ConcurrentHashMap默认将hash表分为16个桶。
== 与 equals
== : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)。
equals() : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
- 情况1:类没有覆盖 equals() 方法。则通过 equals() 比较该类的两个对象时,等价于通过“==”比较这两个对象。
- 情况2:类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来比较两个对象的内容是否相等;若它们的内容相等,则返回 true (即,认为这两个对象相等)。
hashCode 与 equals
hashCode() 的作用就是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 在散列表中才有用,在其它情况下没用。在散列表中hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。
hashCode()与equals()的相关规定
- 如果两个对象相等,则hashcode一定也是相同的
- 两个对象相等,对两个对象分别调用equals方法都返回true
- 两个对象有相同的hashcode值,它们也不一定是相等的
- 因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖
- hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
Java序列化中如果有些字段不想进行序列化,如何做
对于不想进行序列化的变量,使用transient关键字修饰。
synchronized 关键字和 volatile 关键字的区别
- volatile关键字是线程同步的轻量级实现,所以volatile性能肯定比synchronized关键字要好。但是volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块。synchronized关键字在JavaSE1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁和轻量级锁以及其它各种优化之后执行效率有了显著提升,实际开发中使用 synchronized 关键字的场景还是更多一些。
- 多线程访问volatile关键字不会发生阻塞,而synchronized关键字可能会发生阻塞
- volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证。
- volatile关键字主要用于解决变量在多个线程之间的可见性,而 synchronized关键字解决的是多个线程之间访问资源的同步性。
32、RecycleView缓存机制
RecycleView可能会出现复用错乱问题,原因就是我们在请求网络加载图片的时候对RecycleView进行了快速滑动,导致前面复用的条目加载的图片才从服务器返回回来,用这个进行了复用显示在条目上。复用一般复用的都是ViewHolder,所以解决这个的方案就可以设置绑定复用的为一个唯一的标识,比如url的地址,而不是ViewHolder。
RecycleView四级缓存
mChangeScrap与 mAttachedScrap
mCachedViews
mViewCacheExtension
RecycledViewPool
