SSM框架学习----Mybatis (4)
Mybatis----终
- 1. Mybatis延迟加载策略
-
- 1.1. 何为延迟加载
- 1.2. 何为立即加载
- 1.3. 使用Association实现延迟加载
-
- 1.3.1. 只查询帐户信息的Dao接口
- 1.3.2. AccountDao.xml映射文件
- 1.3.3. UserDao接口以及UserDao.xml映射文件
- 1.3.4. 开启Mybatis的延迟加载策略
- 1.3.5. 一对多查询的延迟加载
- 2. Mybatis缓存
-
- 2.1. 缓存
- 2.2. 一级缓存
- 2.3. 一级缓存的分析
- 2.4. 二级缓存
-
- 2.4.1. 二级缓存的使用步骤
- 2.4.2 二级缓存的测试
- 3. Mybatis注解开发
-
- 3.1. 使用Mybatis注解实现CRUD操作
-
-
- 3.1.1. 查询所有操作
- 3.1.2. 增,删,改以及聚合函数的查询
-
- 3.2. 使用注解实现复杂关系的映射开发
-
-
- 3.2.1. 实体类的属性与表中的字段不一致
- 3.2.2. 实现多对一的查询
- 3.2.3. 实现一对多查询
- 3.2.4. 一级缓存和二级缓存
-
1. Mybatis延迟加载策略
1.1. 何为延迟加载
在真正使用数据时才发起查询,不用的时候不查询,按需加载(懒加载)。如:在查询用户信息时,用户对应的帐户信息应该是什么时候用什么时候加载。
优点:先从单表查询,需要时再从关联表去关联查询,大大提高数据库性能,因为查询单表相比查询关联表速度快
缺点:只有当需要用到数据时,才会进行数据库查询,在大批量的数据查询时,查询工作耗时间,造成用户体验不佳。
1.2. 何为立即加载
不管数据用不用,只要一调用,马上发起查询。如:查询账户信息时,账户所属的用户信息应该是随着账户查询一起被查询出来。
对于四种表关系中:
- 一对一,多对一:通常情况下采用立即加载,如:查询账户 -> 用户
- 一对多,多对多:通常情况下采用延迟加载,如:查询用户 -> 账户
1.3. 使用Association实现延迟加载
需求:查询账户信息的同时查询用户信息
Account实体类中加入一个User类的对象
1.3.1. 只查询帐户信息的Dao接口
select * from account;
AccountDao.xml中添加查询账户信息的方法:
<select id="findAll" resultMap="accountUserMap">
select * from account;
</select>
1.3.2. AccountDao.xml映射文件
<!-- 定义封装Account和User的resultMap type表示主体类为Account-->
<resultMap id="accountUserMap" type="account">
<!-- property对应实体类Account column对应数据库中Account表的属性名 -->
<id property="id" column="id"></id>
<result property="uid" column="uid"></result>
<result property="money" column="money"></result>
<!-- 一对一的关系映射,配置封装User的内容 property对应user类,column的uid为Account中的外码
由于多对一结果关系映射,所以使用association 实现延迟加载使用select标签
select属性指定的内容,查询用户的唯一标识 -->
<association property="user" column="uid" javaType="user" select="com.huzhen.dao.UserInterface.findById">
</association>
</resultMap>
在association标签中增加select属性,这里指定的内容为查询用户的唯一标识,也就是根据UserDao映射文件中的按id查询方法:
全限定类名 + 方法名
1.3.3. UserDao接口以及UserDao.xml映射文件
UserDao.xml中根据id查询用户的方法定义如下:
<select id="findById" parameterType="INT" resultType="User">
select * from user where id=#{Uid};
</select>
注意:这里的id name findById与上面AccountDao.xml中的select属性的方法名是对应的。
在测试类中进行测试:
@Test
public void testFindAll(){
List<Account> list = accountDao.findAll();
for(Account account : list){
System.out.println("每个Account信息: ");
System.out.println(account);
System.out.println(account.getUser());
}
}
输出结果为:

由于Account表中对应的全部Uid只有4个:
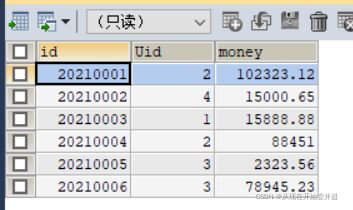
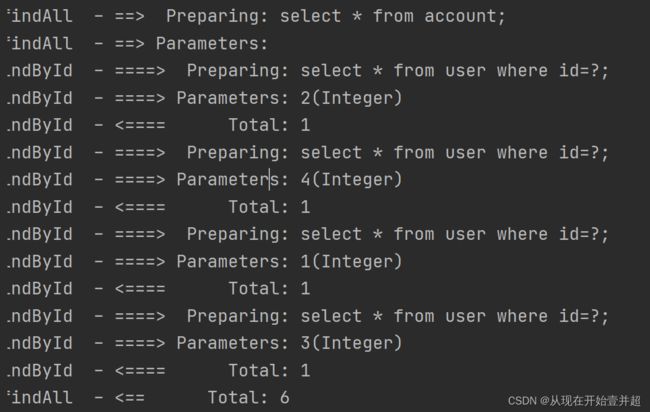
因此在终端显示的sql语句中,会存在4个:
select * from user where id=?;
1.3.4. 开启Mybatis的延迟加载策略
