在计算机早期的时候,计算机是无法将大于内存大小的应用装入内存的,因为计算机读写应用数据是直接通过总线来对内存进行直接操作的,对于写操作来说,计算机会直接将地址写入内存;对于读操作来说,计算机会直接读取内存的数据。
但是随着软件的不断膨胀和移动应用的到来,一切慢慢变了。
我们想要手机既能够运行微信,同时又能够运行 QQ 音乐,还希望能够聊微博、刷知乎以及看股票。如果我们的手机内存只有 1G,那么显然是无法满足这些应用的,因为微信的后台程序都占用 1G 多内存了。那么就会有人说,把内存容量提高不就行了吗?这句话看似没错,但是内存的造价成本非常昂贵,而且内存的容量是永远追不上应用程序所占用的容量的,把所有应用程序直接堆入内存也只是饮鸩止渴,因为即使是多核线程持续不断的进行计算,也会存在性能瓶颈。
客户都是难搞的,我们并不希望正在使用微信,而后台却运行一些其他没有必要的应用,比如说旅游软件、邮箱等。所以站在用户的角度上来说,线程切换到这些应用上是完全没有必要的。
基于上述这些考量,工程师们认为一直扩大内存容量并不能解决根本问题。
就像是软件架构一样,盲目追求高性能并不一定可取,需要同时兼顾 CAP 的各个原则。
后来,提出了一种虚拟内存(virtual memory)思想,虚拟内存是操作系统的一种抽象,虚拟内存的主要思想是:每个程序都有自己的地址空间,程序间的地址空间彼此不可见,我们的程序首先要先运行在虚拟内存中,虚拟内存会分为多个块,每个块称为一页或者页面(page),每一页有连续的地址范围,这些页会被映射到物理内存,当程序引用到一部分在物理内存的地址空间时,会由硬件完成对应的映射过程,当程序引用到不在物理内存的地址空间时,由操作系统负责将缺失(不在内存)的部分装入物理内存并重新执行。
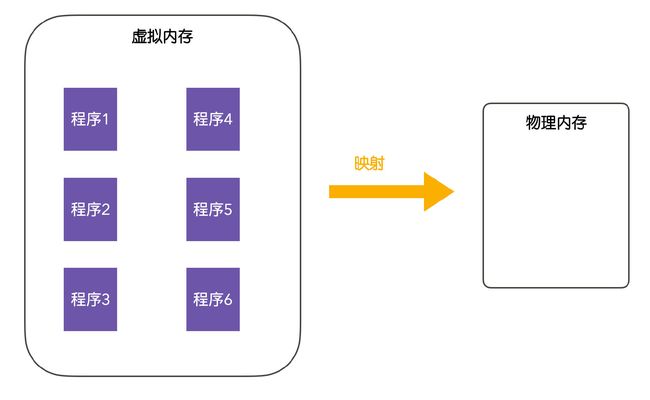
虚拟内存系统是一种管理和分配程序虚拟内存的程序,在使用虚拟内存的情况下,虚拟地址不会直接映射到物理内存中,而是会直接输送到内存管理单元(Memory Management Unit,MMU),由 MMU 将虚拟地址映射为物理内存地址。执行这个映射过程的技术就叫做分页(paging)。
MMU 是一块单独的芯片,它可以独立存在,不过现代 OS 都把它内置在了 CPU 中。
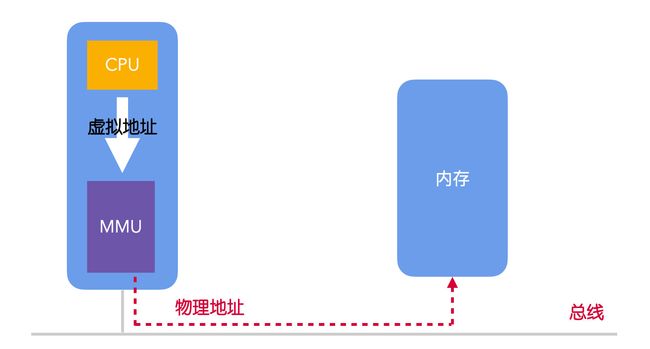
但是,映射到物理内存的哪个位置?映射的规则又是什么?
