Anchor free系列网络之YOLOX源码逐行讲解篇(八)--simOTA标签匹配策略详解(专栏试读)
整个YOLOX源码的学习一定要按照以下顺序才能整体串起来:Backbone->FPN->Head->->数据读入源码->数据增强源码->loss计算源码->simOTA源码->demo.py脚本->train.py脚本。而该系列博文也遵循该顺序来逐行分析代码。注意是逐行,包括python语法,tensor维度和逐行代码的作用及应用。其实网络结构本没有任何神秘的地方,都是一些模块堆叠起来的,你完全可以没有任何理由的修改任何一个模块。看完这个系列后自己完全可以随便的去对任何网络结构做手脚,而不仅仅局限于一个调参者。
只有符合的标签匹配策略的样本才会定义为正样本,只有正样本所对应的特征图的像素才能够参与loss计算及反传。所以标签匹配策略是非常重要的,选择合适的正样本对精度提升至关重要。
本篇讲的是YOLOX中simOTA标签匹配策略,是YOLOX中loss反向传播的一部分,也是YOLOX提出的新思想。simOTA是YOLOX作者在OT策略上提出的简化(simplify)算法,其作用是为不同目标选择不同数量的正样本。在分析代码之前,首先需要对simOTA策略有清晰的认识,以下是simOTA算法的步骤流程分解:
simOTA算法步骤一:首先会通过get_in_boxes_info()方法确定一个正样本的候选区域,如下图所示:

- 一个原始图像上面有绿色框和黄色框。灰色的网格代表以FPN的其中一个stride为长度给图像打的网格。一个网格代表feature map中一个像素点所能看到的感受野。绿色框为其中的一个gtbox。黄色框为YOLOX规定的一个正方形区域,这个区域是以当前gtbox的中心点为中心,向上下左右四个方向分别延伸2.5倍的stride(特征图对应原图的比例),也就是说不同的特征图上的特征点的黄色框是不一样的。如果feature map中的一个像素点对应原图的中心点在绿色框和黄色框的区域内,那么这个像素点就属于YOLOX的正样本的候选区域。
- 注意:get_in_boxes_info()该方法内所有变量都是和gtbox及原始图像相关的真实存在的变量,和网络的预测变量即bboxes_preds_per_image参数没有任何关系。
simOTA算法步骤二:计算get_in_boxes_info()得到的正样本候选区域所产生的每个预测框与当前gtbox的IoU。
simOTA算法步骤三:将计算所得的IoU按从大到小的顺序排序,把排名前n_candidate_k的IoU求和。由于IoU的值不会超过1,因此这个和的值区间为 0 ~ n_candidate_k 。记这个值为dynamic_k。
simOTA算法步骤四:计算候选区域产生的预测框与当前gtbox的cost值,得到Cost代价矩阵。该矩阵的计算公式为: ![]() 。
。 是平衡系数,
是平衡系数,![]() 和
和![]() 分别是一个gtbox和其预测框的分类损失和回归损失。该矩阵代表当前gtbox和预测框之间的代价关系,预测框的cost值越小越好。通过Cost矩阵,使网络能够自适应的找到每个gtbox的正样本。Cost代价矩阵由三个部分组成:
分别是一个gtbox和其预测框的分类损失和回归损失。该矩阵代表当前gtbox和预测框之间的代价关系,预测框的cost值越小越好。通过Cost矩阵,使网络能够自适应的找到每个gtbox的正样本。Cost代价矩阵由三个部分组成:
- 每个真实框和当前特征点的预测框的重合程度,重合程度越高,代表这个特征点已经尝试去拟合该真实框了,因此它的Cost代价就会越小。
- 每个真实框和当前特征点的预测框的分类精度,分类精度越高,也代表这个特征点已经尝试去拟合该真实框了,因此它的Cost代价就会越小。
- 每个真实框的中心是否落在了特征点的一定半径内。如果在特征点的一定半径内,同样代表这个特征点已经尝试去拟合该真实框了,因此它的Cost代价就会越小。
simOTA算法步骤五:将cost矩阵的值按从小到大的顺序排列。取前dynamic_k个cost最小的预测框作为当前gtbox最终的正样本,将其余剩下的预测框作为负样本。对于不同的gtbox,dynamic_k的值是不一样的。
simOTA算法步骤六:使用求出的最终正负样本来计算分类和回归损失。
接着我们来到代码分析环节,接着篇(七)的代码,定位到yolox\models\yolo_head.py脚本的橘色框(下图所示):
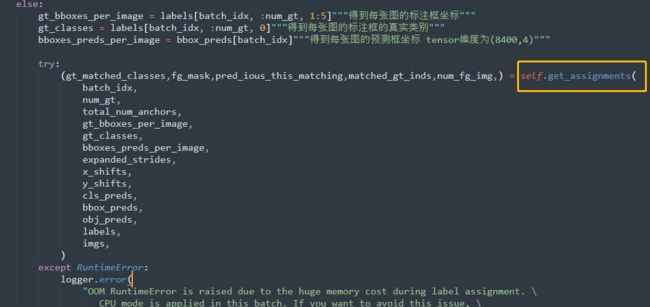
我们直接进入到该方法,输入参数的含义如下:
- batch_idx:batchsize的索引,代表每次只取一个batchsize中的一张图像。如果batchsize = 4,则batch_idx = 0,1,2,3.
- num_gt:当前图像有多少个gtbox。
- total_num_anchors:代表FPN生成特征图的全部像素点的个数,也即YOLOX对一张图像生成预测框的数量。值为20×20+40×40+80×80=8400.
- gt_bboxes_per_image:num_gt个gtbox的边框值。tensor的维度为(num_gt,4),4代表gtbox的中心点坐标和长宽。
- gt_classes:num_gt个gtbox的类别。
