1.写唯一ID生成器的原由
在阅读工程源码的时候,发现有一个工具职责生成一个消息ID,方便进行全链路的查询,实现方式特别简单,核心源码不过两行,根据时间戳以及随机数生成一个ID,这种算法ID在分布式系统中重复的风险就很明显了。本来以为只是日志打印功能,根据于此在不同系统调用间关联业务日志而已,不过后来发现此ID需要入库,看到这里就觉得有些风险了,于是就想着怎么改造它。
String timeString = String.valueOf(System.currentTimeMillis());
return Long.parseLong(timeString.substring(timeString.length() - 8, timeString.length()))
* RandomUtils.nextInt(1, 9);
2. Twitter snowflake
既然是分布式唯一ID,自然而然想到了Twitter的snowflake算法,在以前的做的部分业务中也用到过它来生成数据库主键ID,不过当时仅限于使用,以及将64 bit的long数字拆分成几个部分,以保证唯一,对具体实现没有深入研究。正好借着机会深入下。
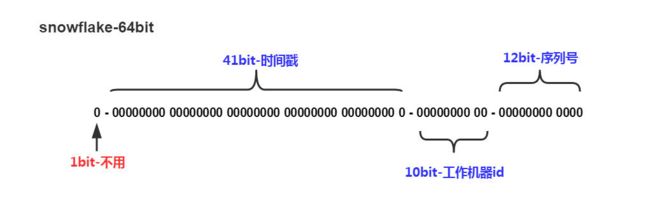
该ID生成方式,用41位时间戳保存当前时间的毫秒数(69年后一个轮回),十位机器码,最多可以供一项业务1024台实例,每个毫秒数,12位序列自增,每秒理论上单机环境可生产409.6万个ID,分享一个官方github的scala实现,twitter-archive/snowflake。
3.关于snowflake的一些思考
1.监视器锁
此锁的目的是为了保证在多线程的情况下,只有一个线程进入方法体生成ID,保证并发情况下生成ID的唯一性,如果在竞争激烈情况下,自旋锁+ CAS原子变量的方式或许是更为合理的选择,可以达到优化部分性能的目的。

2.时间回退问题
时间校准,以及其他因素,可能导致服务器时间回退(时间向前快进不会有问题),如果恰巧回退前生成过一些ID,而时间回退后,生成的ID就有可能重复。官方对于此并没有给出解决方案,而是简单的抛错处理,这样会造成在时间被追回之前的这段时间服务不可用,显然我无法接受这一点。

而对于此的思考是,既然snowflake理论情况下单机可实现每秒409.6万个ID的生成上限,实际上能想得到的业务都不太可能产生如此高的并发,那么就会存在在过去的一段时间内,有大量的时间戳“被浪费”,达不到该上限,可能在某一毫秒内只生成几个ID,如果发生了时间回退,这些“被浪费”的资源是不是就能利用起来,而不是抛错。
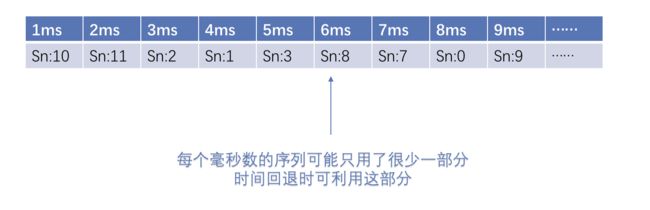
如果在内存中建立一个数组,这个数组设定固定长度,比如说200,这些数组中存储上一次该位置对应的毫秒数的messageId,那么就能在时间回退到追回时间这段时间内,再至多提供819200((2^12) *200)个messageId,如果发生时间回退,就只用在上一次messageId进行+1操作,直到系统时间被追回(此段结合后续源码进行解释)。
4.改进版的snowflake
1.机器码生成器 MachineIdService设计及其实现:
public interface MachineIdService {
/**
* 生成MachineId的方法
*
* @return machineId 机器码
* @throws MessageIdException 获取机器码可能因为外部因素失败
*/
Long getMachineId() throws MessageIdException;
}
实现该接口确保一个集群中,每台实例生成不同的machineID,并且MachineID 不能超过(2^10) 1023,具体实现方式,可使用MySQL数据库,文件描述映射,Redis自增等方式,这里我使用了Redis自增的方式(所以在需要用到该ID生成器的地方需要依赖Redis),具体实现方式如下:
public class RedisMachineIdServiceImpl implements MachineIdService {
private static final String MAX_ID = "MAX_ID";
private static final String IP_MACHINE_ID_MAPPING = "IP_MACHINE_ID_MAPPING";
private RedisTemplate redisTemplate;
private String redisKeyPrefix;
//设置RedisTemplate实例
public void setRedisTemplate(RedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
// 设置redisKey前缀,如果多个业务使用同一个Redis集群,使用不同的Redis前缀进行区分
public void setRedisKeyPrefix(String redisKeyPrefix) {
this.redisKeyPrefix = redisKeyPrefix;
}
@Override
public Long getMachineId() throws MessageIdException {
String host;
try {
//获取本机IP地址
host = InetAddress.getLocalHost().getHostAddress();
} catch (UnknownHostException e) {
throw new MessageIdException("Can not get the host!", e);
}
if (redisTemplate == null) {
throw new MessageIdException("Can not get the redisTemplate instance!");
}
if (redisKeyPrefix == null) {
throw new MessageIdException("The redis key prefix is null,please set redis key prefix first!");
}
HashOperations hashOperations = redisTemplate.opsForHash();
//通过IP地址在Redis中的映射,找到本机的MachineId
Long result = hashOperations.get(redisKeyPrefix + IP_MACHINE_ID_MAPPING, host);
if (result != null) {
return result;
}
//如果没有找到,说明需要对该实例进行新增MachineId,使用Redis的自增函数,生成一个新的MachineId
Long incrementResult = redisTemplate.opsForValue().increment(redisKeyPrefix + MAX_ID, 1L);
if (incrementResult == null) {
throw new MessageIdException("Get the machine id failed,please check the redis environment!");
}
//将生成的MachineId放入Redis中,方便下次查找映射
hashOperations.put(redisKeyPrefix + IP_MACHINE_ID_MAPPING, host, incrementResult);