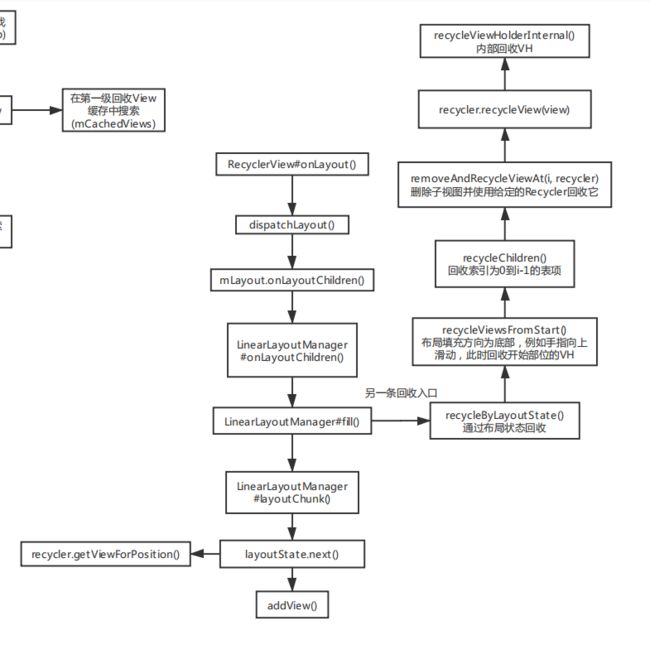
复用机制
- 首先会从 mChangedScrap中进行查找
- 没有找到再从mAttachedScrap中进行查找
- 再没有的话就从缓存中查找mCachedViews
- 从开发者自定义的重用机制中查找
- 从回收池中查找。
1,2,3中如mChangedScrap都是一个ArrayList
2和3会根据不同的方法查找两次,一个是根据positon查找(2中没找到就找3),一个是根据id进行查找。
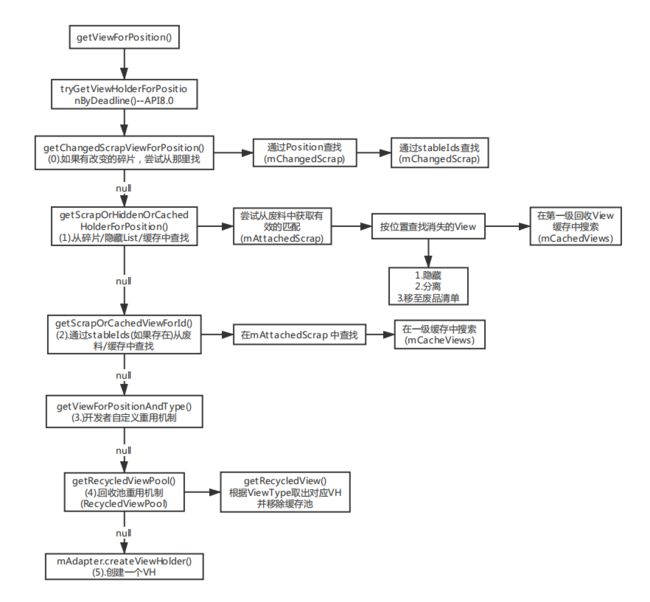
回收机制
回收的话首先会将ViewHolder放入mCachedViews中,其默认大小是2,如果满了就会将最旧的(下标为0的位置)进行移除(先进先出),放入回收池中。回收池默认大小是5,类似于hashmap的存储方式(可以类比为数组存储viewTpye,然后对应的链表存储该ViewType类型的ViewHolder),会根据设置的ViewType的类型进行存储。回收池属于先进后出,当放满之后就不再进行处理了(都是同样的ViewHolder,我的理解是把数据之类的都进行了清除,所以更新不更新就没什么关系了)。所以总缓存的ViewHolder的数量为5n+2,n为ViewType的数量。
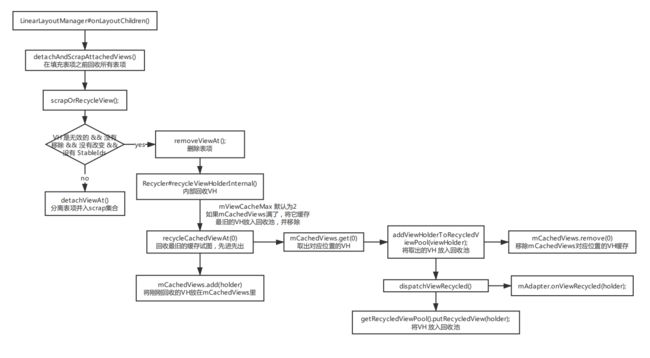
ListView和RecycleView区别:
- ListView 只有两层缓存,但是 RecyclerView有四层;
- ListView 缓存的单位是 view,而 RecyclerView 缓存的单位是 ViewHolder。
- ListView 需要自己在adapter中实现item动画效果,而RecycleView内置许多动画API(notifyItemChanged())
- ListView 本身无法实现局部刷新,需要在adapter中实现一个itemChanged()方法,在其中获取到这个item的position(使用getFirstVisibilePositin()),然后调用getView()方法刷新这个item。RecyclerView可以使用notifyItemChanged()实现局部刷新。
RecycleView复用错乱解决方法
- 数据来源是同步的:
要给每个控件的状态赋值一个新的值,替换掉之前的状态。有if就要有else - 数据来源是异步的:
将imageView和请求的url使用setTag进行绑定。首先在没加载图片之前,给ImageView设置一个默认图片,然后通过setTag方法,将 ImageView和图片的url进行绑定,设置的时候再判断一下,这个 imageview的tag和当时请求的url是不是一致的,如果是一致的,再保存。 - 多布局的,在使用的时候要用getItemViewType进行类型判断
- 插入和删除数据导致错乱,在刷新完后要调用
adapter.notifyItemChanged(posiotn)或者adapter.notifyItemRangeChanged(positionStart,itemCount)刷新position位置。 - 当bindViewHolder没有调用导致错乱时,在给recycleview设置adapter之前调用adapter.setHasStableIds(true),然后在adapter里面重写getItemId(int position),返回position
32、开源框架
okHttp
为什么要用okHttp?