- bboxes_preds_per_image:8400个预测框的坐标信息。tensor的维度为(8400,4)。
- expanded_strides:ferture map上每个像素点的缩放比或预测框之间的步长。tensor的维度为(1,8400)。
- x_shifts,y_shifts:每个特征点在原特征图上的X坐标和Y坐标,对80×80的特征图而言,数值从0-79,对40×40的特征图而言,数值从0-39。该tensor的维度为(1,8400)。
- cls_preds:每个预测框的预测类别。tensor的维度为(B,8400,num_class),B代表batchsize通道。
- obj_preds:每个预测框的置信度。tensor的维度为(B,8400,1),B代表batchsize通道。
- 其他参数如:bbox_preds、imgs、labels函数内都没有用到。
该方法首先会执行get_in_boxes_info()方法来获取正样本的候选区域,该方法会得到绿色框和黄色框的交集和并集:
fg_mask, is_in_boxes_and_center = self.get_in_boxes_info(gt_bboxes_per_image,expanded_strides,x_shifts,
y_shifts,total_num_anchors,num_gt,)"""fg_mask是绿色框和黄色框的并集、is_in_boxes_and_center是绿色框和黄色框的交集"""我们跳到该方法,下面是该方法每一行代码的详细注释:
def get_in_boxes_info(self,gt_bboxes_per_image,expanded_strides,x_shifts,y_shifts,total_num_anchors,num_gt,):
expanded_strides_per_image = expanded_strides[0]"""去掉了一个维度,tensor变为(8400,)"""
x_shifts_per_image = x_shifts[0] * expanded_strides_per_image"""得到特征图上每个特征点对应真实图像上矩形感受野的左上角X坐标"""
y_shifts_per_image = y_shifts[0] * expanded_strides_per_image"""得到特征图上每个特征点对应真实图像上矩形感受野的左上角Y坐标"""
x_centers_per_image = ((x_shifts_per_image + 0.5 * expanded_strides_per_image).unsqueeze(0).repeat(num_gt, 1))"""得到特征图上每个特征点对应真实图像上矩形感受野的中心点X坐标"""
"""unsqueeze为增加维度方便计算,repeat为将当前数据复制标注框的个数倍(shape变为num_gt × 8400),因为每一个标注框都要与8400个预测框进行比较"""
y_centers_per_image = ((y_shifts_per_image + 0.5 * expanded_strides_per_image).unsqueeze(0).repeat(num_gt, 1))"""得到特征图上每个特征点对应真实图像上矩形感受野的中心点Y坐标"""
"""计算gtbox的四个边。这样做是因为输入YOLOX的是gtbox的左上角坐标和长宽,而gt_bboxes_per_image已经变换成了gtbox的中心点坐标和长宽"""
gt_bboxes_per_image_l = ((gt_bboxes_per_image[:, 0] - 0.5 * gt_bboxes_per_image[:, 2]).unsqueeze(1).repeat(1, total_num_anchors))"""得到gtbox左边x坐标"""
gt_bboxes_per_image_r = ((gt_bboxes_per_image[:, 0] + 0.5 * gt_bboxes_per_image[:, 2]).unsqueeze(1).repeat(1, total_num_anchors))"""得到gtbox右边x坐标"""
gt_bboxes_per_image_t = ((gt_bboxes_per_image[:, 1] - 0.5 * gt_bboxes_per_image[:, 3]).unsqueeze(1).repeat(1, total_num_anchors))"""得到gtbox上边y坐标"""
gt_bboxes_per_image_b = ((gt_bboxes_per_image[:, 1] + 0.5 * gt_bboxes_per_image[:, 3]).unsqueeze(1).repeat(1, total_num_anchors))"""得到gtbox下边y坐标"""
"""判断8400个中心点有哪些在gtbox内"""
b_l = x_centers_per_image - gt_bboxes_per_image_l"""特征图上每个特征点对应真实图像上矩形框的中心点X坐标要大于gtbox左边x坐标"""