进入Mybatis的官方文档,找到XML配置中的settings说明:

需要在Mybatis中的SqlMapConfig.xml配置文件中添加延迟加载的配置:
<!-- 配置延迟加载策略 -->
<settings>
<!-- 打开延迟加载的开关 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 将积极加载改为消息加载也就是按需加载 在mybatis 3.4.1版本之后该参数默认为false-->
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
配置之后,再次测试发现此时的sql语句与上面的有所不同:
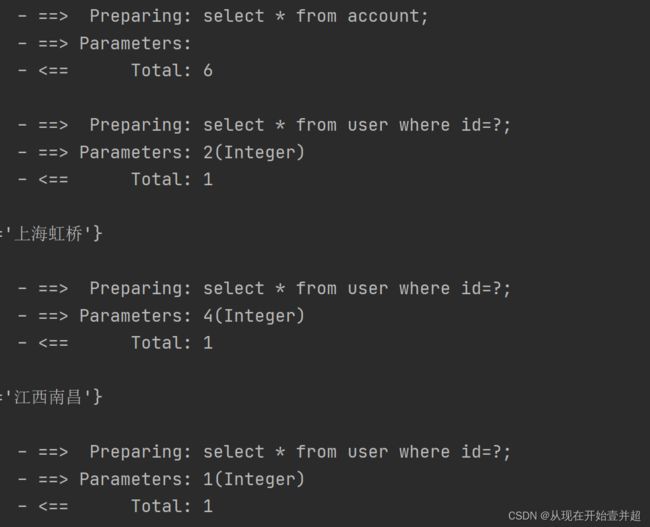
这里看的不是很清晰的话,将测试类中的输出语句删除掉,仅仅是输出账户信息:
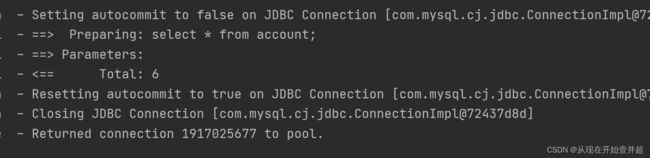
此时的sql语句只有:
select * from account;
可以看出并没有查询用户信息的sql语句,仅仅只有查询account表的语句
1.3.5. 一对多查询的延迟加载
需求:查询用户的同时查询对应的账户信息,不再像之前一样使用立即加载策略,而是使用延迟加载来实现
- 在UserDao.xml中配置resultMap
<resultMap id="userAccountMap" type="user">
<id property="id" column="id"></id>
<result property="username" column="username"></result>
<result property="birthday" column="birthday"></result>
<result property="sex" column="sex"></result>
<result property="address" column="address"></result>
<!-- 配置User实体类中的Accounts集合的映射 property表示User类中Account集合的成员变量名
ofType表示集合中的泛型, 如果没有使用typeAliases配置别名,则此时需要指定Account的全限定类名
由于是一对多关系结果映射,所以使用collection
对于一对多的延迟加载,使用select来关联AccountDao接口中的方法
并且指定column,表示使用用户的id去查询-->
<collection property="accounts" ofType="account"
select="com.huzhen.dao.AccountInterface.findAccountByUid" column="id">
</collection>
</resultMap>
<!-- 使用左外连接返回左表(User)的全部数据 该语句实现的立即加载,同时读取两个表
在这里使用关联开启延迟加载策略来实现按需加载,因此只需要查询用户信息的sql语句即可-->
<select id="findUserAndAccount" resultMap="userAccountMap">
select * from user;
</select>
collection标签中的select属性对应的值与上面的例子类似:全限定类名 + 方法名,column中的id表示根据用户的id来查询对应的账户信息
<select id="findAccountByUid" resultType="account">
select * from account where uid = #{uid};
</select>
- 如果使用之前提过的左外连接的sql语句来查询,实现的是两个关联表的查询,当查询用户的同时,会立即加载账户信息:
select t1.*, t2.id as Aid, t2.uid, t2.money
from user t1 left outer join account t2
on t1.id = account.uid;
这并不是我们所需要的,因此需要在SqlMapConfig.xml中配置将延迟加载开关lazyLoadingEnabled设置为true,并且同级加载开关aggressiveLazyLoading设置为false,此时在测试类中进行测试:
/**
* 测试查询所有用户信息以及所关联的帐户信息,使用的是延迟加载策略
*/
@Test
public void testFindUserAndAccount(){
List<User> list = userDao.findUserAndAccount();
for(User user : list){
System.out.println("User Information: ");
System.out.println(user);
// System.out.println(user.getAccounts());
// }
}
输出结果为:
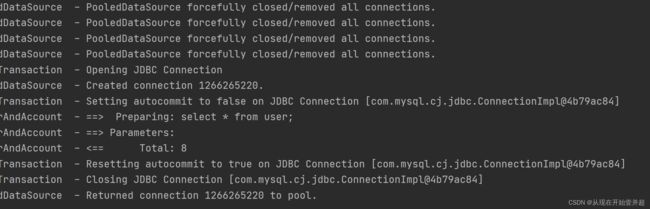
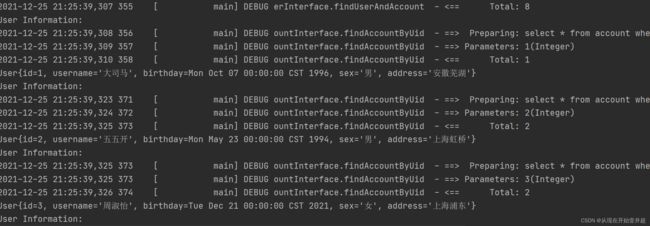
可以看到这里只打印出了用户信息,而用户下的账户信息并没有输出,实现了一对多的延迟加载策略。
2. Mybatis缓存
2.1. 缓存
缓存是什么:在Mybatis中允许使用缓存,缓存是存在于内存中的临时数据,一般放置在可高速读写的存储器上,如服务器的内存。
为什么使用缓存:减少和数据库的交互次数,提高执行效率。
什么样的数据适合用缓存:经常查询并且不经常改变的,数据的正确与否对最终结果影响不大的。
什么样的数据不适合用缓存:经常改变的数据,数据的正确性对最终结果影响很大,如:商品的库存,银行的汇率,股市的牌价等。
2.2. 一级缓存
指的是Mybatis中SqlSession对象的缓存。
当我们执行查询后,查询的结果会同时存入到SqlSession提供的一块区域中,该区域的结构是一个Map,当我们再次查询同样的数据,Mybatis会先去SqlSession中查看是否有,存在则直接拿出来使用;
当SqlSession对象消失时,mybatis的一级缓存也就消失了。
测试同一个sqlSession对象的sql查询结果:
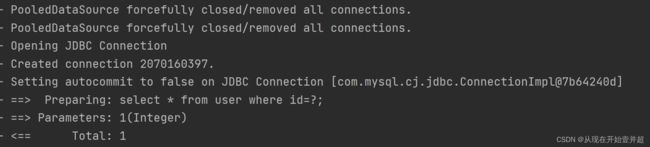

测试不同sqlSession的查询:
@Test
public void testFirstLevelCache(){
/*
SqlSession的一级缓存机制,当查询重复时,只会执行依次查询语句:select * from user where id = ?;
并且两个查询结果是相同的,证明后面的查询结果是从缓存中取的
当SqlSession关闭之后,再次进行重复的查询,此时返回的两个user对象不再相同,由于一级缓存随着SqlSession
的关闭而消失,因此会获取两个不同的Connection连接
*/
User user1 = userDao.findById(1);
System.out.println(user1);
// sqlSession.close();
sqlSession.clearCache(); // 此方法也可以清空缓存
sqlSession = factory.openSession();
userDao = sqlSession.getMapper(UserInterface.class);
User user2 = userDao.findById(1);
System.out.println(user2);
System.out.println(user1 == user2);
}
这里如果定义可以使用sqlSession.close()方法来关闭sqlSession,然后再次获取新的sqlSession对象;
也可以使用sqlSession的clearCache方法来清空缓存:
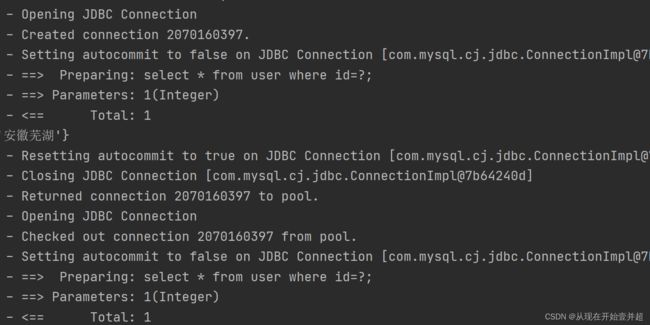
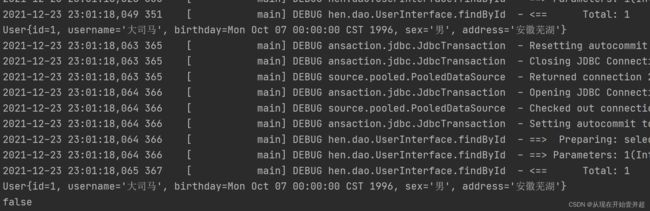
此时,两个sqlSession对象是不同的。
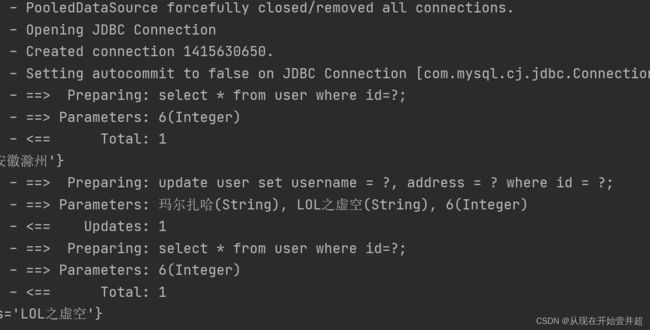
2.3. 一级缓存的分析
一级缓存是SqlSession范围的缓存,当调用SqlSession的update,delete,insert以及commit和close方法时,就会清空一级缓存。

2.4. 二级缓存
指的是Mybatis中的SqlSessionFactory对象的缓存,由同一个SqlSessionFactory对象创建的SqlSession共享其缓存
2.4.1. 二级缓存的使用步骤
- 在SqlMapConfih.xml配置使得Mybatis框架支持二级缓存
下面配置文件中,aggressiveLazyLoading如果设置为true,表示是同级加载,如果多表关联中,主表调用两个表为同一级,则会同时查询同级的两个子表。
<settings>
<!-- 打开延迟加载的开关 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 将积极加载改为消息加载也就是按需加载 在mybatis 3.4.1版本之后该参数默认为false-->
<setting name="aggressiveLazyLoading" value="false"/>
<!-- 设置cacheEnabled为true使得Mybatis支持二级缓存 默认为true-->
<setting name="cacheEnabled" value="true"/>
</settings>
- 在UserDao.xml中配置让当前的映射文支持二级缓存
<mapper namespace="com.huzhen.dao.UserInterface">
<!-- 开启userDao使得其支持二级缓存 -->
<cache/>
- 在select标签中配置让当前的操作支持二级缓存
<!-- 对于所使用的select语句中配置 useCache设置为true 开启二级缓存 -->
<select id="findById" parameterType="INT" resultType="user" useCache="true">
select * from user where id=#{Uid};
</select>
2.4.2 二级缓存的测试
在测试类中进行测试:
public class SecondLevelCacheTest {
private InputStream is;
private SqlSessionFactory factory;
@Before
public void init() throws IOException {
is = Resources.getResourceAsStream("SqlMapConfig.xml");
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
factory = builder.build(is);
}
// AfterAll和BeforeAll注解修饰的必须是静态方法
@After
