何为solr
solr是java搜索引擎Lucene的更高一层封装,通过webapp服务器实现可视化界面,方便使用人员配置、访问和调用
solr架构解析
以下是solrcloud的架构图,单机模式的solr只是在这个基础上的简化:
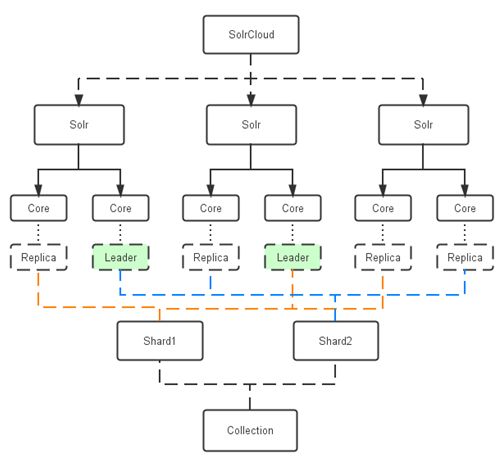
- SolrCloud:由分布在多个物理主机上的solr节点构成一个统一的solr分布式集群
- Solr节点:物理概念,单个的物理主机,对应一个具体的solr服务器
- core:物理概念,对应一系列document以及索引,单个solr主机上的core不相同
- replica(leader):逻辑概念,每个replica都映射到某一个core,一个core可以有多个分布在不同主机上的replica,通过zookeeper进行选举产生leader
- shard:逻辑概念,由多个replica以及一个leader组成集群,一个shard和同一个core的索引一一对应,也就是说shard的多个replica分布在不同的主机上成为core集群
- collection:一套完整的倒排索引,一个独立的collection对应一个solrconfig.xml和schema.xml配置文件,可以分为不同的分片(shard),每个shard又由分布在不同主机上的replica组成
单机模式中,一个collection就对应一个core,当然也就没有shard和replica的概念了
solr环境搭建(单机模式)
solr有单机启动模式和集群启动模式,这里仅学习单机模式
启动服务器
在solr的bin文件夹下打开cmd,输入“solr start”即可快速启动solr服务器,默认8983端口,输入localhost:8983/solr/访问这个服务
创建core
core对应数据库中的一张表(或者保存一系列同类数据的容器),其中的元素为document(对应数据库的一行数据),通过命令行方式创建core:
solr create -c solrDemo
建立名为solrDemo的core,在solr界面中就可以查看core
配置分词器
分词器用于将单份document中的数据/文本中的单词进行分隔、整理、语法化并最终生成索引,solr的默认分词器只能对英文分词,中文分词需要配置额外的分词器
- 配置Lucene默认的中文分词器:
修改solr-7.4.0\server\solr\solrDemo\conf下的managed-schema文件,添加下列配置:
重启后,在core中的Analysis中测试一下,FieldType选择solr_cnAnalyzer,就可以看到solr可以准确的将输入的查询语句拆分为中文词语
设置字段
为了将数据库/文本中的数据和文本正确映射到core中,需要在core的schema中准确设置与数据库/文本完全对应的字段(field):
- 设置文本字段:field type选择solr_cnAnalyzer,字段名选择源文件对应的字段名,其他默认
- 设置数字字段:field type选择ploat或者pint等
特别注意:store和index一定要为true,前者指定数据库字段值存入solr后能够被检索得到,后者指定该字段建立索引
导入数据并创建索引(文本方式)
这里演示通过solrj工具从文本中导入数据到core中
- 建立实体类:通过实体类为载体将数据映射到core中(类似于orm框架),需要在与字段对应的成员属性上进行@Field注解,便于solr4j工具将属性值映射到core字段:
public class Product {
@Field
int id;
@Field
float price;
@Field
String category;
@Field
String name;
@Field
String place;
@Field
String code;
/*
getter and setter
*/
}
- ProductUtil:将文本导入到java程序的工具类:
public class ProductUtil {
//从文本中读入每一行数据,保存为Product对象
public static List file2List(String fileName){
File file = new File(fileName);
try {
List productList = new ArrayList<>(147940);
List list = FileUtils.readLines(file, "UTF-8");
for(String s:list){
productList.add(line2Product(s));
}
return productList;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
public static Product line2Product(String productLine){
Product product = new Product();
String[] fields = productLine.split(",");
product.setId(Integer.parseInt(fields[0]));
product.setName(fields[1]);
product.setCategory(fields[2]);
product.setPrice(Float.parseFloat(fields[3]));
product.setPlace(fields[4]);
product.setCode(fields[5]);
return product;
}
}
- SolrUtil:将实体类Product中保存的数据以document的形式导入到core表中,保存为core字段:
public class SolrUtils {
private static SolrClient solrClient;
private static String url;
static {
url = "http://127.0.0.1:8983/solr/solrDemo";
solrClient = new HttpSolrClient.Builder(url).build();//建立solr通讯连接
}
//批量录入数据
public static boolean batchSaveOrUpdate(List entities) throws SolrServerException,IOException{
DocumentObjectBinder binder = new DocumentObjectBinder();
int total = entities.size();
int count = 0;
for(T t:entities){
SolrInputDocument document = binder.toSolrInputDocument(t);
solrClient.add(document);
System.out.printf("一共有%d条记录需要添加,当前添加到%d条记录"+"\n", total, ++count);
}
solrClient.commit();
return true;
}
//录入单个document数据
