Deeplab系列:从v1到v3+深入解读
前言
在介绍Deeplab系列前,我们先来学习一下空洞卷积的概念。
在空洞卷积提出以前,大部分上采样都是线性或者双线性插值或者后来的反卷积。前者通常是通过线性或双线性变换进行插值,虽然计算量小,但是效果有时不能满足要求;后者则是通过卷积实现,虽然精度高,但是参数计算量增加了,同时会产生“栅格效应”。有没有能够平衡的办法呢,DeepLab就提出了“空洞卷积”(atrous convolution)的概念。
空洞卷积”(atrous convolution)有什么优点?
概括来讲就是:调整感受野(多尺度信息)的同时控制分辨率
- 让我们能够方便的控制特征分辨率
- 在不增加参数数目或者计算量的同时,有效扩大感受野。
那什么是空洞卷积呢?
这里参考如何理解空洞卷积(dilated convolution)?
dilated/atrous Convolution 从字面上就很好理解,翻译为扩张卷积或空洞卷积,是在标准的 convolution map 里注入空洞,以此来增加 reception field。空洞与普通的卷积相比,除了卷积核的大小以外,还有一个扩张率(dilation rate)参数,主要用来表示扩张的大小。扩张卷积与普通卷积的相同点在于,卷积核的大小是一样的,在神经网络中即参数数量不变,区别在于扩张卷积具有更大的感受野

对于 dilated convolution, 可以发现其优点在于**内部数据结构的保留和避免使用 down-sampling **。
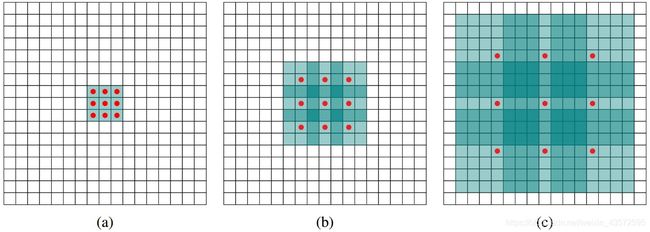
空洞卷积有一个参数可以设置dilation rate(dr),具体含义就是在卷积核中填充dr-1个0,因此,当设置不同dilation rate时,感受野就会不一样,也即获取了多尺度信息。
- 图a为1-dilated conv,感受野为3×3
- 图b为2-dilated conv,跟在1-dilated conv后面,感受野扩大为为7×7
- 图c为4-dilated conv,同样跟在1-dilated conv以及1-dilated conv后面,感受野扩大为为15×15
相比之下,使用stride为1的普通卷积,三层后的感受野仅为7×7
补充感受野的概念:
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应输入图上的区域,如图所示。
空洞卷积存在的缺陷:
The Gridding Effect-网格效应
例如假设我们仅仅多次叠加 dilation rate 2 的 3 x 3 kernel 的话,则会出现这个问题:

即你会发现映射到图片上,有很多格子都未参与计算,导致信息丢失。这里上面链接中提到了Hybrid Dilated Convolution (HDC),使得空洞卷积结构的设计更加标准化,可以了解一下。
Deeplabv1
DeepLabv1是结合了深度卷积神经网络(DCNNs)和概率图模型(DenseCRFs)的方法。在实验中发现DCNNs做语义分割时精准度不够的问题,根本原因是DCNNs的高级特征的平移不变性(即高层次特征映射)。DeepLab解决这一问题的方法是通过将DCNNs层的响应和完全连接的条件随机场(CRF)结合。同时模型创新性的将空洞卷积算法应用到DCNNs模型上。
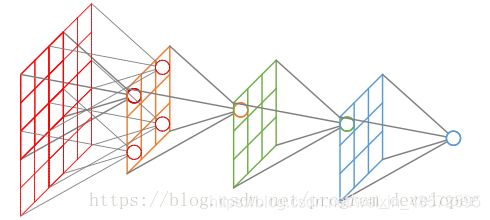
这里先描述一下Deeplabv1 的DCNN是如何设计的:调整VGG16模型,转为一个可以有效提取特征的语义分割系统。具体来说,先将VGG16的FC层(如下图FC6、FC7、FC8)转为卷积层(这里是空洞卷积),模型变为全卷积的方式,也就是类似于FCN那样。但为了以得到更加稠密的特征,在最后的两个最大池化层不下采样(stride=1),再通过2或4的采样率的空洞卷积对特征图做采样扩大感受野,缩小步幅。这里就不详细叙述了,参见FCN精华提炼,然后将空洞卷积作为解码器部分(即VGG16的全连接层被替换成的空洞卷积块)的卷积块。在得到上采样输出的初步结果后,为了使得输出结果更加精细、平滑,后面接上了条件随机场CRF。

