【嵌入式AI部署】轻量化神经网络精述--MobileNet V1-3、ShuffleNet V1-2、NasNet
原文链接:
【嵌入式AI部署&基础网络篇】轻量化神经网络精述--MobileNet V1-3、ShuffleNet V1-2、NasNet
深度神经网络模型被广泛应用在图像分类、物体检测等机器视觉任务中,并取得了巨大成功。然而,由于存储空间和功耗的限制,神经网络模型在嵌入式设备上的存储与计算仍然是一个巨大的挑战。
前面几篇介绍了如何在嵌入式AI芯片上部署神经网络:
【嵌入式AI开发】篇五|实战篇一:STM32cubeIDE上部署神经网络之pytorch搭建指纹识别模型.onnx
在移动端部署深度卷积网络,无论什么视觉任务,选择高精度的计算量少和参数少的骨干网是必经之路。因此,本篇主要跟大家一起简单回顾下轻量化网络的发展历程,把握轻量化网络的发展方向,以更好选择和设计轻量化网络进行移动端部署。
目前的一些主要的轻量化网络及特点如下:
-
MobileNet V1--2017:提出深度可分离卷积;
-
MobileNet V2--2018:提出反转残差线性瓶颈块;
-
MobileNet V3--2019:高效的网络构建模块与互补搜索技术组合;
-
ShuffleNet V1-2017:结合使用分组卷积和通道混洗操作;
-
ShuffleNet V2--2018:高效网络设计的四个准则;
-
NasNet--2017:神经网络结构搜索;
以下按时间顺序一一精述各类轻量化网络的核心,更多细节请参考原论文。
1. NasNet--2017
论文介绍:
《Learning Transferable Architectures for Scalable Image Recognition》
来自Google Brain的一篇著作,是基于前一篇NAS–Neural Architecture Search With Reinforcement Learning 的改进,使得能让机器在小数据集(CIFAR-10数据集)上自动设计出CNN网络,并利用迁移学习技术使得设计的网络能够被很好的迁移到大数据集(ImageNet数据集),同时也可以迁移到其他的计算机视觉任务上(如目标检测)。
论文地址:
https://arxiv.org/pdf/1707.07012.pdf
代码:
https://github.com/tensorflow/models/tree/master/research/slim/nets/nasnet
主要核心点介绍:
(1)延续NAS论文的核心机制使得能够自动产生网络结构;
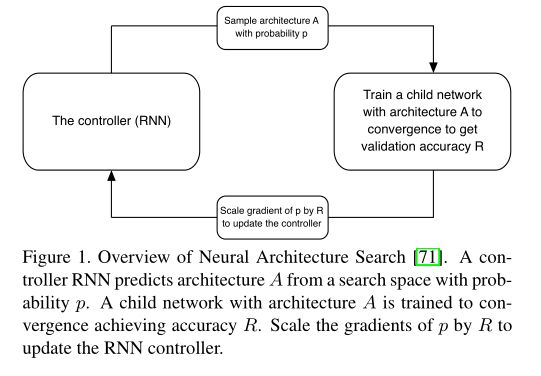
如上图所示,简而言之就是使用RNN来生成网络结构,然后在数据集上进行训练,根据收敛后的准确率对RNN进行权重调整。
(2)采用resnet和Inception重复使用block结构思想;

