消息驱动的微服务: Spring Cloud Stream
1.官方定义:
Spring Cloud Stream 是一个构建消息驱动微服务的框架。
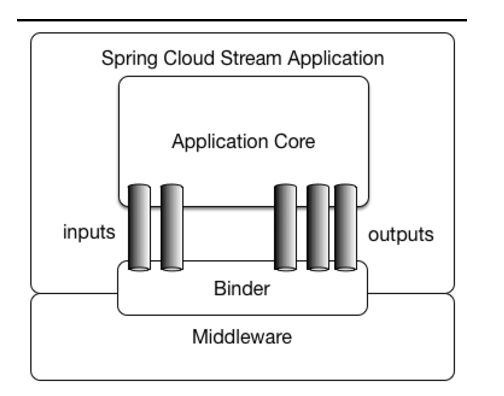
应用程序通过 inputs 或者 outputs 来与 Spring Cloud Stream 中binder交互,通过我们配置来 binding ,而 Spring Cloud Stream 的 binder 负责与消息中间件交互。所以,我们只需要搞清楚如何与 Spring Cloud Stream 交互就可以方便使用消息驱动的方式。
通过使用Spring Integration来连接消息代理中间件以实现消息事件驱动。Spring Cloud Stream 为一些供应商的消息中间件产品提供了个性化的自动化配置实现,引用了发布-订阅、消费组、分区的三个核心概念。目前仅支持RabbitMQ、Kafka。
什么是Spring Integration? Integration 集成
企业应用集成(EAI)是集成应用之间数据和服务的一种应用技术。四种集成风格:
1.文件传输:两个系统生成文件,文件的有效负载就是由另一个系统处理的消息。该类风格的例子之一是针对文件轮询目录或FTP目录,并处理该文件。
2.共享数据库:两个系统查询同一个数据库以获取要传递的数据。一个例子是你部署了两个EAR应用,它们的实体类(JPA、Hibernate等)共用同一个表。
3.远程过程调用:两个系统都暴露另一个能调用的服务。该类例子有EJB服务,或SOAP和REST服务。
4.消息:两个系统连接到一个公用的消息系统,互相交换数据,并利用消息调用行为。该风格的例子就是众所周知的中心辐射式的(hub-and-spoke)JMS架构。
2. 为什么需要SpringCloud Stream消息驱动呢?
比方说我们用到了RabbitMQ和Kafka,由于这两个消息中间件的架构上的不同,像RabbitMQ有exchange,kafka有Topic,partitions分区,这些中间件的差异性导致我们实际项目开发给我们造成了一定的困扰,我们如果用了两个消息队列的其中一种,如果后续业务需求,我想往另外一种消息队列进行迁移,这时候无疑就是一个灾难性的,一大堆东西都要重新推倒重新做,因为它跟我们的系统耦合了,这时候springcloud Stream给我们提供了一种解耦合的方式。
- 应用模型
应用程序通过 inputs 或者 outputs 来与 Spring Cloud Stream 中Binder 交互,通过我们配置来绑定,而 Spring Cloud Stream 的 Binder 负责与中间件交互。所以,我们只需要搞清楚如何与 Spring Cloud Stream 交互就可以方便使用消息驱动的方式。
-
抽象绑定器(The Binder Abstraction)
Spring Cloud Stream实现Kafkat和RabbitMQ的Binder实现,也包括了一个TestSupportBinder,用于测试。你也可以写根据API去写自己的Binder。
Spring Cloud Stream 同样使用了Spring boot的自动配置,并且抽象的Binder使Spring Cloud Stream的应用获得更好的灵活性,比如:我们可以在
application.yml或application.properties中指定参数进行配置使用Kafka或者RabbitMQ,而无需修改我们的代码。
通过 Binder ,可以方便地连接中间件,可以通过修改application.yml中的spring.cloud.stream.bindings.input.destination 来进行改变消息中间件(对应于Kafka的topic,RabbitMQ的exchanges)
在这两者间的切换甚至不需要修改一行代码。
-
发布-订阅(Persistent Publish-Subscribe Support)
如下图是经典的Spring Cloud Stream的 发布-订阅 模型,生产者 生产消息发布在shared topic(共享主题)上,然后 消费者 通过订阅这个topic来获取消息

其中topic对应于Spring Cloud Stream中的destinations(Kafka 的topic,RabbitMQ的 exchanges)
官方文档这块原理说的有点深奥,详见官方文档
-
消费组(Consumer Groups)
尽管发布-订阅 模型通过共享的topic连接应用变得很容易,但是通过创建特定应用的多个实例的来扩展服务的能力同样重要,但是如果这些实例都去消费这条数据,那么很可能会出现重复消费的问题,我们只需要同一应用中只有一个实例消费该消息,这时我们可以通过消费组来解决这种应用场景, 当一个应用程序不同实例放置在一个具有竞争关系的消费组中,组里面的实例中只有一个能够消费消息
设置消费组的配置为
spring.cloud.stream.bindings.,.group 下面举一个DD博客中的例子:
下图中,通过网络传递过来的消息通过主题,按照分组名进行传递到消费者组中
此时可以通过
spring.cloud.stream.bindings.input.group=Group-A或spring.cloud.stream.bindings.input.group=Group-B进行指定消费组
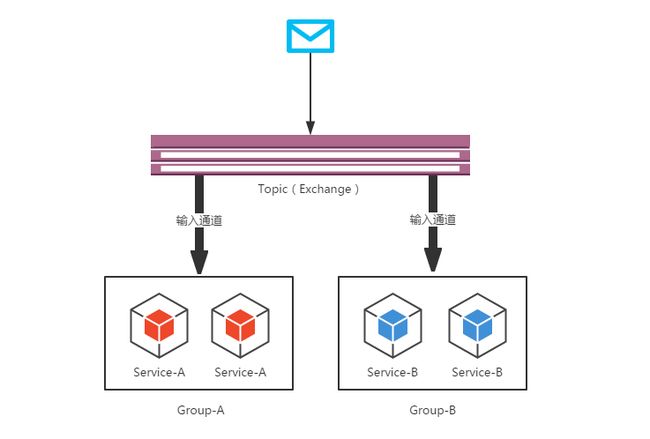
所有订阅指定主题的组都会收到发布消息的一个备份,每个组中只有一个成员会收到该消息;如果没有指定组,那么默认会为该应用分配一个匿名消费者组,与所有其它组处于 订阅-发布 关系中。
ps:也就是说如果管道没有指定消费组,那么这个匿名消费组会与其它组一起消费消息,出现了重复消费的问题。
-
消费者类型(Consumer Types)
1)支持有两种消费者类型:
- Message-driven (消息驱动型,有时简称为
异步) - Polled (轮询型,有时简称为
同步)
在Spring Cloud 2.0版本前只支持 Message-driven这种异步类型的消费者,消息一旦可用就会传递,并且有一个线程可以处理它;当你想控制消息的处理速度时,可能需要用到同步消费者类型。
2)持久化
- Message-driven (消息驱动型,有时简称为
一般来说所有拥有订阅主题的消费组都是持久化的,除了匿名消费组。 Binder的实现确保了所有订阅关系的消费订阅是持久的,一个消费组中至少有一个订阅了主题,那么被订阅主题的消息就会进入这个组中,无论组内是否停止。
注意: 匿名订阅本身是非持久化的,但是有一些Binder的实现(比如RabbitMQ)则可以创建非持久化的组订阅
通常情况下,当有一个应用绑定到目的地的时候,最好指定消费消费组。扩展Spring Cloud Stream应用程序时,必须为每个输入绑定指定一个使用者组。这样做可以防止应用程序的实例接收重复的消息(除非需要这种行为,这是不寻常的)。
-
分区支持(Partitioning Support)
在消费组中我们可以保证消息不会被重复消费,但是在同组下有多个实例的时候,我们无法确定每次处理消息的是不是被同一消费者消费,分区的作用就是为了确保具有共同特征标识的数据由同一个消费者实例进行处理,当然前边的例子是狭义的,通信代理(broken topic)也可以被理解为进行了同样的分区划分。Spring Cloud Stream 的分区概念是抽象的,可以为不支持分区Binder实现(例如RabbitMQ)也可以使用分区。
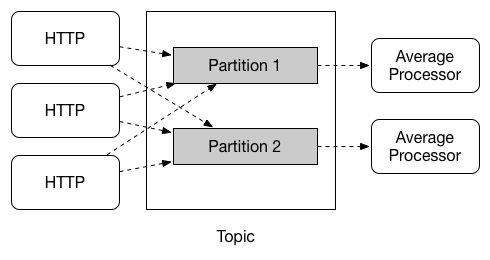
注意:要使用分区处理,你必须同时对生产者和消费者进行配置。
3.编程模型(Programming Model)
为了理解编程模型,需要熟悉下列 核心概念:
Destination Binders(目的地绑定器): 负责与外部消息系统集成交互的组件
Destination Bindings(目的地绑定):在外部消息系统和应用的生产者和消费者之间的桥梁(由Destination Binders创建)
Message (消息): 用于生产者、消费者通过Destination Binders沟通的规范数据。
Destination Binders(目的地绑定器): Destination Binders是Spring Cloud Stream与外部消息中间件提供了必要的配置和实现促进集成的扩展组件。集成了生产者和消费者的消息的路由、连接和委托、数据类型转换、用户代码调用等。
尽管Binders帮我们处理了许多事情,我们仍需要对他进行配置。之后会讲
Destination Bindings (目的地绑定) : 如前所述,Destination Bindings 提供连接外部消息中间件和应用提供的生产者和消费者中间的桥梁。
使用 @EnableBinding注解打在一个配置类上来定义一个Destination Binding,这个注解本身包含有@Configuration,会触发Spring Cloud Stream的基本配置。
接下来的例子展示完全配置且正常运行的Spring Cloud Stream应用,由INPUT接收消息转换成String 类型并打印在控制台上,然后转换出一个大写的信息返回到OUTPUT中。
@SpringBootApplication
@EnableBinding(Processor.class)
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
@StreamListener(Processor.INPUT)
@SendTo(Processor.OUTPUT)
public String handle(String value) {
System.out.println("Received: " + value);
return value.toUpperCase();
}
}
通过SendTo注解将方法内返回值转发到其他消息通道中,这里因为没有定义接收通道,提示消息已丢失,解决方法是新建一个接口,如下:
