前言
最近小农的朋友——小勇在找工作,开年来金三银四,都想跳一跳,找个踏(gao)实(xin)点的工作,这不小勇也去面试了,不得不说,现在面试,各种底层各种原理,层出不穷,小勇就遇上了这么一道面试题,因为没有回答好,面试被PASS,让他备受打击,作为大(lao)哥(si)哥(ji)的我,肯定要安慰一下,到底是什么样的面试题,让小勇又一次夭折在面试的路上,好奇怪为什么要说又?简直让人喜极而泣,哈哈哈,言归正传,我们一起来看一下!
话说小勇正襟危坐在面试官面前,这已经是小勇的第五次面试了,前几次都是石沉大海,让小勇有点着急了,但是小勇这一次可是有备而来,之前面试不会的问题,大部分都狠狠的补习了一下,想来这一次问题应该不大。
前面基础问题小勇都回答的有模有样的,面试官一看,基础还算可以,问一点有深度的吧!
面试官:我看你简历上写的熟悉JVM,我给你下面一个题目,先来讲一讲a = a ++; 和a = ++a; 的运行结果各是多少?
public class Test1 {
public static void main(String[] args) {
int a = 88;
a = a++;
// a = ++a;
System.out.println(a);
}
}
小勇心想:这不是小菜一碟吗,这我能不知道?
于是小勇轻蔑一笑说:a = a++; 输出结果是 8 ,a = ++a; 是 9
心想我还以为多有难度呢,就这?这种题目给我再来一个吧!
面试官:无动于衷,面无表情的说道,为什么结果是这样的,你知道吗?
小勇:还真来,提高难度了,小样有点东西啊,还好准备了,不然今天就在你这道题上坑住了。
a++ 是先计算 a 在++,在分号结束的才会做a++运算,所以当我们做赋值操作的时候a++ 还是 8,所以赋值给a的时候也是8,只有当分号结束了a++才会是9
++a 是 先计算 ++a ,不管是否在分号结束,这个时候的值就已经是 9 了,所以赋值的时候,a就变成了9,输出结果也就是9了
这下没话说了吧!
面试官摸了一下下巴,缓缓说到:这个操作在JVM内存里面是怎样运行的?
小勇:怎么运行的,这个不是底层原理了吗?剧本不是这么发展的,这块没有了解过。。。。
小勇:支支吾吾说道,这个没有了解过,不太清楚底层的实现
面试官轻蔑一笑说:行,今天面试就先到这里了,有什么事情,人事会通知你的!
小勇:!$%@#&*
不懂就学
