定量论文:探究「健康水平、婚姻状况」对幸福感的影响
点击蓝字关注这个神奇的公众号~
作者简介Introduction林筱越:华东政法大学 社会学专业 R语言爱好者
往期回顾:
使用ggplot2绘制心形
注:阅读全文大概需要10-15分钟
坐稳了没?要开车了哦
全文结构:
前言
数据筛选
数据预处理
部分数据重编码与合并
描述性统计部分
回归建模总结
这里如果算上「报告输出」是一套基本的数据分析流程,但是这都是后续工作,这里仅展示以R来进行数据处理的部分;不过「招无定式」,并不一定都按照这样的顺序来操作,仅供大家参考
1. 前言
由于是社会学专业,所以「统计学」也算是被纳入到了必修课当中;大一下的时候除了学习社会统计学之外,还学习了统计软件Stata(社科专业除了SPSS外,大多数会使用Stata)。
这里可以提一提Stata的特点,可以说是从「点击式」的SPSS到「命令式」的R一种中间过渡:
Stata也可以类似于spss一样点击操作,并且会出现操作命令,上手快;
全面的数据管理功能
同时Stata最强大的地方我觉得就是在它的回归建模部分,生成的结果可以说是十分全面了。
「统计学」与「Stata」的接触也为后面自学R语言以及其他数据分析的工具奠定了兴趣的基础吧,自己也被「定量」的研究方法所吸引,于是自己深入学习,先后入了R语言、Python、MySQL等大坑……
本次文章处理过程是选自我大二时「项目设计的理论与实践」所做的有关「健康水平、婚姻状况对于幸福感的影响」期末作业,也算是一篇小小的基础的社科定量论文吧;但是当时用的是Stata做的,由于之前的代码以不知道丢到哪里了,因此也只能尽量复现我之前的思路并呈现给大家,如有错误,请大家指正!
前期准备
本文所使用的数据集是来自[CGSS2015(中国社会综合调查)数据](http://cnsda.ruc.edu.cn./index.php?r=projects/view&id=62072446)(作业当时用的是2010版的,结果不会差太多),大家下载数据集后还需要下载pdf格式的问卷,不然无法理解数据的变量命名代表什么意思
使用工具:Rstudio
本文使用到的包有:
haven包(由于CGSS数据只有stata格式或SPSS格式,没有CSV格式,因此需要额外使用haven包读取)
tidyverse包(可以说这是一套搞定数据分析的大礼包了!高效强大)
其他包的部分函数

