译文出处:https://software.intel.com/en-us/articles/talroo-uses-analytics-zoo-and-aws-to-leverage-deep-learning-for-job-recommendations
基于关键字的求职搜索通常不能充分传达求职者意图。而在人力资源(HR)技术领域,大量含有丰富文本内容提供了更为丰富的信息。例如,求职者的简历中包含了其理想工作的各种指标。这个项目主要演示了如何在基于Amazon Web Services (AWS) 的Databricks平台上利用Analytics Zoo的自然语言文本分析和基于深度学习的推荐模型,根据简历内容和工作职位描述,来预测求职者申请工作职位的可能性。
背景
Talroo 面临基于关键字搜索的挑战。Talroo是一个高容量、数据驱动的全国性招聘网站,有着丰富的市场合作关系,其网络庞大而有针对性。目前,Talroo大规模的根据求职者输入的关键词,通过搜索去匹配和推荐工作。每个月Talroo都会处理百亿条招聘广告和十亿条工作查询的数据,这会导致数以千万计像点击和转换的交互事件。这些描述、查询和交互事件都在AWS上的Databricks平台上处理,并作为parquet table被存储到Amazon Simple Storage Service(Amazon S3)上。了解更多有关 Talroo *
Talroo碰到的挑战之一是,较短的招聘周期限制了招聘广告面向求职者的有效投放。目前,Talroo已有的推荐系统通过关键字搜索来解决这个冷启动问题。但这个简短的关键词缺少上下文来源并不能有效描述求职者的意向。相比单纯的关键词,个人简历在自然语言中提供了更丰富的上下文来源。
新开发的深度神经网络(DNN)已经在捕获用户项数据非线性关系的推荐系统中得到成功应用。经验证据表明,使用更深层次的神经网络可以提供更好的推荐性能。
因此,将自然语言处理(NLP)和大规模DNN技术结合在AWS Databricks生产平台上,是完善Talroo推荐系统的关键。本项目通过使用基于BigDL [1] 的Analytics Zoo构建了端到端的解决方案。
数据集成
我们直接从Talroo的数据处理过程中提取求职者简历和招聘广告以及相关的数据,用于训练和测试模型。并通过含有申请、点击和广告的显示量的日志文件来还原申请职位的过程。基本流程如下:
1、为申请日志中的每一位求职者生成(Resume, Applied-Job) pair
2、生成的(Resume, Applied-Job) pair 和点击日志结合生成点击信息
3、使用 (Resume, Applied-Job, Click) tuple和广告显示日志匹配得到所有推荐的招聘广告,不考虑工作是否被申请
该项目应用了包含了查询、广告显示、点击和转换的5个月简历搜索数据,用于构建解决方案。其中用于模型训练/测试之间的分配比例为4:1。
将Analytics Zoo的深度学习应用到AWS上的Databricks平台非常直接。首先通过上传适当的Java* ARchive文件包(JARs),将Analytics Zoo APIs加载到 Databricks 平台的classpath中;然后,我们通过Databricks平台的Jupyter笔记本接口进行深度学习模型的训练和迭代,如任何其他机器学习模型一样。
Analytics Zoo解决方案
Analytics Zoo是Intel开源的一个统一的数据分析和人工智能平台,它无缝地将Spark、TensorFlow、Keras和BigDL程序集成到一个整合的流水线中,可以透明地扩展到大型Apache Hadoop/Spark集群中,用于分布式训练或推理,而无需额外的GPU基础设施。
此端到端的处理流程运行在已经包含了 Apache Spark 和Analytics Zoo 的Databricks集群上,整个流程包括了数据采集、 特征提取、 推荐模型的训练和评估。推荐系统的输入是一个简历-招聘广告配对,用来训练Neural Collaborative Filtering (NCF) [2] 模型从而学习工作职位与求职者之间的关系,并预测某些求职者申请特定职位的可能性。在当前版本中,点击表示正样本,而非点击表示负样本。下图 1 显示了完整的端到端处理流程。
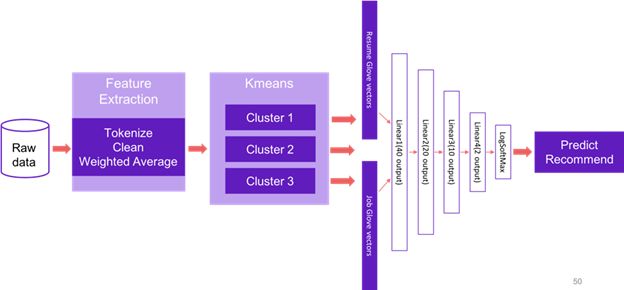
第 1 部分
我们首先会读取Spark中的原始数据作为DataFrames,然后提取用于模型训练的数据特征。在原始数据集中,每份简历或招聘广告的文本内容是我们要处理的对象。我们对每一个文本内容来提取一个数据向量表示该文本,用于训练和测试推荐模型。
在此项目中,我们通过Global Vectors (GloVe) [3] 来得到文档的向量。该数据采用全域对数双线性回归模型的无监督算法,将每个单词转成对应的实数向量。该训练使用了来自2014年维基百科的单词与单词同时出现的统计数据。下载数据地址:zip file from the Stanford NLP Group.