- 请求失败自动重试主机的其它ip,自动重定向
- 默认通过GZip压缩数据
- 响应缓存,避免了重复请求网络
- 支持http/2并允许对同一主机的所有请求共享一个套接字,不需要重复建立TCP连接
- 通过连接池减少请求延迟
使用方法:
// 1. 创建一个OkhttpClient
OkhttpClient client = new OkhttpClient ();
// 2. 创建一个Request
Request request = new Request.Builder()
.url(url)
.build();
// 3.创建一个call对象
Call call = client.newCall(request);
// 4.执行同步请求,获取结果
Response response = call.execute();
// 执行异步请求
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
}
@Override
public void onResponse(Call call, Response response) throws IOException {
}
});
调用流程
OkHttpClient&Builder.build() -> OkHttpClient -> Call[RealCall].execute() -> Dispatcher -> Interceptors -> Response
分发器
Dispatch类中维护了三个队列和一个线程池,最大默认异步请求并发数是64,同一域名的最大请求数是5个
private final Deque readyAsyncCalls = new ArrayDeque<>();
private final Deque runningAsyncCalls = new ArrayDeque<>();
private final Deque runningSyncCalls = new ArrayDeque<>();
//异步请求使用的线程池
private @Nullable ExecutorService executorService;
Q: 如何决定将请求放入ready还是running?
A: 如果当前正在进行的异步请求数不小于64放入ready;如果小于64,但是已经存在同一域名主机的请求5个放入ready!
Q: 从ready移动到running的条件是什么?
A: 每个请求执行完成就会从running移除,同时进行第一步相同逻辑的判断,决定是否移动!
Q: 分发器线程池的工作行为?
A:无等待,最大并发
线程池中核心线程池数为0,线程池不会缓存线程,如果没有网络请求了,这个就不会进行缓存了。
使用的队列为SynchronousQueue,是容量大小为0的队列。这个是希望获得最大并发量,往队列中添加元素都会是失败的,会创建线程去运行,不会进行等待。使用别的队列可能会将后面的请求阻塞。
每执行完一个请求后会调用分发器的finished方法,异步请求会调用
promoteCalls方法,重新调配请求(是否将等待队列中的请求移动到运行队列中交给线程池去运行)
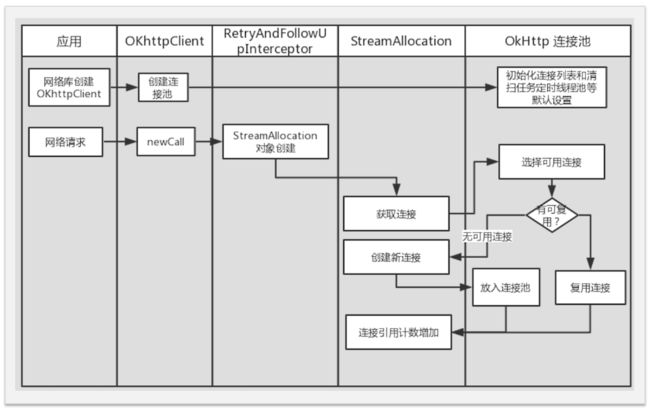
异步请求调用newCall方法会创建一个RealCall对象,调用enqueue方法会调用dispatch的enqueue方法client.dispatcher().enqueue(new AsyncCall(responseCallback));,里面会执行调用promoteAndExecute方法,里面会获取到AsyncCall对象,这个是RealCall的内部类,继承自NamedRunnable(本身就是一个Runnable)。AsyncCall里面的executeOn方法就会去调用线程池的executorService.execute(this);方法,发起网络请求。execute中通过Response response = getResponseWithInterceptorChain();获得响应结果。
拦截器
拦截器的执行流程:
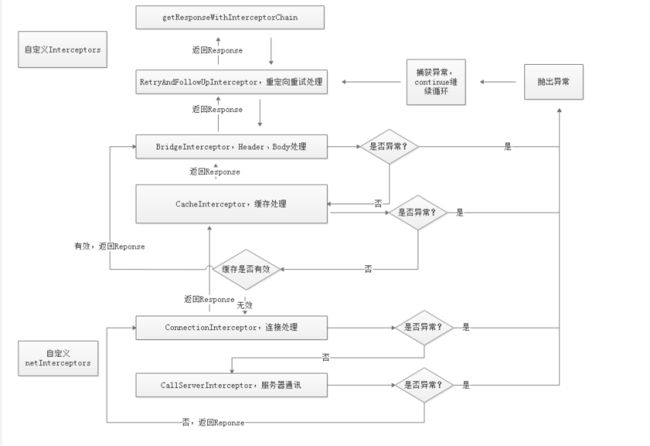
