深度学习面经总结
文章目录
-
- 1. 深度学习基础
-
- 1.1 为什么需要做特征归一化、标准化?
- 1.2 常用的归一化和标准化的方法有哪些?
- 添加:卷积网特征图大小计算
- 1.3 空洞卷积
-
- 1.3.1 空洞卷积的作用
- 1.3.2. 空洞卷积如何利用多尺度信息
- 1.3.3 空洞卷积感受野计算
- 1.3.4 潜在的问题及解决方法
- 1.3.5 空洞卷积的替代
- 1.4为什么线性回归使用mse作为损失函数?
- 1.5 怎么判断模型是否过拟合,有哪些防止过拟合的策略?
- 1.6 关于BN层的知识点
-
- 1.6.1 BN层是什么
- 1.6.2 BN层的优点
- 1.6.3 为什么BN层一般用在线性层和卷积层后面,而不是放在非线性单元后
- 1.6.4 缺点
- 1.7 优化算法
-
- 1.7.1 Momentum
- 1.7.2 Adam
- 1.7.3 SGD
- 1.7.4 AdaGrad
- 1.7.5 RMSProp
- 1.8 阐述一下感受野的概念
- 1.9 神经网路的深度和宽度分别指的是什么?
- 1.10 下采样的作用是什么?通常有哪些方式?
- 添加:池化层是怎么进行反向传播的?
- 1.11 上采样的原理和常用方式
- 1.12 深度可分离卷积的概念和作用
- 1.13 转置卷积的原理
- 1.14 神经网络中Addition / Concatenate区别是什么?
- 1.15 激活函数
-
- 1.15.1 修正线性单元ReLu系列
- 1.15.2 Sigmoid
- 1.15.3 tanh
- 1.15.4 指数线性单元ELU
- 1.15.5 其他激活函数
- 1.16 激活函数的作用
- 1.17 梯度消失和梯度爆炸怎么解决?
- 1.18 权重初始化
- 1.19 神经网络中1*1卷积有什么作用?
- 1.20 随机梯度下降相比全局梯度下降好处是什么?
- 1.21 为什么神经网络种常用relu作为激活函数?
- 1.22 常用的模型压缩方式有哪些?
- 1.23 常用的一阶、二阶优化算法有哪些?区别是什么?
- 1.24 为什么二阶优化算法更快呢?
- 1.25 为什么深度学习不用二阶的优化算法?
- 1.26 为什么神经网络中用CE交叉熵代替了MSE?
- 1.27 其他归一化层
-
- 1.27.1 Layer Normalization
- 1.27.2 Instance Normalization
- 1.27.3 Group Normalization
- 1.27.4 SwitchableNorm
- 1.28 常用的评价指标
- 1.29 解释神经网络的万能逼近定理
- 1.30 超参数搜索方法
- 1.31 各种距离度量
- 1.32 池化层的作用
- 1.33 Dropout层
-
- 1.33.1 工作原理
- 1.33.2 多角度理解为什么Dropout可以防止过拟合。
- 1.34 过拟合与欠拟合
- 1.35 softmax 损失函数与梯度推导
- 2. 骨干网络模型
-
- 2.1 VGGNet
- 2.2 Inception v1
- 2.3 Inception v2
- 2.4 ResNet
- 2.5 DenseNet
- 2.6 特征金字塔:FPN
- 3. 轻量化网络模型
-
- 3.1 SqueezeNet
- 3.2 深度可分离MobileNet
-
- 3.2.1 MobileNet v1
- 3.2.2 MobileNet v2
- 3.2.3 MobileNet v3
- 3.3 通道混洗ShuffleNet
-
- 3.3.1 通道混洗
- 3.3.2 ShuffleNet v1
- 3.3.3 ShuffleNet v2
- 4. 注意力机制
- 4.1 Convolutional Block Attention Module(CBAM)
-
- 4.1.1 通道注意力机制
- 4.1.2 空间注意力机制
- 4.1.3 CBAM
- 4.2 self-attention
- 4.3 Non-local
- 5. 其他
参考链接
-
https://blog.csdn.net/qq_39056987/article/details/112157031?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242
-
https://zhuanlan.zhihu.com/p/113285797
-
https://blog.csdn.net/e01528/article/details/89313518?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-2.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-2.control
-
《深度学习之Pytorch物体检测》
1. 深度学习基础
1.1 为什么需要做特征归一化、标准化?
- 使不同量纲的特征处于同一数值量级,减少方差大的特征的影响,使模型更准确。
- 加快学习算法的收敛速度
1.2 常用的归一化和标准化的方法有哪些?
线性归一化(min-max标准化)
x’ = (x-min(x)) / (max(x)-min(x)),其中max是样本数据的最大值,min是样本数据的最小值
适用于数值比较集中的情况,可使用经验值常量来来代替max,min
标准差归一化(z-score 0均值标准化)
x’=(x-μ) / σ,其中μ为所有样本的均值,σ为所有样本的标准差
经过处理后符合标准正态分布,即均值为0,标准差为1
非线性归一化
使用非线性函数log、指数、正切等,如y = 1-e^(-x),在x∈[0, 6]变化较明显, 用在数据分化比较大的场景
添加:卷积网特征图大小计算
H height = ⌊ Input height − Filter height + 2 × padding stride + 1 ⌋ W width = ⌊ Input width − Filter width + 2 × padding stride + 1 ⌋ \begin{array}{l} H_{\text {height }}=\left\lfloor\frac{\text { Input height }-\text { Filter }_{\text {height }}+2 \times \text { padding }}{\text { stride }}+1\right\rfloor \\ W_{\text {width }}=\left\lfloor\frac{\text { Input width }-\text { Filter width }+2 \times \text { padding }}{\text { stride }}+1\right\rfloor \end{array} Hheight =⌊ stride Input height − Filter height +2× padding +1⌋Wwidth =⌊ stride Input width − Filter width +2× padding +1⌋
1.3 空洞卷积
1.3.1 空洞卷积的作用
- 空洞卷积最初的提出是为了解决图像分割的问题而提出的。
- 常见的图像分割算法通常使用池化层和卷积层来增加感受野(Receptive Filed),同时也缩小了特征图尺寸(resolution),然后再利用上采样还原图像尺寸,特征图缩小再放大的过程造成了精度上的损失,因此需要一种操作可以在增加感受野的同时保持特征图的尺寸不变,从而代替下采样和上采样操作,在这种需求下,空洞卷积就诞生了。