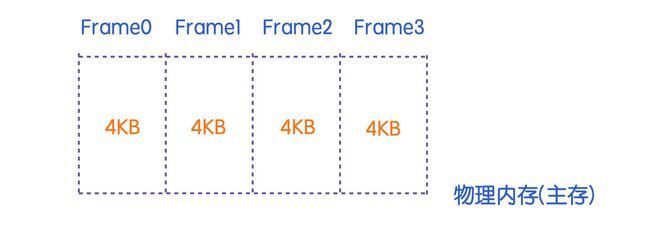
实际上,物理内存的划分其实和虚拟内存是一样的,在物理内存中,也会被划分为一个个的页框(page frame),页框是内存所划分的存储单元,与虚拟内存中的页所不同的是,页框是主存中的物理属性,而页面只是一种虚拟的抽象表示。页面和页框的存储大小通常是一样的,一般是 4KB。
通过 MMU 的帮助,可以有效的将虚拟地址映射到物理内存地址,这也就是说,页面可以和页框进行合理的映射。但是这并没有解决虚拟地址空间比物理内存空间大的这个问题。当 CPU 进行数据写入时,MMU 会判断数据写入的页面是否已经映射到页框中,如果没有映射的话,CPU 会陷入(trap)到操作系统,这个陷入的过程称为缺页中断或者叫做缺页错误(page fault)。
之后,操作系统会找到一个空闲的页框并将它的内容写入到页框中(这个页框其实是在磁盘中,因为操作系统不会一次性把所有的页框都加载到内存中,而是按需加入),然后修改页框和页面的映射关系,再重新启动 trap 陷入的指令。
上面说到,MMU 会判断数据写入的页面是否已经映射到了页框中,这个是如何判断的呢?
实际上,MMU 中有一个叫做页表(page table)的结构,这个页表就记录了页面和页框的映射关系,上面所聊到修改页框和页面的映射关系,实际上就是修改页表中的一个在/不在位的数据项,关于页表的结构,我们后面回说。
下面来看一下页面和页框的映射关系图。
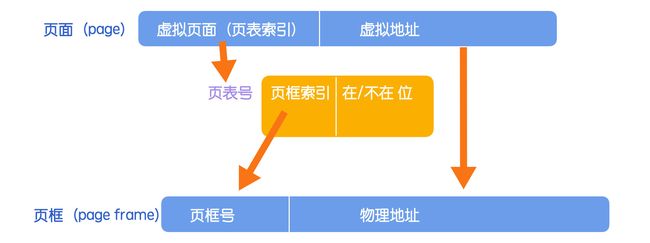
根据页面中的页表索引可以找到对应的页表号,根据页表中的页框索引可以找到页框号,这种映射关系就很类似计算机网络中的路由表(记录各个数据转发路径)。从数学的角度来讲,可以把页表看做是一个函数,它的参数是页表索引(通常也叫做虚拟页号),结果是页框号,通过这个函数可以将虚拟地址中的虚拟页面转换成页框号,然后形成物理地址。
这里强调一点:如果在/不在位是 0 的话,说明该页面和页框没有存在映射关系,此时就会直接引起操作系统陷入,由操作系统找到对应的页框执行写入,写入完成后修改页面和页框的映射关系,然后回到引起陷入的位置继续执行。
上面提到了页表是记录页面和页框映射关系的一个结构,下面我们就来聊一下页表项的结构。不同机器的页表结构是不一样的,但是大多数页表项都具有下面这个结构。

对于页表项这个结构来说,最重要的就是页框号,页框号相当于是页表的身份证,这就跟我们的身份证一样,所以非常重要。
在/不在位我们上面聊过了,这个位就是判断页面和页框有没有进行映射的一项。保护位指出在这个页面上允许什么样的类型访问,是读还是写,一般读是 1,写是 0 ,这是一位的形式,不过还有另外一种形式,是三位,分别对应读、写、执行。修改位用于判断这个页面是否被修改过,在对页面进行写入时会自动设置修改位,如果一个页面已经被修改过,那么必须将它写会磁盘,我们可以认为这个页面是一个脏页。- 无论读写,都会设置
访问位,访问位的意义用来让操作系统淘汰页面所用,没有访问过的页面要比多次访问的页面更容易被淘汰,访问位在页面置换算法中非常有用。 缓存位用于判断是否禁用高速缓存,有的时候 CPU 需要读取最新的用户输入,而不是从高速缓存中读取已有的数据。
聊完页表之后,我们来回顾一下页面到页框的映射过程(上面有写,这里不再阐述了)

思考过后,你会发现,页面到页框的映射过程比较繁琐,又是检索页面、又是操作系统切换、又是内存和磁盘的交互,想必这部分的性能容易出现问题,所以提升这部分的性能就成为了优先级比较高的一个课题。
我们知道,这个映射过程主要是在 MMU 中完成的,所以能不能加快虚拟地址到物理地址的映射速度呢?,而且很多操作系统的虚拟地址空间往往很大,所以需要的页表也会越来越大,那么如何处理日益剧增的页表呢?
