第3章 - Java 数组 和 字符串
作者:vwFisher
时间:2019-09-04
GitHub代码:https://github.com/vwFisher/JavaBasicGuide
目录
- 1 数组
- 1.1 一维数组
- 一维数组运行内存例子
- 1.2 二维数组(多维数组同理)
- 二维数组运行内存例子
- 1.3 数组-常见操作(详细见程序的demo)
- 1.3.3 选择排序(SelectSort)
- 1.3.4 冒泡排序(BubbleSort)
- 1.3.6 折半查找(二分查找 HalfSearch)
- 1.4 byte数组的一些使用
- 1.4.1 byte数组的编解码
- 1.5 Arrays(数组工具类)
- 2 字符串
- 2.1 String类
- 2.2 String的方法
- 2.2.1 字符串连接说明
- 2.2.2 String类intern方法
- 2.3 格式化字符串
- 2.3.1 格式化方法
- 2.3.2 日期格式化
- 2.3.3 时间格式化
- 2.3.4 日期时间组合格式化
- 2.3.5 常规类型格式化
- 2.3.5 System.out.printf
- 2.4 正则表达式
- 2.4.1 判断是否符合正则表达式的方法
- 2.4.2 正则表达式的元字符
- 2.4.3 正则表达式的限定符
- 2.4.4 方括号中元字符的含义
- 2.5 StringBuffer 和 StringBuilder
1 数组
(basic.array.ArrayDemo)
概念: 同一种数据类型的数据集合, 其实数组就是一个容器
好处: 可以自动给数组中的元素从0开始编号, 方便操作这些元素
说明: 数组作为对象允许使用new关键字进行内存分配, 在使用数组之前, 必须首先声明数组变量所属的类型
1.1 一维数组
概念: 一组相同类型数据的集合
语法:
1).数组元素类型 数组名字[] = new 数组元素类型[数组元素个数]
2).数组元素类型[] 数组名字 = new 数组元素类型[数组元素个数]
3).数组元素类型[] 数组名 = new 元素类型[]{元素, 元素, ...};
4).数组元素类型[] 数组名 = {元素, 元素, ...};
int arr[] = new int[5];
int[] arr = new int[5];
// 定义并初始化
int[] arr = new int[]{3, 5, 1, 7};
int[] arr = {3, 5, 1, 7};
说明:
- 数组元素类型: 决定数组的数据类型(Java任意数据类型)
- 数组名字: 合法的标识符
- 符号"[]": 指明该变量是一个数组类型变量, 单个"[]"表示要创建的数组是一维数组
- new: 对数组分配空间的关键字(因为数组是作为对象允许使用new关键字进行内存分配的, 使用new关键字时候, 整数类型默认初始化值为0)
- 数组元素的个数: 指定数组中变量的个数, 即数组的长度
一维数组运行内存例子
(basic.demo08.MemoryDiagram1)
public static void main(String[] args) {
int[] arr = new int[3];
arr[0] = 89;
int[] arr2 = arr;
System.out.println(arr[0]);
arr = null;
}
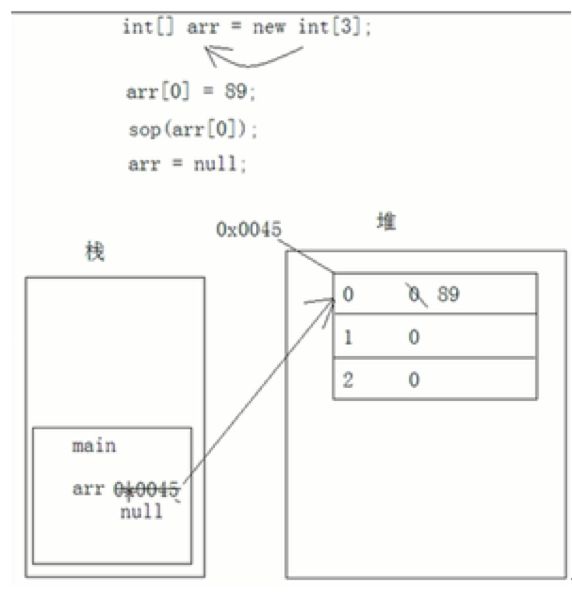
图示说明:
- 主方法main先压栈
- int[] arr: arr压栈
- new int[3]: 放在堆里, 通过new关键字在堆中开辟空间, 内存在存储数据的时候会开辟内存地址(例: 0x0045(16进制)的地址空间, 数组有脚标, 划分3个格子, 每个格子有对应的下标标号, 并默认初始化设置为0)
- 然后对应arr地址就是0x0045, arr就指向该地址的对象数组(这种就叫做引用数据类型(C就叫指针))
- 修改arr指向地址中的下标0的值为89
- 此处不难理解, 当定义int[] arr2 = arr, 实际上就是将arr的指向地址赋给arr2
- 找到arr指向地址中的下标0的值显示
- 当想取消arr的指向, 赋值arr=null