return incrementResult;
}
}
2.MessageIdService设计以及实现
public interface MessageIdService {
/**
* 生成一个保证全局唯一的MessageId
*
* @return messageId
*/
long genMessageId();
/**
* 初始化方法
*
* @throws MessageIdException
*/
void init() throws MessageIdException;
}
public class MessageIdServiceImpl implements MessageIdService {
private static final Logger LOGGER = LoggerFactory.getLogger(MessageIdServiceImpl.class);
//最大的MachineId,1024个
private static final long MAX_MACHINE_ID = 1023L;
//AtomicLongArray 环的大小,可保存200毫秒内,每个毫秒数上一次的MessageId,时间回退的时候依赖与此
private static final int CAPACITY = 200;
// 时间戳在messageId中左移的位数
private static final int TIMESTAMP_SHIFT_COUNT = 22;
// 机器码在messageId中左移的位数
private static final int MACHINE_ID_SHIFT_COUNT = 12;
// 序列号的掩码 2^12 4096
private static final long SEQUENCE_MASK = 4095L;
//messageId ,开始的时间戳,start the world,世界初始之日
private static long START_THE_WORLD_MILLIS;
//机器码变量
private long machineId;
// messageId环,解决时间回退的关键,亦可在多线程情况下减少毫秒数切换的竞争
private AtomicLongArray messageIdCycle = new AtomicLongArray(CAPACITY);
//生成MachineIds的实例
private MachineIdService machineIdService;
static {
try {
//使用一个固定的时间作为start the world的初始值
START_THE_WORLD_MILLIS = SimpleDateFormat.getDateTimeInstance().parse("2018-09-13 00:00:00").getTime();
} catch (ParseException e) {
throw new RuntimeException("init start the world millis failed", e);
}
}
public void setMachineIdService(MachineIdService machineIdService) {
this.machineIdService = machineIdService;
}
/**
* init方法中通过machineIdService 获取本机的machineId
* @throws MessageIdException
*/
@Override
public void init() throws MessageIdException {
if (machineId == 0L) {
machineId = machineIdService.getMachineId();
}
//获取的machineId 不能超过最大值
if (machineId <= 0L || machineId > MAX_MACHINE_ID) {
throw new MessageIdException("the machine id is out of range,it must between 1 and 1023");
}
}
/**
* 核心实现的代码
*/
@Override
public long genMessageId() {
do {
// 获取当前时间戳,此时间戳是当前时间减去start the world的毫秒数
long timestamp = System.currentTimeMillis() - START_THE_WORLD_MILLIS;
// 获取当前时间在messageIdCycle 中的下标,用于获取环中上一个MessageId
int index = (int)(timestamp % CAPACITY);
long messageIdInCycle = messageIdCycle.get(index);
//通过在messageIdCycle 获取到的messageIdInCycle,计算上一个MessageId的时间戳
long timestampInCycle = messageIdInCycle >> TIMESTAMP_SHIFT_COUNT;
// 如果timestampInCycle 并没有设置时间戳,或时间戳小于当前时间,认为需要设置新的时间戳
if (messageIdInCycle == 0 || timestampInCycle < timestamp) {
long messageId = timestamp << TIMESTAMP_SHIFT_COUNT | machineId << MACHINE_ID_SHIFT_COUNT;
// 使用CAS的方式保证在该条件下,messageId 不被重复
if (messageIdCycle.compareAndSet(index, messageIdInCycle, messageId)) {
return messageId;
}
LOGGER.debug("messageId cycle CAS1 failed");
}
// 如果当前时间戳与messageIdCycle的时间戳相等,使用环中的序列号+1的方式,生成新的序列号
// 如果发生了时间回退的情况,(即timestampInCycle > timestamp的情况)那么不能也更新messageIdCycle 的时间戳,使用Cycle中MessageId+1
if (timestampInCycle >= timestamp) {
long sequence = messageIdInCycle & SEQUENCE_MASK;
if (sequence >= SEQUENCE_MASK) {
LOGGER.debug("over sequence mask :{}", sequence);
continue;
}
long messageId = messageIdInCycle + 1L;
// 使用CAS的方式保证在该条件下,messageId 不被重复
if (messageIdCycle.compareAndSet(index, messageIdInCycle, messageId)) {
return messageId;
}
LOGGER.debug("messageId cycle CAS2 failed");
}
// 整个生成过程中,采用的spinLock
} while (true);
}
}