b_r = gt_bboxes_per_image_r - x_centers_per_image"""特征图上每个特征点对应真实图像上矩形框的中心点X坐标要小于gtbox右边x坐标"""
b_t = y_centers_per_image - gt_bboxes_per_image_t"""特征图上每个特征点对应真实图像上矩形框的中心点Y坐标要大于gtbox上边Y坐标"""
b_b = gt_bboxes_per_image_b - y_centers_per_image"""特征图上每个特征点对应真实图像上矩形框的中心点Y坐标要小于gtbox下边Y坐标"""
bbox_deltas = torch.stack([b_l, b_t, b_r, b_b], 2)"""将四值进行连接"""
is_in_boxes = bbox_deltas.min(dim=-1).values > 0.0"""is_in_boxes的shape是(num_gt,8400),值为True或者False。True代表特征点对应原图的矩形框中心点在gtbox内"""
is_in_boxes_all = is_in_boxes.sum(dim=0) > 0"""一幅图中一共有多少个中心点在全部gtbox内,tensor为(8400)"""
center_radius = 2.5"""YOLOX的黄色区域"""
"""求黄色的框的每个边的坐标"""
gt_bboxes_per_image_l = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(1, total_num_anchors) - center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_r = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(1, total_num_anchors) + center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_t = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(1, total_num_anchors) - center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_b = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(1, total_num_anchors) + center_radius * expanded_strides_per_image.unsqueeze(0)
"""判断8400个中心点有哪些在黄色区域内"""
c_l = x_centers_per_image - gt_bboxes_per_image_l
c_r = gt_bboxes_per_image_r - x_centers_per_image
c_t = y_centers_per_image - gt_bboxes_per_image_t
c_b = gt_bboxes_per_image_b - y_centers_per_image
center_deltas = torch.stack([c_l, c_t, c_r, c_b], 2)
is_in_centers = center_deltas.min(dim=-1).values > 0.0
is_in_centers_all = is_in_centers.sum(dim=0) > 0
is_in_boxes_anchor = is_in_boxes_all | is_in_centers_all"""求黄色框和绿色框的并集"""
is_in_boxes_and_center = (is_in_boxes[:, is_in_boxes_anchor] & is_in_centers[:, is_in_boxes_anchor])"""求黄色框和绿色框的交集"""
return is_in_boxes_anchor, is_in_boxes_and_center接着继续get_assignments()方法,下面是一直到bboxes_iou()方法的全部注释,比较简单:
def get_assignments(self,batch_idx, num_gt, total_num_anchors,gt_bboxes_per_image,gt_classes,bboxes_preds_per_image,
expanded_strides,x_shifts,y_shifts,cls_preds,bbox_preds,obj_preds,labels,imgs,mode="gpu",):
if mode == "cpu":"""如果是CPU训练就将参数CPU化"""
print("------------CPU Mode for This Batch-------------")
gt_bboxes_per_image = gt_bboxes_per_image.cpu().float()
bboxes_preds_per_image = bboxes_preds_per_image.cpu().float()
gt_classes = gt_classes.cpu().float()