五大拦截器
1、重试拦截器在交出(交给下一个拦截器)之前,负责判断用户是否取消了请求;在获得了结果之后,会根据响应码判断是否需要重定向,如果满足条件那么就会重启执行所有拦截器。
2、桥接拦截器在交出之前,负责将HTTP协议必备的请求头加入其中(如:Host)并添加一些默认的行为(如:GZIP压缩);在获得了结果后,调用保存cookie接口并解析GZIP数据。
3、缓存拦截器顾名思义,交出之前读取并判断是否使用缓存;获得结果后判断是否缓存。
4、连接拦截器在交出之前,负责找到或者新建一个连接,并获得对应的socket流;在获得结果后不进行额外的处理。
5、请求服务器拦截器进行真正的与服务器的通信,向服务器发送数据,解析读取的响应数据。
重试拦截器
RetryAndFollowUpInterceptor重试拦截器默认开启,最大重定向次数为20。允许重试路由或者IO异常,但是如果是协议异常或者证书异常就直接不进行重试了。


桥接拦截器
BridgeInterceptor桥接拦截器在请求前会补全请求头信息,响应后使用GzipSource包装便于解析
对用户构建的Request进行添加或者删除相关头部信息,以转化成能够真正进行网络请求的Request

缓存拦截器
CacheInterceptor缓存拦截器会根据缓存策略CacheStrategy去判断是使用缓存还是去请求网络(只缓存Get请求的响应)

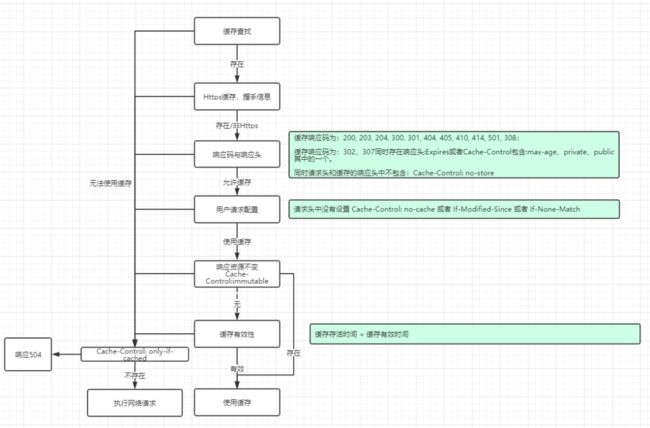
详细流程:
- 判断缓存是否存在
- 如果是Https请求的缓存,但是缓存中没有对应的握手信息,那么缓存无效。
- 根据响应码和响应头判断缓存是否可用
- 获取用户的请求配置,如果用户指定了
Cache-Control:no-cache(不适用缓存)的请求头或者请求头包含If-Modified-Since或If-None-Match(请求验证),那么就不允许使用缓存。 - 判断资源是否不变,如果缓存的响应中包含
Cache-Control: immutable代表响应内容将一直不会改变 - 判断响应缓存的有效期,如果在有效期内就可以使用缓存。(比较复杂,其中涉及按到缓存到现在存活的时间ageMillis,缓存新鲜度-有效时间freshMillis,缓存最小新鲜度minFreshMillis,缓存过期后仍有效时长:maxStaleMillis等判断)
连接拦截器
ConnectInterceptor,打开与目标服务器的连接,并执行下一个拦截器。
RealConnection——封装了Socket与一个Socket连接池
DNS、代理、SSL证书、服务器域名、端口完全相同则可复用连接
请求服务拦截器
CallServerInterceptor,利用Exchange发出请求到服务器并且解析响应生成Response。
Expect: 100-continue请求头(用于上传大容量请求体或者需要验证的情况)。代表了在发送请求体之前需要和服务器确定是否愿意接受客户端发送的请求体。
首先调用exchange.writeRequestHeaders(request); 将请求头写入到缓存中(直到调用flushRequest()才真正发送给服务器)。
- 服务端允许则返回100,客户端继续发送请求体
- 服务端不允许,直接返回用户
- 服务端忽略该请求头,则会一直无法读取应答,抛出超时异常
使用的设计模式
- 建造者模式: OkHttpClient和Request的build
- 门面模式: 由OkHttpClient统一暴露出来
- 责任链模式 :五大构造器使用责任链模式处理自身的逻辑
Retrofit
使用
- 定义一个Api接口
interface WanAndroidApi{
@GET("project/tree/json")
Call getProject();
}
- 使用Retorfit类生成Api接口实现
Retrofit retrofit = new Retrofit.Builder()//建造者模式
.baseUrl("https://www.wanandroid.com/")
.addConverterFactory(GsonConverterFactory.create())