public void close() throws IOException{
is.close();
}
/**
* 测试二级缓存
*/
@Test
public void testSecondLevelCache(){
SqlSession sqlSession1 = factory.openSession();
UserInterface userDao1 = sqlSession1.getMapper(UserInterface.class);
User user1 = userDao1.findById(1);
System.out.println(user1);
sqlSession1.close(); // 让一级缓存消失
SqlSession sqlSession2 = factory.openSession();
UserInterface userDao2 = sqlSession2.getMapper(UserInterface.class);
User user2 = userDao2.findById(1);
System.out.println(user2);
sqlSession2.close(); // 让一级缓存消失
System.out.println(user1 == user2);
}
}
如果这里进行上述三个的配置来开启二级缓存,那么输出结果如下:
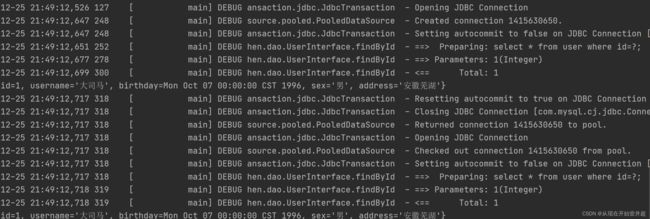

这里依旧调用了两次查询,并没有开启二级缓存机制。
但是当配置好二级缓存之后,再进行输出打印,可以看到此时只有一次查询语句:
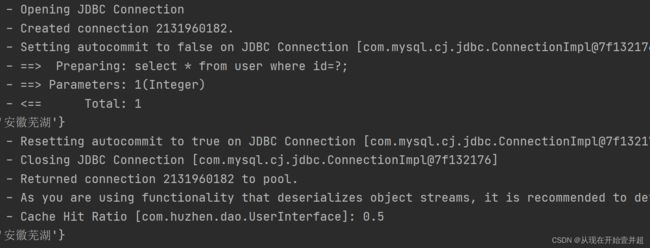
![]()
注意:二级缓存存放的是数据本身而不是对象,虽然没有发起新的查询,但是会创建一个新的对象用来存放数据,因此两次的结果都是false
3. Mybatis注解开发
为了可以减少Mapper映射文件的编写,使用注解开发方式
3.1. 使用Mybatis注解实现CRUD操作
使用User-Account案例,在SqlMapConfig.xml配置中需要注意的是:
由于使用注解开发,如果再resources下的dao包下存在对应的mapper配置文件,Mybatis在执行时会报错,因此这里只有domain包下的实体类以及dao接口。在SqlMapConfig.xml配置mapper映射,可以采用package的name属性来指定dao接口或者mapper标签的class属性来指定对应的Dao接口的全限定类名
<mappers>
<!-- 指定带有注解的dao接口的全限定类名 -->
<!-- <package name="com.huzhen.dao"></package>-->
<!-- 使用mapper标签,使用class属性执行Dao接口的全限定类名 -->
<!-- 当选择使用注解进行开发时,就不能在resources的dao包下定义xml配置文件 一旦存在xml文件会报错-->
<mapper class="com.huzhen.dao.UserInterface"></mapper>
</mappers>
3.1.1. 查询所有操作
在Dao接口中增加查询的抽象方法:
package com.huzhen.dao;
import com.huzhen.domain.User;
import org.apache.ibatis.annotations.Delete;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Select;
import org.apache.ibatis.annotations.Update;
import java.util.List;
/**
* 在Mybatis中,CRUD一共有4个注解
* @SELECT @INSERT @DELETE @UPDATE
*
*/
public interface UserInterface {
/**
* 查询所有用户
*/
@Select("select * from user;")
List<User> findAll();
Mybatis是如何找到注解Select中的sql语句并且执行的,类似使用Mapper配置文件,使用mapper配置文件,使用namespace + id得到map的key,再将sql语句与resultType拼接成mapper对象成为value,调用代理对象去执行对应的sql语句。
而使用注解同样也可以找到这4个参数:
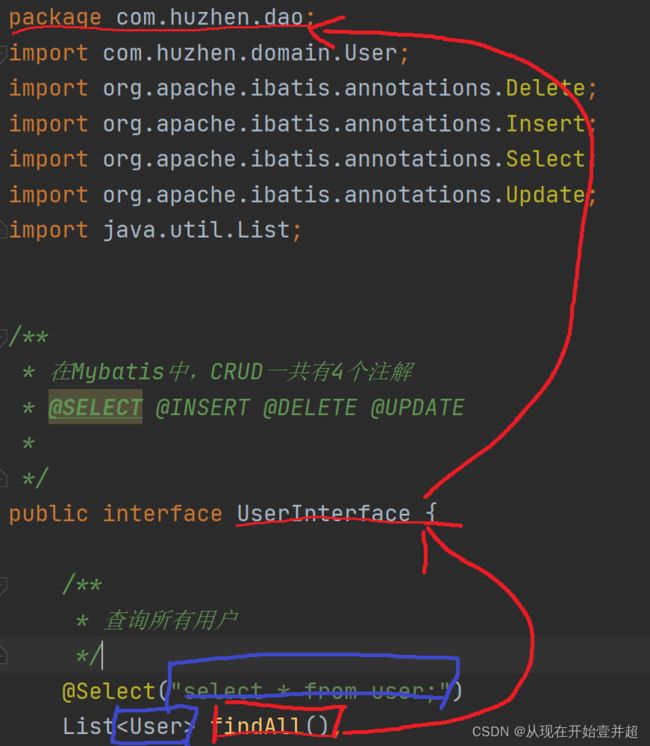
通过方法名可以反射得到对应的全限定类名(红色标注),将全限定类名 + 方法名拼接得到map的key,通过@Select注解中的字符串即可得到sql语句,并且根据返回值中的泛型可以得到resultType(蓝色标注)。
在测试类中进行测试:
public class annoTest {
private InputStream is;
private SqlSession sqlSession;
private SqlSessionFactory factory;
private UserInterface userDao;
@Before
public void init(){
try {
is = Resources.getResourceAsStream("SqlMapConfig.xml");
} catch (IOException ioException) {
ioException.printStackTrace();
}