expanded_strides = expanded_strides.cpu().float()
x_shifts = x_shifts.cpu()
y_shifts = y_shifts.cpu()
fg_mask, is_in_boxes_and_center = self.get_in_boxes_info(gt_bboxes_per_image,expanded_strides,x_shifts,y_shifts,total_num_anchors,num_gt,)"""获取正样本的候选区域"""
bboxes_preds_per_image = bboxes_preds_per_image[fg_mask]"""shape从之前的(8400,4)变为(在并集区域内中心点的个数,4),这样可以大大减少计算量"""
cls_preds_ = cls_preds[batch_idx][fg_mask]"""shape从之前的(8400,num_class)变为(在并集区域内中心点的个数,num_class),这样可以大大减少计算量"""
obj_preds_ = obj_preds[batch_idx][fg_mask]"""shape从之前的(8400,4)变为(在并集区域内中心点的个数,4),这样可以大大减少计算量"""
num_in_boxes_anchor = bboxes_preds_per_image.shape[0]"""获取现在的bboxes_preds_per_image的个数"""
if mode == "cpu":"""cpu训练的话就将参数CPU化"""
gt_bboxes_per_image = gt_bboxes_per_image.cpu()
bboxes_preds_per_image = bboxes_preds_per_image.cpu()
pair_wise_ious = bboxes_iou(gt_bboxes_per_image, bboxes_preds_per_image, False)"""计算gtbox和预测框的IOU"""下面介绍bboxex_iou()方法,我们定位到yolox\utils\boxes.py中的bboxes_iou()方法,下面是一些简单的注释,可以忽略:
def bboxes_iou(bboxes_a, bboxes_b, xyxy=True):
"""bboxes_a为真实框(num_gt,4),bboxes_b为预测框(在候选区域内的像素点的预测框,4),"""
if bboxes_a.shape[1] != 4 or bboxes_b.shape[1] != 4:"""如过bbox的长度不为4,就出错啦。"""
raise IndexError
if xyxy:"""YOLOX框的形式不是xyxy,而是中心点的形式"""
tl = torch.max(bboxes_a[:, None, :2], bboxes_b[:, :2])
br = torch.min(bboxes_a[:, None, 2:], bboxes_b[:, 2:])
area_a = torch.prod(bboxes_a[:, 2:] - bboxes_a[:, :2], 1)
area_b = torch.prod(bboxes_b[:, 2:] - bboxes_b[:, :2], 1)
else:
tl = torch.max(
(bboxes_a[:, None, :2] - bboxes_a[:, None, 2:] / 2),"""真实框的左上角坐标:中心点坐标-长的一半"""
(bboxes_b[:, :2] - bboxes_b[:, 2:] / 2),"""预测框的左上角坐标:中心点坐标-长的一半"""
)
br = torch.min(
(bboxes_a[:, None, :2] + bboxes_a[:, None, 2:] / 2),"""真实框的右下角坐标:中心点坐标+长的一半"""
(bboxes_b[:, :2] + bboxes_b[:, 2:] / 2),"""预测框的右下角坐标:中心点坐标+长的一半"""
)
area_a = torch.prod(bboxes_a[:, 2:], 1)"""计算所有真实框的面积"""
area_b = torch.prod(bboxes_b[:, 2:], 1)"""计算所有预测框的面积"""
en = (tl < br).type(tl.type()).prod(dim=2)""""""
area_i = torch.prod(br - tl, 2) * en # * ((tl < br).all())
return area_i / (area_a[:, None] + area_b - area_i)接着bboxes_iou()方法往下走,首先给出几个loss的计算公式:
边界框loss的计算公式:
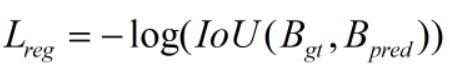
类别loss的计算公式:
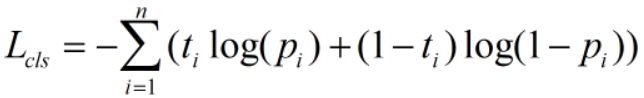
cost代价矩阵的计算公式,默认lambda = 3.0:
![]()
给出loss计算的代码注释:
"""真实框在每幅图像的方格中one_hot向量,输出tensor维度为(gtbox的个数,在并集区域内中心点的个数,类别数)"""
