yolact模型结构探索
yolact是今年产生的高效率实时实例分割模型,最近试图研究了一下,希望能有更深入了解。
论文地址:https://arxiv.org/abs/1904.02689
源码:https://github.com/dbolya/yolact.git
相关理论
先放一张yolact的结构图:

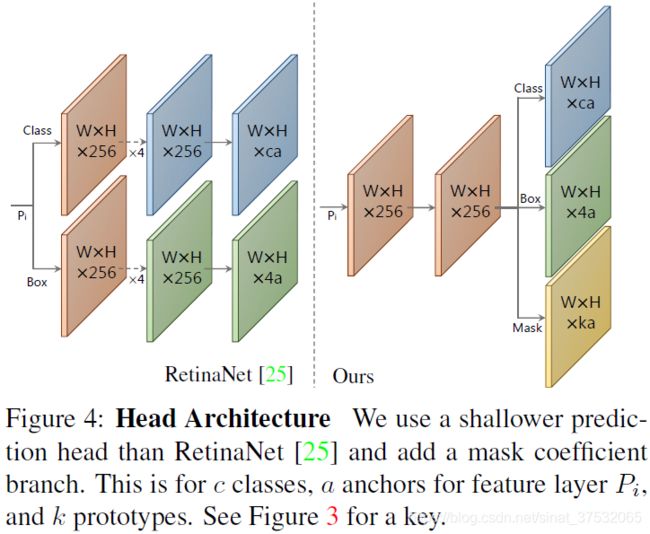
特征提取网络backbone可以采用resnet101,resnet50甚至vgg16等。然后有3个分支,1个分支输出目标位置,1个分支输出mask系数,1个分类的置信率,所以决定目标的有4(位置)+k(mask系数)+c(分类置信率)个参数。
检测的大致步骤为:
1.从backbone中取出C3,C4,C5;
2.通过FPN网络生成P3,P4,P5,通过P5生成P6和P7
3.P3通过Protonet生成k个138*138的proto原型
4.P3~P7通过Prediction Head网络各生成W*H*a(a为anchor数)个位置(4),mask系数(k)以及置信率信息(c):
loc:[None,W*H*a,4]
mask:[None,W*H*a,k]
conf:[None,W*H*a,81]
5.把上面的结果进行FastNMS处理
6.FastNMS的处理结果和Protonet输出的k个138*138的proto原型进行组合运算(叠加,裁切,阈值分割)即可获得最终的检测结果。
Prediction Head的网络结构图(右侧)
protonet是一个卷积网络,最终输出138*138*k的特征图(即proto),下面是一张protonet的的结构图:

关于mask系数,一开始我不是很理解,后来发现mask系数是用于给protonet产生的k个proto进行加权的。不管网络检测出几个目标,protonet都会输出k个138*138的proto,这个很好理解;假设网络检测出8个目标,可以理解为网络会产生8个长度为k的向量,这8个k维向量的k个值分别和k个proto相乘,并再累加,就生成了8个对应的组合结果(即Assmebly),用公式表示如下。
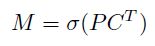
P为poroto(138*138*k),C即某1个目标的mask系数(1*k),M即为该目标的组合结果。
模型试验
模型采用了resnet50的backbone,即yolact_resnet50_54_800000.pth,请自行下载。
1.载入相关模块包
from yolact import Yolact
from utils.augmentations import BaseTransform, FastBaseTransform, Resize
from data import cfg, set_cfg, set_dataset
import numpy as np
import torch
import torch.backends.cudnn as cudnn
from torch.autograd import Variable
import os
import matplotlib.pyplot as plt
import cv2
from pylab import *
import matplotlib.patches as patches
%matplotlib inline2. 定义相关参数
CONFIG='yolact_resnet50_config' #导入yolact模型指定resnet50的backbone
MODEL_PATH='yolact_resnet50_54_800000.pth' #下载下来的预训练模型
PIC_PATH='dogs.jpeg'#测试图片路径
set_cfg(CONFIG) #yolact项目指定的导入config的函数#我们先查看一下这张图
image = plt.imread(PIC_PATH)
plt.imshow(image)
3. 载入模型并预测
#模型推理forward过程
def evalimage(net:Yolact, path:str, save_path:str=None):
'''
net:即yolact网络
path:给定图片路径
savepath:该参数该函数暂时不用
preds:模型正向跑完一张图的结果
'''
frame = torch.from_numpy(cv2.imread(path)).cuda().float()
batch = FastBaseTransform()(frame.unsqueeze(0))
preds = net(batch)
return preds#预测过程,preds即模型计算结果
with torch.no_grad():
cudnn.benchmark = True
cudnn.fastest = True
torch.set_default_tensor_type('torch.cuda.FloatTensor')
net = Yolact()
net.load_weights(MODEL_PATH)
net.eval()
preds=evalimage(net,PIC_PATH)preds就是模型的输出结果,下面让我们看一下模型都输出了些什么!