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
factory = builder.build(is);
sqlSession = factory.openSession();
userDao = sqlSession.getMapper(UserInterface.class);
}
@After
public void close(){
sqlSession.commit();
if(is != null){
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(sqlSession != null){
sqlSession.close();
}
}
@Test
public void testFindAll(){
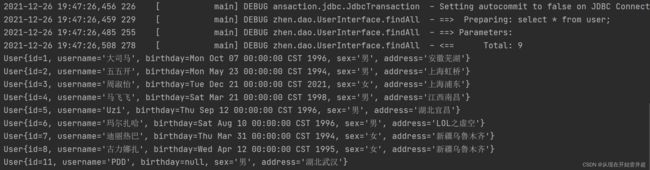
List<User> list = userDao.findAll();
for(User user : list){
System.out.println(user);
}
}
输出结果为:
3.1.2. 增,删,改以及聚合函数的查询
流程与查询相同,在Dao接口中增加抽象方法,并在方法上加上对应的注解,最后在测试类中进行测试:
/**
* 保存用户, #{}中传入的是实体类对应的成员变量名
*/
@Insert("insert into user(username, sex, birthday, address) values(#{username}, #{sex}, #{birthday}, #{address});")
void saveUser(User user);
/**
* 更新用户
*/
@Update("update user set address=#{address}, birthday=#{birthday} where id=#{id}")
void updateUserById(User user);
/**
* 删除用户
*/
@Delete("delete from user where id = #{uid}")
void deleteUserById(int uid);
/**
* 根据id查询用户信息
*/
@Select("select * from user where id=#{uid};")
User findById(Integer userId);
/**
*根据用户名模糊查询
*/
// @Select("select * from user where username like #{username};")
// 使用字符串拼接,容易引起sql注入问题
@Select("select * from user where username like '%${value}%';")
List<User> findUserByName(String name);
/**
* 使用聚合函数查询总记录数
*/
@Select("select count(id) from user")
Integer findTotalUsers();
@Test
public void testInsert(){
User user = new User();
user.setUsername("PDD");
user.setAddress("湖北武汉");
user.setSex("男");
userDao.saveUser(user);
}
@Test
public void testUpdate(){
User user = new User();
user.setId(10);
user.setAddress("上海虹桥");
user.setBirthday(new Date());
userDao.updateUserById(user);
}
@Test
public void testDelete(){
userDao.deleteUserById(10);
}
@Test
public void testFindById(){
User user = userDao.findById(1);
System.out.println(user);
}
@Test
public void testFindByName(){
// List list = userDao.findUserByName("%马%"); 使用占位符的方式进行查询
List<User> list = userDao.findUserByName("马"); // 使用字符串拼接方式进行查询
for(User user : list){
System.out.println(user);
}
}
@Test
public void testFindAllUsers(){
System.out.println("总用户数:" + userDao.findTotalUsers());
}
}
为避免冗余,输出结果不再一一进行展示
3.2. 使用注解实现复杂关系的映射开发
3.2.1. 实体类的属性与表中的字段不一致
当实体类中的属性与对应的表的字段名称不一致,此时需要进行==@Results注解==来进行配置,如果不配置直接查询,结果如下:
private Integer userId;
private String userName;
private Date userBirthday;
private String userSex;
private String userAddress;
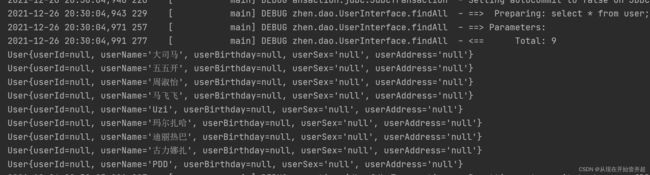
