摘要:大数据计算服务(MaxCompute)的功能详解和使用心得
点此查看原文:http://click.aliyun.com/m/41384/
前言
MapReduce已经有文档,用户可以参考文档使用。本文是在文档的基础上做一些类似注解及细节解释上的工作。
功能介绍
MapReduce
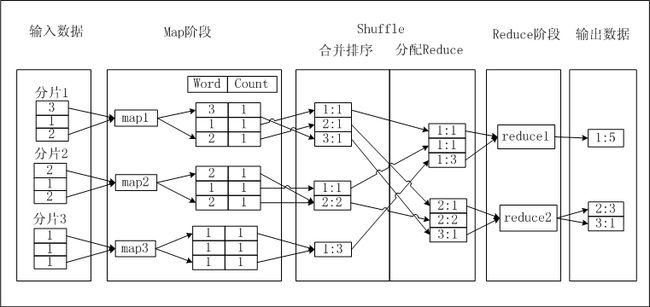
说起MapReduce就少不了WordCount,我特别喜欢文档里的这个图片。
比如有一张很大的表。表里有个String字段记录的是用空格分割开单词。最后需要统计所有记录中,每个单词出现的次数是多少。那整体的计算流程是
输入阶段:根据工作量,生成几个Mapper,把这些表的数据分配给这些Mapper。每个Mapper分配到表里的一部分记录。
Map阶段:每个Mapper针对每条数据,解析里面的字符串,用空格切开字符串,得到一组单词。针对其中每个单词,写一条记录
Shuffle阶段-合并排序:也是发生在Mapper上。会先对数据进行排序。比如WordCount的例子,会根据单词进行排序。排序后的合并,又称Combiner阶段,因为前面已经根据单词排序过了,相同的单词都是连在一起的。那可以把2个相邻的合并成1个。Combiner可以减少在后续Reduce端的计算量,也可以减少Mapper往Reducer的数据传输的工作量。
Shuffle阶段-分配Reducer:把Mapper输出的单词分发给Reducer。Reducer拿到数据后,再做一次排序。因为Reducer拿到的数据已经在Mapper里已经是排序过的了,所以这里的排序只是针对排序过的数据做合并排序。
Reduce阶段:Reducer拿前面已经排序好的输入,相同的单词的所有输入进入同一个Redue循环,在循环里,做个数的累加。
输出阶段:输出Reduce的计算结果,写入到表里或者返回给客户端。
拓展MapReduce
如果Reduce后面还需要做进一步的Reduce计算,可以用拓展MapReduce模型(简称MRR)。MRR其实就是Reduce阶段结束后,不直接输出结果,而是再次经过Shuffle后接另外一个Reduce。
Q:如何实现M->R->M->R这种逻辑呢
A:在Reduce代码里直接嵌套上Map的逻辑就可以了,把第二个M的工作在前一个R里完成,而不是作为计算引擎调度层面上的一个单独步骤,比如
reduce(){
...
map();
}
快速开始
运行环境
工欲善其事,必先利其器。MR的开发提供了基于IDEA和Eclipse的插件。其中比较推荐用IDEA的插件,因为IDEA我们还在持续做迭代,而Eclipse已经停止做更新了。而且IDEA的功能也比较丰富。
具体的插件的安装方法步骤可以参考文档,本文不在赘言。
另外后续还需要用到客户端,可以参考文档安装。
后续为了更加清楚地说明问题,我会尽可能地在客户端上操作,而不用IDEA里已经集成的方法。
线上运行
以WordCount为例,文档可以参考这里
步骤为
做数据准备,包括创建表和使用Tunnel命令行工具导入数据
将代码拷贝到IDE里,编译打包成mapreduce-examples.jar
在odpscmd里执行add jar命令:
add jar /JarPath/mapreduce-examples.jar -f;
这里的/JarPath/mapreduce-examples.jar的路径要替换成本地实际的文件路径。这个命令能把本地的jar包传到服务器上,-f是如果已经有同名的jar包就覆盖,实际使用中对于是报错还是覆盖需要谨慎考虑。
在odpscmd里执行
`jar -resources mapreduce-examples.jar -classpath mapreduce-examples.jar
com.aliyun.odps.mapred.open.example.WordCount wc_in wc_out`
等待作业执行成功后,可以在SQL通过查询wc_out表的数据,看到执行的结果
功能解读
任务提交
任务的是在MaxComput(ODPS)上运行的,客户端通过jar命令发起请求。
对比前面的快速开始,可以看到除去数据准备阶段,和MR相关的,有资源的上传(add jar步骤)和jar命令启动MR作业两步。
客户端发起add jar/add file等资源操作,把在客户端的机器(比如我测试的时候是从我的笔记本)上,运行任务涉及的资源文件传到服务器上。这样后面运行任务的时候,服务器上才能有对应的代码和文件可以用。如果以前已经传过了,这一步可以省略。
jar -resources mapreduce-examples.jar -classpath mapreduce-examples.jar com.aliyun.odps.mapred.open.example.WordCount wc_in wc_out
这个命令发起作业。MapReduce的任务是运行在MaxCompute集群上的,客户端需要通过这个命令把任务运行相关的信息告诉集群。
客户端先解析-classpath参数,找到main方法相关的jar包的位置
根据com.aliyun.odps.mapred.open.example.WordCount,找到main方法所在类的路径和名字
wc_in wc_out是传给main方法的参数,通过解析main方法传入参数String[] args获得这个参数
-resources告诉服务器,在运行任务的时候,需要用到的资源有哪些。
JobConfig
JobConf定义了这个任务的细节,还是这个图,解释一下JobConf的其他设置项的用法。
输入数据
InputUtils.addTable(TableInfo table, JobConf conf)设置了输入的表。
setSplitSize(long size)通过调整分片大小来调整Mapper个数,单位 MB,默认256。Mapper个数不通过void setNumMapTasks(int n)设置。
setMemoryForJVM(int mem)设置 JVM虚拟机的内存资源,单位:MB,默认值 1024.