如果不想使用默认路径,也可以自己获取数据文件所在路径,在使用`read_spss()`函数时可以指定`path`参数即可
一定要加上文件拓展名(.sav)!否则会报错
2. 数据筛选
在论文研究过程中,往往选择一个变量作为研究切入点,然后再通过回归中加入其他自变量以及控制变量来输出结果考察,因此在做数据分析前需要挑选或限定,主要分为以下三部分:
因变量y:幸福感。(问卷A36题)
自变量x:健康水平(问卷A15题);婚姻状况(问卷A69题)
控制变量i:
性别(问卷A2题)
宗教信仰(问卷A5题)
政治面貌(问卷A10题)
教育程度(问卷A7a题)
年龄(问卷A3题,根据出生年月需要自行计算出年龄)
家庭年收入(问卷A62题)
接下来的步骤是需要将以上变量挑出,对数据集进行分割以提高计算效率(如果不减少变量,那么在Rstudio里查看数据集时会特别特别的卡顿!这也就是为什么我说Stata在数据管理上是全面的),这里使用到的是select()函数
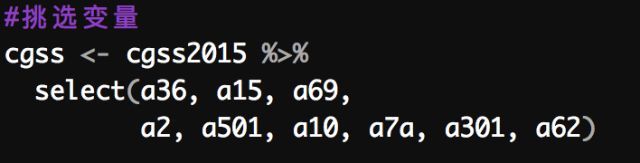
%>%是属于管道操作符,随tidyverse包一同加载;它会将左边的数据集自动导入后面的函数中,在不不赋值的情况下,能使得代码结果不占用内存;并且也提高了代码的整洁程度
由于问题编号与变量名并不完全一致,所以需要花点心思进行挑选,这里已经帮大家挑选好,直接复制代码即可
这里需要说明的是宗教信仰变量选项(a501),由于变量中
3. 数据预处理部分
挑选出研究的变量后,就需要对数据进行简单的查看、清洗;好在使用已经处理好的数据集,但是在读取数据的时候变量类型可能会有所改变,因此这时候需要做的就是对查看变量类型并对类型进行转换:
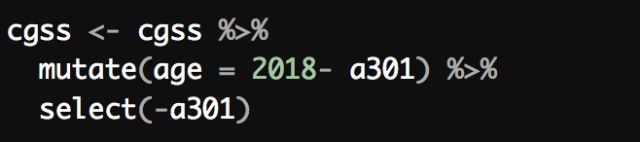
对于「年龄变量」,原数据中以出生年份的形式(a301)给出;因此为了方便研究,粗略取2018减去出生年份作为年龄,并创建年龄变量;最后去掉出生年份的变量,使数据整洁。这里使用到的是mutate函数:
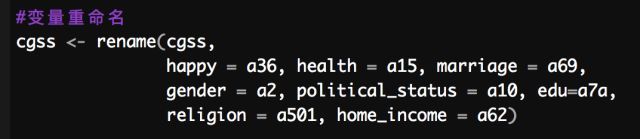
接着我们就需要对数据进行命名的修改,这里使用到的是rename函数:
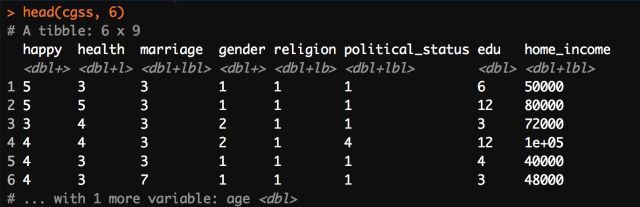
之后我们可以使用R基础的head函数来查看一下预处理后的数据集,可以看出数据集已经被我们化简了
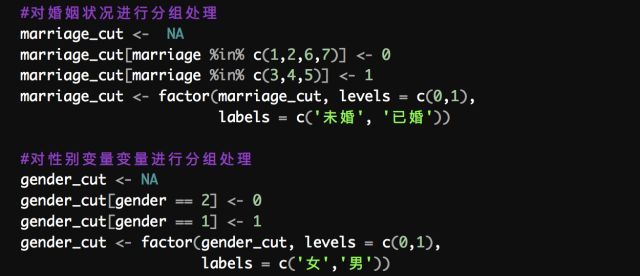
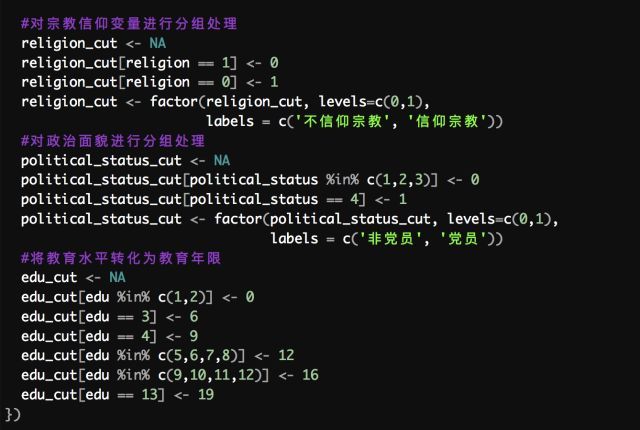
4. 数据重编码与合并
通过对数据初步观察,可以看到所有变量都是定距类型的数值变量,因此接下来就是分别进行类型的转换并重编码,并对部分变量的值进行适当的合并;对于分类变量统一用R基础的factor函数处理为因子;并且对「教育水平」变量(edu)将其从转化为「教育年限」数值变量(如小学=6,初中=9,以此类推)

接着还需要对收入变量进行调整,一般来说,学术界通用的方法是对其取对数,使收入能呈正态分布以便能更好的观察:
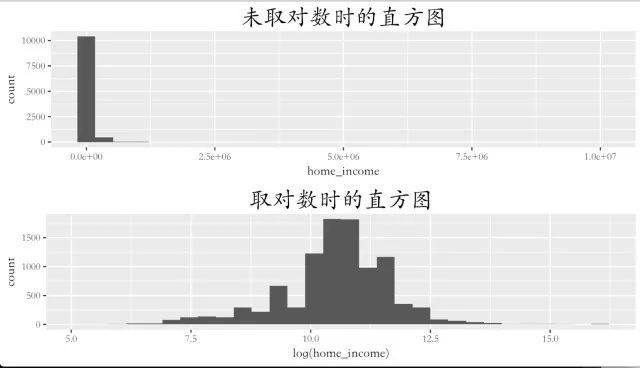

