一、性能基础
什么是性能测试--->本质?
基于协议来模拟用户发送的请求(业务模拟),对服务器形成一定负载。
关注点:时间性能、空间性能
与界面无关
性能测试分类
-
性能测试(狭义)
性能测试方法是通过模拟生产环境运行的业务压力量和使用场景组合,测试系统性能是否满足生产性能要求。通俗地讲,这种方法就是要在特定的运行条件下来验证系统能力状态。
-
负载测试
通过在被测系统上进行不断加压,直到性能指标达到极限,例如“响应时间”超过了预定指标或都某种资源已经达到了饱和状态。
-
压力测试(强度测试)
压力测试方法,测试系统在一定饱和状态下,例如cpu、内存在饱和使用情况下,系统能够处理的会话能力,及系统是否会出现错误。
-
并发测试
并发测试方法通过模拟用户并发的访问,测试多用户并发访问同一应用、同一模块或数据记录时,是否死锁或其他性能问题。
-
配置测试
配置测试方法通过对被测系统软\硬件环境调整,了解各种不同对系统性能影响程度,找到系统各项资源最优分配原则。
-
可靠性测试
在给系统加载一定业务压力情况下,使系统运行一定时间,来检测系统是否稳定。
常见的性能测试指标
-
用户数
并发用户数在同一时间向服务器发送请求的用户数量
与每秒的并发请求数不同,一定要确认需求的目的是并发用户数还是并发请求数 -
吞吐量(Throughput)
说明:单位时间内处理客户端请求数量,直接体现软件系统性能承载能力。
通常情况下,吞吐量用"请求数/秒"或"页面数/秒"来衡量。
提示:
1.从业务角度看,吞吐量可以用"业务数/小时"、"访问人数/天"、"业务数/天","业务访问量/天"去衡量。
2.从网络角度看,还可以用"字节数/天"、"字节数/小时"等来衡量网络流量。
3.每秒事务数(TPS)、每秒查询数(QPS)都归属吞吐量,区别是TPS\QPS描述服务器具体性能处理的能力。
-
并发数
说明:并发测试的用户数
扩展:
并发用户数:某一物理时刻同时向系统发送请求的用户数。
在线用户数:某段时间内访问系统的用户数,这些用户不一定都是同时向系统来提交请求。
系统用户数:系统注册的总用户数据。
-
响应时间
说明:用户从客户端发起一个请求开始,到客户端接收到从服务器端返回结果整个过程中所消耗的时间。
-
点击数
说明:衡量web服务器处理能力的重要指标。
提示:
1.点击数并不是大家认为的访问一个页面就是1个点击数,点击数是页面中包含的元素(如:图片、链接等)向web服务器发出请求数数量。
2.通常会用每秒点击次数(Hits per Second)指标来衡量web服务器的处理能力。
注意:
只有web项目才有指标。
-
资源利用率
说明:指系统各种资源的使用情况,使用率=已使用的资源/全部的资源x100%
常见的资源使用率指标:
CPU,不超过80%
内存,不超过80%
磁盘,不高于90%
网络,不超过80%
如果资源利用率太小,也是造成资源浪费
-
错误率
说明:指系统各个资源的使用情况,一般使用"资源的使用量/总的资源可用量x100%"生成资源利用率的数据。
提示:通常,没有什么特殊需求的话
1.不同系统对错误率要求不同,但一般不超过千分之五---(根据实际项目而定万分之五等等)。
2.稳定性较好的系统,其错误率应该是由超时引起的---超时率。
-
TPS(Transactions Per Second)
说明:每秒的事务数(单位时间内系统处理客户端请求事务次数)
计算:tps=并发数/平均响应时间
事务:业务站在代码角度的统称,可以理解为一段或多段代码。
提示:TPS归属吞吐量
-
QPS(Query Per Second)
说明:每秒查询数(衡量web服务器处理能力的一个重要指标)
应用:控制服务器每秒处理指定请求数(如:控制服务器达到每秒60qps,服务器的性能各项性能指标是否正常)。