gt_cls_per_image = (F.one_hot(gt_classes.to(torch.int64), self.num_classes).float().unsqueeze(1).repeat(1, num_in_boxes_anchor, 1))
pair_wise_ious_loss = -torch.log(pair_wise_ious + 1e-8)"""边界框损失,iou 越大,匹配度越高,所以需要取负号"""
if mode == "cpu":
cls_preds_, obj_preds_ = cls_preds_.cpu(), obj_preds_.cpu()
cls_preds_ = (cls_preds_.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() * obj_preds_.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_())"""类别预测的sigmoid * 置信度预测的sigmoid = 类别分数"""
pair_wise_cls_loss = F.binary_cross_entropy(cls_preds_.sqrt_(), gt_cls_per_image, reduction="none").sum(-1)"""二值交叉熵计算类别综合loss值"""
del cls_preds_
"""构造cost矩阵,"""
cost = (pair_wise_cls_loss+ 3.0 * pair_wise_ious_loss+ 100000.0 * (~is_in_boxes_and_center))"""其中100000.0*(~is_in_boxes_and_center )指正样本取反,剩下的都是负样本,一方面需要最小化正样本的损失,同时意味着需要最大化负样本的损失。"""
"""cost值越小,表示匹配度越高"""
(num_fg,gt_matched_classes,pred_ious_this_matching,matched_gt_inds,) = self.dynamic_k_matching(cost, pair_wise_ious, gt_classes, num_gt, fg_mask)接着进入dynamic_k_matching()方法,其就是YOLOX的标签匹配策略,其参数含义如下:
- cost:通过回归损失和类别损失计算得到的cost。
- pair_wise_ious:全部的gtbox和全部预测框的IoU。
- gt_classes:每一个gtbox对应的类别。
- num_gt:gt的数量。
- fg_mask:绿色框和黄色框的交集。
该方法具体注释如下:
def dynamic_k_matching(self, cost, pair_wise_ious, gt_classes, num_gt, fg_mask):
matching_matrix = torch.zeros_like(cost)"""生成和cost维度一样的矩阵"""
ious_in_boxes_matrix = pair_wise_ious
n_candidate_k = min(10, ious_in_boxes_matrix.size(1))"""取10个或者不大于10,一会要把把排名前n_candidate_k的IoU求和"""
topk_ious, _ = torch.topk(ious_in_boxes_matrix, n_candidate_k, dim=1)"""topk为从大到小的排序,并取前n_candidate_k的IoU。维度为(num_gt,10),即每个gtbox都取自己排名前10的IoU"""
dynamic_ks = torch.clamp(topk_ious.sum(1).int(), min=1)"""获取每一个gtbox的正样本个数。clamp是区间函数,每一个目标保证必须有一个正样本,因此不能小于1"""
for gt_idx in range(num_gt):"""给每个gtbox都这样做"""
_, pos_idx = torch.topk(cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False)"""选取正样本"""
matching_matrix[gt_idx][pos_idx] = 1.0"""找到cost最小的位置,然后设置候选框矩阵对应位置为1"""
del topk_ious, dynamic_ks, pos_idx"""为了节约内存,释放这几个参数"""
anchor_matching_gt = matching_matrix.sum(0)
if (anchor_matching_gt > 1).sum() > 0:"""为了防止一个正样本对应两个真实框"""
_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)"""比较两个真实框谁的cost小就作为正样本,另外一个舍去"""
matching_matrix[:, anchor_matching_gt > 1] *= 0.0"""将大于1的那一列的所有数先全变为0"""