a是普通的卷积过程(dilation rate = 1),卷积后的感受野为3
b是dilation rate = 2的空洞卷积,卷积后的感受野为5
c是dilation rate = 3的空洞卷积,卷积后的感受野为8
1.3.2. 空洞卷积如何利用多尺度信息
一般每一层的卷积核都是用 [公式] 大小的,而每一层只要设置不同dilation rate时,感受野就会不一样,也即获取了多尺度信息,当然这样操作并不影响特征图的尺寸,这样一来,又避免下采样那样造成信息损失,同时也利用到多尺度信息。
1.3.3 空洞卷积感受野计算
假设空洞卷积的卷积核大小为 k k k ,空洞数为 d d d ,则其等效卷积核大小 k ′ k' k′ ,则
k ′ = k + ( k − 1 ) ( d − 1 ) k'=k+(k-1)(d-1) k′=k+(k−1)(d−1)
当前层的感受野计算公式如下,其中, R F i + 1 RF_{i+1} RFi+1表示当前层的感受野, , R F i RF_{i} RFi表示上一层的感受野, k ′ k' k′ 表示卷积核的大小
R F i + 1 = R F i + ( k ′ − 1 ) S i RF_{i+1} = RF_{i}+(k'-1)S_i RFi+1=RFi+(k′−1)Si
S i S_i Si表示之前所有层的步长的乘积(不包括本层),公式如下:
S i = ∏ i = 1 i Stride i S_{i}=\prod_{i=1}^{i} \text { Stride }_{i} Si=i=1∏i Stride i
1.3.4 潜在的问题及解决方法
(1)棋盘格效应
由于空洞卷积的计算方式类似于棋盘格式,某一层得到的卷积结果,来自上一层的独立的集合,没有相互依赖,因此该层的卷积结果之间没有相关性,即局部信息丢失。这对 pixel-level dense prediction 的任务来说是致命的。
(2)远距离获取的信息没有相关性:由于空洞卷积稀疏的采样输入信号,使得远距离卷积得到的信息之间没有相关性,影响分类结果。
1.3.5 空洞卷积的替代
可以使用跨层连接上采样弥补信息。
1.4为什么线性回归使用mse作为损失函数?
在使用线性回归的时候的基本假设是噪声服从正态分布,当噪声符合正态分布N(0,delta2)时,因变量则符合正态分布N(ax(i)+b,delta2),其中预测函数y=ax(i)+b。这个结论可以由正态分布的概率密度函数得到。也就是说当噪声符合正态分布时,其因变量必然也符合正态分布。因此,我们使用mse的时候实际上是假设y服从正态分布的。
具体地:在解决这个问题的时候,我们使用最大似然估计进行求解系数。在求解对数似然函数的时候,由于高斯分布由平方项,会导致最终的求解结果是MSE。
1.5 怎么判断模型是否过拟合,有哪些防止过拟合的策略?
在构建模型的过程中,通常会划分训练集、测试集。
当模型在训练集上精度很高,在测试集上精度很差时,模型过拟合;当模型在训练集和测试集上精度都很差时,模型欠拟合。
- 预防过拟合策略:
从训练数据的角度:
(1)增加训练数据:获取更多数据,也可以使用图像增强、增样等;
(2)数据清洗:去除问题数据、错误标签和噪声数据;
从网络模型的角度:
(3)使用合适的模型:适当减少网络的层数、降低网络参数量;
(4)Dropout:随机抑制网络中一部分神经元,使的每次训练都有一批神经元不参与模型训练;
(5)在网络中使用BN层(Batch Normalization)也可以一定程度上防止过拟合。
从训练技巧的角度:
(6)L1、L2正则化:训练时限制权值的大小,增加惩罚机制,使得网络更稀疏;
(7)限制网络训练时间:在训练时将训练集和验证集损失分别输出,当训练集损失持续下降,而验证集损失不再下降时,网络就开始出现过拟合现象,此时就可以停止训练了;
1.6 关于BN层的知识点
参考链接
1.6.1 BN层是什么