二、性能测试流程
流程图
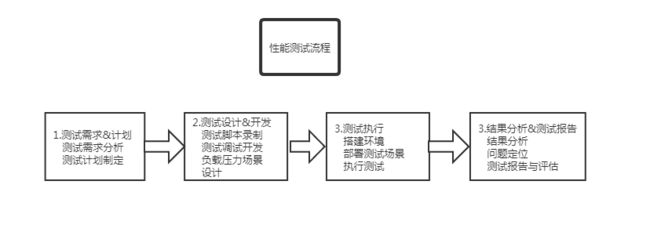
需求分析
-
测试对象
-
常用的
-
核心的,重要的
-
数据量、并发量
-
例子:
注册、登录、搜索、添加购物车、下订单、支付
-
-
确定性能指标
-
吞吐量、TPS
服务器每秒处理的请求数量 -
响应时间
从浏览器发出请求,服务器处理,到收到响应所需要的处理时间
-
用户数
-
资源利用率
-
例子:
例子一:要求每天完成交易额2亿,求每秒钟最大交易数? 客单价:200-500,以300计算 采用28定律换算得出,以24小时计算 2/8原则:80%的用户请求,集中在20%的热点数据上,或时间段 计算公式:(200000000/300*0.8)/(24/0.2)/3600s=30.86个/s例子二:每天8小时系统支付500万用户访问 1.500万在8小时内完成,500万/8*3600,一般不采用,除非系统负载比较平稳/平均 2.先分析流量分布,再根据2/8定律估算每秒请求 80%的用户数:500*0.8=400w 20%的时间内:8*0.2=1.6h 计算得出服务器需要支持694次/s--->500*0.8/(8*0.2)/3600s 每小时的平均负载*4(估算,不建议此计算) -
-
测试场景
-
单一场景
登录
注册
搜索
添加购物车
下单、支付
-
混合场景
用户使用场景
系统使用场景
-
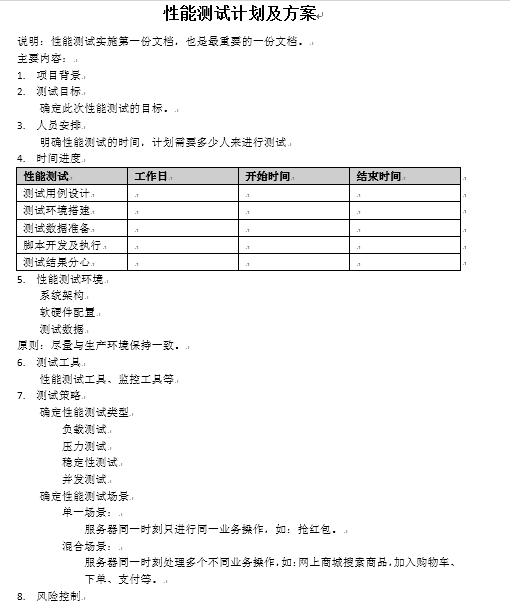
测试计划
-
测试目标
-
测试人员组织
-
压测进度安排
-
压力机
- 配置
- 要求
- 数量
-
风险
测试方案
-
测试工具
loadrunner
jmeter
-
测试环境
数据库
服务器
架构设计
有条件的情况下尽量和生产环境一致
-
测试策略
单一场景
混合场景 -
监控工具
- Linux
nmon
rpc
jvisualVm
Spotlight - windows
Spotlight
perfmon.exe
- Linux
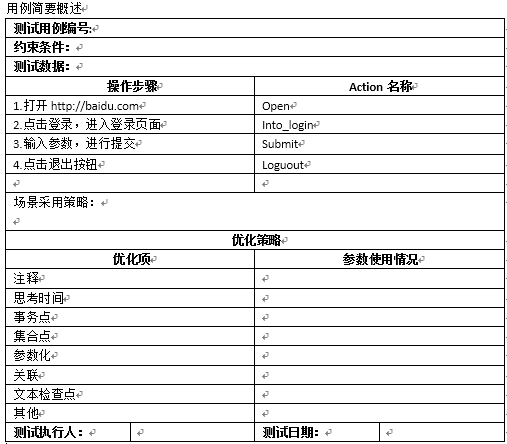
用例设计
-
测试脚本
基于脚本的用例 -
场景设计
基于场景的用例
测试执行
-
脚本编写
-
场景监控设计
业务设计-
场景搭建
说明:测试场景设计重要的原则就是依据测试用例,把用例设计场景进行展现出来。
提示: 1.虚拟用户数量及启动虚拟用户方式 2.场景相关的设置(如:集合点) 3.脚本是否有依赖关系(如:登录与注册)
-
-
运行场景
说明:运行脚本就是运行场景
1.负载的测试机不能够运行设定的虚拟用户数 2.没有"预热"过程 3.没有模拟用户的真实环境 4.性能用例运行次数过少 -
监控场景
-
测试报告
定位分析问题
- 后端
- 代码
- 软件(服务)
数据库
应用服务器 - 硬件
- 前端
- 网络
测试定位问题顺序:硬件问题--->网络问题--->应用服务器、数据库服务器配置问题--->源代码、数据库脚本--->系统架构问题
性能调优
性能测试人员经过对测试结果的对比,发现系统性能的瓶颈。
提示:
1.调优人员:以开发为主导,数据库管理员、系统管理员、网络管理员、性能测试分析人员配合进行性能问题的调优
2.验证:性能测试验证通常需要很多轮;每轮回归时需要对所有的测试指标进行全方位的对比
系统调优由易到难的顺序:
- 硬件问题
- 网络问题
- 应用服务器、数据库服务器配置问题
- 源代码、数据库脚本
- 系统架构问题
测试报告
-
对整体性能测试阶段的回顾(覆盖需求、测试不同阶段的进度和产物、性能测试结果的分析)--->技术角度
-
对整体性能测试阶段风险的管理--->管理的角度
-