首先我们要聊一下的就是如何加快虚拟地址到物理地址的映射速度,加快映射速度有两种方式,一种是使用硬件进行加速,一种是使用软件进行加速。
经过多年的研究表明,大多数程序会对少量的页面进行多次访问,而不会对大量的页面进行多次访问或者访问次数大差不差,因此,只有极少数的页表会被频繁访问,而大多数页面却照顾不到。由于这种局部性原理,使用硬件的方式是设置一个转换检测缓冲区(TLB),它能够直接将虚拟地址映射成为物理地址,而不必再访问页表。
TLB 又叫做快表或者相联存储器。
TLB 可以放在 CPU 和 CPU 缓存(CPU cache)之间,用于缓存虚拟地址,TLB 可以放在 CPU 和 内存之间,用于缓存物理地址,但是一般缓存虚拟地址比较常见,由此可见,TLB 相当于是又多加了一个缓存层。
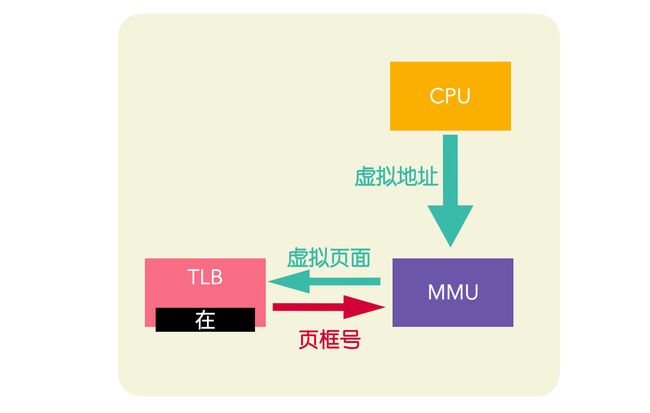
虚拟页面在 TLB 中
当一个数据的虚拟地址交由 MMU 进行转换时,MMU 首先会将这个虚拟地址和 TLB 中缓存的虚拟地址进行匹配,判断虚拟地址所在的页面是否被缓存,如果已经缓存,就会访问 TLB(这里有个前提就是判断访问位)将虚拟页面对应的页框号取出,而不必再访问页表。
虚拟页面不在 TLB 中
如果 MMU 没有检测到虚拟地址所在的页面,就说明没有查询到匹配项,就会走页表访问,通过页表查询到物理地址后,会从 TLB 中淘汰一个页面,用新找到的页面进行替换。

虽然内置一个硬件 TLB 能够加快虚拟地址到物理地址的映射速度,不过现代 os 大多数都是使用软件 TLB 来实现这个加速过程的,使用软件 TLB 就意味着不再使用硬件,转而拥抱操作系统。
这也就是说,当发生 TLB 失效时,不再是通过 MMU 到页表中查询,而是生成一个 TLB 失效并交给操作系统来解决。失效会有两种发生的可能性:当要访问的页面在内存中时,这种失效叫做软失效,软失效比较好处理,找到该页面然后直接更新 TLB 中对应的项即可。当要访问的页面不再内存中时,这种失效叫做硬失效,硬失效涉及磁盘访问,页面调入,硬失效的处理时间往往是软失效的几百万倍。
上述都是理想情况下的失效,但实际情况下会存在既不是软失效也不是硬失效的情况。当程序访问一个非法地址时,根本不需要向 TLB 更新映射,此时 os 会直接报告段错误来终止程序,这种缺页属于程序错误;而软失效通常称为次要缺页错误,硬失效称为严重缺页错误。
解决完第一个问题之后,我们再来看第二个问题,即如何处理日益剧增的页表呢?