- arr=null之后, Java自动回收机制会不定时的回收垃圾数据
1.2 二维数组(多维数组同理)
概念: 如果一维数组中的各个元素仍然是一维数组, 那么它就是一个二维数组, 常用于表, 第一个下标代表行, 第二个下标代表列
语法:
1).int arr[][] = new int[2][4];
int[][] arr = new int[2][4];
{1}.定义了名称为arr的二维数组
{2}.二维数组中有2个一维数组
{3}.每一个一维数组中有4个元素
{4}.一维数组的名称分别为arr[0], arr[1]
{5}.给第一个一维数组1脚标位赋值位78写法是: arr[0][1] = 78
2).int arr[][] = new int[2][];
int[][] arr = new int[2][];
{1}.二维数组中有3个一维数组
{2}.每个一维数组都是默认初始化值null
{3}.可以对这个三个一维数组分别进行初始化
arr[0] = new int[2]; arr[1] = new int[3];
3).int[][] arr = {{3, 1, 7}, {5, 8, 2, 9}, {4, 1}}
二维数组运行内存例子
(basic.array.MemoryDiagram2)
public static void main(String[] args) {
int[][] arr = new int[3][2];
arr[1][1] = 89;
arr[2][2] = 89; // error
// 分别对二维数组中的每一个小数组进行初始化
int[][] arr2 = new int[3][];
arr2[0] = new int[2];
arr2[1] = new int[1];
arr2[2] = new int[3];
}
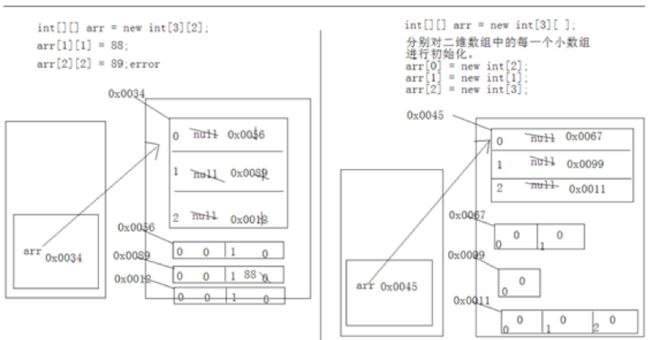
图示说明:
- 主方法main先压栈
- int[][] arr: arr压栈
- new int[3][2]:进堆, 通过new关键字在堆中开辟空间, 如图, 创建地址0x0034指向赋给arr, 然后因为二维数组中就是小地址, 再开辟3个地址, 对应就是小数组的地址
- arr[1][1]=89, 就是先找0x0034, 在找到下标1, 即地址0x0089的下标1赋值88
- arr[2][2]=89, 找到0x0034, 在找0x0012, 但是不存在下标2的对应位置, 所以这段代码报错
1.3 数组-常见操作(详细见程序的demo)
(basic.array.ArrayDemo)
尝试自己实现功能:遍历数组,获取数组最大/小值,基本下标查找
1.3.3 选择排序(SelectSort)
每一趟从待排序的数据元素中选出最小(或最大)的一个元素, 顺序放在已排好序的数列的最后, 直到全部待排序的数据元素排完。
选择排序是不稳定的排序方法, n个记录的文件的直接选择排序可经过n-1趟直接选择排序得到有序结果
1.3.4 冒泡排序(BubbleSort)
冒泡排序是交换排序中一种简单的排序方法. 它的基本思想是对所有相邻记录的关键字值进行比效, 如果是逆顺(a[j]>a[j+1]), 则将其交换, 最终达到有序化. 其处理过程为:
- 将整个待排序的记录序列划分成有序区和无序区, 初始状态有序区为空, 无序区包括所有待排序记录
- 对无序区从前向后依次将相邻记录的关键字进行比较, 若逆序将其交换, 从而使得关键字值小的记录向上"飘浮"(左移), 关键字值大的记录好像石块, 向下"堕落"(右移)
每经过一趟冒泡排序, 都使无序区中关键字值最大的记录进入有序区, 对于n个记录组成的记录序列, 最多经过n-1趟冒泡排序, 就可以将这n个记录重新按关键字顺序排列
【注: 想象轻(小)的浮在上面(左), 重(大)的落在下面(右)】
1.3.6 折半查找(二分查找 HalfSearch)
优点: 比较次数少, 查找速度快, 平均性能好
缺点: 要求待查表为有序表, 且插入删除困难
场景: 不经常变动而查找频繁的有序列表
折半查找法也称为二分查找法, 它充分利用了元素间的次序关系, 采用分治策略, 可在最坏的情况下用O(log n)完成搜索任务.