public static boolean saveOrUpdate(T entity) throws SolrServerException, IOException{
DocumentObjectBinder binder = new DocumentObjectBinder();
SolrInputDocument document = binder.toSolrInputDocument(entity);//将实体类的数据包装为单个document
solrClient.add(document);
solrClient.commit();
return true;
}
}
完成录入后,通过在core中查询:可以查看一共录入了多少条document数据;数据录入后,solr能够对每一段document进行分词、词法和语法解析,并对每一个词生成索引
导入数据并创建索引(数据库方式)
- 导入数据库需要准备两个jar包,将jar包放到webapp的lib下即可:
mysql-connector-java-5.1.46.jar
solr-dataimporthandler-7.4.0.jar
- 配置requestHandler:在当前collection的solrconfig.xml中配置
data-config.xml
- 配置data-config:新建data-config.xml文档,进行如下配置:
其中entity对应数据库实体,如果field不设置的话,solr将查找与column相同名字的solr字段
- 在core的dataimport中进行导入
solr环境搭建(centos7.4):
centos上solr安装完成后,默认的安装目录为 /opt/solr,配置文件默认存放在 /var/solr 文件夹下面,数据文件(core)在/var/solr/data下面
创建core
进行搜索
通过solrj工具在java工程中搜索文本
分页查询
solr支持分页查询,和关系型数据库类型,通过设置offset和count进行分页查询:
- SolrUtils加入以下方法:
public static QueryResponse query(String keyWords, int offset, int count) throws SolrServerException, IOException{
SolrQuery query = new SolrQuery();
query.setStart(offset);
query.setRows(count);
query.setQuery(keyWords);
return solrClient.query(query);
}
keywords为搜索关键词,以“field name : keyword”的方式构成
//获得查询反馈
QueryResponse queryResponse = SolrUtils.query("name:婴儿", 0, 10);
//将反馈结果导出为一张document的List
SolrDocumentList documents = queryResponse.getResults();
//取出document中的数据
for(SolrDocument solrDocument:documents)
Collection fields = solrDocument.getFieldNames();
for(String s:fields){
//根据fieldName从document中取出数据
System.out.print(solrDocument.get(s) + "\t");
}
System.out.println();
}
高亮查询
高亮查询可以将文本中查询到的文字加上类似html的前缀和后缀,便于醒目提示:
- 在SolrUtils中加入以下方法:
public static void queryHighlight(String keyWords, String fieldName, int offset, int count) throws SolrServerException, IOException{
SolrQuery query = new SolrQuery();
query.setQuery(fieldName + ":" + keyWords);
query.setStart(offset);
query.setRows(count);
//打开高亮提示,设置需要高亮的字段名和前后缀提示符,以及每个分片最大长度(100)
query.setHighlight(true);
query.addHighlightField(fieldName);
query.setHighlightSimplePre("");
query.setHighlightSimplePost("");
query.setHighlightFragsize(100);
//获得查询反馈,将反馈结果以NamedList的形式取出,然后取出高亮查询的结果“highlighting”,遍历显示
QueryResponse queryResponse = solrClient.query(query);
NamedList删除document
通过id删除某个document:
public static boolean deleteById(String id){
try {
solrClient.deleteById(id);
solrClient.commit();
} catch (Exception e) {
e.printStackTrace();
return false;
}
return true;
}
添加单个document
通过SolrInputDocument向solr添加单个document,记得一定要commit:
public boolean newQuestionIndex(int qid, String title, String content){
SolrInputDocument document = new SolrInputDocument();
document.setField("id", String.valueOf(qid));
document.setField(QUESTION_TITLE_FIELD, title);
document.setField(QUESTION_CONTENT_FIELD, content);
try {
UpdateResponse response = solrClient.add(document);
int status = response.getStatus();
if(status == 0){
logger.info("添加问题:“"+title+"”成功 !");
solrClient.commit();
}else {
logger.info("添加问题:“"+title+"”失败 !");
}
return response != null && status == 0;
} catch (Exception e) {
logger.error("向solr添加document时出错:"+e.getMessage());
e.printStackTrace();
return false;
}
}