我们将文档分割成词,清洗,然后根据每个单词的向量计算加权平均值,从而得到该文档的数据向量,文档的数据向量代表了该文档在向量空间中的线性子结构。
第 2 部分
我们使用Spark 自有的APIs训练k-Means模型,将简历分到了多个组中。了解更多K-means++.
<<<<
val kmeans = new KMeans()
.setK(param.kClusters)
.setSeed(1L)
.setInitMode("k-means||")
.setMaxIter(param.numIterations)
.setFeaturesCol("kmeansFeatures")
.setPredictionCol("kth")
val trained: KMeansModel = kmeans.fit(resueDF)
<<<<
第 3 部分
我们进一步处理每个组中的简历和招聘广告,对于每个简历-招聘广告配对,我们将对应的两个向量连接成一个向量作为数据特征,将点击或不点击分别转换表示为正标签或负标签。含有数据特征和标签的DataFrame被转换成Sample 的RDD。
第 4 部分
然后,我们用Analytics Zoo APIs为每个组构建NCF推荐模型 (由四个线性层组成,如下所示),并训练模型。对模型的权重和偏差给与平均值为0且标准偏差为0.1初始值,以得到更快的收敛效果。
<<<<
val model = Sequential[Float]()
model
.add(Linear(100, 40, initWeight = Tensor(40, 100).randn(0, 0.1), initBias = Tensor(40).randn(0, 0.1))).add(ReLU())
.add(Linear(40, 20, initWeight = Tensor(20, 40).randn(0, 0.1), initBias = Tensor(20).randn(0, 0.1))).add(ReLU())
.add(Linear(20, 10, initWeight = Tensor(10, 20).randn(0, 0.1), initBias = Tensor(10).randn(0, 0.1))).add(ReLU())
.add(Linear(10, 2, initWeight = Tensor(2, 10).randn(0, 0.1), initBias = Tensor(2).randn(0, 0.1))).add(ReLU())
.add(LogSoftMax())
<<<<
第 5 部分
我们一共训练了五个推荐模型,对每个测试记录根据其对应的推荐模型做出预测,从而得到综合预测。
模型评估和结果
我们使用两种离线评估方法,根据一个月的数据来对推荐系统进行评估。一个关注数量和另一个关注模型的质量。
对于数量评估,需要测量求职者选择的推荐数量。应用准确率 [4],[5]公式来测量检索到的实例中相关实例的分数。准确率是通过模拟点击率来估计点击率(CTR)的一种离线方法。
质量意味着推荐的工作的排名位置准确地反映了他们与简历的相关性,这意味着更匹配的工作应该得到更高的排名。因为当前模型是二进制秩,我们使用Mean reciprocal rank(MRR)[4] 。MRR从多个查询中计算出第一个相关实例的倒数的平均值,这将给出排名质量的统一衡量标准。
由于求职者的行为通常差异很大,最终的评估图表对应于工作的百分位数增加。我们没有使用召回率是因为很难得到真实的假阴性数据。
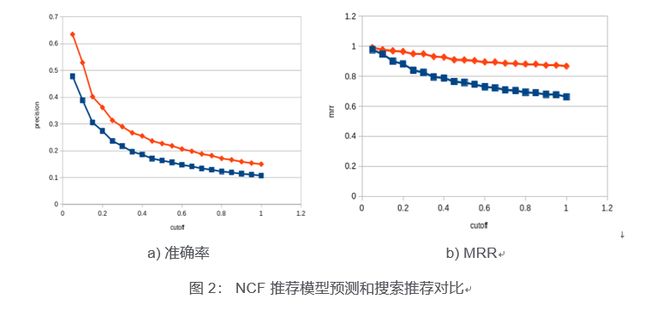
图 2 显示了推荐模型预测和搜索推荐的对比。橙线表示搜索的结果,蓝线表示 NCF 推荐模型的结果。两项统计信息图表分别是准确率 (图 2a) 和 MRR (图 2b) 。通过采用端到端Analytics Zoo解决方案的处理流程,我们看到了相比搜索推荐有大幅提高,MRR与准确率分别为 10%和6%。
结论
本文简要介绍了Talroo在使用关键字搜索来推荐工作面临的挑战,以及可以利用丰富文本信息和深度学习来改进推荐系统的可能。我们给出了判断模型成功的关键指标,介绍了整个解决方案。该方案使用Analytics Zoo搭建了端到端的深度学习处理流程,首先通过自然语言分析得到文本向量作为数据特征,又搭建了深度学习NCF推荐模型,从而预测求职者申请某工作的可能性。我们的方案成功运行在基于AWS的Databricks集群上。类似的基于深度学习和丰富内容的推荐系统也可以应用到在其他场景中(如Web搜索和电子商务)并发挥关键作用。更多的示例和API请参考Analytics Zoo模型推荐 。
参考资料
1、J Dai, Y Wang, X Qiu, etc., 2018, "BigDL: A Distributed Deep Learning Framework for Big Data"
2、X He, L Liao, H Zhang, etc., 2015, "Neural Collaborative Filtering"
3、J Pennington, R Socher, C Manning, 2014, "GloVe: Global Vectors for Word Representation"
4、Evaluation Measures (Information Retrieval)
5、P Lak, A Bener, 2017, "Predicting Click Through Rate for Advertisements- Dealing with Imbalanced Data"