一 ThreadLocal
ThreadLocal 和 Synchonized 都用于解决多线程并发訪问。可是 ThreadLocal 与 synchronized 有本质的差别。synchronized 是利用锁的机制,使变量或代码块在某一时该仅仅能被一个线程訪问。而 ThreadLocal 为每个线程都提供了变量的副本,使得每个线程在某一时间訪问到的自身线程内部保存的副本变量,这样就隔离了多个线程对数据的数据共享。
ThreadLocal关键方法
- set
public void set(T value) {
Thread t = Thread.currentThread();//每个线程只能获取线程私有的ThreadLocalMap
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
- get
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);//通过key(threadLocal)获取Entry,再获取value
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
- Entry
static class Entry extends WeakReference> {
/** The value associated with this ThreadLocal. */
Object value;
//当key(threadLocal)不再有强引用指向它,此时threadLocal会被gc回收,
//而value是强引用没有被回收,由于key被回收,此时key为null,value无法被
//访问,引起内存泄漏,只有在thread停止退出的时候value才会被释放
//或者是ThreadLocalMap扩容或者缩小容量的时候才会移除key为null的value值
Entry(ThreadLocal k, Object v) {
super(k);//threadlocal弱引用形式保存在entry中
value = v;//value强引用的形式存在于entry中
}
}
- threadLocalMap初始化
ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];//初始容量为16
//通过内存地址和容量大小计算存放数组的位置
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
- ThreadLocalMap重新调整容量
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// expunge entry at staleSlot
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// Rehash until we encounter null
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal k = e.get();
if (k == null) {
e.value = null;//key为null,释放value值
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
二 等待/通知机制(wait/notify)
指一个线程 A 调用了对象 O 的 wait()方法进入等待状态,而另一个线程 B 调用了对象 O 的 notify()或者 notifyAll()方法,线程 A 收到通知后从对象 O 的 wait() 方法返回,进而执行后续操作。上述两个线程通过对象 O 来完成交互,而对象 上的 wait()和 notify/notifyAll()的关系就如同开关信号一样,用来完成等待方和通 知方之间的交互工作。
wait/notify/notifyAll为对象的方法
- notify():
通知一个在对象上等待的线程,使其从 wait 方法返回,而返回的前提是该线程
获取到了对象的锁,没有获得锁的线程重新进入 WAITING 状态。 notifyAll():
通知所有等待在该对象上的线程
- wait()
调用该方法的线程进入 WAITING 状态,只有等待另外线程的通知或被中断
才会返回.需要注意,调用 wait()方法后,会释放对象的锁
- wait(long)
超时等待一段时间,这里的参数时间是毫秒,也就是等待长达 n 毫秒,如果没有 通知就超时返回
- wait (long,int)
对于超时时间更细粒度的控制,可以达到纳秒
等待和通知的标准范式
- 获取对象的锁。
- 如果条件不满足,那么调用对象的 wait()方法,被通知后仍要检查条件。
- 条件满足则执行对应的逻辑
synchronized (obj){
while(condition==false){
obj.wait();//进入等待状态等待其他线程notify重新竞争obj锁,调用该方法回释放锁
}
//todo something
}
通知方遵循如下原则
- 获得对象的锁。
- 改变条件。
- 通知所有等待在对象上的线程
synchronized (obj){
//todo something
obj.notifyAll();//调用该方法回释放锁,一般放在synchronized最后
}
面试题:调用 yield() 、sleep()、wait()、notify()等方法对锁有何影响?
yield() 、sleep()被调用后,都不会释放当前线程所持有的锁。
调用 wait()方法后,会释放当前线程持有的锁,而且当前被唤醒后,会重新 去竞争锁,锁竞争到后才会执行 wait 方法后面的代码。
调用 notify()系列方法后,对锁无影响,线程只有在 syn 同步代码执行完后才 会自然而然的释放锁,所以 notify()系列方法一般都是 syn 同步代码的最后一行
三 线程的并发工具类
Fork-Join
java 下多线程的开发可以我们自己启用多线程,线程池,还可以使用 forkjoin, forkjoin 可以让我们不去了解诸如 Thread,Runnable 等相关的知识,只要遵循 forkjoin 的开发模式,就可以写出很好的多线程并发程序
分而治之
同时 forkjoin 在处理某一类问题时非常的有用,哪一类问题?分而治之的问 题。十大计算机经典算法:快速排序、堆排序、归并排序、二分查找、线性查找、
深度优先、广度优先、Dijkstra、动态规划、朴素贝叶斯分类,有几个属于分 而治之?