#查看预测结果
for key in preds[0].keys():
if key=='class'or key=='score':
print(key,':',preds[0][key].shape,'\t',preds[0][key])
else:
print(key,':',preds[0][key].shape)--------------------------------------------------------------------------------------------------------------
mask : torch.Size([8, 32])
proto : torch.Size([138, 138, 32])
score : torch.Size([8]) tensor([0.9464, 0.9457, 0.9455, 0.3396, 0.1167, 0.1127, 0.0791, 0.0610])
class : torch.Size([8]) tensor([16, 16, 16, 21, 21, 18, 16, 21])
box : torch.Size([8, 4])
---------------------------------------------------------------------------------------------------------------
从上面的输出可以发现模型一共输出了5个分支:
1)mask:mask系数,网络检出了8个目标,每个目标都有1个32位的mask系数
2)proto:protonet的输出,这里是138*138*32即32张138*138的特征图
3)score:8个目标的置信率(这里可以看到前3个置信率有百分之94以上)
4)class:8个目标的分类结果(对应的class_id)
5)box:8个目标的位置信息(x_min,y_min,x_max,y_max)
从以上信息我们可以知道网络检测出了8个目标,其中3个处于高置信率(90%)以上。为什么检测出的结果是8个呢?这主要是网络内部对检测结果进行了快速NMS处理,最后筛选合并的结果,关于快速NMS我还没有深入研究。
最后实例分割的实现主要是靠proto,mask,box3个结果进行输出。
4.模型输出展示
1)proto展示(32个)
proto=preds[0]['proto'].cpu().numpy()
plt.figure(figsize=(4*1.38*2,8*1.38*2))#8行4列
for i in range(32):
plt.subplot(8, 4, i + 1)
plt.imshow(proto[:,:,i])
axis('off')
plt.show()
这里可以看见32个特征图的效果,我们可以发现这些有的是加强前景(1排2列,5排3列),有的是加强背景(2排4列,8排4列),有的是加强左边(一二排3列),有的是加强右边(4排3列);yolact所有的mask都是根据这32(k)张特征图进行不同的加权方式产生的。而决定加权方式的就是mask系数。
2)模型输出展示
#模型数据转为numpy格式
box=preds[0]['box'].cpu().numpy()
score=preds[0]['score'].cpu().numpy()
class_id=preds[0]['class'].cpu().numpy()
mask=preds[0]['mask'].cpu().numpy()
##############################
de_num=mask.shape[0]#确定检测到目标的个数
col=4#展示4列
row=(de_num/col+0.5)#展示行数
plt.figure(figsize=(col*1.38*2,row*1.38*2))
for j in range(de_num):
result=proto*np.transpose(mask[j])# proto乘以mask系数
result = 1 / (1 + np.exp(-result))#sigmoid处理
result=np.sum(result,2)#累加
plt.subplot(row,col,j+1)
title='class_id:'+str(class_id[j])+' '+str(score[j])
plt.title(title,color='red',fontsize='large',fontweight='bold')
plt.imshow(result)
axis('off')
#画框处理,从box中读取位置信息
currentAxis=plt.gca()
x_min=int(box[j][0]*138)
y_min=int(box[j][1]*138)
x_max=int(box[j][2]*138)
y_max=int(box[j][3]*138)
rect=patches.Rectangle((x_min, y_min),x_max-x_min,y_max-y_min,linewidth=1,edgecolor='r',facecolor='none')
currentAxis.add_patch(rect)
plt.show()
最终8个目标的位置和protonet的累加结果就可以展示出来,把框内的裁剪出来进行阈值分割即可得到最终的2值mask图。