- 为了追求更高的性能, 卷积网络被设计得越来越深,然而网络却变得难以训练收敛与调参。原因在于,浅层参数的微弱变化经过多层线性变换与激活函数后会被放大,改变了每一层的输入分布, 造成深层的网络需要不断调整以适应这些分布变化,最终导致模型难以训练收敛。
- 由于网络中参数变化导致的内部节点数据分布发生变化的现象被称做ICS(Internal Covariate Shift)。ICS现象容易使训练过程陷入饱和区, 减慢网络的收敛。 前面提到的ReLU从激活函数的角度出发, 在一定程度上解决了梯度饱和的现象, 而2015年提出的BN层, 则从改变数据分布的角度避免了参数陷入饱和区。 由于BN层优越的性能, 其已经是当前卷积网络中的“标配”。
1.6.2 BN层的优点
(1)BN使得网络中每层输入数据的分布相对稳定,加速模型学习速度
BN通过规范化与线性变换使得每一层网络的输入数据的均值与方差都在一定范围内,使得后一层网络不必不断去适应底层网络中输入的变化,从而实现了网络中层与层之间的解耦,更加有利于优化的过程,提高整个神经网络的学习速度。
(2)BN使得模型对初始化方法和网络中的参数不那么敏感,简化调参过程,使得网络学习更加稳定
(3)BN允许网络使用饱和性激活函数(例如sigmoid,tanh等),缓解梯度消失问题
在不使用BN层的时候,由于网络的深度与复杂性,很容易使得底层网络变化累积到上层网络中,导致模型的训练很容易进入到激活函数的梯度饱和区;通过normalize操作可以使得参数值落到0附近,也就是梯度非饱和区,缓解梯度消失的问题。
(4)BN具有一定的正则化效果
在Batch Normalization中,由于我们使用mini-batch的均值与方差作为对整体训练样本均值与方差的估计,尽管每一个batch中的数据都是从总体样本中抽样得到,但不同mini-batch的均值与方差会有所不同,这就为网络的学习过程中增加了随机噪音,与Dropout通过关闭神经元给网络训练带来噪音类似,在一定程度上对模型起到了正则化的效果。原作者也证明了网络加入BN后,可以丢弃Dropout,模型也同样具有很好的泛化效果。
(5)用上BN层之后可以使用更大的学习率,从而跳出不好的局部极值,增强泛化能力。
1.6.3 为什么BN层一般用在线性层和卷积层后面,而不是放在非线性单元后
原文中是这样解释的,因为非线性单元的输出分布形状会在训练过程中变化,归一化无法消除他的方差偏移,相反的,全连接和卷积层的输出一般是一个对称,非稀疏的一个分布,更加类似高斯分布,对他们进行归一化会产生更加稳定的分布。其实想想也是的,像relu这样的激活函数,如果你输入的数据是一个高斯分布,经过他变换出来的数据能是一个什么形状?小于0的被抑制了,也就是分布小于0的部分直接变成0了,这样不是很高斯了。
1.6.4 缺点
- 由于是在batch的维度进行归一化,BN层要求较大的batch才能有效地工作, 而物体检测等任务由于占用内存较高,限制了batch的大小,这会限制BN层有效地发挥归一化功能。
- 数据的batch大小在训练与测试时往往不一样。在训练时一般采用滑动来计算平均值与方差,在测试时直接拿训练集的平均值与方差来使用。这种方式会导致测试集依赖于训练集,然而有时训练集与测试集的数据分布并不一致。最新的工作GN(Group Normalization) 从通道方向计算均值与方差, 使用更为灵活有效, 避开了batch大小对归一化的影响。
1.7 优化算法
基本梯度下降法,包括 GD,BGD,SGD;
动量优化法,包括 Momentum,NAG 等;
自适应学习率优化法,包括 Adam,AdaGrad,RMSProp 等
参考链接
Momentum --> Nesterov Momentum
AdaGrad --> RMSProp --> AdaDelta
Adam是Momentum与RMSProp的一个结合体
Adam --> AdaMax
Nesterov与AdaMax结合变成NadaMax
NAdam是Nesterov Momentum与RMSProp组合
1.7.1 Momentum
Momentum是在前面简单的梯度下降上添加一个动量,从物理角度上看就是给了它一个惯性,使得在一直下落的路上,速度越来越快,而在遇到局部最优,有可能借着惯性冲出去。
优点:使得物体的震荡减弱,更快地运动到最优解
v i = α v i − 1 + ( 1 − α ) g i Δ w = − η v i \begin{aligned} v_{i} &=\alpha v_{i-1}+(1-\alpha) g_{i} \\ \Delta w &=-\eta v_{i} \end{aligned} viΔw=αvi−1+(1−α)gi=−ηvi
1.7.2 Adam
Adam的名称来自Adaptive Momentum,可以看作是Momentum与RMSProp的一个结合体,该算法通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
s i = α s i − 1 + ( 1 − α ) g i r i = β r i − 1 + ( 1 − β ) g i , 2 s ^ i = s i 1 − α i r ^ i = r i 1 − β i Δ w = − η s ^ i r ^ i + ϵ w = w + Δ w \begin{aligned} s_{i} &=\alpha s_{i-1}+(1-\alpha) g_{i} \\ r_{i} &=\beta r_{i-1}+(1-\beta) g_{i,}^{2} \\ \hat{s}_{i} &=\frac{s_{i}}{1-\alpha^{i}} \\ \hat{r}_{i} &=\frac{r_{i}}{1-\beta^{i}} \\ \Delta w &=-\eta \frac{\hat{s}_{i}}{\sqrt{\hat{r}_{i}+\epsilon}} \\ w &=w+\Delta w \end{aligned} siris^ir^iΔww=αsi−1+(1−α)gi=βri−1+(1−β)gi,2=1−αisi=1−βiri=−ηr^i+ϵs^i=w+Δw
- 计算效率高
- 很少的内存需求
- 梯度的对角线重缩放不变(这意味着亚当将梯度乘以仅带正因子的对角矩阵是不变的,以便更好地理解此堆栈交换)
- 非常适合数据和/或参数较大的问题
- 适用于非固定目标
- 适用于非常嘈杂和/或稀疏梯度的问题
- 超参数具有直观的解释,通常需要很少的调整(我们将在配置部分中对此进行详细介绍
1.7.3 SGD
常规的SGD
Δ w = − η J ′ ( w ) \Delta w=-\eta J^{\prime}(w) Δw=−ηJ′(w)
不过相比SGD,用的更多的还是小批量梯度下降(mBGD)算法,不同之处在于一次训练使用多个样本,然后取所有参与训练样本梯度的平均来更新参数,公式如下:
Δ w = − η g i g i = 1 m ∑ k = 1 m J ′ ( w ) \begin{aligned} \Delta w &=-\eta g_{i} \\ g_{i} &=\frac{1}{m} \sum_{k=1}^{m} J^{\prime}(w) \end{aligned} Δwgi=−ηgi=m1k=1∑mJ′(w)
注意:随机梯度下降(SGD)是指每次随机挑选一个样本用于梯度下降;批量梯度下降(BGD)是指每次使用所有样本用于梯度下降;小批量梯度下降(mBGD)是指每次挑选一部分样本用于梯度下降,当遍历完所有的训练数据,称之为一个epoch。一般程序里都是用的mBGD。
1.7.4 AdaGrad
AdaGrad全称为Adaptive Subgradient,其主要特点在于不断累加每次训练中梯度的平方。
自适应地为各个参数分配不同学习率的算法。
r i = r i − 1 + g i 2 Δ w = − η ϵ + r i g i w = w + Δ w \begin{aligned} r_{i} &=r_{i-1}+g_{i}^{2} \\ \Delta w &=-\frac{\eta}{\epsilon+\sqrt{r_{i}}} g_{i} \\ w &=w+\Delta w \end{aligned} riΔww=ri−1+gi2=−ϵ+riηgi=w+Δw
缺点:梯度会急剧下降
1.7.5 RMSProp
RMSProp是AdaGrad的改进算法
r i = β r i − 1 + ( 1 − β ) g i 2 Δ w = − η ϵ + r i g i w = w + Δ w \begin{aligned} r_{i} &=\beta r_{i-1}+(1-\beta) g_{i}^{2} \\ \Delta w &=-\frac{\eta}{\epsilon+\sqrt{r_{i}}} g_{i} \\ w &=w+\Delta w \end{aligned} riΔww=βri−1+(1−β)gi2=−ϵ+riηgi=w+Δw
- 优点:
相比于AdaGrad,这种方法很好的解决了深度学习中过早结束的问题
适合处理非平稳目标,对于RNN效果很好 - 缺点:
又引入了新的超参,衰减系数
依然依赖于全局学习速率
1.8 阐述一下感受野的概念
感受野指的是卷积神经网络每一层输出的特征图上每个像素点映射回输入图像上的区域的大小,神经元感受野的范围越大表示其接触到的原始图像范围就越大,也就意味着它能学习更为全局,语义层次更高的特征信息,相反,范围越小则表示其所包含的特征越趋向局部和细节。因此感受野的范围可以用来大致判断每一层的抽象层次,并且我们可以很明显地知道网络越深,神经元的感受野越大。
卷积层的感受野大小与其之前层的卷积核尺寸和步长有关,与padding无关。
第i层特征图上的点在第i-1层上的感受野公式:
R F [ i − 1 ] = ( R F [ i ] − 1 ) ∗ stride [ i − 1 ] + ksize [ i − 1 ] RF[i-1]=(RF[i]-1) * \text { stride }[i-1]+\text { ksize }[i-1] RF[i−1]=(RF[i]−1)∗ stride [i−1]+ ksize [i−1]如果当前要求第n层的特征图的感受野,初始 R F [ n ] = 1 RF[n] = 1 RF[n]=1.
1.9 神经网路的深度和宽度分别指的是什么?
神经网络的深度决定了网络的表达能力,早期的backbone设计都是直接堆叠卷积层,它的深度指的是神经网络的层数;后来的backbone设计采用了更高效的module(或block)堆叠的方式,每个module是由多个卷积层组成,这时深度指的是module的个数。
神经网络的宽度决定了网络在某一层学习到的信息量,指的是卷积神经网络中最大的通道数,由卷积核数量最多的层决定。通常的结构设计中卷积核的数量随着层数越来越多的,直到最后一层feature map达到最大,这是因为越到深层,feature map的分辨率越小,所包含的信息越高级,所以需要更多的卷积核来进行学习。通道越多效果越好,但带来的计算量也会大大增加,所以具体设定也是一个调参的过程,并且各层通道数会按照8×的倍数来确定,这样有利于GPU的并行计算。
1.10 下采样的作用是什么?通常有哪些方式?
下采样层有两个作用,一是减少计算量,防止过拟合;二是增大感受野,使得后面的卷积核能够学到更加全局的信息。下采样的方式主要有两种:
- 采用stride为2的池化层,如Max-pooling和Average-pooling,目前通常使用Max-pooling,因为他计算简单而且能够更好的保留纹理特征;
- 采用stride为2的卷积层,下采样的过程是一个信息损失的过程,而池化层是不可学习的,用stride为2的可学习卷积层来代替pooling可以得到更好的效果,当然同时也增加了一定的计算量。
添加:池化层是怎么进行反向传播的?
https://blog.csdn.net/weixin_41683218/article/details/86473488
mean pooling的前向传播就是把一个patch中的值求取平均来做pooling,那么反向传播的过程也就是把某个元素的梯度等分为n份分配给前一层,这样就保证池化前后的梯度(残差)之和保持不变,还是比较理解的,图示如下

max pooling也要满足梯度之和不变的原则,max pooling的前向传播是把patch中最大的值传递给后一层,而其他像素的值直接被舍弃掉。那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为0。所以max pooling操作和mean pooling操作不同点在于需要记录下池化操作时到底哪个像素的值是最大,也就是max id。

1.11 上采样的原理和常用方式
在卷积神经网络中,由于输入图像通过卷积神经网络(CNN)提取特征后,输出的尺寸往往会变小,而有时我们需要将图像恢复到原来的尺寸以便进行进一步的计算(如图像的语义分割),这个使图像由小分辨率映射到大分辨率的操作,叫做上采样,它的实现一般有三种方式:
插值,一般使用的是双线性插值,因为效果最好,虽然计算上比其他插值方式复杂,但是相对于卷积计算可以说不值一提,其他插值方式还有最近邻插值、三线性插值等;
转置卷积又或是说反卷积,通过对输入feature map间隔填充0,再进行标准的卷积计算,可以使得输出feature map的尺寸比输入更大;
Max Unpooling,在对称的max pooling位置记录最大值的索引位置,然后在unpooling阶段时将对应的值放置到原先最大值位置,其余位置补0;
1.12 深度可分离卷积的概念和作用
深度可分离卷积将传统的卷积分两步进行,分别是depthwise和pointwise。首先按照通道进行计算按位相乘的计算,深度可分离卷积中的卷积核都是单通道的,输出不能改变feature map的通道数,此时通道数不变;然后依然得到将第一步的结果,使用1*1的卷积核进行传统的卷积运算,此时通道数可以进行改变。

