PubMed 是一个提供生物医学方面的论文搜寻以及摘要,并且免费搜寻的数据库。是一个做生物方面经常要用到的一个查找文献的网站。最近刚学了爬虫相关的知识包括urllib库,requests库,xpath表达式,scrapy框架等。就想着去爬一下PubMed,就当练练手,准备根据搜索的关键字爬取PubMed上近五年发表文章数量,以此为依据来看看该研究方向的近五年的热门程度。
最开始的想法是利用scrapy框架去进行爬取和存储的。于是打开PubMed开始分析网页构成,源代码等。发现NCBI使用的是动态网页,进行翻页,搜索关键字等操作时网址没有发生变化。于是我想到了爬虫神器之一的selenium模块,利用selenium进行模拟搜索,翻页等操作,再分析源代码获取想要的信息。由于接触selenium并不多,有些函数是临时网上查找的。
1、 加载需要用到的模块
import urllib
import time
import matplotlib.pyplot as plt
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
2、通过关键字构造网址
自己手动输入几个关键字,分析出网址的构造。
PubMed的原始链接为'https://www.ncbi.nlm.nih.gov/pubmed',当输入并搜索'cancer,TCGA,Breast'时,url变成了'https://www.ncbi.nlm.nih.gov/pubmed/?term=cancer%2CTCGA%2CBreast'。于是不难分析出网址由两部分组成,一部分是不变的'https://www.ncbi.nlm.nih.gov/pubmed/?term=',另一部分由我们搜索的关键字由字符串'%2C'拼接而构成。因此对于传进来的'keyword',我们可以做以下处理,拼接成搜索后返回的url
keyword = '%2C'.join(keyword)
tart_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
url = start_url + keyword
这样我们就简单地把返回的url拼接好了。
3、创建浏览器对象
下一步是使用selenium模块打开我们的Chrome浏览器并且跳转到url的界面。相信大家都对这个操作比较熟悉了。因为我们待会要进行模拟点击翻页等操作,因此需要实例化一个WebDriverWait对象,方便后续进行调用
browser = webdriver.Chrome()
self.browser.get(url)
wait = WebDriverWait(browser, 10)
对网页进行模拟点击
打开了网页之后我们需要对网页进行模拟点击,首先我们要查找的是近五年的文章,所以需要模拟点击左边的5years的按键以及将单页显示的文章数量改成200,这样可以减少我们的翻页操作
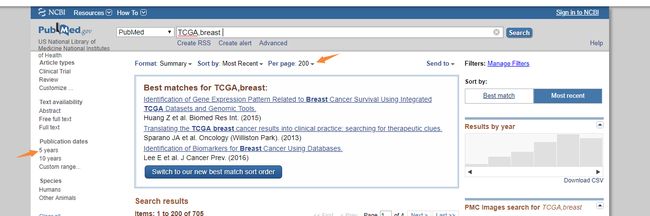
我们进行模拟点击之前要先等待到网页加载出相应元素才能进行点击,因此要使用到之前提过的WebDriverWait对象。代码如下
years =wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH,'//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
这里既用到了CSS selector也用到了Xpath表达式,具体使用哪个看个人喜好,觉得哪个方便就可以用哪个。EC.element_to_be_clickable内传入的是一个元组,第一个元素就是声明使用的是那个选择器,第二个元素则是表达式,这个函数的意思就是等待至你传入表达式的元素在网页中出现了才会进行后续操作,在使用selenium过程中,有很多地方我们需要用到类似的操作例如presence_of_element_located, text_to_be_present_in_element等,大家有兴趣可以自己上网了解一下
对网页进行解析并提取信息
接下来就是对网页进行解析了,我这里用的是lxml来进行网页解析以及Xpath提取信息的,代码如下
html = self.browser.page_source
doc = etree.HTML(self.html)
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
这里主要就是对网页中的年份做了个Xpath提取以及字符串的切片处理,从而得到年份信息,并存入列表。在实际操作过程中发现了少量其它的无关元素,经过仔细排查,发现是网页源码的问题,因此后续做了个正则处理,把不是‘2’开头的元素移除,最后结果经过检查是正确的。
这里我们就提取到了单页的信息。
进行翻页操作
我们还需要经过翻页操作才能获得我们所有的想要的信息。还是用到selenium模块。
status = True
def next_page():
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
status = False
while True:
if status:
next_page()
else:
break
这里我先定义了一个判断是否能够翻页的函数,用到了异常捕获,因为翻页动作到最后一页就应该停止,而且翻页的元素无法再次被点击。因此尽行click操作时应该先进行判断,如果无法被点击的话就会因为超时而抛出异常。next_page函数中的status变量就记录了’下一页‘按钮是否能够被点击。后面进行的是一个while True的循环,只有当next_page变成False时翻页动作才会停止,在循环中我们不断地解析网页提取信息就可以获得所有想要的信息了
可视化处理
爬取到所有年份信息的列表后,我们还需要进一步的进行可视化的处理,从而直观地判断目标课题的研究趋势,因此利用matplotlib来进行可视化操作,简单的绘制一个折线图。代码如下:
def plot_curve(yearlist):
counter = Counter(yearlist)
dic = dict(counter)
keys = sorted(list(dic.keys()))
curcount = 0
y = []
temp = [int(i) for i in keys]
for i in range(min(temp), max(temp)+1):
if str(i) in keys:
curcount += self.dic[str(i)]
y.append(self.curcount)
else:
y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.plot(np.arange(min(temp), max(temp)+1), np.array(y), 'r', marker='+', linewidth=2)
plt.show()
最后贴上完整代码:
import re
import urllib
import time
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
import matplotlib.pyplot as plt
class NcbiInfo(object):
browser = webdriver.Chrome()
start_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
wait = WebDriverWait(browser, 10)
def __init__(self, keywordlist):
self.temp = [urllib.parse.quote(i) for i in keywordlist]
self.keyword = '%2C'.join(self.temp)
self.title = ' AND '.join(self.temp)
self.url = NcbiInfo.start_url + self.keyword
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
self.file = open('information.txt', 'w')
self.status = True
self.yearlist = []
def click_yearandabstract(self, ):
self.browser.get(self.url)
years = self.wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH, '//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
page_200.click()
def get_response(self):
self.html = self.browser.page_source
self.doc = etree.HTML(self.html)
def get_numof_article(self):
article_count_ = self.doc.xpath('//*[@id="maincontent"]/div/div[3]/div[1]/h3/text()')[0]
if 'of' not in article_count_:
print(article_count_.split(': ')[1])
else:
print(article_count_.split('of ')[1])
def get_info(self):
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
def next_page(self):
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
self.status = False
def plot_curve(self):
self.counter = Counter(self.yearlist)
self.dic = dict(self.counter)
self.keys = sorted(list(self.dic.keys()))
self.curcount = 0
self.y = []
temp = [int(i) for i in self.keys]
for i in range(min(temp), max(temp)+1):
if str(i) in self.keys:
self.curcount += self.dic[str(i)]
self.y.append(self.curcount)
else:
self.y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.title(self.title)
plt.plot(np.arange(min(temp), max(temp)+1), np.array(self.y), 'r', marker='+', linewidth=2)
plt.show()
def main(self):
self.click_yearandabstract()
time.sleep(3)
self.get_response()
self.get_numof_article()
while True:
self.get_info()
self.next_page()
if self.status:
self.nextpage.click()
self.get_response()
else:
break
self.plot_curve()
if __name__ == '__main__':
a = NcbiInfo(['TCGA', 'breast', 'cancer'])
a.main()
结果如下图:
