多线程学习-第一天
1 多线程的实现方式
1.1 继承Thread类
通过继承Thread类并重写run方法实现:
public class MyThread1 extends Thread{
@Override
public void run() {
System.out.println(Thread.currentThread() + "run...");
}
}
public class Main {
public static void main(String[] args) {
MyThread1 t1 = new MyThread1();
t1.start();
}
}
1.2 实现Runnable接口
通过继承实现虽然简单但是由于java是单继承的,继承了Thread类就不能继承其他类了,所以一般不使用继承Thread去实现多线程,所以一般使用实现接口的方式,然后通过new Thread(Runnable)创建线程
public class MyRunnableThread implements Runnable{
@Override
public void run() {
System.out.println("Runnable接口实现线程创建...");
}
public static void main(String[] args) {
MyRunnableThread runnableThread = new MyRunnableThread();
Thread t2 = new Thread(runnableThread);
t2.start();
}
}
也可以通过匿名内部类结合lambda表达式实现:
public class MyRunnableThread{
public static void main(String[] args) {
Thread t2 = new Thread(() -> {
System.out.println("Runnable创建线程...");
});
t2.start();
}
}
以上方式使用最多
1.3 实现Callable接口
上面两种方式都无法获得线程的执行结果,所以可以通过实现Callable接口结合Future实现返回值的获取:
public class MyCallableThread implements Callable {
@Override
public Integer call() throws Exception {
System.out.println("Callable创建线程...");
return 0;
}
public static void main(String[] args) throws InterruptedException, ExecutionException {
MyCallableThread callableThread = new MyCallableThread();
FutureTask futureTask = new FutureTask<>(callableThread);
Thread t3 = new Thread(futureTask);
t3.start();
t3.join();
System.out.println(futureTask.get());
}
}
通过lambda表达式创建
public class MyCallableThread{
public static void main(String[] args) throws InterruptedException, ExecutionException {
FutureTask futureTask = new FutureTask<>(() -> {
System.out.println("Callable接口创建线程...");
return 0;
});
Thread t3 = new Thread(futureTask);
t3.start();
t3.join();//等线程t3执行完再执行主线程,保证能get到值
System.out.println(futureTask.get());
}
}
这里使用了FutureTask类我们看看其继承结构

通过图看出FutureTask类可以将Callable封装,而FutureTask类又是一个Runnable,所以可以通过FutureTask来创建线程,下面通过源码分析FutureTask是如何获得Callable的返回结果的