https://www.jianshu.com/p/6db4e6e2b7a7

1.13 转置卷积的原理
转置卷积又称反卷积(Deconvolution),它和空洞卷积的思路正好相反,是为上采样而生,也应用于语义分割当中,而且他的计算也和空洞卷积正好相反,先对输入的feature map间隔补0,卷积核不变,然后使用标准的卷积进行计算,得到更大尺寸的feature map。
1.14 神经网络中Addition / Concatenate区别是什么?
Addition和Concatenate分支操作统称为shortcut,Addition是在ResNet中提出,两个相同维度的feature map相同位置点的值直接相加,得到新的相同维度feature map,这个操作可以融合之前的特征,增加信息的表达,Concatenate操作是在Inception中首次使用,被DenseNet发扬光大,和addition不同的是,它只要求两个feature map的HW相同,通道数可以不同,然后两个feature map在通道上直接拼接,得到一个更大的feature map,它保留了一些原始的特征,增加了特征的数量,使得有效的信息流继续向后传递。
1.15 激活函数
参考链接
1.15.1 修正线性单元ReLu系列
ReLU、ReLU6和leaky ReLU;ReLU6与ReLU相比也只是在正向部分多了个阈值,大于6的值等于6,而leaky ReLU和ReLU正向部分一样,都是大于0等于原始值,但负向部分却是等于原始值的1/10,浮点运算的话乘个0.1就好了。
ReLU函数的优点:
- 解决了梯度消失的问题;
- 计算速度和收敛速度非常快;
ReLU函数的缺点:
- 低维特征向高维转换时会部分丢失;
- 均值为非零;
1.15.2 Sigmoid
Sigmoid、swish、h-sigmoid、h-swish;sigmoid对低性能的硬件来说非常不友好,因为涉及到大量的exp指数运算和除法运算,于是有研究人员针对此专门设计了近似的硬件友好的函数h-sigmoid和h-swish函数,这里的h指的就是hardware的意思。


1.15.3 tanh
tanh x = sinh x cosh x = e x − e − x e x + e − x \tanh x=\frac{\sinh x}{\cosh x}=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}} tanhx=coshxsinhx=ex+e−xex−e−x
tanh函数的优点:
- Tanh 函数的导数比 Sigmoid 函数导数值更大、梯度变化更快,在训练过程中收敛速度更快;
- 使得输出均值为 0,可以提高训练的效率;
- 将线性函数转变为非线性函数;
tanh函数的缺点:
- 幂运算相对来讲比较耗时;
- 容易出现梯度消失;
1.15.4 指数线性单元ELU
f ( x ) = { α ( e x − 1 ) , x ≤ 0 x , x > 0 f ′ ( x ) = { f ( x ) + α , x ≤ 0 1 , x > 0 \begin{array}{l} f(x)=\left\{\begin{array}{ll} \alpha\left(e^{x}-1\right), & x \leq 0 \\ x, & x>0 \end{array}\right. \\ f^{\prime}(x)=\left\{\begin{array}{ll} f(x)+\alpha, & x \leq 0 \\ 1, & x>0 \end{array}\right. \end{array} f(x)={α(ex−1),x,x≤0x>0f′(x)={f(x)+α,1,x≤0x>0
1.15.5 其他激活函数
-
softplus: f ( x ) = log ( 1 + e x ) f(x) = \log \left(1+e^{x}\right) f(x)=log(1+ex)