.build();
WanAndroidApi wanAndroidApi = retrofit.create(WanAndroidApi.class);//代理实例
- 发送同步或者异步请求
Call call = wanAndroidApi.getProject();//获取具体的某个业务
//同步请求
Response response = call.execute(); ProjectBean projectBean = response.body();
//异步请求
call.enqueue(new Callback() {
@Override
public void onResponse(final Call call, final Response response) {
Log.i("Steven","response: " + response.body());
}
@Override
public void onFailure(final Call call, final Throwable t) {}
});
注解分类
- 请求方法类:GET,POST,PUT,DELETE,PATCH,HEAD,OPTIONS,HTTP
- 标记类:
- FromUrlEncoded: 表单请求,表示请求实体是一个Form表单,配合@Filed和@FileMap注解使用
- Multipart: 请求参数,表示请求实体是一个支持文件长传的Form表单,需要配合@Part使用,适用于文件上传。
- Streaming: 表示响应体的数据用流的方式返回,适用于返回的数据比较大的情况(下载大文件)
- 参数类:
- Headers 作用于方法,用于添加固定请求头,可以同时添加多个。
- Header 用于添加不固定的请求头,会更新已有请求头
- Body 用于post请求发送非表单数据(如post方式传递json数据)
- Filed 用于post请求中表单字段(Filed和FiledMap需要结合FromUrlEncoded使用)
- FiledMap 接收键值对类型的参数
- Part Part和PartMap与Multipart注解结合使用,适合文件
上传的情况 - PartMap 接收键值对类型参数
- HeaderMap 用于URL,添加请求头
- Path 用于url中的占位符
- Query 用于Get中指定参数
- QueryMap 和Query使用类似,接收的是键值对参数
- Url 指定请求的路径
解析
Retrofit通过create()方法,使用动态代理模式,在InvocationHandler接口的实现方法invoke()中调用loadServiceMethod()方法,通过反射获取method的标注和参数,生成ServiceMethod对象,缓存在serviceMethodCache中。最终通过invoke()调用动态代理类的实现方法。
Retrofit通过build()方法,将用户设置的CallAdapter.Factory添加到callAdapterFactories集合中,然后调用platform.defaultCallAdapterFactories(callbackExecutor)方法添加默认的CallAdapter。创建converterFactories集合,添加new BuiltInConverters()转换器,再将用户设置的Converter.Factory添加进去,最后添加通过platform.defaultConverterFactories()添加一个默认的转换器。最终通过Retrofit的构造方法,创建Retrofit对象。
Platform
Retrofit使用静态内部类Builder时,构造方法会调用Platform.get()方法,通过findPlatform()方法返回对应的平台。同时在build()方法中初始化了defaultCallAdpterFactor工厂。支持Android和Java8。
ServiceMethod
通过接口映射的网络请求对象,通过动态代理,将自定义接口的标注转换为该对象,将标注以及参数生成OkHttp所需要的Request对象。