如上图所示,NASNet 仅对模型的整体结构进行了设置,具体的模块或神经元并未预定义,而是通过强化学习搜索方法完成的。如序列重复的次数 N 和初始的卷积核形状都是自由参数,用于模型的缩放。
此外, 类似resnet和inception一样,进行基本block的堆叠生成最终网络。因此搜索最优网络的时候,只搜索最优block。这样的好处,1)可以极大的加快搜索速度2)基础block对其他分类,检测问题都具有很好的泛化能力。
(3)设计了新的搜索空间,即NASNet search space,并在实验中搜索得到最优的网络结构NASNet;
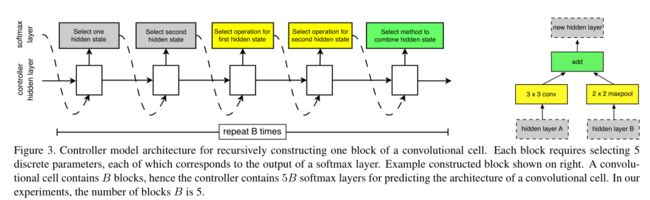
该部分是论文的核心所在,如上图所示,每个网络单元由 B块 的网络块(block)组成,在实验中 B=5 。每个块的具体形式如图右侧部分,每个块有并行的两个卷积组成,它们会由控制器决定选择哪些Feature Map作为输入(灰色部分)以及使用哪些运算(黄色部分)来计算输入的Feature Map。最后它们会由控制器决定如何合并这两个Feature Map。在 NASNet 中,由 RNN 构成的控制器使用两个初始的隐藏状态,迭代地对余下的卷积神经元的结构进行预测。具体步骤是:
Step1:从hidden states(前面block中产生的)中选择一个hidden state—hi-1作为输入;
Step2:重复step的操作,选择一个hidden state—hi;
Step3:为step1中选择的hidden state选择一个操作;
Step4:为step2中选择的hidden state选择一个操作;
Step5:选择一个方法去连接step3和step4中的输出从而产生一个new hidden state,并将其添加到hidden states中。
其中,步骤3和步骤4可选的运算包括:

最终得到了多个候选的卷积神经元,最终形成了三种不同结构的Normal cell和reduction cell,包括NASNet-A, NASNet-B和NASNet-C。
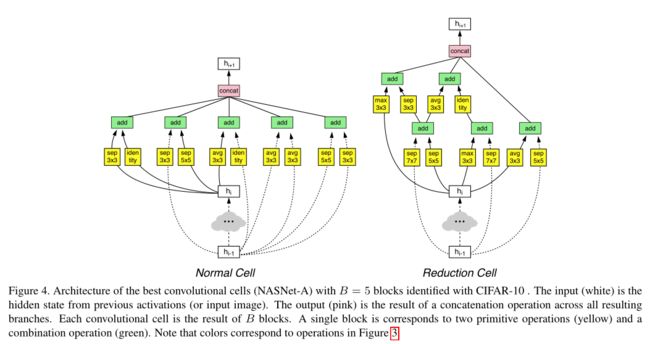
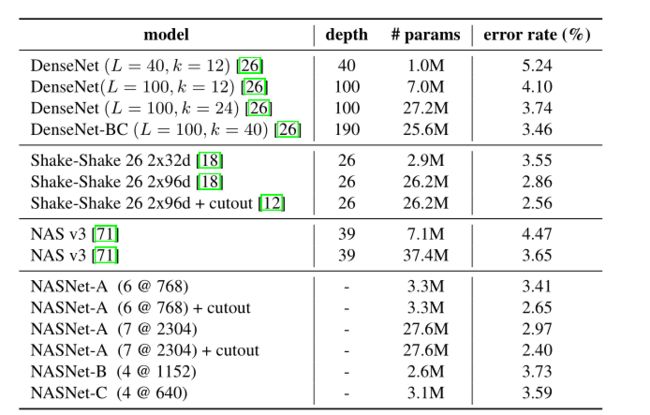
结果分析:
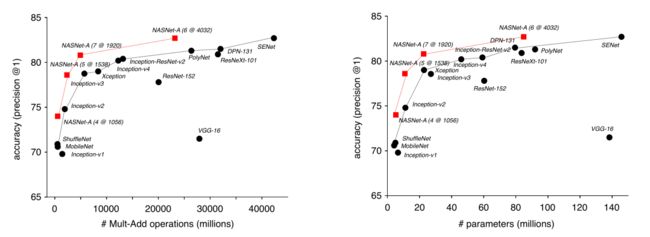
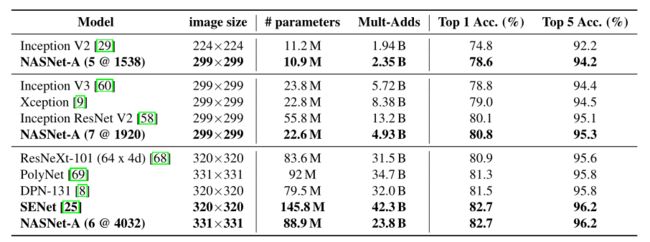
2. ShuffleNet V1--2017
论文:
《ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices 》
ShuffleNet是Face++的一篇关于降低深度网络计算量的论文,主要针对在移动设备上的部署。结合了MobileNet、Xception和ResNeXt的思想。组卷积操作从AlexNet就已经有了,当时主要是解决模型在双GPU上的训练。ResNeXt借鉴了这种group操作改进了原本的ResNet。MobileNet则是采用了depthwise separable convolution代替传统的卷积操作,在几乎不影响准确率的前提下大大降低计算量。Xception主要也是采用depthwise separable convolution改进Inception v3的结构。而文章主要采用channel shuffle、pointwise group convolutions和depthwise separable convolution来修改原来的ResNet单元。
地址:
https://arxiv.org/abs/1707.01083
代码:
https://github.com/megvii-model/ShuffleNet-Series
主要核心点介绍:
(1)Channel Shuffle for Group Convolutions