它的基本思想是, 将n个元素分成个数大致相同的两半, 取a[n/2]与欲查找的x作比较, 如果x=a[n/2]则找到x, 算法终止. 如果x
1.4 byte数组的一些使用
1.4.1 byte数组的编解码
(basic.array.EncodeDemo)
private static String ENCODING_GBK = "GBK";
private static String ENCODING_UTF8 = "UTF-8";
public static void main(String[] args) throws IOException {
String str = "谢谢";
byte[] encodeGbkByte = encodeDemo(str, ENCODING_GBK);
printBytes(encodeGbkByte);
String decodeUtf8 = decodeDemo(encodeGbkByte, ENCODING_UTF8);
System.out.println(decodeUtf8);
byte[] encodeUtf8Byte = encodeDemo(decodeUtf8, ENCODING_UTF8);
printBytes(encodeUtf8Byte);
String decodeGbk = decodeDemo(encodeUtf8Byte, ENCODING_GBK);
System.out.println(decodeGbk);
}
private static byte[] encodeDemo(String str, String charset) {
try {
return str.getBytes(charset);
} catch (Exception e) {
throw new RuntimeException(e.getMessage());
}
}
private static String decodeDemo(byte[] byteArray, String charset) {
try {
return new String(byteArray, charset);
} catch (Exception e) {
throw new RuntimeException(e.getMessage());
}
}
private static void printBytes(byte[] buf) {
for (byte b : buf) {
System.out.print(b + " ");
}
System.out.println();
}
1.5 Arrays(数组工具类)
(basic.demo08.ArraysDemo)
此类包含用来操作数组(比如排序和搜索)的各种方法. 还包含一个允许将数组作为列表来查看的静态工厂.
除非特别注明, 否则如果指定数组引用为 null, 则此类中的方法都会抛出 NullPointerException.
Arrays常用工具类方法归类:大部分方法都含有基础数据的参数,以下省略说明:
- typeAll:byte、short、int、long、float、double、char、Object
- typeBasic:byte、short、int、long、float、double、char
1).排序
void sort(typeAll[] a) // 对指定Object型数组按升序排序
void sort(Object[] a, int fromIndex, int toIndex) // 指定范围排序
void sort(T[] a, Comparator c) // 指定比较器顺序排序
void sort(T[] a, int fromIndex, int toIndex, Comparator c)
void parallelSort(typeBasic[] a) // 并行排序
void parallelSort(typeBasic[] a, int fromIndex, int toIndex)
> void parallelSort(T[] a)
> void parallelSort(T[] a, int fromIndex, int toIndex)
void parallelSort(T[] a, Comparator cmp) // 指定比较器顺序并行排序
void parallelSort(T[] a, int fromIndex, int toIndex, Comparator cmp)
2).搜索
int binarySearch(typeAll[] a, typeAll key) // 使用二分搜索法来搜索指定的下标值
int binarySearch(typeAll[] a, int fromIndex, int toIndex, typeAll key)
int binarySearch(T[] a, T key, Comparator c)
int binarySearch(T[] a, int fromIndex, int toIndex, T key, Comparator c)
3).比较
boolean equals(typeAll[] a, typeAll [] a2) // 如果两个指定的数组彼此相等,则返回 true
4).赋值
void fill(typeAll[] a, typeAll val) // 将指定的值赋值给数组所有元素
void fill(typeAll[] a, int fromIndex, int toIndex, typeAll val)
5).复制
T[] copyOf(T[] original, int newLength) 复制指定的数组, 截取或用null填充(如有必要), 以使副本具有指定的长度
T[] copyOf(U[] original, int newLength, Class newType) 复制指定的数组, 截取或用null填充(如有必要), 以使副本具有指定的长度
T[] copyOfRange(T[] original, int from, int to) 将指定数组的指定范围复制到一个新数组
T[] copyOfRange(U[] original, int from, int to, Class newType)
typeBasic[] copyOf(typeBasic[] original, int newLength) // 复制指定的数组, 截取或用0[注:boolean用false, char用null, 其余用0]填充(如有必要), 以使副本具有指定的长度
typeBasic[] copyOf(typeBasic[] original, int from, int to)
6).Array -> List
List asList(T... a) // 返回一个受指定数组支持的固定大小的列表
7).获取
int hashCode(typeAll[] a) // 基于指定数组的内容返回哈希码
int deepHashCode(Object a[]) // 基于指定数组的"深层内容"返回哈希码
boolean deepEquals(Object[] a1, Object[] a2) // 如果两个指定数组彼此是深层相等的, 则返回true