听到上面小勇所讲的东西之后,大概了解到,面试官应该是要考他关于运行时数据在内存时候的知识点,不懂就学,遇到事情不要慌,想要真正理解上面的面试题的精髓,我们要做一些前置知识的点缀,首先我们先来看看下面一张图:
类生命周期:
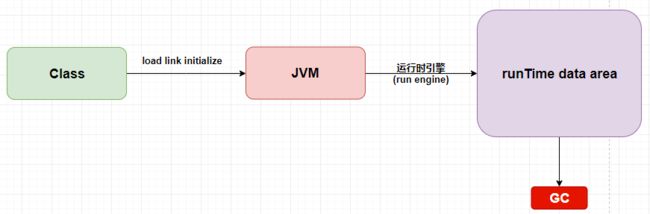
上图中首先将.class 文件读取到内存,存放在方法区(Perm Gen), 最终产品是Class对象,然后检查是否有正确数据结构,JVM为Class的静态变量分配内存,并设置默认初始值,把Class的二进制数据中的符号引用替换为直接引用,JVM为执行Class 的static 语句块,会先初始化其父类,跑到JVM虚拟机之后呢,会进入到运行时引擎,最后在运行时引擎里面运行,运行的时候在内存里面是一个什么样的情况,这个就是我们要讲的重点——run-time data areas
运行时数据区
Java虚拟机运行时数据区:
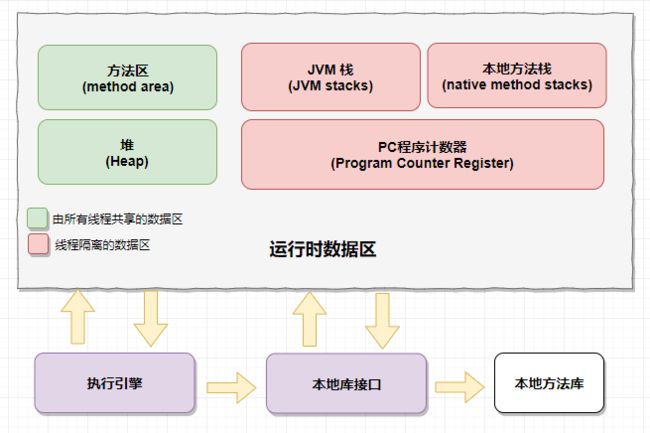
1.1 程序计数器
> 程序计数器是一块较小的内存空间, 它可以看作是当前线程所执行的字节码的行号指示器。由于Java虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器都会只执行一条线程中的指令,因此为了线程切换后都能回复正确的执行位置,每个线程都有一个独立的程序计数器。如果线程正在执行的是一个java方法,这个计数器记录的就是正在执行的虚拟机字节码指令的地址。如果正在执行的是native方法,这个计数器值则为空。
作用:
1、字节码解释器通过改变程序计数器来一次读取指令,从而实现代码的流程控制。比如:顺序执行、选择、循环、异常处理等
2、在多线程的情况下,程序计数器用于记录当前线程线程执行的位置,当线程被切换回来的时候能够知道该线程上次运行到哪里了
特点:
- 是一块较小的内存空间
- 线程私有,每一条线程都有一个程序计数器
- 是唯一不会出现 OutOfMemoryError的内存区域
- 生命周期随着线程的创建而创建,随着线程的结束而结束
1.2 Java虚拟机栈
Java虚拟机栈也是线程私有的,它的生命周期与线程相同,虚拟机栈描述的是Java方法执行的内存模型;每个方法在执行的同时都会创建一个栈帧(stack frame) 用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用至执行完成的过程,就对应着一个栈帧在虚拟机中入栈到出栈的过程。