Map阶段
setMapperClass(Class theClass)设置Mapper使用的Java类。
setMapOutputKeySchema(Column[] schema)设置 Mapper 输出到 Reducer 的 Key 行属性。
setMapOutputValueSchema(Column[] schema)设置 Mapper 输出到 Reducer 的 Value 行属性。和上个设置一起定义了Mapper到Reducer的数据格式。
Shuffle-合并排序
setOutputKeySortColumns(String[] cols)设置 Mapper 输出到 Reducer 的 Key 排序列。
setOutputKeySortOrder(JobConf.SortOrder[] order)设置 Key 排序列的顺序。
setCombinerOptimizeEnable(boolean isCombineOpt)设置是否对Combiner进行优化。
setCombinerClass(Class theClass)设置作业的 combiner。
Shuffle-分配Reduce
setNumReduceTasks(int n)设置 Reducer 任务数,默认为 Mapper 任务数的 1/4。如果是Map only的任务,需要设置成0。可以参考这里。
setPartitionColumns(String[] cols)设置作业的分区列,定义了数据分配到Reducer的分配策略。
Reduce阶段
setOutputGroupingColumns(String[] cols)数据在Reducer里排序好了后,是哪些数据进入到同一个reduce方法的,就是看这里的设置。一般来说,设置的和setPartitionColumns(String[] cols)一样。可以看到二次排序的用法。
setReducerClass(Class theClass)设置Reducer使用的Java类。
数据输出
setOutputOverwrite(boolean isOverwrite)设置对输出表是否进行覆盖。类似SQL里的Insert into/overwrite Talbe的区别。
OutputUtils.addTable(TableInfo table, JobConf conf)设置了输出的表。多路输入输出可以参考这里。
其他
void setResources(String resourceNames)有和jar命令的-resources一样的功能,但是优先级高于-resources(也就是说代码里的设置优先级比较高)
最后通过JobClient.runJob(job);客户端往服务器发起了这个MapReduce作业。
详细的SDK的文档,可以在Maven里下载。这是下载地址。
Map/Reduce
读表
在一个Mapper里,只会读一张表,不同的表的数据会在不同的Mapper worker上运行,所以可以用示例里的这个方法先获得这个Mapper读的是什么表。
资源表/文件
资源表和文件可以让一些小表/小文件可以方便被读取。鉴于读取数据的限制需要小于64次,一般是在setup里读取后缓存起来,具体的例子可以参考这里。
生产及周期调度
任务提交
客户端做的就是给服务器发起任务的调度的指令。之前提到的jar命令就是一种方法。鉴于实际上运行场景的多样性,这里介绍其他的几种常见方法:
odpscmd -e/-f:odpscmd的-e命令可以在shell脚本里直接运行一个odpscmd里的命令,所以可以在shell脚本里运行odpscmd -e 'jar -resources xxxxxx'这样的命令,在shell脚本里调用MapReduce作业。一个完整的例子是
odpscmd -u accessId -p accessKey --project=testproject --endpoint=http://service.odps.aliyun.com/api -e "jar -resources aaa.jar -classpath ./aaa.jar com.XXX.A"
如果在odpscmd的配置文件里已经配置好了,那只需要写-e的部分。
-f和-e一样,只是把命令写到文件里,然后用odpscmd -f xxx.sql引用这个文件,那这个文件里的多个指令都会被执行。
大数据开发套件可以配置MapReduce作业。
大数据开发套件可以配置Shell作业。可以在Shell作业里参考上面的方法用odpscmd -e/-f来调度MapReduce作业。
在JAVA代码里直接调用MapReduce作业,可以通过设置SessionState.setLocalRun(false); 实现,具体可以参考这里。
定时调度
大数据开发套件的定时任务/工作流可以配置调度周期和任务依赖,配合前面提到的方法里的MapReduce作业/Shell作业,实现任务的调度。
产品限制
安全沙箱
沙箱是MaxCompute的一套安全体系,使得在MaxCompute上运行的作业无法获得其他用户的信息,也无法获得系统的一些信息。主要包括以下几点,完整的列表可以参考文档
无法访问外部数据源(不能当爬虫,不能读RDS等)
无法起多线程/多进程
不支持反射/自定义类加载器(所以不支持一些第三方包)
不允许读本地文件(比如JSON里就用到了,就需要改用GSON)
不允许JNI调用
其他限制
详见MaxCompute MR 限制项汇总