对项目性能测试结果的总结(是否通过,经验、教训)
三、工具介绍及选型
LoadRunner
- 工业化的性能测试工具,能支持大量用户,提供详细的报表来提供测试分析的数量
- 支持的协议多
- 使用C语言来编写的
优点
1.支持用户量大(以万为单位)
2.提供精确的报表
3.支持ip欺骗
缺点
1.收费
2.体积大
3.无法定制
Jmeter
jmeter是Apache组织基于java开发的一款性能测试软件。多协议(HTTP/HTTPS、JDBC、JAVA...等等)
优点
1.开源免费
2.体积小
3.有丰富的第三方插件
缺点
1.不支持ip欺骗
2.报表的精度比LR要差
LoadRunner与Jmeter之间该如何选择?
- 优选选择Jmeter
- Jmeter能解决用Jmeter,Jmeter解决不了的用LoadRunner
四、Jmeter工具使用
文件目录介绍
1.1 bin目录
存放可执行文件和配置文件
jmeter.bat:windows的启动文件
jmeter.log:日志文件
jmeter.sh:linux的启动文件
jmeter-properties:系统配置文件
jmeter-server.bat:windows分布式测试要用到的服务器配置
jmeter-server:linux分布式测试要用到的服务器配置
1.2 docs目录
docs:是Jmeter的api文档,可打开api/index.html页面来查看
1.3 printable_docs目录
printable_docs的usermanual子目录下的内容是Jmeter的用户手册文档。
usermanual下component_reference.html是最常用到的核心元件帮助文档。
提示:printable_docs的demos子目录下有些常用Jmeter脚本案例,可以参考。
1.4 lib目录
该目录用来存放Jmeter依赖的jar包和用户扩展所依赖的jar包。
基础配置
汉化设置
-
临时修改:
options--->language--->choose language--->Chinese
-
永久修改:
-
打开jmeter.properties
-
修改language=zh_CN
-
重启jmeter
-
主题修改
选项--->主题--->选择对应的主题,重启jmeter
基本操作
- 启动jmeter
- 添加线程组
- 添加http请求的取样器,并配置
- 添加查询结果树的监听器
- 点击"启动"运行jmeter,并查看结果
基本元件
线程组:模拟用户的。
配置元件:进行测试环境和测试数据初始化--->比如自动化脚本中setup
前置处理器:对要发送请求进行预处理--->比如自动化脚本中参数化
取样器:往服务器发送请求--->比如自动化脚本中发请求的代码
后置处理器:对收到服务器的响应进行数据提取--->比如自动化脚本中获取响应中特定字段语句
断言:将收到响应结果又预期结果做对比--->比如自动化脚本中断言
监听器:查看测试脚本运行后结果和日志--->比如自动化脚本中测试报告
定时器:等待一段时间--->比如自动化脚本中sleep
测试片段:封装基本功能,不单独执行,需要通过脚本的调用才能执行--->比如自动化脚本中封装函数
作用域
核心:根据测试计划中的树形结构的父子节点来确定的
原则:
- 取样器是没有作用域的。
- 逻辑控制器:只对其子节点下的所有元件有效。
- 其他的元件。
- 如果其父节点是取样器,则只对父节点取样器有效。
- 如果其父节点不是取样器,对父节点下所有子节点及节点中子节点有效。
元件的执行顺序
顺序:配置元件--->前置处理器--->定时器--->取样器--->后置处理器--->断言--->监听器
注意:
- 配置元件、前置处理器、后置处理器都需要依赖取样器才能运行
- 在同一个作用域下,相同类型元件执行顺序是从上到下来按顺序执行
Jemter重要的三个组件
线程组
作用:通过配置线程组中的线程数来模拟用户。线程数就是用户数,线程组是用户组
特点:
- 模拟多用户
- 取样器和逻辑控制器必须在线程组下使用
- 一个测试计划下可以添加多个线程组,可以并行或串行执行
- 并行:默认情况下线程组为并行执行
- 串行:在测试计划下勾上"独立运行每个线程组"
线程组的分类:
- setup线程组:拥有测试前预处理操作,在所有线程组中最先执行
- 普通线程组:来执行业务测试脚本
- teardown线程组:用来测试后的后置处理(数据、恢复环境)的操作,在所有的线程组中最后执行
线程组的属性
线程数:模拟虚拟用户数
Ramp-up时间:虚拟用户启动所需要的时间
循环次数:
- 配置指定次数:控制脚本运行执行的次数
- 配置循环永远
- 需要调度器配置使用
- 运行时间:脚本执行的时间
- 延迟启动时间:脚本等待特定的时间才能开始运行
http请求
http协议:可以填写为HTTP或者HTTPS,默认不填写为HTTP协议
http主机名/ip:如:http://baidu.com 80
端口:可以填写为任意值。默认不填写时为80端口
请求发方法:HTTP协议所有支持的所有方法
路径:目录+参数
编码格式:默认IOS国际标准,推荐使用utf-8
查看结果树
取样器结果:统计请求相关的信息
请求:HTTP请求的请求头和请求体的详情信息
响应:HTTP响应的响应头和响应体的详情信息
jmeter响应中出现乱码时:
- 修改jmeter.properties文件中,sampleresult.default.encoding=utf-8
- 重启jmeter
Jmeter参数化常用方式
用户定义的变量
- 方式1:
添加:线程组--->配置元件--->用户自定义变量
配置:参数名+参数值
使用:在HTTP请求的取样器中引用定义变量。$(参数名)
- 方式2:
配置:在测试计划中去配置用户定义变量
使用:在HTTP请求的取样器中引用定义变量。$(参数名)
应用场景:当大量脚本中的参数值需要修改时候,直接修改用户定义变量中值会更方便
用户参数
添加:线程组--->前置处理器--->用户参数
配置:
- 参数:添加变量
- 参数值:添加用户--->针对每个用户配置不同的参数值
使用:在HTTP请求的取样器中引用定义的变量。$(参数名)
应用场景:可以针对不同的用户获取到不同的参数值
CSV Data Set Config
添加:线程组--->配置元件--->CSV数据文件设置
编写CSV数据文件(.csv作为后缀):
- 多个参数写为多列,其中用逗号分隔
- 多组参数值,则使用多行来设置
配置:
- 路径
- 文件编码:UTF-8
- 变量名称:从CSV数据文件中读取的数据需要保存变量名。有多个变量时用逗号分隔
- 是否忽略首行:是否从CSV文件第一行中开始读取
- 分隔符:要求与CSV数据文件中多列的分隔符一致
- 遇到文件结束符是否再次循环:默认TRUE
- 遇到文件结束符是否停止线程:当前一个参数为FALSE,该参数有效,一般设置为TRUE
函数
counter:
- TRUE:每个用户使用独立计数器
- FALSE:所有的用户使用全局计数器
引用:在取样器中使用$(__counter(FALSE,))来引用对应值
建议大家使用函数方式
Jmeter断言
作用:让脚本自动化执行过程中,能够自动判定执行结果是否符合要求时候,需要添加断言
响应断言
添加:线程组--->HTTP请求--->断言--->响应断言
配置:
- 测试字段:需要检查的字段
- 模式匹配规则:需要使用什么规则来进行检查