Call
Retrofit定义网络请求的接口,包含execute,enqueue,cancel等方法。
OkHttpCall
OkHttp的Call的实现,通过createRawCall()方法得到真正的okhttp3.Call对象(通过okhttp3.Call.Factory callFactory工厂调用newCall()方法获取),用于进行实际的网络请求。
CallAdapter.Factory
CallAdapter的静态工厂,包含get的抽象方法,用于生产CallAdapter对象
DefaultCallAdapterFactory
继承自CallAdapter.Factory类的工厂,get方法使用匿名内部类实现CallAdapter,返回
ExecutorCallbackCall,实现了Call
ExecutorCallbackCall
采用静态代理设计,内部变量delegate实际为OkHttpCall,使用callbackExecutor实现回调在主线程中执行
RxJava2CallAdapterFactory
Rxjava平台的CallAdapter工厂,get方法返回RxJavaCall2Adapter对象
RxJava2CallAdapter
Rxjava平台的设配器,返回Observable对象
Converter.Factory
数据解析器工厂,用于生产Converter实例
GsonConverterFactory
数据解析工厂实例,返回了GsonResponseBodyConverter数据解析器
GsonResponseBodyConverter
Gson的数据解析器,将服务端返回的json对象通过输出流转换成对应的java模型
Response
Retrofit网络请求响应的Response
使用的设计模式
- 建造者模式:
Retrofit和ServiceMethod对象的创建都使用Build模式,将复杂对象的创建和表示分离。 - 外观模式(门面模式):由
Retrofit类进行暴露 - 动态代理模式:调用
Retrofit的create()方法时,进行动态代理监听。通过反射解析method的标注和参数,生成ServiceMethod对象 - 静态代理模式:Android平台默认的适配器
ExecutorCallbackCall,具体的实现delegate为OkHttpCall。 - 工厂模式:
Converter和CallAdapter的创建都采用了工厂模式进行创建。 - 适配器模式:
CallAdapter的adapter,是的interface的返回对象可以动态扩展,增强了灵活性。
Glide
ActiveResources 活动资源,记录正在运行的资源,通过弱引用进行管理
内存缓存MemoryCache接口的实现LruResourceCache继承自LruCache,使用Lru算法进行缓存,会有一个有最大缓存值
LruCache或者DiskLruCache里面会存在LinkedHashMap,实际是通过该map进行管理的,内部有实现访问排序。
在Activity上添加一个空的Fragment来监听Activity的生命周期,不用和别的开源框架一样在onDestroy方法中去移除监听。
调用getRequestManagerFragment()方法通过事务提交,添加fragment,会使用Handler发送消息,目的是为了让fragment马上添加进去,不让它处于排队状态。因为事务的提交也是会通过Handler发送消息的。
图片加载流程:
- APP冷启动首次加载,会去判断磁盘缓存中是否存在,存在的话会读取磁盘缓存中的数据进行展示,并且放入ActiveResources活动缓存中。不存在会进行外部加载(通过网络请求或者加载本地图片),加载成功后会保存到磁盘缓存中,再放入活动缓存中。
- 正常加载图片会先从活动缓存中查找,如果没有再从内存缓存中找,再没有会从此磁盘缓存中查找,再没有会从外部加载。内存缓存中存在,从该缓存加载显示并且移出放入活动缓存中。磁盘缓存中存在,会从该缓存中加载显示并复制到活动缓存中。活动缓存中的图片如果没有使用了,就会放入内存缓存中。
使用了内存缓存为什么还要使用活动缓存?