String toString(typeAll[] a) // 返回指定数组内容的字符串表示形式
String deepToString(Object[] a) 返回指定数组"深层内容"的字符串表示形式
8).其他
void legacyMergeSort(T[] a, int fromIndex, int toIndex, Comparator c)
void parallelPrefix(T[] array, BinaryOperator op)
void parallelPrefix(T[] array, int fromIndex, int toIndex, BinaryOperator op)
void parallelPrefix(long[] array, LongBinaryOperator op)
void parallelPrefix(long[] array, int fromIndex, int toIndex, LongBinaryOperator op)
void parallelPrefix(double[] array, DoubleBinaryOperator op)
void parallelPrefix(double[] array, int fromIndex, int toIndex, DoubleBinaryOperator op)
void parallelPrefix(int[] array, IntBinaryOperator op)
void parallelPrefix(int[] array, int fromIndex, int toIndex, IntBinaryOperator op)
void setAll(T[] array, IntFunction generator)
void parallelSetAll(T[] array, IntFunction generator)
void setAll(int[] array, IntUnaryOperator generator)
void parallelSetAll(long[] array, IntToLongFunction generator)
void setAll(double[] array, IntToDoubleFunction generator)
void parallelSetAll(double[] array, IntToDoubleFunction generator)
Spliterator spliterator(T[] array)
Spliterator spliterator(T[] array, int startInclusive, int endExclusive)
Spliterator.OfInt spliterator(int[] array)
Spliterator.OfInt spliterator(int[] array, int startInclusive, int endExclusive)
Spliterator.OfLong spliterator(long[] array)
Spliterator.OfLong spliterator(long[] array, int startInclusive, int endExclusive)
Spliterator.OfDouble spliterator(double[] array)
Spliterator.OfDouble spliterator(double[] array, int startInclusive, int endExclusive)
Stream stream(T[] array)
Stream stream(T[] array, int startInclusive, int endExclusive)
IntStream stream(int[] array)
IntStream stream(int[] array, int startInclusive, int endExclusive)
LongStream stream(long[] array)
LongStream stream(long[] array, int startInclusive, int endExclusive)
DoubleStream stream(double[] array)
DoubleStream stream(double[] array, int startInclusive, int endExclusive)
2 字符串
2.1 String类
String类即字符串类型(不可变类), 并不是Java的基本数据类型, 但可以像基本数据类型一样使用, 用双引号括起来进行声明. 在Java中用String类的构造方法来创建字符串变量
特点:
- 字符串是一个特殊的对象
- 字符串对象一旦被初始化就不会被改变, 查看源码可以看到定义:
public final class String - 不可变原因,在 String 类中使用 final 关键字修饰字符数组来保存字符串:
private final char value[]
2.2 String的方法
(basic.str.StringDemo, StringMethod)
底层实现: char value[]; 用类型是char的数组来存储数据
String主要方法如下:
1).构造函数
public String() // 初始化一个新创建的String对象, 默认为:""
public String(String original)
public String(char value[])
public String(char value[], int offset, int count)
public String(int[] codePoints, int offset, int count)
public String(byte bytes[], String charsetName) 使用指定的charset解码指定的byte数组
public String(byte bytes[], int offset, int length, String charsetName)
public String(byte bytes[], int offset, int length, Charset charset)
public String(byte bytes[], Charset charset)
public String(byte bytes[], int offset, int length)
public String(byte bytes[])
public String(StringBuffer buffer)
public String(StringBuilder builder)
过时的构造函数:该方法无法将字节正确地转换为字符.从JDK1.1开始, 完成该转换的首选方法是使用带有Charset、字符集名称, 或使用平台默认字符集的String构造方法
public String(byte ascii[], int hibyte, int offset, int count)