public interface MyPipe{
//方法1
@Input(Processor.OUTPUT) //这里使用Processor.OUTPUT是因为要同一个管道,或者名称相同
SubscribableChannel input();
//还可以如下这样=====二选一即可==========
//方法2
String INPUT = "output";
@Input(MyPipe.INPUT)
SubscribableChannel input();
}
然后在在上边的方法下边加一个方法,并在@EnableBinding注解中改成
@EnableBinding({Processor.class, MyPipe.class})
@StreamListener(MyPipe.INPUT)
public void handleMyPipe(String value) {
System.out.println("Received: " + value);
}
Spring Cloud Stream已经为我们提供了三个绑定消息通道的默认实现
Sink:通过指定消费消息的目标来标识消息使用者的约定。
Source:与Sink相反,用于标识消息生产者的约定。
Processor:集成了Sink和Source的作用,标识消息生产者和使用者
他们的源码分别为:
public interface Sink {
String INPUT = "input";
@Input("input")
SubscribableChannel input();
}
public interface Source {
String OUTPUT = "output";
@Output("output")
MessageChannel output();
}
public interface Processor extends Source, Sink {
}
Sink和Source中分别通过@Input和@Output注解定义了输入通道和输出通道,通过使用这两个接口中的成员变量来定义输入和输出通道的名称,Processor由于继承自这两个接口,所以同时拥有这两个通道。
注意点:拥有多条管道的时候不能有输入输出管道名相同的,否则会出现发送消息被自己接收或报错的情况
我们可以根据上述源码的方式来定义我们自己的输入输出通道,定义输入通道需要返回SubscribaleChannel 接口对象,这个接口继承自 MessageChannel 接口,它定义了维护消息通道订阅者的方法;定义输出通道则需要返回MessageChannel接口对象,它定义了向消息通道发送消息的方法。
自定义消息通道 发送与接收
依照上面的内容,我们也可以创建自己的绑定通道 如果你实现了上边的MyPipe接口,那么直接使用这个接口就好, 和主类同包下建一个MyPipe接口,实现如下:
import org.springframework.cloud.stream.annotation.Input;
import org.springframework.cloud.stream.messaging.Source;
import org.springframework.messaging.SubscribableChannel;
public interface MyPipe {
//方法1
// @Input(Source.OUTPUT) //Source.OUTPUT的值是output,我们自定义也是一样的
// SubscribableChannel input(); //使用@Input注解标注的输入管道需要使用SubscribableChannel来订阅通道
//========二选一使用===========
//方法2
String INPUT = "output";
@Input(MyPipe.INPUT)
SubscribableChannel input();
}
这里用Source.OUTPUT和第二种方法 是一样的,我们只要将消息发送到名为output的管道中,那么监听output管道的输入流一端就能获得数据
扩展主类,添加监听output管道方法
@StreamListener(MyPipe.INPUT)
public void receiveFromMyPipe(Object payload){
logger.info("Received: "+payload);
}
在主类的头上的@EnableBinding改为@EnableBinding({Sink.class, MyPipe.class}),加入了Mypipe接口的绑定
在test/java下创建com.cnblogs.hellxz,并在包下新建一个测试类,如下:
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.messaging.Source;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@EnableBinding(value = {Source.class})