public FutureTask(Callable callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
//run方法
public void run() {
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
Callable c = callable;
//Callable不为空并且状态是NEW
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();//调用call方法,并将结果封装到result
ran = true;//记录执行是否成功
} catch (Throwable ex) {
result = null;//执行失败返回空
ran = false;
setException(ex);
}
//执行成功设置result的值
if (ran)
set(result);
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
//set方法
//通过CAS将设置状态为COMPLETING,如果成功将结果封装到outcome变量中,然后再将state设置为NORMAL
//state状态
//private static final int NEW = 0;新建
//private static final int COMPLETING = 1;完成
//private static final int NORMAL = 2;正常结束
//private static final int EXCEPTIONAL = 3;异常结束
//private static final int CANCELLED = 4;取消
//private static final int INTERRUPTING = 5;中断
//private static final int INTERRUPTED = 6;响应中断
protected void set(V v) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
outcome = v;
UNSAFE.putOrderedInt(this, stateOffset, NORMAL); // final state
finishCompletion();
}
}
以上分析了如何获取返回值,下面看看如何get
public V get() throws InterruptedException, ExecutionException {
int s = state;//获取状态
if (s <= COMPLETING)//如果没完成,等待完成
s = awaitDone(false, 0L);
return report(s);
}
//reports方法
private V report(int s) throws ExecutionException {
Object x = outcome;//获取返回值
if (s == NORMAL)//正常结束直接返回
return (V)x;
if (s >= CANCELLED)//CANCELLED、INTERRUPTING、INTERRUPTED抛出CancellationException异常
throw new CancellationException();
throw new ExecutionException((Throwable)x);
}
1.4 线程池创建
如果使用new线程的方式创建线程,每执行一个任务就创建一个线程,这样会十分消费资源,所以一般使用线程池来创建线程
public class MyThreadExecutor {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(5);
executorService.execute(() -> {
System.out.println("执行线程任务...");
});
}
}
上述是使用Executors框架来创建线程池,创建一个固定数量的线程池,除此之外该工具类还提供很多线程池
newFixedThreadPool(int nThreads) //固定数量线程的线程池
newWorkStealingPool(int parallelism)//通过并发量创建线程池 jdk1.8才有
newSingleThreadExecutor()//单线程化线程池