softplus函数与ReLU函数接近,但比较平滑, 同ReLU一样是单边抑制,有宽广的接受域(0,+inf), 但是由于指数运算,对数运算计算量大的原因,而不太被人使用.并且从一些人的使用经验来看(Glorot et al.(2011a)),效果也并不比ReLU好. softplus的导数恰好是sigmoid函数。 -
Leaky ReLU: f ( x ) = max ( α x , x ) f(x)=\max (\alpha x, x) f(x)=max(αx,x)
当固定为α=0.01α=0.01时,是Leaky ReLU。当 αα 从高斯分布中随机产生时称为Random Rectifier(RReLU)。将 α 作为可学习的参数,称为Parametric Rectifier(PReLU)。 -
Maxout激活函数
与常规激活函数不同的是,它是一个可学习的分段线性函数.
然而任何一个凸函数,都可以由线性分段函数进行逼近近似。其实我们可以把以前所学到的激活函数:ReLU、abs激活函数,看成是分成两段的线性函数。实验结果表明Maxout与Dropout组合使用可以发挥比较好的效果。 -
Maxout
Maxout可以看做是在深度学习网络中加入一层激活函数层,包含一个参数k。这一层相比ReLU,sigmoid等,其特殊之处在于增加了k个神经元,然后输出激活值最大的值。
- 优点:
- Maxout的拟合能力非常强,可以拟合任意的凸函数。
- Maxout具有ReLU的所有优点,线性、不饱和性。
- 同时没有ReLU的一些缺点。如:神经元的死亡。
- 缺点:
- 从上面的激活函数公式中可以看出,每个神经元中有两组(w,b)参数,那么参数量就增加了一倍,这就导致了整体参数的数量激增。
-
swish: f ( x ) = x ⋅ sigmoid ( β x ) f(x)=x \cdot \operatorname{sigmoid}(\beta x) f(x)=x⋅sigmoid(βx)
β是个常数或可训练的参数.Swish 具备无上界有下界、平滑、非单调的特性。 Swish 在深层模型上的效果优于 ReLU。 -
SELU(自归一化线性单元):是给ELU乘上系数 λλ, 即 SELU(x)=λ⋅ELU(x)
f ( x ) = λ { α ( e x − 1 ) x ≤ 0 x x > 0 f(x)=\lambda\left\{\begin{array}{ll} \alpha\left(e^{x}-1\right) & x \leq 0 \\ x & x>0 \end{array}\right. f(x)=λ{α(ex−1)xx≤0x>0 -
GELU(高斯误差线性单元)
1.16 激活函数的作用
参考
- 加入非线性因素
- 充分组合特征
1.17 梯度消失和梯度爆炸怎么解决?
https://zhuanlan.zhihu.com/p/72589432
- 防止梯度爆炸:
- 预训练+微调
- 梯度剪切:对梯度设定阈值
- 权重正则化
- 选择合适的激活函数
- 防止梯度消失:
- 残差网络
- BN层
- 选择合适的激活函数
1.18 权重初始化
- 常数
- 正态分布(RandomNormal)
- RandomUniform
- xaiver。Xavier假设激活函数关于0对称,在0附近为线性函数。适用于tanh和softsign激活函数。
- he初始化。He初始化适用于Relu激活函数。
- Orthogonal
1.19 神经网络中1*1卷积有什么作用?
- 降维,减少计算量;在ResNet模块中,先通过1*1卷积对通道数进行降通道,再送入3*3的卷积中,能够有效的减少神经网络的参数量和计算量;
- 升维;用最少的参数拓宽网络通道,通常在轻量级的网络中会用到,经过深度可分离卷积后,使用1*1卷积核增加通道的数量,例如mobilenet、shufflenet等;
- 实现跨通道的交互和信息整合;增强通道层面上特征融合的信息,在feature map尺度不变的情况下,实现通道升维、降维操作其实就是通道间信息的线性组合变化,也就是通道的信息交互整合的过程;
- 1*1卷积核可以在保持feature map尺度(不损失分辨率)不变的情况下,大幅增加非线性特性(利用后接的非线性激活函数)。
1.20 随机梯度下降相比全局梯度下降好处是什么?
当处理大量数据时,比如SSD或者faster-rcnn等目标检测算法,每个样本都有大量候选框参与训练,这时使用随机梯度下降法能够加快梯度的计算;
每次只随机选取一个样本来更新模型参数,因此每次的学习是非常快速的,并且可以进行在线更新。
1.21 为什么神经网络种常用relu作为激活函数?
在前向传播和反向传播过程中,ReLU相比于Sigmoid等激活函数计算量小;
在反向传播过程中,Sigmoid函数存在饱和区,若激活值进入饱和区,则其梯度更新值非常小,导致出现梯度消失的现象。而ReLU没有饱和区,可避免此问题;
ReLU可令部分神经元输出为0,造成网络的稀疏性,减少前后层参数对当前层参数的影响,提升了模型的泛化性能;
1.22 常用的模型压缩方式有哪些?
- 使用轻量型的特征提取网络,例如:mobileNet、- -shuffleNet、GhostNet系列等等;
- 通道、层剪枝;
- 模型蒸馏;
- 模型量化。
模型参数量化将FP32的数值精度量化到FP16、INT8、二值网络、三值网络等。
1.23 常用的一阶、二阶优化算法有哪些?区别是什么?
一阶的有:梯度下降法GD、SGD、ASGD、指数加权平均AdaDelta、RMSProp、Adam
二阶的有:牛顿法、拟牛顿法(二阶收敛更快)
基础概念:
- 梯度(一阶导数)考虑一座在 (x1, x2) 点高度是 f(x1, x2) 的山。那么,某一点的梯度方向是在该点坡度最陡的方向,而梯度的大小告诉我们坡度到底有多陡。
- Hesse 矩阵(二阶导数,二阶梯度)
- 牛顿法是一种在实数域和复数域上近似求解方程的方法。方法使用函数f (x)的泰勒级数的前面几项来寻找方程f (x) = 0的根。牛顿法最大的特点就在于它的收敛速度很快。主要有两个缺陷,一个是需要计算Hessian矩阵,需要 O ( n p 2 ) O(np^2) O(np2) 的复杂度,另外一个便是计算Hessian的逆矩阵需要 O ( p 3 ) O(p^3) O(p3)的复杂度。
- 拟牛顿法:本质思想是改善牛顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度。
1.24 为什么二阶优化算法更快呢?
- 更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部。梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。(牛顿法目光更加长远,所以少走弯路;相对而言,梯度下降法只考虑了局部的最优,没有全局思想。)
- 根据wiki上的解释,从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
1.25 为什么深度学习不用二阶的优化算法?
但相比于一阶梯度,二阶优化问题:
(1)计算量大,训练非常慢。
(2)二阶方法能够更快地求得更高精度的解,这在浅层模型是有益的。而在神经网络这类深层模型中对参数的精度要求不高,甚至不高的精度对模型还有益处,能够提高模型的泛化能力。
(3)稳定性。越简单的模型越robust。
1.26 为什么神经网络中用CE交叉熵代替了MSE?
知乎
- 很多解释是从收敛速度角度阐述的。就是当网络使用sigmoid作为激活函数时,使用MSE作为损失函数可能会遇到当预测值和真值误差很大时,收敛速度却很慢。而使用CE就不会有这种问题。但是如果我们把激活函数换成Leaky,这种解释就行不通了。
- 在知乎上看到了更加合适的解释方法:
MSE是高斯分布的最大似然;
CE是多项式分布的最大似然;
对于回归任务
f ( x ) = 1 2 π σ exp − ( x − u ) 2 2 σ 2 f(x)=\frac{1}{\sqrt{2 \pi} \sigma} \exp ^{-\frac{(x-u)^{2}}{2 \sigma^{2}}} f(x)=2πσ1exp−2σ2(x−u)2
假设误差服从均值为零的高斯分布,对可观测样本集Y,其对数似然
l = log ( L ( θ ) ) = ∏ i = 1 m log [ 1 2 π σ exp − ( y i − y ^ i ) 2 2 σ 2 ] = m log 1 2 π σ − 1 2 σ 2 ∑ i = 1 m ( y i − y ^ i ) 2 ⇒ 1 2 ∑ i = 1 m ( y i − y ^ i ) 2 \begin{array}{c} l=\log (L(\theta))=\prod_{i=1}^{m} \log \left[\frac{1}{\sqrt{2 \pi} \sigma} \exp ^{-\frac{\left(y_{i}-\hat{y}_{i}\right)^{2}}{2 \sigma^{2}}}\right] \\ =m \log \frac{1}{\sqrt{2 \pi} \sigma}-\frac{1}{2 \sigma^{2}} \sum_{i=1}^{m}\left(y_{i}-\hat{y}_{i}\right)^{2} \\ \Rightarrow \frac{1}{2} \sum_{i=1}^{m}\left(y_{i}-\hat{y}_{i}\right)^{2} \end{array} l=log(L(θ))=∏i=1mlog[2πσ1exp−2σ2(yi−y^i)2]=mlog2πσ1−2σ21∑i=1m(yi−y^i)2⇒21∑i=1m(yi−y^i)2
对于分类任务
单标签多分类任务->多项式分布的概率质量函数:
f ( Y ∣ p ) = ∏ j = 1 n p j y j f(Y \mid p)=\prod_{j=1}^{n} p_{j}^{y_{j}} f(Y∣p)=j=1∏npjyj这里 n n n表示类别数量。其对数似然函数为:
l = log ∏ i = 1 m ∏ j = 1 n p j y j = ∑ i = 1 m ∑ j = 1 n y j log p j l=\log \prod_{i=1}^{m} \prod_{j=1}^{n} p_{j}^{y_{j}}=\sum_{i=1}^{m} \sum_{j=1}^{n} y_{j} \log p_{j} l=logi=1∏mj=1∏npjyj=i=1∑mj=1∑nyjlogpj,其中 m m m表示样本数量。机器学习中one-hot编码 y j = 0 y_j=0 yj=0 的项乘积为0,只考虑 y j = 1 y_j=1 yj=1,简化为:
l = ∑ i = 1 m y j log p j l=\sum_{i=1}^{m} y_{j} \log p_{j} l=i=1∑myjlogpj
约束条件 ∑ p j = 1 \sum p_{j}=1 ∑pj=1 ,一般网络输出后接softmax。
所以分类任务用交叉熵损失,回归任务用均方误差。
1.27 其他归一化层
参考链接
1.27.1 Layer Normalization
batch normalization存在以下缺点:
对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布;
BN实际使用时需要计算并且保存某一层神经网络batch的均值和方差等统计信息,对于对一个固定深度的前向神经网络(DNN,CNN)使用BN,很方便;但对于RNN来说,sequence的长度是不一致的,换句话说RNN的深度不是固定的,不同的time-step需要保存不同的statics特征,可能存在一个特殊sequence比其他sequence长很多,这样training时,计算很麻烦。
与BN不同,LN是针对深度网络的某一层的所有神经元的输入按以下公式进行normalize操作。
BN与LN的区别在于:
LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;
BN中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差。
所以,LN不依赖于batch的大小和输入sequence的深度,因此可以用于batchsize为1和RNN中对边长的输入sequence的normalize操作。
μ l = 1 H ∑ i = 1 H a i l σ l = 1 H ∑ i = 1 H ( a i l − μ l ) 2 \mu^{l}=\frac{1}{H} \sum_{i=1}^{H} a_{i}^{l} \quad \sigma^{l}=\sqrt{\frac{1}{H} \sum_{i=1}^{H}\left(a_{i}^{l}-\mu^{l}\right)^{2}} μl=H1i=1∑Hailσl=H1i=1∑H(ail−μl)2
BN与LN的区别在于:
- LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;
- BN中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差。
所以,LN不依赖于batch的大小和输入sequence的深度,因此可以用于batchsize为1和RNN中对边长的输入sequence的normalize操作。
LN用于RNN效果比较明显,但是在CNN上,不如BN。
1.27.2 Instance Normalization
BN注重对每个batch进行归一化,保证数据分布一致,因为判别模型中结果取决于数据整体分布。
但是图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
y t i j k = x t i j k − μ t i σ t i 2 + ϵ , μ t i = 1 H W ∑ l = 1 W ∑ m = 1 H x t i l m , σ t i 2 = 1 H W ∑ l = 1 W ∑ m = 1 H ( x t i l m − m u t i ) 2 . y_{t i j k}=\frac{x_{t i j k}-\mu_{t i}}{\sqrt{\sigma_{t i}^{2}+\epsilon}}, \quad \mu_{t i}=\frac{1}{H W} \sum_{l=1}^{W} \sum_{m=1}^{H} x_{t i l m}, \quad \sigma_{t i}^{2}=\frac{1}{H W} \sum_{l=1}^{W} \sum_{m=1}^{H}\left(x_{t i l m}-m u_{t i}\right)^{2} . ytijk=σti2+ϵxtijk−μti,μti=HW1l=1∑Wm=1∑Hxtilm,σti2=HW1l=1∑Wm=1∑H(xtilm−muti)2.
1.27.3 Group Normalization
主要是针对Batch Normalization对小batchsize效果差,GN将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值,这样与batchsize无关,不受其约束。