此时可能会提出警告出现了NaNs(Not a number)这一类型的值,因此后面需要统计一下这型的值有多少再作处理
至此可以看出数据清洗与重编码部分所花的代码量是最多的;毕竟大多数数据分析工作80%的时间可能都花在了数据的初步处理上。
做完以上的工作后,再次对数据集进行切片,挑选新的已经处理好的变量变量,然后创建新的、处理好的数据集;之后需要查看对数据集各变量进行一个基本的描述性统计,然后再查看一下缺失值和其他异常值的数量:

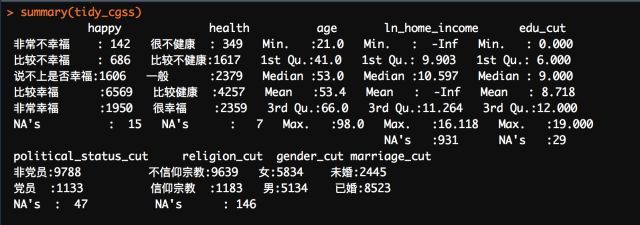
通过基本观察可以发现,除了收入变量外,大多数变量都包含了缺失值,但是数量并不多;收入变量的缺失从隐私的角度来理解的话或许可以解释得通,因为对于大多数人而言,往往倾向于保密自己的收入情况。
但是收入变量除了之前出现的NaN值外,还有-Inf(无限小)类型的值;很有可能是因为原始数据中出现误填或者是值过大的情况,所以在取对数时出现过小的情况,因此我们还需要查看一下缺失值、NaN值、Inf值的情况:
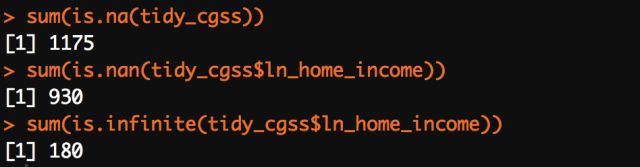
从返回结果看到相对于上万的样本量(在数据集观察窗口可以发现样本量N=10968)而言,缺失值只占到了大约10%,;而nan类型的值有930个,但是Inf类型的值有180,但是收入变量的缺失值已经达到了931个,所以怀疑缺失值很有可能导致前两种类型的值出现;所以,这里粗糙地将后两个类型的值归入缺失值后再查看一下缺失值的数量变化情况:

这里看出,最后缺失值只有1355个,实际上就是已有的缺失值加上Inf值的数量;那么nan值去哪了呢?其实nan和NA值是有一定关联的,或许说,NA值可以看作是nan值的一种,从官方帮助文档可以查看对于Nan的说明:
不过官方建议不要直接将nan值作为缺失值对待,这里为了方便演示而采取处理为缺失值的操作;如果在实际中出现的nan值特别多,那么就最好就要格外注意一下了!
最后提取无缺失值数据集:

5. 描述性统计部分
由于处理后的数据集分类变量居多,因此这里就使用到R基础的描述性统计函数来查看即可,就可以看到大多数变量的相关描述性统计:
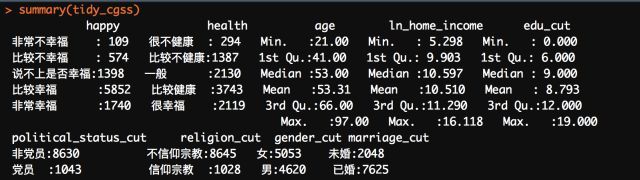
当然,如果还想查看一下一些变量的分布状况,如幸福感、年龄、以及家庭收入等,可以使用ggplot2来进行绘制,这里以画出幸福感和年龄的分布图形为例,这一部分仅是作为拓展:

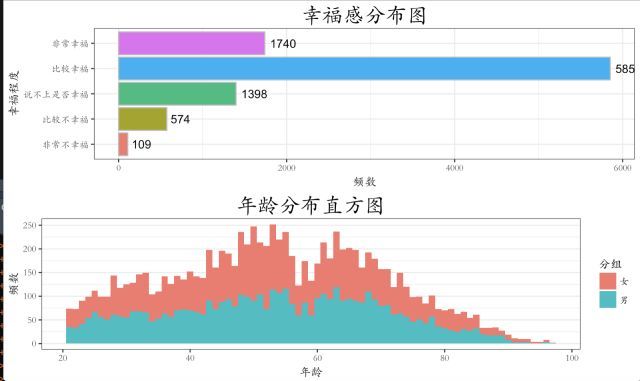
如果想学习ggplot2绘图更多的细节,可以参考《R graphics cookbook》
由于ggplot2的绘图有些特殊,R基础的「一页多图」方法无法起到作用,因此借助gridExtra包的grid.arrange函数来实现
6. 回归建模
由于因变量属于定序多分类变量,而R基础的glm函数适用于因变量为二分类变量;因此这就需要借用到MASS包的polr函数,最后用summary函数对回归结果进行提取,但是这里就不过多开展有关统计方法的东西,仅作为演示:
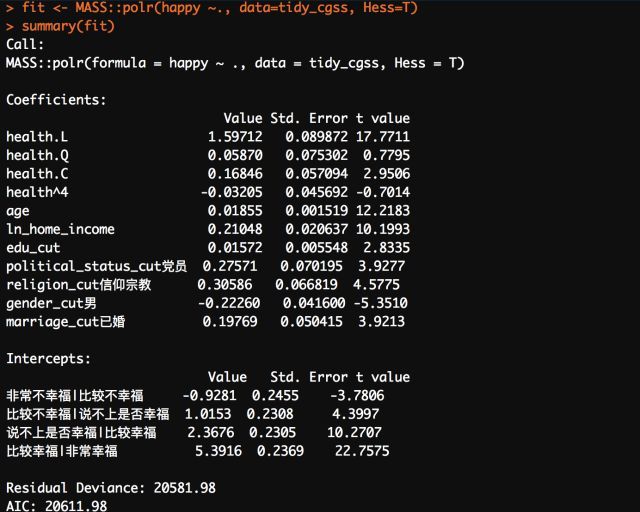
由于polr函数生成的结果没有p值,因此需要自己额外创建p值:
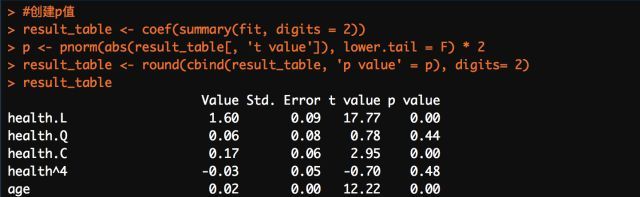
作为展示,这里的统计回归诸多细节这里并没有很好的展现与考虑,只能是一个很「粗糙」的回归
不得不说R提供的回归功能还不是很全面,因此需要借助到其他包来实现;这也就是为什么前面提到的Stata在回归模型输出方面是优于R的
7. 总结
本文主要借助了tidyverse包来完成了大部分操作,当然仍有一些部分的功能需要借助其他函数来实现;
大部分的代码都用在了数据的清洗与预处理上,大多数数据分析工作在前期的数据处理上需要花费大量的精力,否则后续工作只能是「垃圾进,垃圾出」
千万千万不要忽略掉缺失值和异常值!
但是R语言并不是没有缺陷,如在对面板数据的管理上我觉得是没有Stata那样完善
目前而言,在许多社科研究中大多数仍然是使用Stata或者Spss等较为简单的统计软件,但是如果花上一点时间掌握R语言,借助其他强大的包,可以实现比Stata和Spss等软件无法实现的功能
愿能与诸君共勉!
2017年R语言发展报告(国内)
R语言中文社区历史文章整理(作者篇)
R语言中文社区历史文章整理(类型篇)

公众号后台回复关键字即可学习
回复 R R语言快速入门及数据挖掘
回复 Kaggle案例 Kaggle十大案例精讲(连载中)
回复 文本挖掘 手把手教你做文本挖掘
回复 可视化 R语言可视化在商务场景中的应用
回复 大数据 大数据系列免费视频教程
回复 量化投资 张丹教你如何用R语言量化投资
回复 用户画像 京东大数据,揭秘用户画像
回复 数据挖掘 常用数据挖掘算法原理解释与应用
回复 机器学习 人工智能系列之机器学习与实践
回复 爬虫 R语言爬虫实战案例分享