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0"""将cost最小的位置变为1"""
fg_mask_inboxes = matching_matrix.sum(0) > 0.0
num_fg = fg_mask_inboxes.sum().item()"""获取正样本的个数"""
fg_mask[fg_mask.clone()] = fg_mask_inboxes"""8400中有哪些是正样本"""
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)"""每个正样本对应的真实框的索引"""
gt_matched_classes = gt_classes[matched_gt_inds]"""每个正样本对应的真实类别"""
pred_ious_this_matching = (matching_matrix * pair_wise_ious).sum(0)[fg_mask_inboxes]"""每个正样本与真实框对应的IoU"""
return num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds有了dynamic_k_matching()方法返回的正负样本,就可以计算后面的loss。回到yolo_head.py中的get_losses()方法,接着进行:
torch.cuda.empty_cache()"""清除显存,释放空间"""
num_fg += num_fg_img"""总的正样本个数"""
cls_target = F.one_hot(gt_matched_classes.to(torch.int64), self.num_classes) * pred_ious_this_matching.unsqueeze(-1)"""得到num_class个类别对应的IoU"""
obj_target = fg_mask.unsqueeze(-1)"""以正样本的位置为置信度"""
reg_target = gt_bboxes_per_image[matched_gt_inds]"""框的目标"""
if self.use_l1:
l1_target = self.get_l1_target(
outputs.new_zeros((num_fg_img, 4)),
gt_bboxes_per_image[matched_gt_inds],
expanded_strides[0][fg_mask],
x_shifts=x_shifts[0][fg_mask],
y_shifts=y_shifts[0][fg_mask],
)
cls_targets.append(cls_target)"""把batchsize个图的正样本信息进行拼接"""
reg_targets.append(reg_target)"""把batchsize个图的正样本信息进行拼接"""
obj_targets.append(obj_target.to(dtype))"""把batchsize个图的正样本信息进行拼接"""
fg_masks.append(fg_mask)"""把batchsize个图的正样本信息进行拼接"""
if self.use_l1:
l1_targets.append(l1_target)
cls_targets = torch.cat(cls_targets, 0)
reg_targets = torch.cat(reg_targets, 0)
obj_targets = torch.cat(obj_targets, 0)
fg_masks = torch.cat(fg_masks, 0)
if self.use_l1:
l1_targets = torch.cat(l1_targets, 0)
num_fg = max(num_fg, 1)"""总的正样本个数"""
loss_iou = (self.iou_loss(bbox_preds.view(-1, 4)[fg_masks], reg_targets)).sum() / num_fg).sum() / num_fg"""计算IoU的loss"""
loss_cls = (self.bcewithlog_loss(cls_preds.view(-1, self.num_classes)[fg_masks], cls_targets)).sum() / num_fg"""二元交叉熵损失"""
if self.use_l1:
loss_l1 = (self.l1_loss(origin_preds.view(-1, 4)[fg_masks], l1_targets)).sum() / num_fg
else:
loss_l1 = 0.0
reg_weight = 5.0
loss = reg_weight * loss_iou + loss_obj + loss_cls + loss_l1"""总损失"""
return (loss,reg_weight * loss_iou,loss_obj,loss_cls,loss_l1,num_fg / max(num_gts, 1),)代码部分到这里就算结束了,但YOLOX代码往深了挖还是需要花很多时间的。