可以看到,除了username之外其余字段的值都得不到,这是因为Window系统下Mysql是不区分大小写的,因此只有username可以被识别。
在UserDao中进行配置:
@Select("select * from user;")
// 针对于实体类中的属性与表中的字段名不一致时候,使用Results中result注解进行配置
// id设置为true表示进行主码配置,column属性对应表中的字段名,property对应实体类属性名
@Results(id = "userMap",value = {
@Result(id = true, column = "id", property = "userId"),
@Result(column = "username", property = "userName"),
@Result(column = "birthday", property = "userBirthday"),
@Result(column = "sex", property = "userSex"),
@Result(column = "address", property = "userAddress")})
List<User> findAll();
与xml配置同理,property对应实体类中的属性,column对应表中的字段名称。
当存在多个方法需要配置,如根据username进行模糊查询和根据id查询用户,可以设置@Results注解的id也就是名称,然后在其他查询方法上直接调用该注解:
/**
* 根据id查询用户信息
*/
@Select("select * from user where id=#{uid};")
@ResultMap("userMap")
User findById(Integer userId);
/**
*根据用户名模糊查询
*/
// @Select("select * from user where username like #{username};")
// 使用字符串拼接,容易引起sql注入问题
@Select("select * from user where username like '%${value}%';")
@ResultMap(value = {"userMap"})
List<User> findUserByName(String name);
3.2.2. 实现多对一的查询
需求:查询账户信息的同时返回所属的用户信息
实体类Account中增加一个User属性用来接收账户所属的用户,在AccountDao接口中增加查询所有的方法
select * from account;
但是仅仅有上面的sql语句查询得到的依旧是一个单表的信息,得不到所属的用户信息,因此使用注解***@Results***进行配置:
@Select("select * from account") // 不加下面的resultMap仅仅是单表查询Account信息
@Results(id = "accountMap", value = {
@Result(id = true, column = "id", property = "id"),
@Result(column = "uid", property = "uid"),
@Result(column = "money", property = "money"),
@Result(property = "user", column = "uid",one = @One(select="com.huzhen.dao.UserInterface.findById", fetchType= FetchType.EAGER))
})
List<Account> findAll();
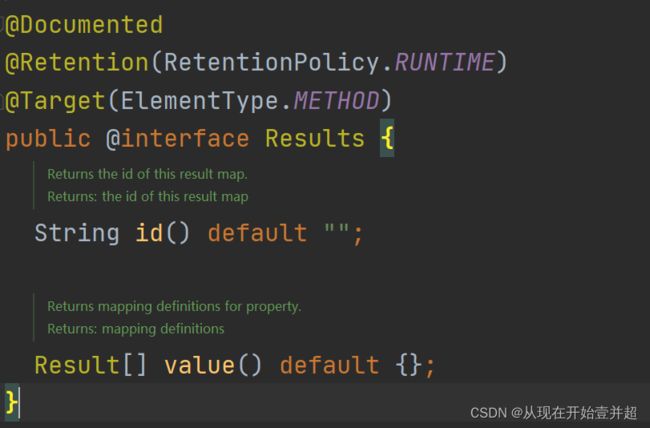
通过源码可以发现Results注解包括属性:String类型的id,以及@Result注解
进入到Result注解,可以看到:
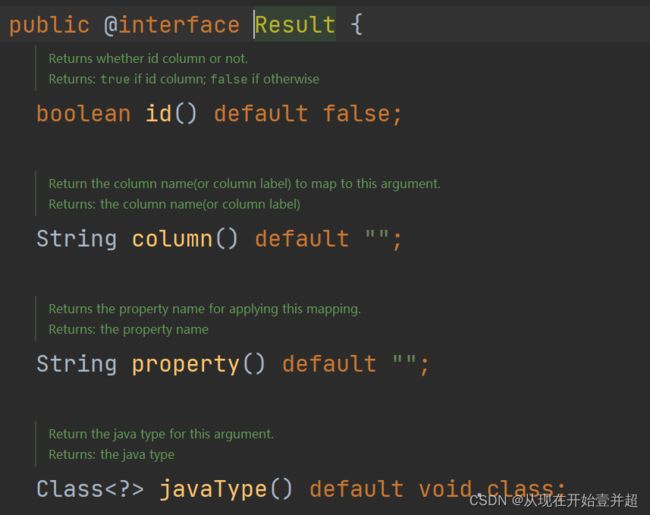
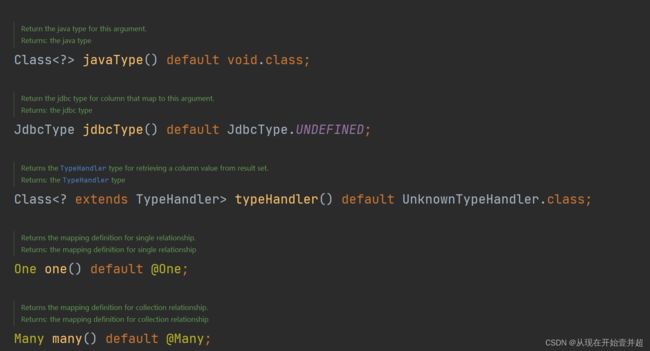
这里的property和column和之前使用xml配置使用的参数配置是一样的,而这里的注解One和注解Many:如果是多对一或者一对一的查询,应该使用@One注解;如果使用多对多或者一对多查询,应该使用@Many注解。
查询所有账户信息, 以及账户信息所属的用户信息, 由于是多对一因此使用立即加载, 并且one注解是在Result注解中的select属性对应的指定需要执行方法的全限定类名(表示根据uid来查询用户信息);fetchType有三个取值: LAZY(延迟加载), EAGER(立即加载), DEFAULT,由于根据账户对应的uid来查询用户,因此在最后一个Result注解中的property对应的是Account实体类的user,column对应的是account表的uid
在测试类中进行测试并打印结果:
public class AccountTest {
private InputStream is;
private SqlSession sqlSession;
private SqlSessionFactory factory;
private AccountInterface accountDao;
@Before
public void init(){
try {
is = Resources.getResourceAsStream("SqlMapConfig.xml");
} catch (IOException ioException) {