组卷积可以降低计算量,但是组卷积有个问题(如图a),那就是不同组的通道间没有信息交换。channel shuffle的作用就是打乱通道顺序,让不同的组间进行信息交换。上图b和c是两种等价的画法。
(2)ShuffleNet Unit
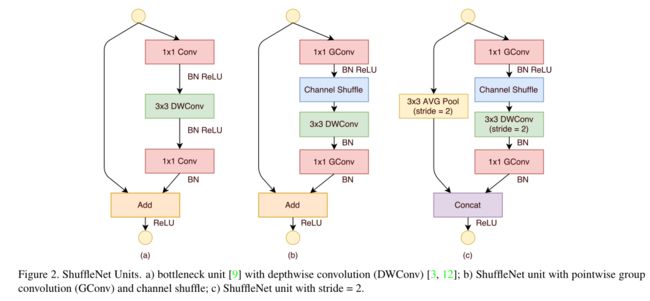
ShuffleNet的核心是采用了两种操作:pointwise group convolution和channel shuffle,这在保持精度的同时大大降低了模型的计算量。其基本单元则是在一个残差单元的基础上改进而成。
上图a是基本ResNet轻量级结构,这是一个包含3层的残差单元:首先是1x1卷积,然后是3x3的depthwise convolution(DWConv,主要是为了降低计算量),这里的3x3卷积是瓶颈层(bottleneck),紧接着是1x1卷积,最后是一个短路连接,将输入直接加到输出上。
b为一个标准的shuffle unit:将密集的1x1卷积替换成1x1的group convolution,不过在第一个1x1卷积之后增加了一个channel shuffle操作。值得注意的是3x3卷积后面没有增加channel shuffle,按论文的意思,对于这样一个残差单元,一个channel shuffle操作是足够了。还有就是3x3的depthwise convolution之后没有使用ReLU激活函数。
c中为步长为2的shuffle unit,可用于降采样:对原输入采用stride=2的3x3 avg pool,在depthwise convolution卷积处取stride=2保证两个通路shape相同,然后将得到特征图与输出进行concat,而不是相加。降低了计算量与参数大小。
结果分析:
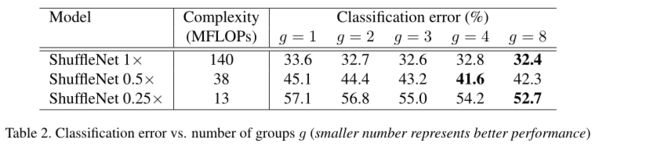
3. ShuffleNet V2--2018
论文:《ShuffleNet V2: Practical Guidelines for EfficientCNN Architecture Design》
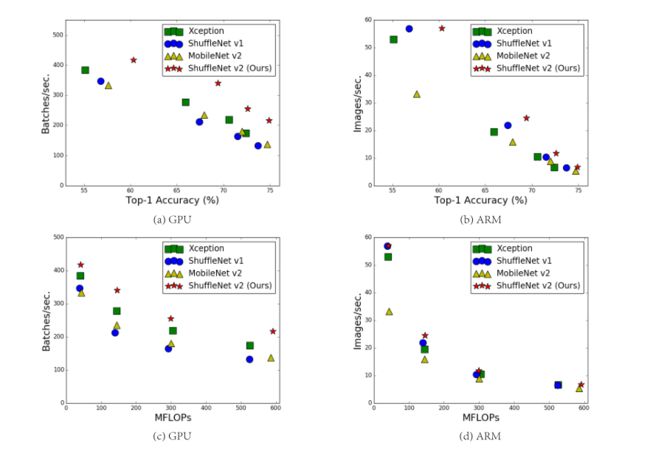
论文中提出FLOPs不能作为衡量目标检测模型运行速度的标准,因为MAC(Memory access cost)也是影响模型运行速度的一大因素。另外模型的并行程度也影响速度,并行度高的模型速度相对更快。提出模型在不同平台上的运行速度是有差异的,如GPU和ARM,而且采用不同的库也会有影响。在同等复杂度下,ShuffleNetv2比ShuffleNet和MobileNetv2更准确,但用的还是MobileNetv2多。
地址:
https://arxiv.org/abs/1807.11164
代码:
https://github.com/megvii-model/ShuffleNet-Series
主要核心点介绍:

作者在不同平台下研究了ShuffleNetv1和MobileNetv2的运行时间,并结合理论与实验得到了4条实用的指导原则:
(G1)同等通道大小最小化内存访问量
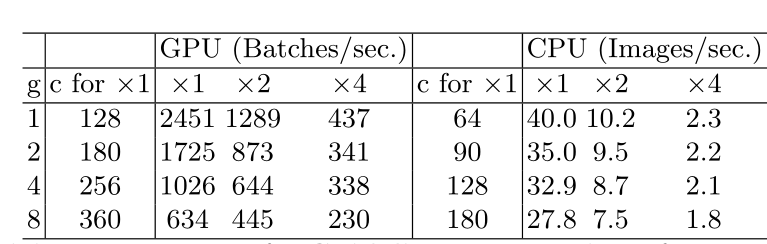
网络通常采用深度可分离卷积,其中点卷积(即1×1卷积)占大部分复杂性。我们研究了1×1卷积的核形状。该形状由两个参数指定:输入通道C1和输出通道c2的数量。设h和w为特征映射的空间大小,1×1卷积的触发器为B=hw*c1*c2。对应的MAC为:
![]()
根据均值不等式,固定 B 时,MAC存在下限:

仅当 C1=C2 时,MAC取最小值,这个理论分析也通过实验得到证实,如下表所示,通道比为1:1时速度更快。
(G2)过量使用组卷积会增加MAC
通过公式转换可以得出:
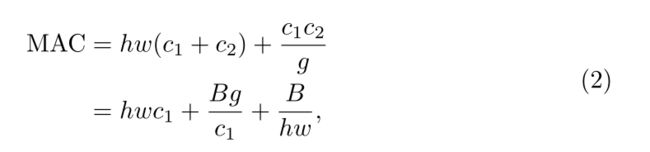
当FLOPs、通道数、特征图不变时,组数g的增加,会增加MAC。
(G3)分支数量过少,模型速度越快

