现场填坑系列:使用bulk操作提高性能,解决mongoshake 向ES同步延迟。
接到现场报告,MongoDB向ES同步数据延迟越来越大,有的已经超过10个小时,造成客户新加入的用户无法被搜索出来。由于在系统中ES类似于数仓,很多统计和第三方接系统都需要从ES获取数据,所以也影响了一些其他依赖ES数据的功能和业务。
架构简图
tomcat------日志数据----->logstash-------日志数据--->| E S
mongodb---业务数据--->mongoshake---业务数据 -->| 集群
日志通过logstash同步到ES,业务数据通过mongoshake自己实现的ES推送组件推送到ES。ES 5台构成一个集群。
问题现象
- 延迟只发生在第二条通路,第一条通路虽然也有较大并发,但不发生延迟;
- 且延迟在业务峰期才会出现,非高峰期延迟不严重或没有延迟;
- 通过上面的描述可以确定此延迟于业务相关,且与mongoshake推送的实现方式相关;
初步分析
这个结构在两个异地机房各有一套,中间通过同步机制同步。由于业务数据是从本地mongodb同步到本地ES发生延迟,首先排除是双机房间传输带宽问题。
会不会是ES在业务高峰期负载过高,造成推送延迟:可能性有,但是较低,因为如果是ES查询并不慢,且如果是由此造成,logstash 推送也应该受到影响。对ES的性能监控也可以印证这个问题。
会不会是两种数据业务的不同造成的性能差异:logstash的数据主要是日志,插入为主,mongoshake的数据是业务数据,涉及到对以前的数据进行修改:确实有可能,但比较起来延迟不应该有如此之大,一个秒级延迟,一个天级延迟,还是首先考虑实现机制问题。
同步机制
mongoshake向ES同步机制,是将需要在ES存放的几张表的oplog在ES回放,此程序由我们的开发人员扩展的mongoshake ES组件完成。
oplog ----- mongoshake----- oplog replay----->ES
联合高峰期延迟增加的现象,可以猜测高峰期业务数据操作造成的oplog有大量增加,由于mongoshake本身(除非修改源码)只能筛选表,不能筛选哪些表的具体日志,只要是这几张包的oplog都会同步,所以造成延迟。到底是oplog过多需要筛选,还是同步能力太低需要改进,我们需要进一步查证。
推送能力统计
现场人员查看了一段时间的同步量,对现有机制的oplog处理及回放能力进行统计。
第一次统计:130秒同步 2186
第二次统计:180秒同步 2714
可见平均每秒能力不足20条日志,肯定是过低。那么客户现场实际业务每秒到底要产生多少条数据?这个问题要查清楚,作为推送性能优化的底线。
实际业务oplog情况分析
对客户业务能力进行统计,需要将一整天的oplog导出,oplog由于没有索引,虽然可以直接通过find,并给出ts 查询,但由于有40G数据,查询及其缓慢 。所以我们选择将数据导出到文本文件,进行分析
start=$(date +%s -d "2020-03-24 08:00:00")
end=$(date +%s -d "2020-03-24 10:00:00")
mongodump -h localhost -d local -c oplog.rs -q '{"ts":{$gt:Timestamp('$start',1),$lt:Timestamp('$end',1)}}' -o /home/backup
cd /home/backup/local
bsondump oplog.rs.bson > oplog.rs.txt
进一步对oplog进行分析,在vim中分别统计每个小时的日志数量,可以得到下表:横轴是北京时间24个小时,纵轴是oplog数量,其中灰色是oplog中需要同步到ES的
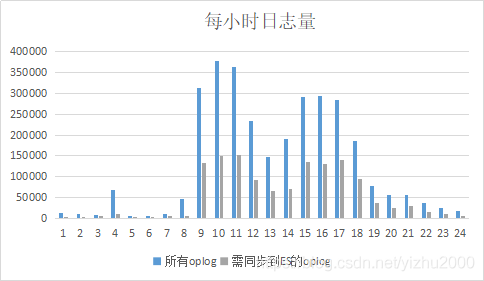
可以看出高峰期oplog大量增长,需要同步的日志超过150000,平均每秒42条oplog需要同步。而处理能力不到20,所以高峰期一个小时的数据往往需要2-3个小时才能同步完成,且从8点开始,一直都下午18点,实际oplog产生都超过处理能力。
往下的优化方向,一个是减少日志,一个是增加处理能力,高峰期每秒42条日志已经不高,虽然可以优化,但可优化范围有限。增加处理能力才是关键。
开发查看ES同步代码,原有代码使用逐条同步模式,同步一条,获取一条,同时采用性能较低的脚本同步方式,现在使用批量处理(实现参照mongoshake 向mongodb同步的 direct writer实现。批量调用elastic Client 提供的bulk api进行操作)
bulkRequest := bw.client.Bulk()
for _, log := range oplogs {
......
bulkRequest.Add(elastic.NewBulkDeleteRequest().Index(index).Type(doc_type).Id(id))
}
bulkResponse, err := bulkRequest.Do(context.Background())
对update 中的unset(删除字段) 进行处理,因为unset执行有速度有瓶颈,所以根据实际情况直接改为将字段置空;
for _, v := range unsets {
doc[v] = nil
}
效果
在进行上述操作后,单线程情况下数据处理的速度超过每秒1000条(未严格测试),新同步代码几分钟就能同步一个小时的oplog,完全达到性能要求。
讨论
oplog优化
由于ES同步性能大幅提高,所以可以不用继续优化oplog,但是oplog可以反映关键业务对数据库的访问情况,特别是写入,在mongodb replica set中只能在primary 节点完成,即使增加节点也无法分担流量,所以对oplog的进一步分析依然必要。同时oplog中包含数量的大小,也对replicaset 的同步带宽有影响,特别是出现跨机房同步的情况时。
所以更进一步,我们还对业务oplog进行了分析,此分析我们会在别的文章中讨论。
多线程执行
注意这里ES同步没有使用多线程处理,主要是考虑业务数据多线程操作的事务性。要实现此种事务,需要对mongodb本身进行一定改造。对mongodb源码改造实现双向同步和多线程写入会在其他文章中讨论。