我们结合一个案例来看一下:
public class TestStack {
public static void main(String[] args) {
new PlayRice().print();
}
}
class PlayRice{
public void fun(){
System.out.println("干饭人,干饭魂,干饭都是人上人!!!");
}
public void print(){
fun();
}
}

经常有人把Java 内存区域笼统的划分成堆内存(Heap)和栈内存(Stack),这种划分方式是直接继承自传统的 C、C++程序的内部结构,但是在Java语言里面显然是不合适的,Java的内存区域过分要比这两个更复杂,不过这种划分方式的流行也简洁说明了程序员最关注的、对象内存分配关系最密切的区域是 堆和栈,栈通常是指虚拟机,或者更多情况下只是指 虚拟机栈中的局部变量表的部分
局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用
在《Java虚拟机规范中》,对这个区域规定了两种异常状况:
1. 如果线程请求的栈深度大于虚拟机所允许的深度,将抛出 StackOverflowError
2. 如果Java虚拟机栈可以动态扩展,当扩展时无法申请到足够的内存,就会抛出OutOfMemoryError异常
1.3 本地方法栈
本地方法栈(Native Method Stack)和虚拟机栈所发挥的作用是非常相似的,他们之间的区别就是虚拟机栈为虚拟机执行的Java方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native方法服务。
在虚拟机规范中对本地方法栈中方法使用的语言、使用方式与数据结构并没有强制规定,因此具体的虚拟机可以自由实现它,甚至有的Java虚拟机(Hot-Spot虚拟机)直接就把本地方法栈和虚拟机栈合二为一。与虚拟机一样,本地方法栈也会抛出 StackOverflowError 和 OutOfMemoryError 异常。
1.4 堆
Java堆是虚拟机所管理中内存最大的一块。Java堆是被所有线程共享的一个内存区域,在虚拟机启动时创建。这个内存区域的唯一目的就是存放对象的实例,Java世界里 几乎 所有的对象实例都在这里分配。
在《Java虚拟机规范》中对Java堆的描述是:“所有的对象实例以及数组都应当在堆上分配”。Java对是垃圾收集器管理的内存区域。从回收内存的角度看,现代的垃圾收集器大部分都是分代收集理论设计的,所以Java堆中经常会出现 “新生代、老年代、永久代、Eden、Survivor”。
根据《Java虚拟机规范》的规定,Java堆可以处在物理上不连续的内存空间中,但在逻辑上它应该被视为连续的,这点就像我们用磁盘空间去存储文件一样,并不要求每个文件都连续存放。但对于大对象(典型的如数组对象),多数虚拟机实现出于实现简答、存储高效的考虑,很可能会要求连续的内存空间。
Java堆既可以被实现成固定大小的,也可以是可扩展的,不过当前主流的Java虚拟机都是按照可扩展来实现的(通过参数-Xmx和-Xms设定)。如果在Java堆中没有内存完成实例分配,并且堆也无法再扩展时,Java虚拟机会抛出OutOfMemoryError异常。
1.5 方法区
方法区(Method Area)和Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。虽然《Java虚拟机规范》中把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做 “非堆”(Non-Heap),目的是与Java堆区分开来。
《Java虚拟机规范》对方法区的约束是非常高宽松的,除了和Java堆一样不需要连续的内存和可以选择固定大小或者可扩展外,甚至还可以选择不实现垃圾收集,所以垃圾收集的行为在这个区域就会比较少出现。这个区域的内存回收目标主要是针对常量池的回收和类型的卸载,但是这个区域的回收效果就比较差强人意了。
如果方法区无法满足新的内存分配需求的时候,就会抛出 OutOfMemoryError异常。
1.6 运行时常量池
运行时常量池(Runtime Constant Pool)是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池表(Constant Pool Table),用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。
Java虚拟机对于Class文件每一部分(包括常量池)的格式都有严格规定,如每一个字节用于存储哪种数据都必须符合规范上的要求才会被虚拟机认可、加载和执行,但对于运行时常量池,《Java虚拟机规范》并没有任何细节的要求,不同提供商实现的虚拟机可以按照自己的需要来实现,这个内存区域,不过一般来说,除了保存Class文件描述的符号引用外,还会把符号引用翻译出来的直接引用也存储在运行时常量池中
运行时常量池相对于Class文件常量池的另外一个重要特征是具备动态性,Java语言并不要求常量一定只有编译器才能产生,也就是说,并非预置入Class文件中常量池的内容才能进入方法区运行时常量池,运行期间也可以将新的常量放入池中,这种特性被开发人员利用的比较多就是String类的intern()方法。
既然运行时常量池是方法区的一部分,自然受到方法区内存的限制,当常量池无法再申请到内存 时会抛出OutOfMemoryError异常。
1.7 直接内存
直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是《Java虚拟机规范》中定义的内存区域。但是这部分也被频繁的使用过,而且也有可能会导致OutOfMemoryError异常出现,在JDK1.4中新加入了NIO(New Input/Output)类,引入了一种基于通道(Channel)与缓冲区(Buffer)的I/O方式,它可以使用Native函数库直接分配堆外内存。然后通过一个存储在Java堆里面的DirectByteBuffer对象作为这块内存的引用进行操作。
1.8 小结
从下面一张图我们就可以看出,每一个线程都有自己的程序计数器、Java虚拟机栈以及本地方法栈,但是他们共享的是堆以及方法区,为什么每个线程都有自己的程序计数器?我们在上面已经讲过,就是当一个线程执行完了,CPU切换到另一个线程去执行,当另外一个线程执行完成之后切回来的时候,能够知道当前线程执行的位置。

理解面试题
我们回到最开始我们讲的面试题,我们先来看 i=i++等于8,具体他内部是怎样执行的呢,我们需要看它的指令是怎么操作的
我们可以用过 Jclasslib来解析他二进制码之后点到的main方法
1.1 安装 Jclasslib
首先我们需要安装 Jclasslib,安装成功如下图所示:

1.2 查看字节码
首先我们需要 运行main方法 ,加载其class的内容后,点击 view -> show Bytecode With Jclasslib


main方法里面记录的有两张表:
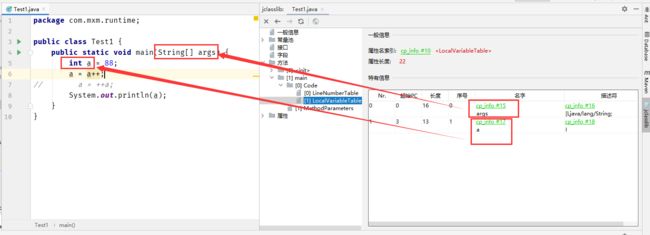
表1:LineNumberTable 记录是行号
表2:LocalVariabletable 是局部变量表,里面就是方法内部使用到的变量,第一个是 args ,第二个是a,所以局部变量表,指的就是我们当前这个方法,这个栈帧里面用到了哪些局部变量。
a = a++;
接下来我们来看一下,a = a++;中间的执行过程具体是怎么样的
0 bipush 88
2 istore_1
3 iload_1
4 iinc 1 by 1
7 istore_1
8 getstatic #2
11 iload_1
12 invokevirtual #3
15 return
如果我们不理解指令具体是什么意思,我们可以点击对应指令,浏览器直接定位这条指令的详细说明
首先我们来看一下 bipush 88 和 istore_1,对应的是 int a = 88;iload+1 等于89,再把89赋值出来还是89,
bipush 88 是指 push byte 放到栈中,88当成一个byte值,会自动扩展成Int类型,把它放到栈中,88放在局部变量表,输入结果是88。
第二条指令
istore_1是把我们栈顶上的那个数出栈,放到下标值为1的局部变量表。局部变量表下标值为1的就是a的值,刚才88是放到栈顶上的,现在把88弹出来放到a里面,所以这两句话完成之后对应的int a = 88就完成了,如下图所示

- iload_1: 的意思是 从局部变量加载int(load int from local variable) ,就是从局部变量表中 拿值,之后放到栈里面,如下图所示:
 在这里插入图片描述
在这里插入图片描述
- iinc 1 by 1: 执行 a++ 操作,将局部变量表中 数值为88的进行+1 操作,所以就是 89了,
 在这里插入图片描述
在这里插入图片描述
istore_1: 执行 a = a++ 操作,原先已经执行了 a++ 操作,这个时候将 a++ 中 a 赋值给 int a ,所以会将栈中的数据赋值到 局部变量表中,所以这个时候局部变量表中的数据就是88了

所以我们最后的结果就是88
a = ++a;
字节码指令:
0 bipush 88
2 istore_1
3 iinc 1 by 1
6 iload_1
7 istore_1
8 getstatic #2
11 iload_1
12 invokevirtual #3
15 return
bipush 88和istore_1: 这句话其实完成了 int a = 88,先将88压栈,然后在出栈赋值到局部变量表中

iinc 1 by 1: 进行++a 操作,所以这个时候局部变量表中的数据就变成了89
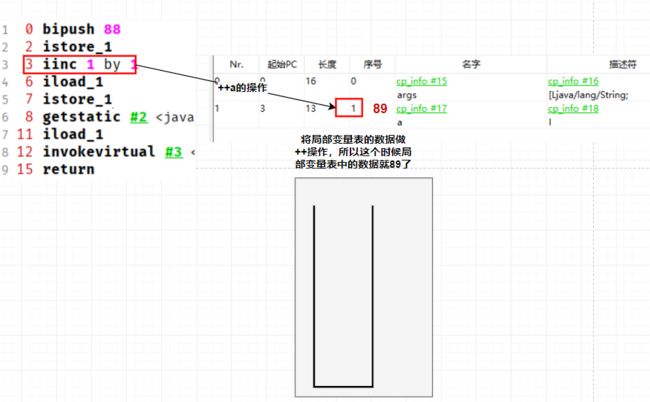
iload_1: 这个时候将局部变量表中的数值压到栈中,

istore_1: 这个时候做 a = ++a 操作,将 a的值赋值给 int a,因为在栈中的数据本身就是89,所以最后打印出来的结果就是89

补充:
当我们设置 int a = 250 的时候,下面的值会变成 sipush,是因为 250已经超过127,他已经超过byte 所能代表的最大结果,所以看到的二进制就是sipush,s 代表 short

总结
到这里,你学废了吗?其实有时候我们学东西,知道怎么用,但是具体里面的细节,就需要我们仔细的去琢磨,有时候会很枯燥,当我们了解其原理之后,会有豁然开朗的感觉吗?小农会有,你们呢?
我是牧小农,怕什么真理无穷,进一步有进一步的欢喜,大家加油!