newCachedThreadPool()//创建一个可缓存的线程池,线程可以重复使用,如果没有就创建一个
newScheduledThreadPool(int corePoolSize)//创建一个定时及周期性执行任务的线程池
下面看看以上线程池的实现
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
这里的线程池的参数下面再说
2 线程池的七大参数
2.1 corePoolSize
核心线程数,以银行服务窗口为例,corePoolSize就是服务窗口的数量
2.2 maximumPoolSize
最大线程数,随着银行中排队的人越来越多,corePoolSize数量的窗口已经无法处理,这时需要另外开maximumPoolSize - corePoolSize 个窗口来应急
2.3 keepAliveTime
核心线程存活时间
2.4 unit
核心线程存活时间单位
2.5 workQueue
阻塞队列,相当于大于corePoolSize时,后面来的线程在队列里排队
2.6 threadFactory
线程工厂,创建线程的工厂默认使用DefaultThreadFactory
2.7 handler
拒绝策略,当队列满了,maximumPoolSize也满了,之后的线程采用拒绝策略进行处理。
线程池的执行过程:
(1) corePoolSize数量的线程直接执行
(2)其他的线程进入阻塞队列中排队等待,当阻塞队列满之后,线程数量如果大于maximumPoolSize则直接执行,如果小于maximumPoolSize将会执行拒绝策略
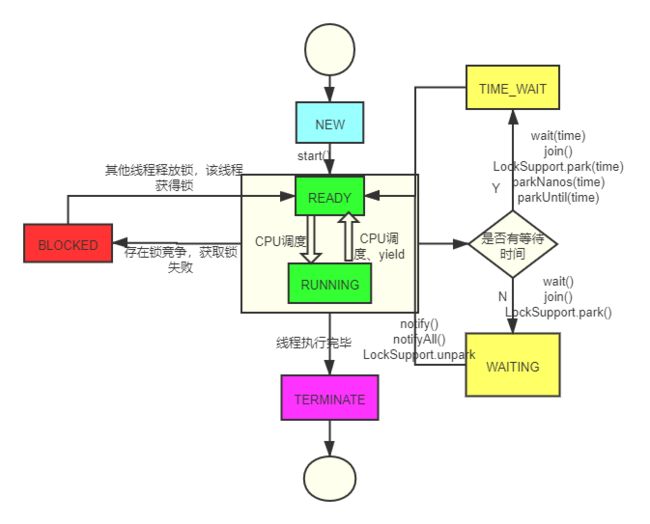
3 线程的状态
线程一共有六种状态分别是:NEW、RUNNABLE、BLOCKED、WAITING、TIME_WAITING、TERMINATED
3.1 NEW
线程初始状态,线程刚刚创建还未调用start方法
3.2 RUNNABLE
运行状态,其中包含就绪和运行,当调用start之后线程进入就绪状态,这时候如果线程获得了CPU资源,,将转为运行状态
3.3 BLOCKED
阻塞状态,线程进入等待状态,放弃CPU资源给其他线程,阻塞分为以下几种情况:
-
等待阻塞
线程运行wait方法,此时放弃CPU资源进入阻塞,JVM将当前线程放入等待队列等待其他线程唤醒
-
同步阻塞
运行的线程获取锁失败时(存在竞争),JVM会将该线程放入锁池中
-
其他阻塞
Thread.sleep()、join方法、发出I/O请求时,JVM会将当前线程设置为阻塞状态,相应方法执行结束线程恢复(不放弃锁)
3.4 WAITING
其他阻塞,等待结束之后继续执行(不释放对象锁)
3.5 TIME_WAITING
超时等待,超时之后自动返回
3.6 TERMINATED
终止状态,线程执行完毕
4 synchronized锁
在jdk1.6之前synchronized是一个重量级锁,而在jdk1.6时底层对synchronized进行了优化
4.1 synchronized用法
synchronized修饰实例方法,要想进入该方法必须先获得该方法的对象锁
synchronized修饰静态方法,要想进入该方法必须先获得该方法所属的类锁
synchronized修饰同步代码块,给指定代码块加锁
4.2 synchronized锁的实现
锁是在对象头中存储的,首先分析对象头信息
在Hotspot虚拟机中,对象在内存中的存储布局分为三个区域:对象头(Header)、实例数据(Instance Data)、对齐填充(Padding)
Mark Word记录了对象和锁有关的信息,Mark Word在32为虚拟机中存储的是32位,在64位虚拟机中存储64位,下面研究32位虚拟机中Mark Word的五种情况

我们可以观察到这里hashCode只有在无锁的情况下存储在对象头中,也就意味着一旦对象计算了hashCode,对象在也不可能成为偏向锁 ,轻量级锁和重量级锁是可以实现的,这个下面再说。
4.3 synchronized锁的升级过程
在JDK1.6之后,系统底层对synchronized关键字做出了优化,引入了偏向锁和轻量级锁的概念,这一引入极大的提高了synchronized锁的性能。所以现在的synchronized锁有四种状态:无锁、偏向锁、轻量级锁、重量级锁。
偏向锁
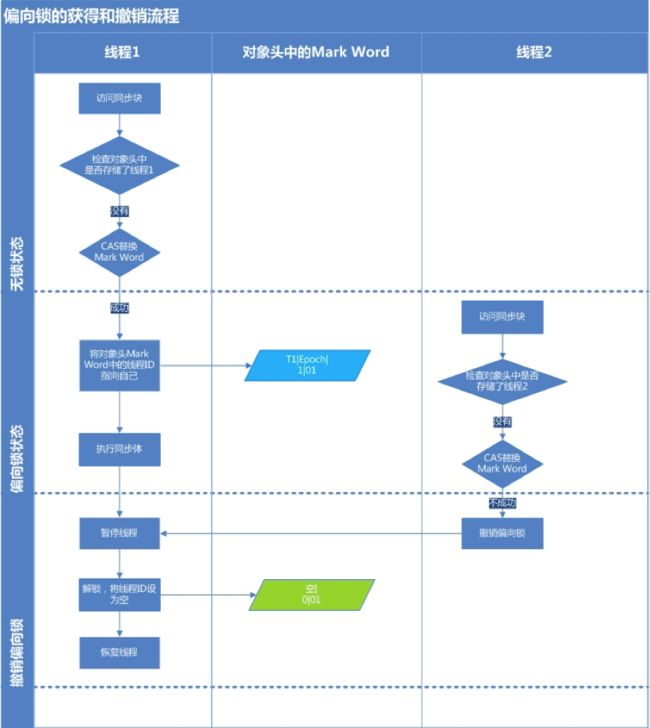