CRF
条件随机场可以优化物体的边界,平滑带噪声的分割结果,去掉物体中间的预测的孔洞,使得分割结果更加准确。
对于每个像素位置ii具有隐变量xi(这里隐变量就是像素的真实类别标签,如果预测结果有21类,则(i∈1,2,…,21),还有对应的观测值yi(即像素点对应的颜色值)。以像素为节点,像素与像素间的关系作为边,构成了一个条件随机场(CRF)。通过观测变量yi来推测像素位置i对应的类别标签xi。条件随机场示意图如下:

整个网络的结构:

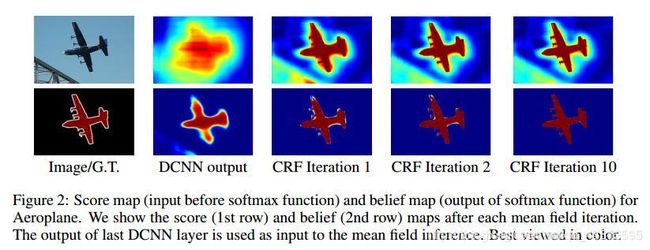
从结果来看,经过CRF优化的结果的确更加平滑、精细。但是缺点在于CRF的速度实在是太慢了。
多尺度预测
论文还探讨了使用多尺度预测提高边界定位效果。具体的,在输入图像和前四个最大池化层的输出上附加了两层的MLP(第一层是128个3×33×3卷积,第二层是128个1×11×1卷积),最终输出的特征映射送到模型的最后一层辅助预测,合起来模型最后的softmax层输入特征多了5×128=6405×128=640个通道,实验表示多尺度有助于提升预测结果,但是效果不如CRF明显。
Deeplabv2
相较于上一个版本,这个版本的主要改进在于:
- 使用ResNet101替代vgg16,做基础网络的改进,可以得到更好的准确性
- .提出atrous spatial pyramid pooling (ASPP即空洞卷进金字塔池化)来替代多尺度预测,可以大大增加感受野,感受野从普通卷积的kk增大到(k + (k - 1)(r - 1))(k + (k - 1)(r - 1))。其实就是将前面的最后一个池化层的输出以下图(b)的结构继续得到结果。
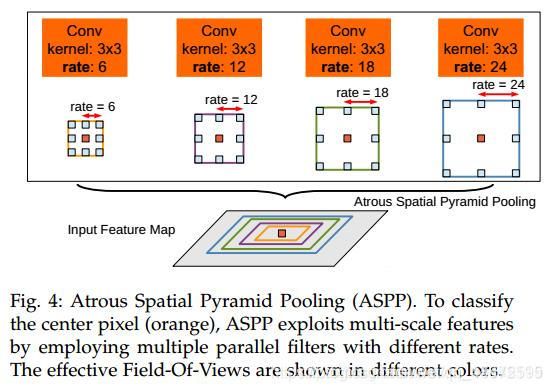

如上图,经过不同空洞dilation rate的空洞卷积块,并行的得到最后的结果,最后对所有结果进行融合。
Deeplabv3
这个版本中依旧延续了v2的深层空洞卷积网络(2、级联形式的空洞卷积代入ResNet块)和空洞卷积空间金字塔(3、并行化策略:重新设计ASPP,加入了Batch Normalization)两种策略,分别做了测试。但是去掉了后面的CRF后处理块。
1、总结获取多尺度信息的内容的几种方式:
- 将输入图片经过resize成不同大小作为输入,最后得到不同尺度的结果做融合
- 编解码结构
- 使用空洞卷积(串行)
- 空间金字塔结构(并行)