一般有两种处理方式,使用多级页表和倒排页表。
第一种方案是使用多级页表,下面是一个例子

32 位的虚拟地址被划分为 10 位的 PT1 域,10 位的 PT2 域,还有 12 位的 Offset 域。因为偏移量是 12 位,所以页面大小是 4 KB,公有 2^20 次方个页面。
引入多级页表的原因是避免把全部页表一直保存在内存中。不需要的页表就不应该保留。
多级页表是一种分页方案,它由两个或多个层次的分页表组成,也称为分层分页。级别1(level 1)页面表的条目是指向级别 2(level 2) 页面表的指针,级别2页面表的条目是指向级别 3(level 3) 页面表的指针,依此类推。最后一级页表存储的是实际的信息。
下面是一个二级页表的工作过程
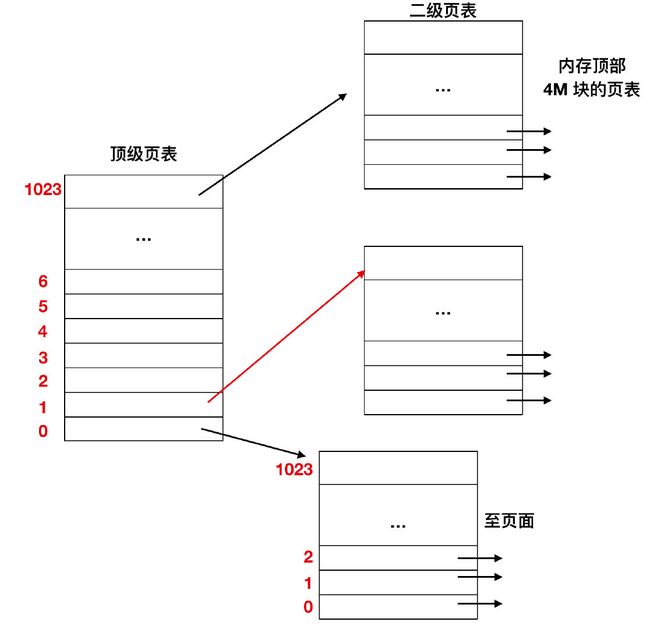
在最左边是顶级页表,它有 1024 个表项,对应于 10 位的 PT1 域。当一个虚拟地址被送到 MMU 时,MMU 首先提取 PT1 域并把该值作为访问顶级页表的索引。因为整个 4 GB (即 32 位)虚拟地址已经按 4 KB 大小分块,所以顶级页表中的 1024 个表项的每一个都表示 4M 的块地址范围。
由索引顶级页表得到的表项中含有二级页表的地址或页框号。顶级页表的表项 0 指向程序正文的页表,表项 1 指向含有数据的页表,表项 1023 指向堆栈的页表,其他的项(用阴影表示)表示没有使用。现在把 PT2 域作为访问选定的二级页表的索引,以便找到虚拟页面的对应页框号。
针对分页层级结构中不断增加的替代方法是使用倒排页表(inverted page tables)。采用这种解决方案的有 PowerPC、UltraSPARC 和 Itanium。在这种设计中,实际内存中的每个页框对应一个表项,而不是每个虚拟页面对应一个表项。
虽然倒排页表节省了大量的空间,但是它也有自己的缺陷:那就是从虚拟地址到物理地址的转换会变得很困难。当进程 n 访问虚拟页面 p 时,硬件不能再通过把 p 当作指向页表的一个索引来查找物理页。而是必须搜索整个倒排表来查找某个表项。另外,搜索必须对每一个内存访问操作都执行一次,而不是在发生缺页中断时执行。
解决这一问题的方式时使用 TLB。当发生 TLB 失效时,需要用软件搜索整个倒排页表。一个可行的方式是建立一个散列表,用虚拟地址来散列。当前所有内存中的具有相同散列值的虚拟页面被链接在一起。如下图所示
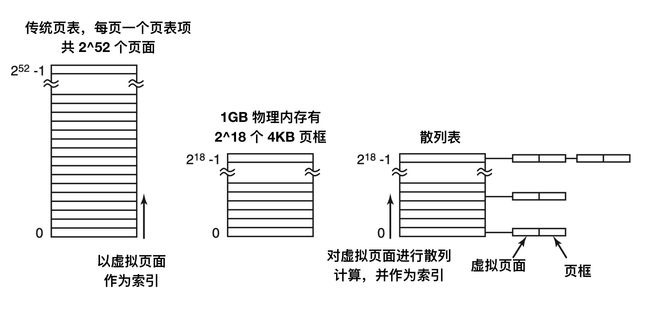
如果散列表中的槽数与机器中物理页面数一样多,那么散列表的冲突链的长度将会是 1 个表项的长度,这将会大大提高映射速度。一旦页框被找到,新的(虚拟页号,物理页框号)就会被装在到 TLB 中。
总结
这篇文章我从 MMU 这个知识点进行切入,来为你展开了操作系统中的虚拟地址的概念,操作系统是如何处理日益增加的地址空间的,以及内存管理面临的挑战,如何优化等。
如果这篇文章对你有帮助,求点赞,求转发,求关注,你的支持是我更文最大的动力。
原文链接:从 MMU 看内存管理