public String(byte ascii[], int hibyte)
2).判断
boolean isEmpty() // 当且仅当length()为 0 时返回true
boolean startsWith(String prefix) // 测试此字符串是否以指定的前缀开始
boolean startsWith(String prefix, int toffset) // 同上,区别:从指定索引开始的字符串
boolean endsWith(String suffix) // 测试此字符串是否以指定的后缀结束
boolean matches(String regex) // 测试此字符串是否匹配给定的正则表达式
boolean contains(CharSequence s) // 当且仅当此字符串包含指定的 char 值序列时,返回 true
3).比较
int compareTo(String anotherString) // 按字典顺序比较两个字符串。如:"abc".compareTo("acz") 结果为-1, b与c比,为-1
int compareToIgnoreCase(String str) // 按字典顺序比较两个字符串, 不考虑大小写
boolean equals(Object anObject) // 将此字符串与指定的对象比较(内容)
boolean equalsIgnoreCase(String anotherString) // 忽略大小写比较
boolean contentEquals(StringBuffer sb) // 将此字符串与指定的StringBuffer比较
boolean contentEquals(CharSequence cs) // 将此字符串与指定的CharSequence比较
boolean regionMatches(int toffset, String other, int ooffset, int len) // 测试两个字符串区域是否相等
boolean regionMatches(boolean ignoreCase, int toffset, String other, int ooffset, int len) // 测试两个字符串区域是否相等
4).获取
int length() 返回此字符串的长度
char charAt(int index) 返回指定索引处的char值
int codePointAt(int index) 返回指定索引处的字符(Unicode代码点)
int codePointBefore(int index) 返回指定索引之前的字符(Unicode代码点)
int codePointCount(int beginIndex, int endIndex) 返回此String的指定文本范围中的Unicode代码点数
int offsetByCodePoints(int index, int codePointOffset) 返回此String中从给定的index处偏移codePointOffset个代码点的索引
void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin) 将字符从此字符串复制到目标字符数组
void getBytes(int srcBegin, int srcEnd, byte dst[], int dstBegin) 已过时, 该方法无法将字符正确转换为字节. 从JDK 1.1起, 完成该转换的首选方法是通过getBytes()方法, 该方法使用平台的默认字符集
byte[] getBytes(String charsetName) 使用指定的字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中
byte[] getBytes(Charset charset) 使用给定的 charset 将此 String 编码到 byte 序列, 并将结果存储到新的 byte 数组
byte[] getBytes() 使用平台的默认字符集将此 String 编码为 byte 序列, 并将结果存储到一个新的 byte 数组中
int hashCode() // 返回此字符串的哈希码
int indexOf(int ch) // 返回指定字符在此字符串中第一次出现处的索引
int indexOf(int ch, int fromIndex) // 从指定的索引开始搜索
int indexOf(String str)
int indexOf(String str, int fromIndex)
int lastIndexOf(int ch) 返回指定字符在此字符串中最后一次出现处的索引
int lastIndexOf(int ch, int fromIndex)
int lastIndexOf(String str)
int lastIndexOf(String str, int fromIndex)
String substring(int beginIndex) 返回一个新的字符串, 它是此字符串的一个子字符串
String substring(int beginIndex, int endIndex) 返回一个新字符串, 它是此字符串的一个子字符串
CharSequence subSequence(int beginIndex, int endIndex) 返回一个新的字符序列, 它是此序列的一个子序列
String concat(String str) 将指定字符串连接到此字符串的结尾
String replace(char oldChar, char newChar) 返回一个新的字符串, 它是通过用 newChar 替换此字符串中出现的所有 oldChar 得到的
String replaceFirst(String regex, String replacement) 使用给定的 replacement 替换此字符串匹配给定的正则表达式的第一个子字符串
String replaceAll(String regex, String replacement) 使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串
String replace(CharSequence target, CharSequence replacement) 使用指定的字面值替换序列替换此字符串所有匹配字面值目标序列的子字符串
String[] split(String regex, int limit) 根据匹配给定的正则表达式来拆分此字符串
String[] split(String regex) 根据给定正则表达式的匹配拆分此字符串
String toLowerCase(Locale locale) 使用给定 Locale 的规则将此 String 中的所有字符都转换为小写
String toLowerCase() // 使用默认语言环境的规则将此 String 中的所有字符都转换为小写
String toUpperCase(Locale locale) // 使用给定Locale的规则将所有字符都转换为大写
String toUpperCase() // 使用默认语言环境的规则将此 String 中的所有字符都转换为大写
