此篇文章基于上一篇carbondata 构建过程。
1、可为carbondata用户增加管理员权限,避免一些对新手来说比较棘手的权限问题
以root账号登录,并输入visudo命令,增加如下图标红所示行。
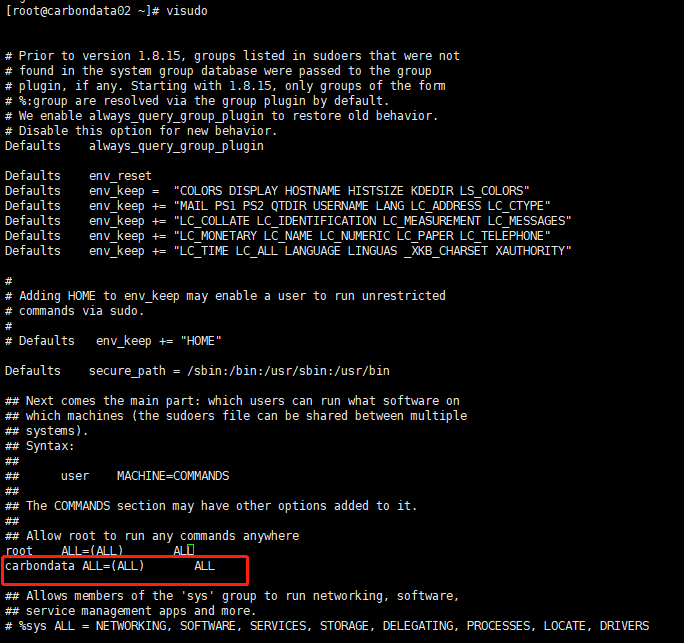
然后再以carbondata用户登录。
2、配置SSH免密登录
- 测试ssh是否可用
# 按提示输入密码xxx,就可以登陆到本机
ssh localhost
但这样登录是需要每次输入密码的,我们需要配置成SSH无密码登录比较方便。
2)SSH无密码登录配置
首先输入 exit 退出刚才的 ssh,就回到了我们原先的终端窗口。
然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中。
# 若没有该目录,请先执行一次ssh localhost
cd ~/.ssh/
# 会有提示,都按回车就可以
ssh-keygen -t rsa
cat id_rsa.pub >> authorized_keys
chmod 600 ./authorized_keys
cd ~
此时再用 ssh localhost 命令, 无需输入密码就可以直接登录了。
3、安装hadoop2
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
tar -xzvf hadoop-2.7.2.tar.gz
cd hadoop-2.7.2/bin
#检查hadoop version
./hadoop version
4、hadoop伪分布式配置
1) 设置HADOOP环境变量
# 编辑profile
sudo vim /etc/profile
# 文件末尾新增
export HADOOP_HOME=/home/carbondata/hadoop-2.7.2
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
# 使配置生效
source /etc/profile
- 修改核心配置文件
核心配置文件hdfs-site.xml,core-site.xml,yarn-site.xml等位于/home/carbondata/hadoop-2.7.2/etc/hadoop。
hdfs-site.xml:
core-site.xml:
yarn-site.xml:
mapred-site.xml:
hadoop-env.sh:
#export JAVA_HOME=${JAVA_HOME}
#将java home指定为绝对路径
export JAVA_HOME=/usr/local/jdk1.8.0_202
# Extra Java runtime options. Empty by default.
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true -Djava.library.path=${HADOOP_HOME}/lib/native"
配置完成后,格式化namenode
./bin/hdfs namenode -format
- 启动hdfs
cd ~/hadoop-2.7.2
#启动hdfs
./sbin/start-dfs.sh
#检查启动进程(namenode、second namenode、datanode)
jps
- 启动yarn
./sbin/start-yarn.sh
#检查进程ResourceManager、SecondaryNameNode
jps
引用链接:
1、Hadoop2.7.2之集群搭建(单机)