中国人工智能大会是我国人工智能领域规格最高、规模最大、影响力最强的专业会议。时隔一年回顾CCAI 2018大会,我们不难印证,演讲者提出的很多设想与展望都正逐渐成为现实,他们的宝贵经验为产、学、研等领域引领了发展方向。

CCAI 2018《GDPR对AI的挑战和基于联邦迁移学习的对策》主题演讲实录摘编
杨强教授 中国人工智能学会副理事长、AAAI/ACM/IEEE Fellow、IJCAI理事长
人工智能曾经有过三个高峰,现在是处在第三个高峰。一个说法是我们正处于大数据时代,所以这一波的人工智能一定会成功。但让我们非常失望的是,很多的应用领域有的只是小数据,或者质量很差的数据。那么可不可以把很多散落在各地、各个机构的数据合并成大数据?我们发现,这样做是越来越难了,因为企业中间是有道墙的,形成数据源的隔离。这里有几个原因。首先公司间的数据合作要考虑利益的交换,然后不同部门和机构的行政批准流程也许很不一样;同时,现代社会对于用户隐私的要求也越来越高,公众的诉求和监管的要求也是不允许数据简单“粗暴”地进行交换的。因此很多数据的共享性很差。

欧盟最近引入了一个新的法案《通用数据保护条例》(General Data Protection Regulation,GDPR)。和以往的行业规范不同,这是一个真正可以执行的法律,违背它的后果是非常严重的,因为罚款可以高达被罚机构的全球营收的4%。研究界和企业现在满足这样或类似法规的程度如何?我觉得几乎是零。我们经常用到的做法,是在使用用户数据时都让用户划个钩,表示“同意”。但往往收集数据的一方并不是建立模型的一方,在实际应用中,大家习惯在一个地方收集数据,把数据转移到另外一个地方去处理和清洗,然后可能再把数据拿到另一个地方去建立模型,再把模型卖给第三方去应用。现在这个过程要非常小心,因为数据只要出了收集方就可能犯法。第三方使用模型的目的,也许产生原始数据的用户完全不知道,这就很有可能触犯GDPR的法律。数据在企业间的交换,无论加噪音与否,本身就违反了《通用数据保护条例》。

那么,GDPR是欧盟建立的,和我们有什么关系?我看到,最近对隐私和安全的考虑是一个世界的趋势,欧盟引入了这个法律,不能说明天美国和世界其他地方就不引入这个法律。同样,中国对数据的监管也是非常严格的,对用户数据的隐私保护也已经有相关的法案,而且越来越细化。这个趋势是世界性的。
2019年2月1日
全国信息安全标准化技术委员会公布了《信息安全技术 个人信息安全规范(草案)》全文,面向社会公开征求意见(意见反馈截止日期为2019年3月3日)
2019年2月27日
美国参议院提出《数据隐私法案》。这个法案加强了对美国消费者的数据隐私保护,同时确保企业专注于实施新的数据安全标准以及采用必要的隐私保护措施。法案还增加了对保护美国公民隐私技术研究的规定,并确保小企业免受不必要的监管。
在数据保护日趋严格的当下,能否在满足法律法规要求,保护用户数据隐私的前提下进行合作?我们提出一个可能的解决方案,叫做联邦迁移学习。我们所希望看到的是,假设有三个不同的企业A、B和C,每个企业都有不同数据。比如,第一个企业A有一些用户特征数据;第二个企业B有其他的一些用户特征数据,同时也包括一些标注数据;第三个企业C是一个银行,可能有有关金融的特征和标注数据。这三个企业按照GDPR准则是不能粗暴地把三方数据加以合并,因为他们的用户并没有同意这样做。假设在三方各自建立一个模型,而这个行为已经获得各自用户的认可。我们希望做到的是各个企业的自有数据不出本地,就像把自己围一个圈,围起来。然后,系统可以通过加密机制下的参数交换方式,在不违反法规情况下,建立一个虚拟的共有模型。这个虚拟模型的效果就好像大家把数据聚合在一起一样,但是实际上数据本身不移动,也不泄露隐私,模型在各自的区域还是为本地的目标服务。在这样一个机制下,各个参与者的身份和地位相同,这就是为什么这个体系叫做“联邦学习”。
我们建立这个机制,不是只把参数从A转到C、从C转到B那么简单,实际上对最后模型的效果是有要求的——既要安全,又要有效。安全是指数据在本地不能移出,而模型的参数被第三方处理时不仅要加密,而且要保证不能被反推原始用户的任何特征;效果高是指所谓的Lossless,就是效果要符合无损失原则,在A、B和C的模型效果要和把数据真正聚合在一起一样。这两个要求对AI的从业者是一个挑战。