String trim() 返回字符串的副本,忽略前导空白和尾部空白
String toString() 返回此对象本身(它已经是一个字符串!)
char[] toCharArray() 将此字符串转换为一个新的字符数组
native String intern() 返回字符串对象的规范化表示形式
5).静态方法
static String format(String format, Object... args) 使用指定的格式字符串和参数返回一个格式化字符串
static String format(Locale l, String format, Object... args) 使用指定的语言环境、格式字符串和参数返回一个格式化字符串
static String valueOf(boolean/char/int/long/float/double b) // 返回指定类型参数的字符串表示形式
static String valueOf(Object obj) 返回 Object 参数的字符串表示形式
static String valueOf(char data[]) 返回 char 数组参数的字符串表示形式
static String valueOf(char data[], int offset, int count) // 返回 char 数组参数的特定子数组的字符串表示形式
static String copyValueOf(char data[], int offset, int count) // 返回指定数组中表示该字符序列的 String
static String copyValueOf(char data[]) 返回指定数组中表示该字符序列的 String
static String join(CharSequence delimiter, CharSequence... elements)
static String join(CharSequence delimiter, Iterable elements)
2.2.1 字符串连接说明
连接多个字符串, 两个连接的字符串之间用 +(连接符) 相连, 连接之后生成一个新的字符串。
Java中的字符串不能分开两行中写, 如果一个字符串太长, 需要将这个字符串分在两行上书写, 此时可以使用"+"将两个字符串连起来, 并在加号处换行
在字符串和其他数据类型连接时, 同样使用 + 连接符, 连接之后的返回值是字符串。只要用 + 连接其中一个操作类型是字符串,那么编译器就会将另外的操作类型转换成字符串形式, 所以应谨慎地将其他数据类型与字符串相连
2.2.2 String类intern方法
(basic.str.StringDemo)
如果池中包含一个等于此String对象的字符串, 则返回池中的字符串, 否则将此String对象添加到池中, 并返回此String对象的引用
/**
* public String intern()返回字符串对象的规范化表示形式。
* 如果池中包含一个等于此String对象的字符串,则返回池中的字符串
* 否则将此String对象添加到池中,并返回此String对象的引用
*/
public static void main(String[] args) {
String s0 = "kvill";
String s1 = new String("kvill");
String s2 = new String("kvill");
System.out.println(s0 == s1); //false
s1.intern();
s2 = s2.intern();
System.out.println(s0 == s1); //false
System.out.println(s0 == s1.intern()); //true
System.out.println(s0 == s2); //true
}
2.3 格式化字符串
(示例: basic.str.format.DataFormat, TimeFormat, DateAndTimeFormat, GeneralFormat, SystemOutPrintf)
格式化字符串: 主要包括日期格式化、时间格式化、日期/时间组合的格式化和常规类型格式化
2.3.1 格式化方法
语法:
format(String format, Object... args)
format(Locale locale, String format, Object... args)
- locale:格式化过程要应用的语言环境, 如果l位null, 则不进行本地化
- format: 格式化转换符
- args: 格式化字符串格式说明符引用的参数, 如果还有格式说明符以外的参数, 则忽略这些额外的参数
- 返回值: 一个格式化的字符串
2.3.2 日期格式化
常见的日期格式化转换符
| 转换符 | 说明 | 示例 |
|---|---|---|
| %te | 一个月中的某一天 | 6 |
| %tb | 指定语言环境的月份简称 | Feb(英文), 二月(中文) |
| %tB | 指定语言环境的月份全称 | February(英), 二月(中) |
| %ta | 指定语言环境的星期几简称 | Mon(英), 星期一(中) |
| %tA | 指定语言环境的星期几全称 | Monday(英), 星期一(中) |
| %tc | 包括全部日期和时间信息 | 星期二 三月 25 13:37:22 CST 2008 |
| %tY | 4位年份 | 2008 |
| %ty | 2位年份 | 08 |
| %tm | 月份 | 03 |
| %td | 一个月中的第几天(0~31) | 02 |
| %tj | 一年中的第几天(001~366) | 085 |
2.3.3 时间格式化
常见的时间格式化转换符
| 转换符 | 说明 | 示例 |
|---|---|---|
| %tH | 2位数字的24时制小时(00~23 | 14 |
| %tI | 2位数字的12时制小时(01~12) | 05 |
| %tk | 2位数字的24时制小时(0~23) | 5 |
| %tl | 2位数字的12时制小时(1~12) | 10 |
| %tM | 2位数字的分钟(00~59) | 05 |
| %tS | 2位数字的秒数(00~60) | 12 |
| %tL | 3位数字的毫秒数(000~999) | 920 |
| %tN | 9位数字的微秒数(000000000~999999999) | 062000000 |
| %tp | 指定语言环境下上午或下午标记 | 下午(中), pm(英) |
| %tz | 相对于GMT RFC82格式的数字时区偏移量 | +0800 |
| %tZ | 时区缩写形式的字符串 | CST |
| %ts | 1970-01-01 00:00:00至现在经过的秒数 | 1206426737 |
| %tQ | 1970-01-01 00:00:00至现在经过的毫秒数 | 1206426737453 |
2.3.4 日期时间组合格式化
常见的时间格式化转换符
| 转换符 | 说明 | 示例 |
|---|---|---|
| %tF | "年-月-日"格式(4位年份) | 2008-03-25 |