- 测试模式:需要校验的值
Json断言
适用于返回的HTTP响应为JSON格式
添加:线程组--->HTTP请求--->断言--->JSON断言
配置:
- JSON PATH:$.weatherinfo.city
- 勾选"Addltonal assert value"
- 在expected value里填写期望值
断言持续时间:
适用于性能测试时,检查HTTP请求的响应时间是否超过预期值
添加:线程组--->HTTP请求--->断言--->断言持续时间
配置:预期时间
Jmeter关联(提取器、数据库、逻辑控制器等)
当多个请求之间有依赖关系,后一个请求的参数需要使用前一个请求的响应数据时,需要用到关联。
分类:
- 正则表达式提取器
- xpath提取器
- Json提取器
提取器
正则提取器
添加:线程组--->HTTP请求--->后置处理器--->正则表达式提取器
配置:
- 要检查的响应字段:默认主体
- 引用名称:匹配后的数据要存储的变量名
- 正则表达式:
(.*?)
,"()"里是要保存的数据 - 模板:$1$
- 数据1代表上面正则表达式中第几个()
- 匹配数字:0代表随机值、1代表第一个结果,-1代表所有结果
- 缺省值:当没有匹配上时将该值保存到变量里
xpath提取器
添加:线程组--->HTTP请求--->后置处理器--->xpath提取器
配置:
- 引用名称:匹配后的数据要存储的变量名
- xpath path:xpath匹配规则
- 匹配数字:0代表随机值、1代表第一个结果,-1代表所有结果
- 缺省值:当没有匹配上时将该值保存到变量里
json提取器
添加:线程组--->HTTP请求--->后置处理器--->json提取器
配置:
- 引用名称:匹配后的数据要存储的变量名
- json path:json路径。$.weatherinfo.city
引用:直接引用变量名即可
数据库
连接准备:
- 打开数据库,确定数据库的表及对应的字段
- 加载mysql的jdbc驱动
- 方法一:将jdbc驱动通过测试计划,浏览的方式添加
- 方式二:将jdbc驱动jar包放入到lib\ext目录下,并重启jmeter
- 配置jdbc connection configuration
- created pool name:给连接池命名,用于后续引用
- 数据库URL:jdbc:mysql://127.0.0.1:3306/test
- 用户名
- 密码
直连数据库使用:
- 添加JDBC Request:取样器下添加
- 配置:
- 配置连接池名称
- 配置SQL语句
- 配置保存的变量名
- 如果SQL语句返回了多个参数,输入相同个数的变量名来保存
- HTTP断言中,就可以引用变量来进行判断
逻辑控制器
控制元件的执行顺序
if控制器
添加:线程组--->逻辑控制器--->if控制器
配置:
- 使用JS预发:"${name}"=="baidu"
- 使用jmeter函数的方式:${__jexl3("${name}"=="baidu",)}
- 推荐使用函数的方式
循环控制器
指定HTTP请求执行特定的次数
添加:线程组--->逻辑控制器--->循环控制器
配置:次数
循环控制器中的循环次数配置m与线程组中的循环次数n配置对比:
- 关系:如果同时配置,循环控制器下HTTP请求实际执行的次数应该是n*m
- 区别:这两个循环次数作用域不同
ForEach控制器
与用户定义的变量或正则表达式提取器配合使用,循环读取返回的变量值,执行一次或多次。
-
与用户定义的变量配合
添加:线程组--->逻辑控制器--->ForEach控制器
配置:
-
用户定义的变量
- 变量名:固定前缀+连续数字
-