3 个,快速排序、归并排序、二分查找,还有大数据中 M/R 都是。
分治法的设计思想是:将一个难以直接解决的大问题,分割成一些规模较小 的相同问题,以便各个击破,分而治之。
分治策略是:对于一个规模为 n 的问题,若该问题可以容易地解决(比如说 规模 n 较小)则直接解决,否则将其分解为 k 个规模较小的子问题,这些子问题 互相独立且与原问题形式相同(子问题相互之间有联系就会变为动态规范算法), 递归地解这些子问题,然后将各子问题的解合并得到原问题的解。这种算法设计 策略叫做分治法。
归并排序
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法 的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使 每个子序列有序,再使子序列段间有序。
若将两个有序表合并成一个有序表,称为 2-路归并,与之对应的还有多路归 并。
对于给定的一组数据,利用递归与分治技术将数据序列划分成为越来越小的 半子表,在对半子表排序后,再用递归方法将排好序的半子表合并成为越来越大 的有序序列。
为了提升性能,有时我们在半子表的个数小于某个数(比如 15)的情况下, 对半子表的排序采用其他排序算法,比如插入排序。
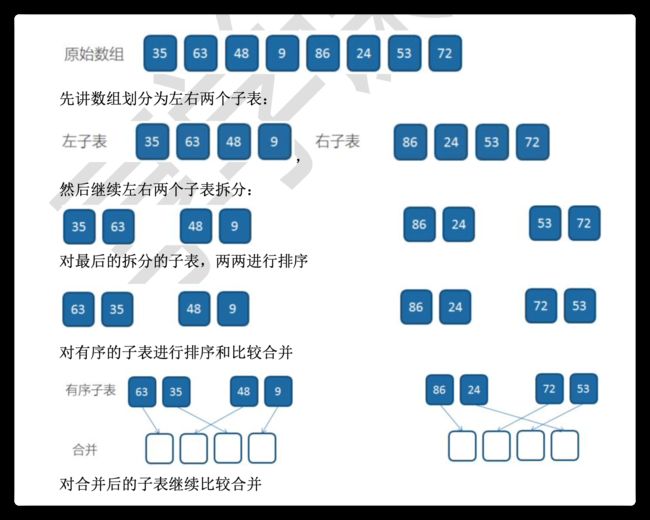 image.png
image.png
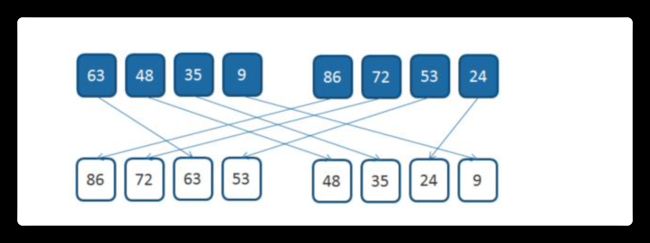 image.png
image.png
Fork-Join 原理
image.png
工作密取
即当前线程的 Task 已经全被执行完毕,则自动取到其他线程的 Task 池中取 出 Task 继续执行。
ForkJoinPool 中维护着多个线程(一般为 CPU 核数)在不断地执行 Task,每 个线程除了执行自己职务内的 Task 之外,还会根据自己工作线程的闲置情况去 获取其他繁忙的工作线程的 Task,如此一来就能能够减少线程阻塞或是闲置的时 间,提高 CPU 利用率。
Fork/Join 使用的标准范式
我们要使用 ForkJoin 框架,必须首先创建一个 ForkJoin 任务。它提供在任务 中执行 fork 和 join 的操作机制,通常我们不直接继承 ForkjoinTask 类,只需要直 接继承其子类
- RecursiveAction,用于没有返回结果的任务
- RecursiveTask,用于有返回值的任务
task 要通过 ForkJoinPool 来执行,使用 submit 或 invoke 提交,两者的区 别是:invoke 是同步执行,调用之后需要等待任务完成,才能执行后面的代码; submit 是异步执行。
join()和 get 方法当任务完成的时候返回计算结果。
求和案例
public class MakeArray {
//数组长度
public static final int ARRAY_LENGTH = 4000;
public static int[] makeArray() {
//new一个随机数发生器
Random r = new Random();
int[] result = new int[ARRAY_LENGTH];
for(int i=0;i{
private final static int THRESHOLD = MakeArray.ARRAY_LENGTH/10;
private int[] src;
private int fromIndex;
private int toIndex;
public SumTask(int[] src, int fromIndex, int toIndex) {
this.src = src;
this.fromIndex = fromIndex;
this.toIndex = toIndex;
}
@Override
protected Integer compute() {
if (toIndex - fromIndex < THRESHOLD){
System.out.println(" from index = "+fromIndex+" toIndex="+toIndex);
int count = 0;
for(int i= fromIndex;i<=toIndex;i++){
SleepTools.ms(1);
count = count + src[i];
}
return count;
}else{
//fromIndex....mid.....toIndex
int mid = (fromIndex+toIndex)/2;
SumTask left = new SumTask(src,fromIndex,mid);
SumTask right = new SumTask(src,mid+1,toIndex);
invokeAll(left,right);