从上面的表格可以看出,偏向锁记录了线程ID,如果该线程再次进入该同步代码块时不需要去获得锁,意味着该锁偏向于该线程。
偏向锁的获取和撤销
1 首先获取锁对象的Mark Word判断是否处于可偏向状态(可偏向标志位为1,线程ID为空)
2 若该对象锁是可偏向状态,则使用CAS将当前线程ID写入锁对象的Mark Word中
2.1 写入成功,表示该线程获得了偏向锁
2.2 写入失败,说明偏向锁已经被其它线程获取,存在竞争,此时需要将偏向锁撤回,将其升级为轻量级锁(这里必须在没有其他线程执行的时候升级)
3 若该对象锁已经是偏向状态(其他线程已经获得了偏向锁)
3.1 若该线程ID与Mark Word中的线程ID相等,该线程可直接进入
3.2 若该线程ID与Mark Word中的线程ID不等,偏向锁撤销,升级成轻量级锁
偏向锁的撤销逻辑
偏向锁的撤销并不是将偏向锁降级成无锁,锁是不存在降级的,偏向锁的撤销直接将偏向锁升级成轻量级锁,这里撤销有两种情况:
1 如果获得偏向锁的线程同步代码块执行完毕,这时候将线程ID置为空,可偏向状态置为0,接着唤醒持有偏向锁的线程,接着执行获取偏向锁逻辑
2 如果获得偏向锁的线程同步代码块未执行完毕,这时候升级为轻量级锁
ps:实际应用中一定存在两个或者两个以上的线程,偏向锁的撤销会增加资源消耗,所以一般关闭偏向锁使用JVM参数UseBiasedLocking设置关闭偏向锁
轻量级锁
当锁存在竞争时,会升级成轻量级锁,此时锁标志位置为00,会采用自旋的方式尝试获得锁
轻量级锁的加锁
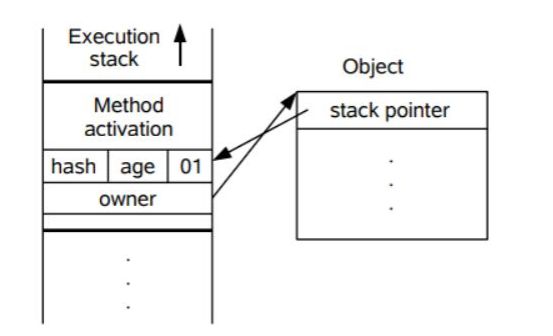
当升级为轻量级锁时,Mark Word也会相应变化,其中过程如下:
1 线程在自己的栈帧中创建LockRecord
2 将Mark Word中的信息(hashCode、分代年龄等)复制到LockRecord中
3 将栈中LockRecord的Owner指针指向锁对象
4 将对象头的Mark Word替换成指向LockRecord的指针

轻量级锁的解锁
轻量级锁的解锁过程和加锁是逆向的,首先使用CAS尝试将LockRecord中的Mark Word信息写回原对象头中,如果成功表示没有竞争,否则失败升级为重量级锁
自旋锁
众所周知,线程从阻塞切换成运行状态需要消耗极大的CPU资源,所以当存在竞争时,不让线程直接阻塞,而是让线程不段尝试获取锁,一旦获取到锁,就避免了线程进入阻塞,这就是自旋锁,就是写一个死循环,一旦CAS获取到锁之后,跳出循环,但是这样会让CPU一直坐着无意义的事情,JDK1.6之前默认自旋次数是10次,如果自旋10次还没有获取到锁,将直接阻塞。JDK1.6做出了优化,提出了自适应自旋锁,可以通过之前锁的状态来自适应自旋次数。也可以使用JVM参数preBlockSpin来修改自旋次数。
重量级锁
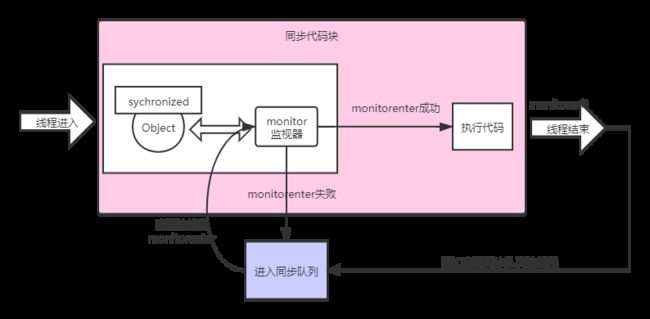
重量级锁主要是通过monitor来实现的,在加入同步代码块后,字节码会在同步代码块前后分别加monitorenter和monitorexit,每一个java对象都有一个monitor监视器与其相关联,当一个线程想要执行一段被synchronized修饰的同步方法或者代码块时,该线程得先获取到synchronized修饰的对象对应的monitor。monitorenter表示去获得一个对象监视器。monitorexit表示释放monitor监视器的所有权,使得其他被阻塞的线程可以尝试去获得这个监视器。
monitor依赖操作系统的MutexLock(互斥锁)来实现的,线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换,严重影响锁的性能。
重量级锁的加锁过程
线程访问synchronized修饰的对象,首先先去获得该对象的监视器monitor,如果获取成功,线程进入synchronized修饰的同步代码块执行,如果获取失败,直接阻塞,并放入同步队列中。
当访问Object的前驱(获得了锁的线程)释放了锁,则该释放操作唤醒阻塞在同步队列中的线程,使其重新尝试对监视器的获取。其流程图如下:
当只有一个线程A进入同步代码块,此时会将锁对象的Mark Word可偏向标志记为1,将线程ID置为空,然后通过CAS将线程A的线程ID记录到Mark Word中,此时如果线程B进入,发现锁是可偏向状态,会用CAS尝试获取,但是由于锁是线程A占有着,所以线程B只能通过自旋的方式尝试获得锁,此时锁取消偏向状态,升级为轻量级锁,一旦自旋还是获取失败,会升级为重量级锁。