1.27.4 SwitchableNorm
本篇论文作者认为,
- 第一,归一化虽然提高模型泛化能力,然而归一化层的操作是人工设计的。在实际应用中,解决不同的问题原则上需要设计不同的归一化操作,并没有一个通用的归一化方法能够解决所有应用问题;
- 第二,一个深度神经网络往往包含几十个归一化层,通常这些归一化层都使用同样的归一化操作,因为手工为每一个归一化层设计操作需要进行大量的实验。
因此作者提出自适配归一化方法——Switchable Normalization(SN)来解决上述问题
1.28 常用的评价指标
1.29 解释神经网络的万能逼近定理
只要激活函数选择得当,神经元的数量足够,至少有一个隐含层的神经网络可以逼近闭区间上任意一个连续函数到任意指定的精度。
1.30 超参数搜索方法
- 网格搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。
- 贝叶斯优化:贝叶斯优化其实就是在函数方程不知的情况下根据已有的采样点预估函数最大值的一个算法。该算法假设函数符合高斯过程(GP)。
- 随机搜索:已经发现,简单地对参数设置进行固定次数的随机搜索,比在穷举搜索中的高维空间更有效。这是因为事实证明,一些超参数不通过特征变换的方式把低维空间转换到高维空间,而在低维空间不可分的数据,到高维空间中线性可分的几率会高一些。具体方法:核函数,如:高斯核,多项式核等等。
- 基于梯度:计算相对于超参数的梯度,然后使用梯度下降优化超参数。
1.31 各种距离度量
参考链接
简单说来,各种"距离"的应用场景简单概括为:
- 空间:欧氏距离
- 路径:曼哈顿距离 国际象棋国王:切比雪夫距离 (以上三种的统一形式:闵可夫斯基距离)
- 加权:标准化欧氏距离
- 排除量纲和依存:马氏距离
- 向量差距:夹角余弦
- 编码差别:汉明距离
- 集合近似度:杰卡德相似系数与距离
- 相关:相关系数与相关距离
- 时间序列:DTW距离
1.32 池化层的作用
搬运自《深度学习之Pytorch物体检测》
- 降低特征图的参数量, 提升计算速度, 增加感受野, 是一种降采样操作。
- 增大感受野
- 池化是一种较强的先验, 可以使模型更关注全局特征而非局部出现的位置, 这种降维的过程可以保留一些重要的特征信息, 提升容错能力, 并且还能在一定程度上起到防止过拟合的作用。
- 在物体检测中, 常用的池化有最大值池化(Max Pooling) 与平均值池化(Average Pooling) 。
1.33 Dropout层
搬运自《深度学习之Pytorch物体检测》
1.33.1 工作原理
在训练时, 每个神经元以概率p保留, 即以1-p的概率停止工作, 每次前向传播保留下来的神经元都不同, 这样可以使得模型不太依赖于某些局部特征, 泛化性能更强。在测试时, 为了保证相同的输出期望值, 每个参数还要乘以p。当然还有另外一种计算方式称为Inverted Dropout, 即在训练时将保留下的神经元乘以1/p, 这样测试时就不需要再改变权重。
1.33.2 多角度理解为什么Dropout可以防止过拟合。
- 多模型的平均:不同的固定神经网络会有不同的过拟合,多个取平均则有可能让一些相反的拟合抵消掉,而Dropout每次都是不同的神经元失活,可以看做是多个模型的平均,类似于多数投票取胜的策略。
- 减少神经元间的依赖:由于两个神经元不一定同时有效,因-此减少了特征之间的依赖,迫使网络学习有更为鲁棒的特征,因为神经网不应该对特定的特征敏感,而应该从众多特征中学习更为共同的规律,这也起到了正则化的效果。
- 生物进化:Dropout类似于性别在生物进化中的角色,物种为了适应环境变化,在繁衍时取雄性和雌性的各一半基因进行组合,这样可适应更复杂的新环境,避免了单一基因的过拟合,当环境发生变化时也不至于灭绝。
1.34 过拟合与欠拟合
1.35 softmax 损失函数与梯度推导
https://blog.csdn.net/normol/article/details/84322626
- 将score映射到概率的softmax function, f i = W i x f_i=W_i x fi=Wix
p i = e f i ∑ k e f k p_i = \frac{e^{f_i}}{\sum_k e^{f_k}} pi=∑kefkefi - 对于某一个样本 x i x_i xi的损失函数为
L i = − ∑ j y j l o g ( p j ) L_i = -\sum_j y_jlog(p_j) Li=−j∑yjlog(pj) - 以下所有的公式为了便于表达,设定只有一个样品,即 L i L_i Li全部写做 L L L.
- 公式中没有进行偏移,实际算法为了避免指数计算容易越界,需要另做偏移处理)
- 假设类别总数是C,那么网络输出结果有C个概率值,对应one-hot向量有C各元素。我们将它们一一对应求出损失函数 L = ∑ i = 1 C L i L=\sum_{i=1}^C{L_i} L=∑i=1CLi。但是在求解梯度时,是对矢量求解梯度,因此对每一个 L i L_i Li,要分别对 f j f_j fj求解梯度。
∂ p i ∂ f j = ∂ e f i ∑ k e f k ∂ f j \frac{\partial p_{i}}{\partial f_{j}}=\frac{\partial \frac{e^{f_{i}}}{\sum_{k} e^{f_{k}}}}{\partial f_{j}} ∂fj∂pi=∂fj∂∑kefkefi
令 g i = e f i g_i=e^{f_i} gi=efi, h i = ∑ k e f k h_i=\sum_k{e^{f_k}} hi=∑kefk,
∂ p i ∂ f j = ∂ g i h i ∂ f j = g i ′ ( f j ) h i ( f j ) − h i ′ ( f j ) g i ( f j ) h i 2 ( f j ) \frac{\partial p_{i}}{\partial f_{j}} = \frac{\partial \frac{g_i}{h_i}}{\partial f_{j}}=\frac{g_i^{\prime}(f_j) h_i(f_j)-h_i^{\prime}(f_j) g_i(f_j)}{h^{2}_i(f_j)} ∂fj∂pi=∂fj∂higi=hi2(fj)gi′(fj)hi(fj)−hi′(fj)gi(fj)
∂ g i ∂ f j = { if i = j e f i if i ≠ j 0 \frac{\partial g_{i}}{\partial f_{j}}= \begin{cases}\text { if } i=j & e^{f_{i}} \\ \text { if } i \neq j & 0\end{cases} ∂fj∂gi={ if i=j if i=jefi0
∂ h i ∂ f j = e f j , for all \frac{\partial h_{i}}{\partial f_{j}}=e^{f_{j}}, \text { for } \text { all } ∂fj∂hi=efj, for all
最终
∂ p i ∂ f j = ∂ g i h i ∂ f j = { if i = j , e f i ∑ − e f j e f i ∑ 2 = e f i ∑ ∑ − e f j ∑ = p i ( 1 − p j ) if i ≠ j , 0 − e f j f i Σ 2 = − e f j ∑ e f i Σ = − p j p i \frac{\partial p_{i}}{\partial f_{j}} = \frac{\partial \frac{g_i}{h_i}}{\partial f_{j}}=\begin{cases}\text { if } i=j, & \frac{e^{f_{i}} \sum-e^{f_{j} e f_{i}}}{\sum^{2}}=\frac{e^{f_{i}}}{\sum} \frac{\sum-e^{f_{j}}}{\sum}=p_{i}\left(1-p_{j}\right) \\ \text { if } i \neq j, & \frac{0-e^{f_{j} f_{i}}}{\Sigma^{2}}=-\frac{e^{f_{j}}}{\sum} \frac{e f_{i}}{\Sigma}=-p_{j} p_{i}\end{cases} ∂fj∂pi=∂fj∂higi=⎩⎨⎧ if i=j, if i=j,∑2efi∑−efjefi=∑efi∑∑−efj=pi(1−pj)Σ20−efjfi=−∑efjΣefi=−pjpi
∂ L ∂ f j = ∂ L ∂ p k ∂ p k ∂ f j = − ∑ k y k 1 p k ∂ p k ∂ f j = − y j ( 1 − p j ) − ∑ k ≠ j y k 1 p k ( − p k p j ) = − y j ( 1 − p j ) + ∑ k ≠ i y k p j = − y j + y j p j + ∑ k ≠ j y k p j = p j ( ∑ k y k ) − y j = p j − y j \begin{aligned} & \frac{\partial L}{\partial f_{j}} =\frac{\partial L}{\partial p_{k}} \frac{\partial p_{k}}{\partial f_{j}} =-\sum_{k} y_{k} \frac{1}{p_{k}} \frac{\partial p_{k}}{\partial f_{j}} \\ =&-y_{j}\left(1-p_{j}\right)-\sum_{k \neq j} y_{k} \frac{1}{p_{k}}\left(-p_{k} p_{j}\right) \\ =&-y_{j}\left(1-p_{j}\right)+\sum_{k \neq i} y_{k} p_{j} \\ =&-y_{j}+y_{j} p_{j}+\sum_{k \neq j} y_{k} p_{j} \\ =& p_{j}\left(\sum_{k} y_{k}\right)-y_{j}=p_{j}-y_{j} \end{aligned} ====∂fj∂L=∂pk∂L∂fj∂pk=−k∑ykpk1∂fj∂pk−yj(1−pj)−k=j∑ykpk1(−pkpj)−yj(1−pj)+k=i∑ykpj−yj+yjpj+k=j∑ykpjpj(k∑yk)−yj=pj−yj
∂ L ∂ W i = ∂ L ∂ f i ∂ f i ∂ W i = ( p i − y i ) x \frac{\partial L}{\partial W_{i}}=\frac{\partial L}{\partial f_{i}} \frac{\partial f_{i}}{\partial W_{i}}=\left(p_{i}-y_{i}\right) x ∂Wi∂L=∂fi∂L∂Wi∂fi=(pi−yi)x
2. 骨干网络模型
2.1 VGGNet
- 每次经过池化层(maxpool) 后特征图的尺寸减小一倍, 而通道数则增加一倍(最后一个池化层除外)
- 使用的卷积核基本都是3×3,与AlexNet相比参数量更少,两个3×3卷积核的非线性能力要比5×5卷积核强, 因为其拥有两个激活函数, 可大大提高卷积网络的学习能力。
2.2 Inception v1
- Inception v1网络是一个精心设计的22层卷积网络, 并提出了具有良好局部特征结构的Inception模块, 即对特征并行地执行多个大小不同的卷积运算与池化, 最后再拼接到一起。 由于1×1、 3×3和5×5的卷积运算对应不同的特征图区域, 因此这样做的好处是可以得到更好的图像表征信息。