ForEach控制器
- 变量前缀:用户定义的变量中配置的固定前缀
- 起始数字:连续数字的最小值-1
- 结束数字:连续数字的最大值
- 输出变量名称:依次读取变量值后存储到参数中,共HTTP请求来引用
-
HTTP请求:
- 引用输出的变量名称
-
-
与正则表达式配合使用
- 先通过正则表达式提取器,提取出请求中所有满足条件数据
- 添加ForEach控制器,并配置提取所有满足条件的数据,并保存为变量
- 在其子节点下,添加HTTP请求并引用变量,可循环读取正则表达式里匹配的所有数据
定时器
同步定时器
需要进行大量用户的并发测试时,为了让用户能真正同时执行,添加"同步定时器"使其阻塞线程,直到线程达到了预先设置数值,才开始进行取样器操作。
配置:
-
并发数:同时达到多少用户才开始发请求
-
超时时间:
- 必须配置:否则当虚拟用户数无法被并发数整除时,会导致有部分用户挂起无法执行
- 配置不能太短:必须比并发数加载时间要长。否则无法达到并发数的要求,数据就会被释放掉
常数吞吐量定时器
用于性能测试中模拟用户产生业务压力,通过给定QPS来对服务器发送固定频率要求。
添加:线程组--->HTTP取样器--->常数吞吐量定时器
配置:吞吐量的值QPS*60
分布式
原理:
- 分布式测试时分为一台控制机和多台代理机
- 控制机负责发布测试任务给代理机
- 代理机接收任务并向服务器发送请求,并接收服务器返回的响应,然后将测试结果返回给控制机
- 由控制机对测试结果数据进行汇总统计
分布式相关注意事项:
- 所有的测试机防火墙都已经关闭
- 所有的测试机及服务器在同一个网络内
- 所有的测试机的jmeter版本和JDK版本完全相同
- 关闭jmeter里的RMI SSL开关
分布式配置
配置
- 代理机
- server_port:不重复。如果使用多个机器做代理机,可不用配置
- 关闭RMI SSL
- 控制机
- remote_server:所有代理机的IP+port,有多个代理机时要使用逗号分隔
- 关闭RMI SSL
运行
- 代理机
- jmeter-server.bat运行
- 控制机:
- jmeter.bat运行
- 控制代理机执行脚本,运行--->远程启动所有
性能测试常用术语解释
性能测试,有些专业术语,为了方便大家的理解,这里用通俗易懂的语言来解释下,若有不准地方,谢谢纠正。
并发:tps
线程数:跑道中参加赛跑的人数
迭代:每人跑多少圈
循环:一次迭代里面,循环跑其中的一条脚本,就是重复来回跑其中一条跑道
参数值:发请求时用的数据
参数化:这是一种策略,上面有介绍到它的具体用法
思考时间:模拟用户等待时间
关联:下一个请求入参依赖上一个请求中的某个返回值
检查点:判断请求的是否成功,一般只有查询请求才会加检查点,也就是断言
集合点:等待所有用户,同一时刻去发起请求,主要应用场景是购物中的秒杀
事务:一般把被测试中某个或者某几个请求一起定义成一个事务,是人为的测试定义,可以是整个下单流程,也可以是下单中的一个请求
负载:服务器的繁忙程度,如果一个服务器,每次可以同时处理8个请求,如果请求数量大,后面请求就排队,排队请求越多,服务器负载就越高
平均响应时间(art):每个事务处理时间,从发送请求到接收到的响应
tps:每秒处理事务数
每秒点击率(数):每秒处理请求数,而不是用户每秒发送请求数
性能学习路线:
jmeter→java基础→beanshell→架构知识→linux分析调优→各种中间件等定位调优
性能测试,从0到实战(包含热门主流技术docker、k8s、skywalking、全链路、微服务、性能调优等)
热门实战性能测试:https://www.cnblogs.com/upstudy/p/15916266.html