那么,这个要求能不能做到?
首先看一下最近业界的一些进展。谷歌最近提出了一个针对安卓手机模型更新的数据加密需求,建立的一种联邦学习方案。比如,使用安卓手机时,会不断汇聚数据到安卓云上进行处理。联邦学习就是针对这样的过程,首先在每个终端上进行模型建设,参与者的特征相同,但他们做的模型可能很弱,虽然功能都一样。然后在云端把单个的模型加以聚合形成大的模型,大的模型再分发到各自终端里。参与者特征相同,样本不同,这样不断的聚合使得模型加以更新;同时通过加密算法,使得云端并没有解密终端传来的模型,同样别的终端也没有办法解密邻居的数据。

2019年3月
Google 开源了一款名为 TensorFlow Federated (TFF)的框架,可用于去中心化(decentralized)数据的机器学习及运算实验。它实现了一种称为联邦学习(Federated Learning,FL)的方法,将为开发者提供分布式机器学习,以便在没有数据离开设备的情况下,便可在多种设备上训练共享的机器学习模型。其中,通过加密方式提供多一层的隐私保护,并且设备上模型训练的权重与用于连续学习的中心模型共享。
另外一种联邦学习是假设我们有原始数据和一个建立好的模型,那么在应用这个模型到原始数据时会不会泄露隐私?这里有个算法叫做CryptoDL,是应用同态加密算法于多项式形态的激活函数。这样的好处是可以把原始数据加密,然后用这个模型做决策,得到的结果也是一个加密的结果。我们把加密的结果传到终端,终端可以解密实施。在整个过程中,通过这个加密机制,模型并不知道自己在做什么决策。所以说,这是在应用Inference时使用的。
2019年4月
在《时代》百大人物峰会上,创新工场创始人李开复谈及数据隐私保护和监管问题时,表示:“人们不应该只将人工智能带来的隐私问题视为一个监管问题,可尝试用‘以子之矛攻己之盾’——用更好的技术解决技术带来的挑战,例如同态加密、联邦学习等技术。”
刚才讲的例子都是把数据横向分段,横向的每段都是不同的用户样本,他们的特征一样。还有一种分割的方法就是按照特征来分段,可以看作是纵向分段,对应于两个不同机构,机构A和机构B它们的特征不一样。那么,我们希望在一个虚拟的第三方能够把这些特征,在加密的状态下加以聚合,以增强各自模型的能力。这种联邦学习,因为加密算法的原因,只能对某些类的模型使用,比如逻辑回归模型。当时对很多其他模型,我们还不知道行不行。最近经过研究发现,联邦学习对于树型结构模型也是可以用的。例如,在这有一个企业、有一个数据集,那边也有一个企业和一个数据集,通过这种加密技术可以使两边的树都得到成长。有了树模型以后就很自然可以发展到森林模型。
2019年1月25日
(Kewei Cheng, Tao Fan, Yilun Jin, Yang Liu, Tianjian Chen,Qiang Yang,“SecureBoost: A Lossless Federated Learning Framework”,arXiv:1901.08755,Submitted on 25 Jan 2019)本文提出了一个基于联邦学习的,新的无损、保护隐私的提升树(tree-boosting)系统 SecureBoost 安全树模型。它可以让多个机构的学习过程共同进行,用户样本只需要有一部分相同,但可以使用完全不同的特征集,相当于对应了不同的垂直分组的虚拟数据集。SecureBoost 安全树模型的优点是,它在训练数据保持多方相互保密的前提下,可以达到和不保护隐私的方法相同的性能;而且这个过程还不需要一个共同信任的第三方参与。