2.3 Inception v2
- Inception v2利用两个级联的3×3卷积取代了Inception v1版本中的5×5卷积;通过卷积分解与正则化实现更高效的计算, 增加了BN层。

2.4 ResNet
- 背景:随着网络的加深, 网络却越发难以训练, 一方面会产生梯度消失现象; 另一方面越深的网络返回的梯度相关性会越来越差,接近于白噪声, 导致梯度更新也接近于随机扰动。
- 通过引入一个shortcut(捷径)分支,将需要拟合的映射变为残差F(x):H(x)-x。ResNet给出的假设是:相较于直接优化潜在映射H(x),优化残差映射F(x)是更为容易的。

2.5 DenseNet
- 网络由多个Dense Block与中间
的卷积池化组成, 核心就在Dense Block中。 Dense Block中的黑点代表一个卷积层, 其中的多条黑线代表数据的流动, 每一层的输入由前面的所有卷积层的输出组成。 注意这里使用了通道拼接(Concatnate) 操作, 而非ResNet的逐元素相加操作。

2.6 特征金字塔:FPN

3. 轻量化网络模型

- 轻量化设计: 从模型设计时就采用一些轻量化的思想, 例如采用深度可分离卷积、 分组卷积等轻量卷积方式, 减少卷积过程的计算量。此外,利用全局池化来取代全连接层,利用1×1卷积实现特征的通道降维,也可以降低模型的计算量, 这两点在众多网络中已经得到了应用。
- BN层合并:在训练检测模型时,BN层可以有效加速收敛,并在一定程度上防止模型的过拟合,但在前向测试时,BN层的存在也增加了多余的计算量。由于测试时BN层的参数已经固定,因此可以在测试时将BN层的计算合并到卷积层,从而减少计算量,实现模型加速。
- 网络剪枝:在卷积网络成千上万的权重中, 存在着大量接近于0的参数, 这些属于冗余参数, 去掉后模型也可以基本达到相同的表达能力, 因此有众多学者以此为出发点, 搜索网络中的冗余卷积核, 将网络稀疏化, 称之为网络剪枝。 具体来讲, 网络剪枝有训练中稀疏与训练后剪枝两种方法。
- 权重量化: 是指将网络中高精度的参数量化为低精度的参数, 从而加速计算的方法。 高精度的模型参数拥有更大的动态变化范围, 能够表达更丰富的参数空间, 因此在训练中通常使用32位浮点数(单精度)作为网络参数的模型。 训练完成后为了减小模型大小, 通常可以将32位浮点数量化为16位浮点数的半精度, 甚至是int8的整型、 0与1的二值类型。 典型方法如Deep Compression。
- 张量分解: 由于原始网络参数中存在大量的冗余, 除了剪枝的方法以外, 我们还可以利用SVD分解和PQ分解等方法, 将原始张量分解为低秩的若干张量, 以减少卷积的计算量, 提升前向速度。
- 知识蒸馏: 通常来讲, 大的模型拥有更强的拟合与泛化能力, 而小模型的拟合能力较弱, 并且容易出现过拟合。 因此, 我们可以使用大的模型指导小模型的训练, 保留大模型的有效信息, 实现知识的蒸馏。
3.1 SqueezeNet
SqueezeNet, 其性能与AlexNet相近, 而模型参数仅有AlexNet的1/50。
使用了如下3点策略来减少网络参数, 提升网络性能:
- 使用1×1卷积来替代部分的3×3卷积,这也是之前介绍过的常用的策略,可以将参数减少为原来的1/9。
- 减少输入通道的数量,这一点也是通过1×1卷积来实现,通道数量的减少可以使后续卷积核的数量也相应地减少。
- 在减少通道数之后,使用多个尺寸的卷积核进行计算,以保留更多的信息, 提升分类的准确率。
SqueezeNet提出了如下图所示的基础模块, 称之为Fire Module。
如图所示:

SqueezeNet整体结构:
SqueezeNet一共使用了3个Pool层,前两个是Max Pooling层,步长为2,最后一个为全局平均池化,利用该层可以取代全连接层,减少了计算量。

3.2 深度可分离MobileNet
度可分离卷积将卷积过程分为了两步,凭借其轻量的卷积方式,总体计算量约等于标准卷积的1/9。
3.2.1 MobileNet v1
MobileNet v1使用的深度可分离模块的具体结构如图所示。 其中使用了BN层及ReLU的激活函数。 值得注意的是, 在此使用了ReLU6来替代原始的ReLU激活函数, 将ReLU的最大输出限制在6以下。