(G4)element-wise操作导致速度的消耗,远比FLOPs上体现的多

对于元素级(element-wise operators)比如ReLU和Add,虽然它们的FLOPs较小,但是却需要较大的MAC。这里实验发现如果将ResNet中残差单元中的ReLU和shortcut移除的话,速度有20%的提升。
根据前面的4条准则,作者分析了ShuffleNetv1设计的不足,并在此基础上改进得到了ShuffleNetv2,如下图所示:

结果分析:


4. MobileNet V1--2017
论文:
《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
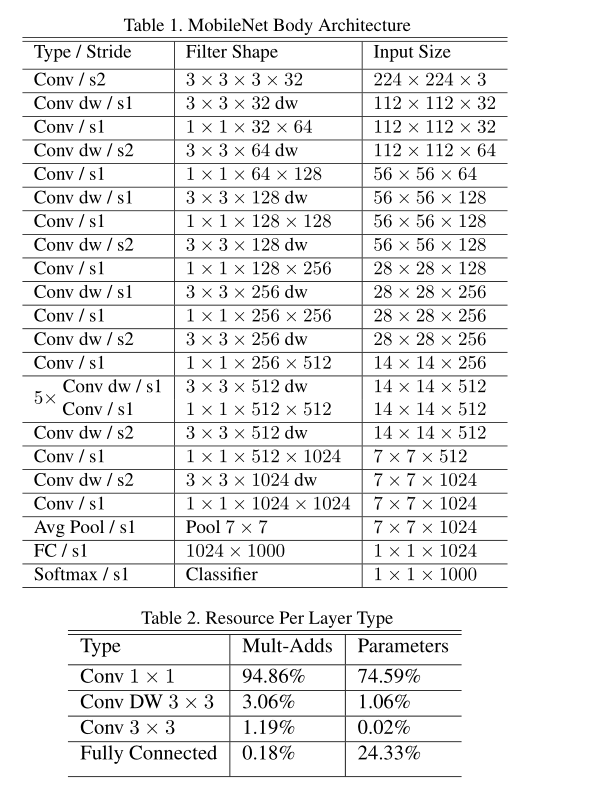
mobilenet 利用分组卷积降低网络的计算量,将分组卷积应用到极致。组卷积网络的分组数与网络的channel数量相等,使网络的计算量减到最低,但是这样channel之间的交互就没有了,所以作者使用的point-wise conv,即使用1x1的卷积进行channel之间的融合。采用depth-wise separable convolutions以达到模型压缩(inspired by inception、Xception),广泛应用于目标检测、细粒度分类、人脸属性和大规模地理定位等领域。

地址:
https://arxiv.org/pdf/1704.04861.pdf
代码:
https://github.com/Zehaos/MobileNet
主要核心点介绍:深度可分离卷积

左:带batchnorm和ReLU的标准卷积层。右图:深度可分离卷积,深度层和点层后跟batchnorm和ReLU。
通俗的来说,深度可分离卷积干的活是:把标准卷积分解成深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)。这么做的好处是可以大幅度降低参数量和计算量。分解过程示意图如下:

结果分析:

5. MobileNet V2--2018
论文:
《MobileNetV2: Inverted Residuals and Linear Bottlenecks》
MobileNet V1设计时参考传统的VGGNet等链式架构,以层叠卷积层的方式提高网络深度,从而提高识别精度。但层叠过多的卷积层会出现一个问题,就是梯度弥散(Vanishing)。MobileNet V2基的改进,主要解决了V1在训练过程中非常容易梯度弥散(Vanishing)的问题,V2相比V1效果有一定提升,是目前应用得较为广泛的网络之一。
地址:
https://arxiv.org/pdf/1801.04381.pdf
代码:
https://github.com/d-li14/mobilenetv2.pytorch
主要核心点介绍:V2相对V1有以下改进
(1)借鉴ResNet的思想增加skip connection
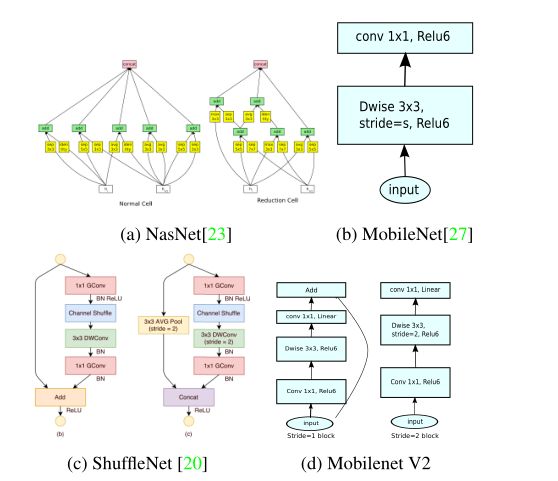
(2)采用Inverted residual block结构
DWConv layer提取得到的特征受限于输入的通道数,若是采用以往的residual block,先“压缩”,再卷积提特征,那么DWConv layer可提取得特征就太少了。因此MobileNetV2反其道而行,一开始先“扩张”,本文实验“扩张”倍数为6。通常residual block里面是 “压缩”→“卷积提特征”→“扩张”,MobileNetV2就变成了 “扩张”→“卷积提特征”→ “压缩”,因此称为Inverted residuals.

(3)去掉building block最后面1x1之后的ReLu6,用Linear代替
当采用“扩张”→“卷积提特征”→ “压缩”时,在“压缩”之后会碰到一个问题,那就是Relu会破坏特征。为什么这里的Relu会破坏特征呢?这得从Relu的性质说起,Relu对于负的输入,输出全为零;而本来特征就已经被“压缩”,再经过Relu的话,又要“损失”一部分特征,因此这里不采用Relu,实验结果表明这样做是正确的,这就称为Linear bottlenecks.
最后的网络结构为:

结果分析:


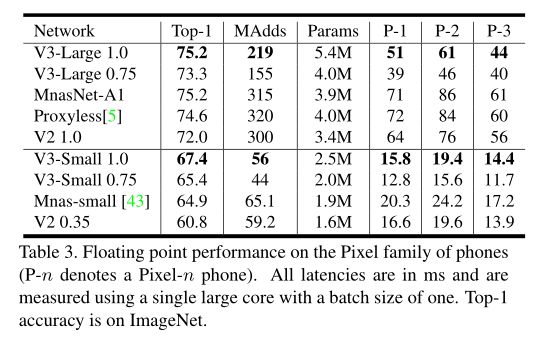
6. MobileNet V3--2019
论文:《Searching for MobileNetV3》
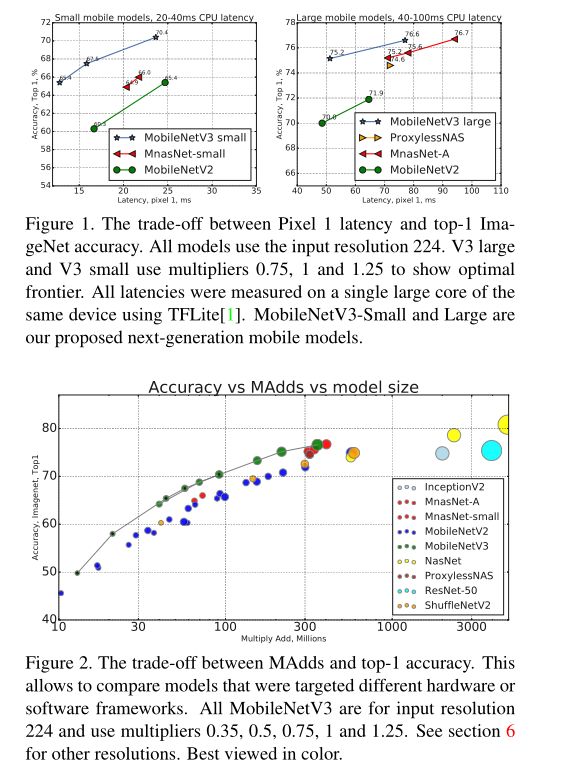
mobilenet-v3是Google继mobilenet-v2之后的又一力作,MobileNetV3 有两个版本,MobileNetV3-Small 与 MobileNetV3-Large 分别对应对计算和存储要求低和高的版本。论文中提到,mobilenet-v3 small在imagenet分类任务上,较mobilenet-v2,精度提高了大约3.2%,时间却减少了15%,mobilenet-v3 large在imagenet分类任务上,较mobilenet-v2,精度提高了大约4.6%,时间减少了5%,mobilenet-v3 large 与v2相比,在COCO上达到相同的精度,速度快了25%,同时在分割算法上也有一定的提高。
地址:
https://arxiv.org/abs/1905.02244
代码:
https://github.com/xiaolai-sqlai/mobilenetv3
主要核心点介绍:整体来说MobileNetV3有三大创新点
(1)引入SE注意力
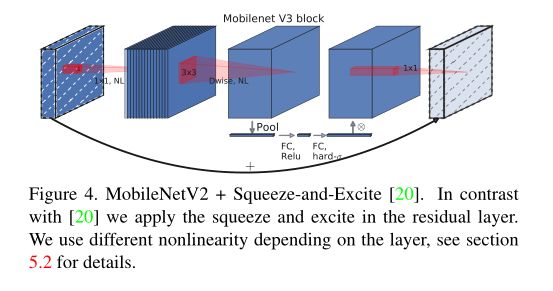
在bottlenet结构中加入了SE结构,并且放在了depthwise filter之后,如上图。因为SE结构会消耗一定的时间,所以作者在含有SE的结构中,将expansion layer的channel变为原来的1/4,这样即提高了精度,同时还没有增加时间消耗。并且SE结构放在了depthwise之后。
(2)互补搜索技术组合:由资源受限的NAS执行模块级搜索,NetAdapt执行局部搜索。
在网络结构搜索中,作者结合两种技术:资源受限的NAS(platform-aware NAS)与NetAdapt,前者用于在计算和参数量受限的前提下搜索网络的各个模块,所以称之为模块级的搜索(Block-wise Search) ,后者用于对各个模块确定之后网络层的微调。详细可参考论文:
Mnasnet: Platform-aware neural architecture search for mobile.
Netadapt: Platform-aware neural network adaptation for mobile applications.
最近提出的MCUNet就是基于这种算法:
【嵌入式AI开发】MCUNet: Tiny Deep Learning on IoT Devices-微型机器学习时代已经到来了
(3)网络结构改进:将最后一步的平均池化层前移并移除最后一个卷积层,引入h-swish激活函数。

在mobilenetv2中,bottlenet结构存中使用个1x1的卷积层来提高特征维度,但这会带来一定的计算量。所以mobilenetv3将其放在avg pooling的后面,首先利用avg pooling将特征图大小由7x7降到了1x1,降到1x1后,然后再利用1x1提高维度,这样就减少了7x7=49倍的计算量。除此之外,作者直接去掉了前面纺锤型卷积的3x3以及1x1卷积,进一步减少了计算量如上图所示。
另外,作者发现一种新出的激活函数swish x 能有效改进网络精度:
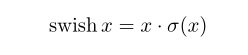
但就是计算量太大了,于是作者对这个函数进行了数值近似:

事实证明,这个近似很有效:

结果分析:
7. 更多精彩内容推荐
嵌入式AI部署的系列教程,关注公众号“AI研修 潜水摸大鱼”获取最新资讯。
【嵌入式AI开发】篇四|部署篇:STM32cubeIDE上部署神经网络之模型部署