上面所述的“联邦学习”的优点是,在不具体交换原数据的情况下,以及对用户ID的差值不泄露的情况下,A和B两边可以参与联邦学习的网络。在这个网络里就可以建立一个共同模型,这个模型的参数可以分别独立持有。也就是说,两边的模型都可以得到成长,但是它们却不直接互相沟通。这样用户的样本和用户的特征都不泄露,已经满足GDPR大部分的要求。不同企业和机构可以形成一个“朋友圈”,在其中用这种联邦学习一起建模。联邦的意思就是各个数据的拥有体,大家是平等的。
2019年7月
(Luping Wang,Wei Wang,and Bo Li,“CMFL:Mitigating Communication Overhead for Federated Learning”to appear in IEEE ICDCS'19,Dallas,TX,July,2019.)本文提出了通信缓解联合学习(CMFL)概念。CMFL为客户提供有关模型更新的全局趋势的反馈信息。每个客户检查其更新是否与此全局趋势一致,并且与模型改进相关。通过避免将那些不相关的更新上传到服务器,CMFL可以大大减少联邦学习的通信开销,同时仍然保证学习收敛。
回到一开始讲的联邦学习的应用,可以把我刚才讲的应用分为四种分类的子应用,第一种情况是数据分别在两个不同的企业,它们特征相近、样本也相同,这是个简单情况,在本地建模就好,不需要沟通。第二种情况,如果特征一样、样本不一样,要让两个领域之间能够协同,可以引入Google这样的联邦学习方式,不断更新一个总模型,再分发到各个终端去;如果特征不一样、样本一样就可以引入纵向的联邦学习和同态加密技术,在一些逻辑回归或树形模型上加密、合并、更新;如果特征、样本都不一样的两个企业,它们中间的交集很少,这时就要为它进行迁移学习的建模,并在建模当中保证不能反推用户个体信息。
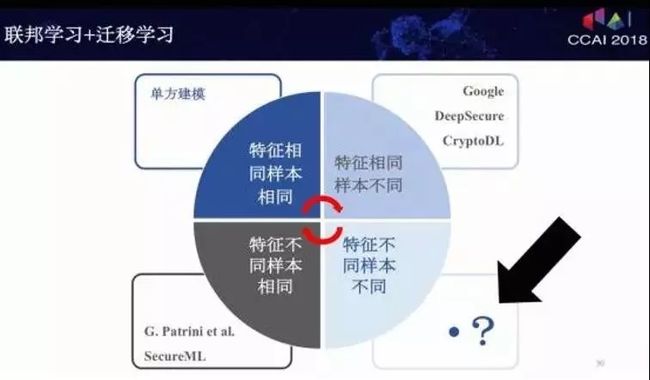
2018年12月8日
(Yang Liu,Tianjian Chen,Qiang Yang,“Secure Federated Transfer Learning”,arXiv:1812.03337,Submitted on 8 Dec 2018)本文的提出联邦传输学习(FTL)针对的是有标签学习(监督学习)任务,利用整个数据联邦内的数据资源,提高每个成员的模型的表现。通过联邦迁移学习框架,联邦内不同的成员之间可以在严守数据隐私的前提下共同挖掘数据的价值,而且可以在网络内转移补充性的数据。
总之,目前AI的发展并不是大家所想的那么乐观。因为现在社会大众和监管机构对数据的安全、隐私非常重视,面对这个重视程度AI界还做得远远不够。今后用简单粗暴方式进行多方数据的聚合是不可能的。那么,AI的路应该怎么走?可以有不同的答案。我这里介绍的是一个技术手段——联邦迁移学习——也许是一个出路。同时,我们也有一个联邦生态的建议,就是建立一个联邦学习的企业和机构联盟,监管部门可以作为其中一个单元,把监管的要求变成解决方案的一部分,让大家共同成长。