ioException.printStackTrace();
}
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
factory = builder.build(is);
sqlSession = factory.openSession();
accountDao = sqlSession.getMapper(AccountInterface.class);
}
@After
public void close(){
sqlSession.commit();
if(is != null){
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(sqlSession != null){
sqlSession.close();
}
}
/**
* 查询账户信息的同时返回所属的用户信息,因为是多对一,则使用One注解以及设置fetchType为eager(立即加载)
*/
@Test
public void testFindAll(){
List<Account> list = accountDao.findAll();
for(Account account : list){
System.out.println("==============Account Info==============");
System.out.println(account);
System.out.println(account.getUser());
}
}
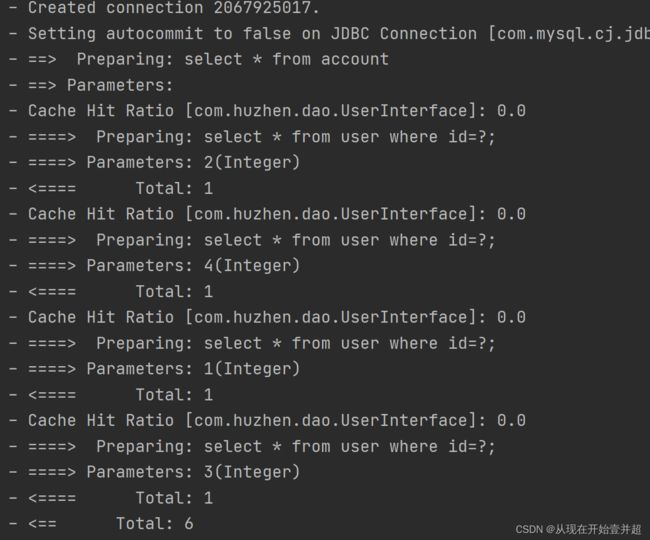
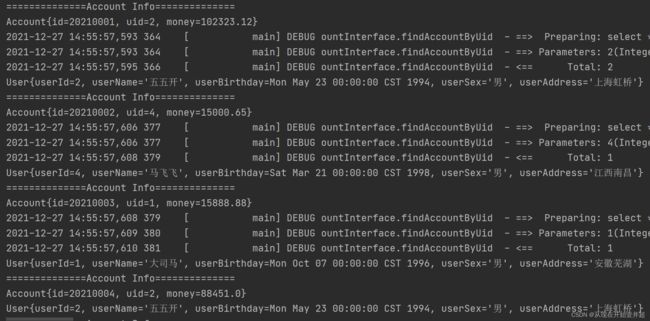
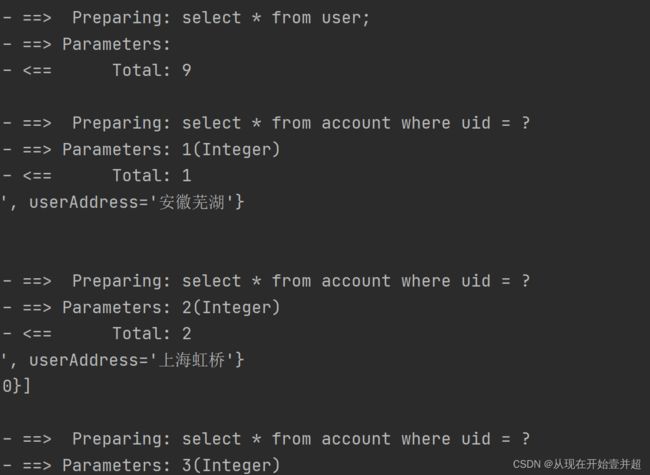
从第一张图片的输出结果可以发现,这里实现的是立即加载,1条查询Account语句以及4条查询用户信息的sql语句(由于Account表中对应的用户id只有4个)一起被执行。
3.2.3. 实现一对多查询
需求:查询用户的同时返回账户信息
- 由于一个用户可能有多个账户,因此在用户实体类中增加一个保存account的列表,用于接收多个账户信息:
// 一对多的关系映射,一个用户对应多个账户信息
private List<Account> accounts;
public List<Account> getAccounts() {
return accounts;
}
public void setAccounts(List<Account> accounts) {
this.accounts = accounts;
}
- UserDao接口的配置
@Select("select * from user;")
// 针对于实体类中的属性与表中的字段名不一致时候,使用Results中result注解进行配置
// id设置为true表示进行主码配置,column属性对应表中的字段名,property对应实体类属性名
@Results(id = "userMap",value = {
@Result(id = true, column = "id", property = "userId"),
@Result(column = "username", property = "userName"),
@Result(column = "birthday", property = "userBirthday"),
@Result(column = "sex", property = "userSex"),
@Result(column = "address", property = "userAddress"),
@Result(property = "accounts", column = "id", many=@Many(select = "com.huzhen.dao.AccountInterface.findAccountByUid",
fetchType = FetchType.LAZY))
})
List<User> findAll();
着重看最后一个Result注解,这里的property对应的是实体类User中的集合Account的成员变量名,column对应的是user表中的用户id,因为是根据用户id去Account表去查询账户信息;并且是一对多查询,因此使用Many注解,其中的select对应的是Account接口中的findByUid方法,即根据用户id来查询,fetchType使用延迟加载。
- AccountDao接口增加findAccountByUid方法
/**
* 根据用户的id来查询账户信息
* uid为account表中的字段(用户id),userId为user实体类中的id属性
* @return
*/
@Select("select * from account where uid = #{userId}")
List<Account> findAccountByUid(Integer uid);
注意这里的查询语句
select * from account where uid = ?;
因为是根据用户的id来查询,所有不能使用Account表中的id来查询。
- 测试类中进行测试并打印输出结果
private InputStream is;
private SqlSession sqlSession;
private SqlSessionFactory factory;
private UserInterface userDao;