@SpringBootTest
public class TestSendMessage {
@Autowired
private Source source; //注入接口和注入MessageChannel的区别在于发送时需不需要调用接口内的方法
@Test
public void testSender() {
source.output().send(MessageBuilder.withPayload("Message from MyPipe").build());
//假设注入了MessageChannel messageChannel; 因为绑定的是Source这个接口,
//所以会使用其中的唯一产生MessageChannel的方法,那么下边的代码会是
//messageChannel.send(MessageBuilder.withPayload("Message from MyPipe").build());
}
}
启动主类,清空输出,运行测试类,然后你就会得到在主类的控制台的消息以log形式输出Message from MyPipe
通过注入消息通道,并调用他的output方法声明的管道获得的MessageChannel实例,发送的消息,管道注入过程中可能会出现的问题,通过注入消息通道的方式虽然很直接,但是也容易犯错,当一个接口中有多个通道的时候,他们返回的实例都是MessageChannel,这样通过@Autowired注入的时候往往会出现有多个实例找到无法确定需要注入实例的错误,我们可以通过@Qualifier指定消息通道的名称,下面举例:
在主类包内创建一个拥有多个输出流的管道
/**
* 多个输出管道
*/
public interface MutiplePipe {
@Output("output1")
MessageChannel output1();
@Output("output2")
MessageChannel output2();
}
创建一个测试类
@RunWith(SpringRunner.class)
@EnableBinding(value = {MutiplePipe.class}) //开启绑定功能
@SpringBootTest //测试
public class TestMultipleOutput {
@Autowired
private MessageChannel messageChannel;
@Test
public void testSender() {
//向管道发送消息
messageChannel.send(MessageBuilder.withPayload("produce by multiple pipe").build());
}
}
启动测试类,会出现刚才说的不唯一的bean,无法注入
Caused by: org.springframework.beans.factory.NoUniqueBeanDefinitionException: No qualifying bean of type 'org.springframework.messaging.MessageChannel' available: expected single matching bean but found 6: output1,output2,input,output,nullChannel,errorChannel
我们在@Autowired旁边加上@Qualifier("output1"),然后测试就可以正常启动了
通过上边的错误,我们可以清楚的看到,每个MessageChannel都是使用消息通道的名字做为bean的名称。
这里我们没有使用监听这个管道,仅为了测试并发现问题
常用配置
消费组和分区的设置
给消费者设置消费组和主题
1.设置消费组: spring.cloud.stream.bindings.<通道名>.group=<消费组名>
2.设置主题: spring.cloud.stream.bindings.<通道名>.destination=<主题名>
给生产者指定通道的主题:spring.cloud.stream.bindings.<通道名>.destination=<主题名>
消费者开启分区,指定实例数量与实例索引
1.开启消费分区: spring.cloud.stream.bindings.<通道名>.consumer.partitioned=true
2.消费实例数量: spring.cloud.stream.instanceCount=1 (具体指定)
实例索引: spring.cloud.stream.instanceIndex=1#设置当前实例的索引值
生产者指定分区键
1.分区键: spring.cloud.stream.bindings.<通道名>.producer.partitionKeyExpress=<分区键>
2.分区数量: spring.cloud.stream.bindings.<通道名>.producer.partitionCount=<分区数量>
Less is more.