| %tD | "月/日/年"格式(2位年份) | 03/25/08 |
| %tc | 全部日期和时间信息 | 星期二 三月 25 15:20:00 CST 2008 |
| %tr | "时:分:秒 PM(AM)"格式(12时制) | 03:22:06 下午 |
| %tT | "时:分:秒"格式(24时制) | 15:25:50 |
| %tR | "时:分"格式(24时制) | 15:25 |
2.3.5 常规类型格式化
常见的类型格式化转换符
| 转换符 | 说明 | 示例 |
|---|---|---|
| %b, %B | 结果被格式化为布尔值 | true |
| %h, %H | 结果被格式化为散列码 | A05A5198 |
| %s, %S | 结果被格式化为字符串类型 | "abcd" |
| %c, %C | 结果被格式化为字符类型 | 'a' |
| %d | 结果被格式化为十进制整数 | 40 |
| %o | 结果被格式化为八进制整数 | 11 |
| %x, %X | 结果被格式化为十六进制整数 | 4b1 |
| %e | 结果被格式化为用计算机科学计数法表示的十进制数 | 1.700000e+01 |
| %a | 结果被格式化为带有效位数和指数的十六进制浮点值 | 0X1.C0000000000001P4 |
| %n | 结果为特定平台的行分隔符 | |
| %% | 结果为字面值'%' | % |
| %h, %H | 哈希值 | cd |
2.3.5 System.out.printf
printf格式控制的说明
| 转换符 | 说明 |
|---|---|
| % | 表示格式说明的起始符号, 不可缺少 |
| - | 有-表示左对齐输出, 如省略表示右对齐输出 |
| 0 | 有0表示指定空位置0, 如省略表示指定空位不填 |
| m.n | m指域宽, 即对应的输出项在输出设备上所占的字符串 n指精度, 用于说明输出的实型数的小数位数, 缺省n=6 |
| d格式: 用来输出十进制整数 | |
| %d | 按整型数据的实际长度输出 |
| %md | m为指定的输出字段的宽度, 如果数据位数小于m, 左端补空格, 若大于m, 按实际位数输出, 如: printf("%5d\n", 123) |
| %-md | -代表左对齐, 如果数据位数小于m, 右端补空格, 若大于m, 按实际位数输出, 如: printf("%-5d\n", 123) |
| %05d | 0代表有空位置显示0 如: printf("%05d\n", 123) |
| o格式: 用来输出八进制整数 | |
| %o | 按整型数据的实际长度输出 |
| %mo | m为指定的输出字段的宽度, 如果数据位数小于m, 左端补空格, 若大于m, 按实际位数输出, 如: printf("%5o\n", 123) |
| %-mo | -代表左对齐, 如果数据位数小于m, 右端补空格, 若大于m, 按实际位数输出, 如: printf("%-5o\n", 123) |
| %05o | 0代表有空位置显示0 如: printf("%05o\n", 123) |
| x格式: 用来输出十六进制整数 | |
| %x | 按整型数据的实际长度输出 |
| %mx | m为指定的输出字段的宽度, 如果数据位数小于m, 左端补空格, 若大于m, 按实际位数输出, 如: printf("%5x\n", 123) |
| %-mx | -代表左对齐, 如果数据位数小于m, 右端补空格, 若大于m, 按实际位数输出, 如: printf("%-5x\n", 123) |
| %05x | 0代表有空位置显示0 如: printf("%05x\n", 123) |
| c格式: 用来输出字符 | |
| %c | 输出字符, 如: printf("%c\n", 97) |
| f格式: 用来输出浮点数 | |
| %f | 按浮点数据的输出, 小数默认精确到6位 |
| %m.nf | m为指定的整数部分输出位数,m没啥影响 n为指定的小数部分的输出位数, 四舍五入到精确的位数 |
| %-m.nf | -代表左对齐 |
| e格式: 用来输出浮点数 | |
| %e | 按浮点数据的输出, 小数默认精确到6位 |
| %m.ne | m为指定的整数部分输出位数,m没啥影响 n为指定的小数部分的输出位数, 四舍五入到精确的位数 |
| %-m.ne | -代表左对齐 |
| s格式: 用来输出浮点数 | |
| %s | |
| %ms | |
| %-ms | |
| %m.nf | n代表要输出的长度, 从左到右 |
| %-m.nf | |
| g格式: 用来输出浮点数 | |
| %g | |
| %mg | |
| %-mg | |
| %m.ng | n代表要输出的长度, 从左到右 |
| %-m.ng |
2.4 正则表达式
(basic.str.regex.RegexDemo, RegexCrawler)
2.4.1 判断是否符合正则表达式的方法
为了检查输入的数据是否满足某种格式, 从JDK1.4开始可以使用String类的matches()方法进行判断
语法:boolean matches(String regex)
- regex: 指定的正则表达式
- 返回值: 返回boolean类型
该方法用于告知当前字符串是否匹配参数regex指定的正则表达式, 返回值是boolean类型, 如果当前字符串与正则表达式匹配, 则该方法返回true, 否则返回false
2.4.2 正则表达式的元字符
正则表达式是由一些含有特殊意义的字符组成的字符串, 这些含有特殊意义的字符串称为元字符
元字符 正则表达式中的写法 含义
. "." 代表任意一个字符
\d "\\d" 代表0~9的任何一个数字
\D "\\D" 代表任何一个非数字字符
\s "\\s" 代表空白字符, 如'\t','\n'
\S "\\S" 代表非空白字符
\w "\\w" 代表可用作标识符的字符, 但不包括"$"
\W "\\W" 代表不可用于标识符的字符
\p{Lower} \\p{Lower} 代表小写字母{a~z}
\p{Upper} \\p{Upper} 代表小写字母{A~Z}
\p{ASCII} \\p{ASCII} ASCII字符
\p{Aplha} \\p{Aplha} 字母字符
\p{Digit} \\p{Digit} 十进制数组,即[0~9]
\p{Alnum} \\p{Alnum} 数字或字母字符
\p{Punct} \\p{Punct} 标点符号: !#$%&'()*+,-./:;<=>?@[\]^_`{|}~
\p{Graph} \\p{Graph} 可见字符: [\p{Alnum}\p{Punct}]
\p{Print} \\p{Print} 可打印字符: [\p{Graph}\x20]
\p{Blank} \\p{Blank} 空格或制表符: [\t]
\p{Cntrl} \\p{Cntrl} 控制字符: [\x00~\x1F\x7F]
2.4.3 正则表达式的限定符
在使用正则表达式时, 如果需要某一个类型元字符多次输出, 逐个输入就相当麻烦, 这时可以使用正则表达式的限定元字符来重复次数
限定修饰符 意义 示例
? 0次或1次 A?