使用ReLU6的原因主要是为了满足移动端部署的需求。 移动端通常使用Float16或者Int8等较低精度的模型, 如果不对激活函数的输出进行限制的话, 激活值的分布范围会很大, 而低精度的模型很难精确地覆盖如此大范围的输出, 这样会带来精度的损失。
在基本的结构之外, MobileNet v1还设置了两个超参数, 用来控制模型的大小与计算量, 具体如下:
- 宽度乘子: 用于控制特征图的通道数, 记做α, 当α<1时, 模型会变得更薄, 可以将计算量减少为原来的α2。
- 分辨率乘子: 用于控制特征图的尺寸, 记做ρ, 在相应的特征图上应用该乘子, 也可以有效降低每一层的计算量。
MobileNet v1也有其自身结构带来的缺陷, 主要有以下两点:
- 模型结构较为复古, 采用了与VGGNet类似的卷积简单堆叠, 没有采用残差、 特征融合等先进的结构。
- 深度分解卷积中各通道相互独立, 卷积核维度较小, 输出特征中只有较少的输入特征, 再加上ReLU激活函数, 使得输出很容易变为0,难以恢复正常训练, 因此在训练时部分卷积核容易被训练废掉。
3.2.2 MobileNet v2
(1)Inverted Residual Block结构
- 由于3×3卷积处的计算量较大, 因此传统的残差网络通常先使用1×1卷积进行特征降维, 减少通道数, 再送入3×3卷积, 最后再利用1×1卷积升维。 这种结构从形状上看中间窄两边宽, 类似于沙漏形状。
- 然而在MobileNet v2中, 由于使用了深度可分离卷积来逐通道计算, 本身计算量就比较少, 因此在此可以使用1×1卷积来升维, 在计算量增加不大的基础上获取更好的效果, 最后再用1×1卷积降维。 这种结构中间宽两边窄, 类似于柳叶, 该结构也因此被称为Inverted Residual Block。
(2)去掉ReLU6
- 深度可分离卷积得到的特征对应于低维空间, 特征较少, 如果后续接线性映射则能够保留大部分特征, 而如果接非线性映射如ReLU, 则会破坏特征, 造成特征的损耗, 从而使得模型效果变差。
- MobileNet v2直接去掉了每一个Block中最后的ReLU6层, 减少了特征的损耗, 获得了更好的检测效果。

3.2.3 MobileNet v3
- 作者发现,计算资源耗费最多的层是网络的输入和输出层,因此作者对这两部分进行了改进。
- 由于嵌入式设备计算sigmoid是会耗费相当大的计算资源的,因此作者提出了h-switch作为激活函数。且随着网络的加深,非线性激活函数的成本也会随之减少。所以,只有在较深的层使用h-switch才能获得更大的优势。
- 在v2的block上引入SE模块,SE模块是一种轻量级的通道注意力模块。
- 利用NAS(神经结构搜索)来搜索网络的配置和参数。
3.3 通道混洗ShuffleNet
2017年的ShuffleNet v1从优化网络结构的角度出发, 利用组卷积与通道混洗(Channel Shuffle) 的操作有效降低了1×1逐点卷积的计算量,是一个极为高效的轻量化网络。 而2018年的ShuffleNet v2则在ShuffleNetv1版本的基础上实现了更为优越的性能, 本节将详细介绍这两个ShuffleNet网络的思想与结构。
3.3.1 通道混洗
逐点的1×1卷积有如下两点特性:
- 可以促进通道之间信息的融合, 改变通道至指定维度。
- 轻量化网络中1×1卷积占据了大量的计算, 并且致使通道之间充满约束, 一定程度上降低了模型的精度。
为了进一步降低计算量,ShuffleNet提出了通道混洗的操作, 通过通道混洗也可以完成通道之间信息的融合。
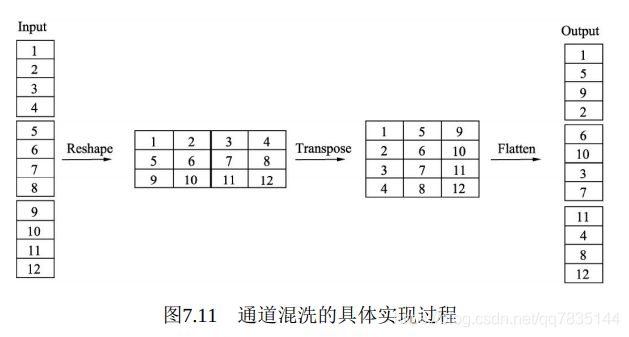
3.3.2 ShuffleNet v1
shuffleNet v1的基本结构:

其中DWConv表示深度可分离卷积;GConv表示分组卷积。
3.3.3 ShuffleNet v2
ShuffleNet v2做了大量的实验, 分析影响网络运行速度的原因, 提出了建立高性能网络的4个基本规则:
(1) 卷积层的输入特征与输出特征通道数相等时, 内存访问时间(Memory Access Cost, MAC) 最小, 此时模型速度最快。
(2) 过多的组卷积会增加MAC, 导致模型的速度变慢。
(3) 网络的碎片化会降低可并行度, 这表明模型中分支数量越少, 模型速度会越快。
(4) 逐元素(Element Wise) 操作虽然FLOPs值较低, 但其MAC较高, 因此也应当尽可能减少逐元素操作。
以这4个规则为基础, 可以看出ShuffleNet v1有3点违反了此规则:
- 在Bottleneck中使用了1×1组卷积与1×1的逐点卷积, 导致输入输出通道数不同, 违背了规则1与规则2。
- 整体网络中使用了大量的组卷积, 造成了太多的分组, 违背了规则3。
- 网络中存在大量的逐点相加操作, 违背了规则4。
4. 注意力机制
https://blog.csdn.net/qq_35975753/article/details/108801408
https://blog.csdn.net/weixin_43578873/article/details/104517029
注意力机制(attention)的基本思想就是想让系统学会注意力——能够忽略无关信息而关注重点信息。注意力机制一种是软注意力(soft attention),另一种则是强注意力(hard attention)。
- 软注意力的关键点在于,这种注意力更关注区域或者通道,而且软注意力是确定性的注意力,学习完成后直接可以通过网络生成,最关键的地方是软注意力是可微的,这是一个非常重要的地方。可以微分的注意力就可以通过神经网络算出梯度并且前向传播和后向反馈来学习得到注意力的权重。
- 强注意力与软注意力不同点在于,首先强注意力是更加关注点,也就是图像中的每个点都有可能延伸出注意力,同时强注意力是一个随机的预测过程,更强调动态变化。当然,最关键是强注意力是一个不可微的注意力,训练过程往往是通过增强学习(reinforcement learning)来完成的。
4.1 Convolutional Block Attention Module(CBAM)
4.1.1 通道注意力机制

分别对特征图进行全局最大池化和全局平均池化,然后分别将这两个特征向量输入同一个MLP网络中,最后将得到的两个结果逐点相加并进行sigmoid归一化。
4.1.2 空间注意力机制
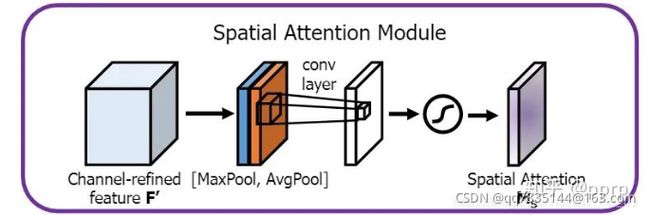
对特征图分别进行局部最大池化和局部平均池化,并缩减输出通道数。将这两个输出结果沿通道数进行拼接,然后经过一个卷积层并进行sigmoid归一化。
4.1.3 CBAM

CBAM模块就是把通道注意力机制和空间注意力机制串联起来。需要注意的是通道注意力机制和空间注意力机制都是范围0-1的,都是扮演加权系数的角色。只是一个通道加权,一个给空间加权。
4.2 self-attention

Self-attention结构自上而下分为三个分支,分别是query、key和value。计算时通常分为三步:
第一步是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等;
第二步一般是使用一个softmax函数对这些权重进行归一化;
第三步将权重和相应的键值value进行加权求和得到最后的attention。
4.3 Non-local
卷积操作和递归操作都是构建块,一次处理一个局部邻居,在此文中,作者将非局部操作作为捕获远程依赖项的构建块的一个通用族来表示。受传统算法非局部均值启发,非局部操作用所有位置特征的加权来作为一个位置的响应。

5. 其他
https://blog.csdn.net/qq_39056987/article/details/112104199
https://mp.weixin.qq.com/s/Y2e1JF8qrA5TaNlMk8fFJA
https://mp.weixin.qq.com/s/Ml9MrdbgxRZAnLYxIrev4Q
https://github.com/amusi/Deep-Learning-Interview-Book/blob/master/docs/%E8%AE%A1%E7%AE%97%E6%9C%BA%E8%A7%86%E8%A7%89.md
https://github.com/GYee/CV_interviews_Q-A
https://github.com/amusi/Deep-Learning-Interview-Book/blob/master/docs/%E8%AE%A1%E7%AE%97%E6%9C%BA%E8%A7%86%E8%A7%89.md