内存缓存是使用Lru算法管理的,有maxsize最大内存的限制,如果超过这个限制,内部算法会进行回收。(不安全,不稳定)
活动缓存保存正在使用的图片,如果不用了才会进行扫描回收。通过弱引用进行监听管理,没有使用了就进行回收,通过
Engine的监听回调存入到内存缓冲中。存入 移除 非常快。
Glide的资源封装使用到了引用计数的方式。
Java知识
抽象类和接口的区别
- 接口中的方法默认是public的,所有方法在接口中不能有实现(Java8开始接口方法可以有默认实现),抽象类可以有非抽象的方法。
- 接口中的实例变量是final的,而抽象类中的不是。
- 一个类可以实现多个接口,但是只能继承一个抽象类。
- 一个类实现接口必须要实现其所有的方法,而抽象类只需要实现其抽象方法。
注解
元注解
Java中一共有五种元注解:
-
@Retention标识注解的存活时间- RetentionPolicy.SOURCE 只在源码阶段保留,在编译器进行编译时丢弃。
- RetentionPolicy.CLASS 只被保留到编译进行的时候,并不会加载到JVM中
- RetentionPolicy.RUNTIME 保留到程序运行的时候,会被加载进入到JVM中,程序运行时可以获取到。
@Documented与文档相关 能够将注解中的元素包含到JavaDoc中去@Target注解可以应用的地方ElementType枚举中定义了很多种类,比如说可以用到类,接口,枚举,成员变量,方法等。@Inherited继承(并不是注解本身可以继承,注解本身不支持继承) 如果一个超类被@Inherited注解过的注解进行注解的话,那么如果它的子类没有被任何注解应用的话,那这个子类就继承了超类的注解。@Repeatable可重复的 用于注解的值可以同时设置多个。
注解的属性
注解的属性也叫作成员变量,注解只有属性,没有方法。
注解中属性的类型只能是8种基本类型数据加枚举,注解以及它们的数组,String类型。
属性可以有默认值,用default关键字修饰 属性名称后面必须加上小括号()
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Target(ElementType.ANNOTATION_TYPE)
public @interface TestAnnotation1 {
String name() default "名称";
int id();
TestAnnotation test_annotation();
TestAnnotation[] test_annotations();
TestEnum value();
}
注解的提取
通过反射获取。
通过Class对象的isAnnotationPresent(注解名.class)方法判断是否应用了某个注解
再通过getAnnotation(注解名.class)方法来获取Annotation单个对象。或者通过getAnnotations()获取所有的注解。
Class clazz = ExtendAbs.class;
boolean b = clazz.isAnnotationPresent(TestAnnotation.class);
if (b) {
TestAnnotation annotation = clazz.getAnnotation(TestAnnotation.class);
System.out.println("ExtendAbs.main:name = " +annotation.name());
System.out.println("ExtendAbs.main:id = " +annotation.id());
}
Annotation[] annotations = clazz.getAnnotations();
for (int i = 0; i < annotations.length; i++) {
System.out.println(annotations[i]);
}