(.?) 非贪婪匹配 (.?)
* 0次或多次 A*
+ 1次或多次 A+
{n} 正好出现n次 A{2}
{n,} 至少出现n次 A{3,}
{n,m} 出现n~m次 A{2,6}
2.4.4 方括号中元字符的含义
字符 含义
[abc] 表示 a, b 或 c
[^abc] 表示 a, b, c 之外的任何字符
[a-zA-Z] a~z 或 A~Z 的任何字符
[a-d[m-p]] a~d 或 m~p 的任何字符
[a-z&&[def]] d, e 或 f
[a-z&&[^bc]] a~z 之间不含 b 和 c 的所有字符
[a-z&&[^m-p]] a~z 之间不含 m~p 的所有字符
正则表达式对字符串的常见操作:
- 匹配: 其实使用的就是String类中的matches方法.
- 切割: 其实使用的就是String类中的split方法. 组:((A)(B(C)))
- 替换: 其实使用的就是String类中的replaceAll()方法.
- 获取: 案例: 网页爬虫
将正则规则进行对象的封装
Pattern p = Pattern.compile("a*b");
// 通过正则对象的matcher方法字符串相关联。获取要对字符串操作的匹配器对象Matcher .
Matcher m = p.matcher("aaaaab");
// 通过Matcher匹配器对象的方法对字符串进行操作。
boolean b = m.matches();
String priceStr = "匹配字符串:满 2999 元减 100 元";
Pattern pricePattern = Pattern.compile("[^0-9]+([0-9]+?)[^0-9]+([0-9]+?)[^0-9]+"); // 结果:group(1) = 2999,group(2) = 100
Matcher priceMatcher = pricePattern.matcher(priceStr);
if (priceMatcher.find()) {
System.out.println(priceMatcher.group(1));
System.out.println(priceMatcher.group(2));
}
2.5 StringBuffer 和 StringBuilder
(basic.str.StringBufferDemo, StringBuilderDemo)
StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类
在 AbstractStringBuilder 中也是使用字符数组保存字符串 char[] value,但是没有用 final 关键字修饰,所以这两种对象都是可变的。
StringBuilder 与 StringBuffer 的构造方法都是调用父类构造方法也就是 AbstractStringBuilder 实现的,大家可以自行查阅源码。
AbstractStringBuilder.java
abstract class AbstractStringBuilder implements Appendable, CharSequence {
char[] value;
int count;
AbstractStringBuilder() {
}
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
StringBuffer 和 StringBuilder,常用于 。
特点:
- 长度的可变
- 可以存储不同类型的数据
- 最终要转成字符串进行使用
- 可以对字符串进行修改
- 一般作为 字符串缓冲区。存储数据的容器,具备CRUD功能 C(create) U(update) R(read) D(delete)
1).添加
StringBuffer append(data);
StringBuffer append(StringBuffer sb)
StringBuffer insert(index, data);
2).删除
StringBuffer delete(start, end); // 包含头, 不包含尾
StringBuffer deleteCharAt(int index); // 删除指定位置的元素
3).查找
char charAt(index);
int indexOf(string);
int lastIndexOf(string);
4).修改
StringBuffer replace(start, end, string);
void setCharAt(index, char);
5).其他
length(); // 获取长度
setLength(int length); // 设置长度
reverse(); // 反转显示
toString(); // 字符串格式
StringBuilder 和 StringBuffer 的区别:
- StringBuffer是线程同步的. 通常用于多线程。(源码中可以发现方法带有synchronized关键字)
- StringBuilder是线程不同步的. 通常用于单线程. 它的出现提高效率.
- 在字符串缓存被单个线程使用时要比StringBuffer类快
线程安全性
String 中的对象是不可变的,也就可以理解为常量,线程安全。
AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。
StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
性能
- 每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。
- StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。
- 相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结:
- 操作少量的数据: 适用String
- 单线程操作字符串缓冲区下操作大量数据: 适用StringBuilder
- 多线程操作字符串缓冲区下操作大量数据: 适用StringBuffer