return left.join()+right.join();
}
}
}
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool();
int[] src = MakeArray.makeArray();
SumTask innerFind = new SumTask(src,0,src.length-1);
long start = System.currentTimeMillis();
pool.invoke(innerFind);
//System.out.println("Task is Running.....");
System.out.println("The count is "+innerFind.join()
+" spend time:"+(System.currentTimeMillis()-start)+"ms");
}
}
四 CountDownLatch
闭锁,CountDownLatch 这个类能够使一个线程等待其他线程完成各自的工 作后再执行。例如,应用程序的主线程希望在负责启动框架服务的线程已经启动 所有的框架服务之后再执行。
CountDownLatch 是通过一个计数器来实现的,计数器的初始值为初始任务 的数量。每当完成了一个任务后,计数器的值就会减 1 (CountDownLatch.countDown()方法)。当计数器值到达 0 时,它表示所有的已 经完成了任务,然后在闭锁上等待 CountDownLatch.await()方法的线程就可以恢 复执行任务。
案例
/**
*类说明:演示CountDownLatch用法,
* 共5个初始化子线程,6个闭锁扣除点,扣除完毕后,主线程和业务线程才能继续执行
*/
public class UseCountDownLatch {
//TODO
private static CountDownLatch countDownLatch = new CountDownLatch(6);
private static class InitThread implements Runnable{
@Override
public void run() {
System.out.println("Thread_"+Thread.currentThread().getId()
+" ready init work......");
//TODO
countDownLatch.countDown();
for(int i =0;i<2;i++) {
System.out.println("Thread_"+Thread.currentThread().getId()
+" ........continue do its work");
}
}
}
private static class BusiThread implements Runnable{
@Override
public void run() {
//TODO
for(int i =0;i<3;i++) {
System.out.println("BusiThread_"+Thread.currentThread().getId()
+" do business-----");
}
}
}
public static void main(String[] args) throws InterruptedException {
new Thread(new Runnable() {
@Override
public void run() {
SleepTools.ms(1);
System.out.println("Thread_"+Thread.currentThread().getId()
+" ready init work step 1st......");
//TODO
countDownLatch.countDown();
System.out.println("begin step 2nd.......");
SleepTools.ms(1);
System.out.println("Thread_"+Thread.currentThread().getId()
+" ready init work step 2nd......");
//TODO
countDownLatch.countDown();
}
}).start();
new Thread(new BusiThread()).start();
for(int i=0;i<=3;i++){
Thread thread = new Thread(new InitThread());
thread.start();
}
//TODO
countDownLatch.await();
System.out.println("Main do ites work........");
}
}