@Before
public void init(){
try {
is = Resources.getResourceAsStream("SqlMapConfig.xml");
} catch (IOException ioException) {
ioException.printStackTrace();
}
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
factory = builder.build(is);
sqlSession = factory.openSession();
userDao = sqlSession.getMapper(UserInterface.class);
}
@After
public void close(){
sqlSession.commit();
if(is != null){
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(sqlSession != null){
sqlSession.close();
}
}
@Test
public void testFindAll(){
List<User> list = userDao.findAll();
for(User user : list){
System.out.println("===========User Info=========");
System.out.println(user);
System.out.println(user.getAccounts());
}
}
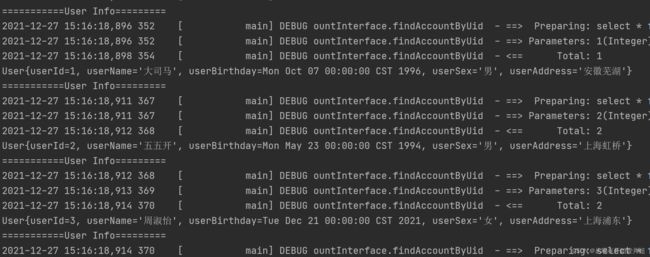
可以明显的看出,当在测试中将调用Account方法注释掉,这里并不会得到每个用户的账户信息,实现了一对多的延迟加载。
3.2.4. 一级缓存和二级缓存
- 一级缓存
使用userDao接口中的findById来进行测试一级缓存:
@Test
public void testFindById(){
User user1 = userDao.findById(1);
System.out.println(user1);
// mybatis默认开启一级缓存
User user2 = userDao.findById(1);
System.out.println(user2);
System.out.println(user1 == user2);
}
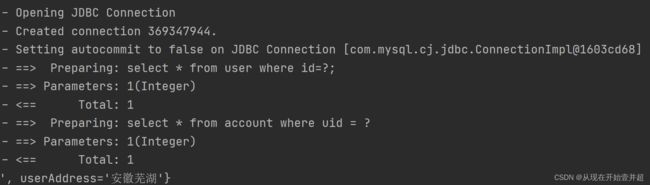
可以看到Mybatis只发起了一次查询,证明第二次查询是在缓存中进行读取的
- 二级缓存
package com.huzhen.test;
import com.huzhen.dao.UserInterface;
import com.huzhen.domain.User;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.io.InputStream;
public class SecondLevelCache {
private InputStream is;
private SqlSessionFactory factory;
private SqlSession sqlSession;
UserInterface mapper;
@Before
public void init(){
try {
is = Resources.getResourceAsStream("SqlMapConfig.xml");
} catch (IOException e) {
e.printStackTrace();
}
factory = new SqlSessionFactoryBuilder().build(is);
sqlSession = factory.openSession();
mapper = sqlSession.getMapper(UserInterface.class);
}
@After
public void close() {
if (is != null) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Test
public void testSecondLevelCache(){
User user1 = mapper.findById(1);
System.out.println(user1);
sqlSession.close();
SqlSession sqlSession1 = factory.openSession();
UserInterface mapper1 = sqlSession1.getMapper(UserInterface.class);
User user2 = mapper1.findById(1);
System.out.println(user2);
System.out.println(user1 == user2);
}
}
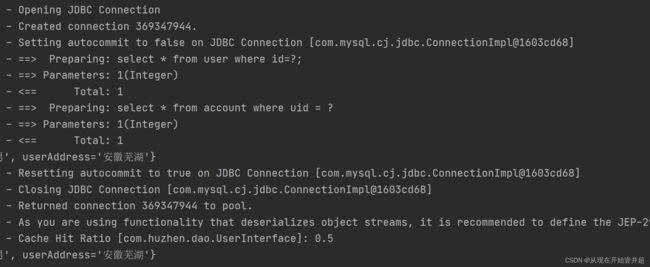
另外,对于SqlMapConfig.xml中开启二级缓存是可以省略的,因为cacheEnabled默认是开启的,这里仅仅是展示:
<!-- 设置二级缓存以及开启延迟加载 -->
<settings>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
<setting name="cacheEnabled" value="true"/>
</settings>