2、级联形式的空洞卷积代入ResNet块

可见,采用相同的stride,不用空洞卷积的情况下,经过8个Resnet块后分辨率变为了输入的256分之一,但加入空洞卷积后,分辨率变为了原来的16分之一。也就在说加入空洞卷积后,可以在不减小分辨率的同时提取特征。
3、并行化策略:重新设计ASPP,并加入了Batch Normalization
具有不同dilation rate的ASPP可有效捕获多尺度信息。 但是,随着采样率变大,有效滤波器权重(即应用于有效特征区域的权重,而不是填充的零)的数量变小。 在dilation rate接近要素图大小的极端情况下,3×3过滤器会代替简单的1×1过滤器,而不是捕获整个图像上下文,因为只有中央过滤器权重才有效。 解决办法:在最后一个特征图(Block4的输出)上输出上应用全局平均池化,将结果图像级特征馈送给具有256个过滤器的1×1卷积(和批量归一化),然后将特征双线性上采样至所需空间维度,最后将(a)和(b)的通道concat。经过最后的1*1卷积输出融合结果。
看下面的代码就很清楚了
# deeplabv3的ASPP模块
class ASPP(nn.Module):
def __init__(self, C, depth, num_classes, conv=nn.Conv2d, norm=nn.BatchNorm2d, momentum=0.0003, mult=1):
super(ASPP, self).__init__()
self._C = C # 进入aspp的通道数
self._depth = depth # filter的个数
self._num_classes = num_classes
self.global_pooling = nn.AdaptiveAvgPool2d(1)
self.relu = nn.ReLU(inplace=True)
# 第一个1x1卷积
self.aspp1 = conv(C, depth, kernel_size=1, stride=1, bias=False)
# aspp中的空洞卷积,rate=6,12,18
self.aspp2 = conv(C, depth, kernel_size=3, stride=1,
dilation=int(6*mult), padding=int(6*mult),
bias=False)
self.aspp3 = conv(C, depth, kernel_size=3, stride=1,
dilation=int(12*mult), padding=int(12*mult),
bias=False)
self.aspp4 = conv(C, depth, kernel_size=3, stride=1,
dilation=int(18*mult), padding=int(18*mult),
bias=False)
# 对最后一个特征图进行全局平均池化,再feed给256个1x1的卷积核,都带BN
self.aspp5 = conv(C, depth, kernel_size=1, stride=1, bias=False)
self.aspp1_bn = norm(depth, momentum)
self.aspp2_bn = norm(depth, momentum)
self.aspp3_bn = norm(depth, momentum)
self.aspp4_bn = norm(depth, momentum)
self.aspp5_bn = norm(depth, momentum)
# 先上采样双线性插值得到想要的维度,再进入下面的conv
self.conv2 = conv(depth * 5, depth, kernel_size=1, stride=1,
bias=False)
self.bn2 = norm(depth, momentum)
# 打分分类
self.conv3 = nn.Conv2d(depth, num_classes, kernel_size=1, stride=1)
def forward(self, x):
x1 = self.aspp1(x)
x1 = self.aspp1_bn(x1)
x1 = self.relu(x1)
x2 = self.aspp2(x)
x2 = self.aspp2_bn(x2)
x2 = self.relu(x2)
x3 = self.aspp3(x)
x3 = self.aspp3_bn(x3)
x3 = self.relu(x3)
x4 = self.aspp4(x)
x4 = self.aspp4_bn(x4)
x4 = self.relu(x4)
x5 = self.global_pooling(x)
x5 = self.aspp5(x5)
x5 = self.aspp5_bn(x5)
x5 = self.relu(x5)
# 上采样:双线性插值使x得到想要的维度
x5 = nn.Upsample((x.shape[2], x.shape[3]), mode='bilinear',
align_corners=True)(x5)
# 经过aspp之后,concat之后通道数变为了5倍
x = torch.cat((x1, x2, x3, x4, x5), 1)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.conv3(x)
return x
Deeplabv3+
在最新的DeeplabV3+中,有了较大的改动:
- 将ResNet改为了Xception块,因为Xception各方面表现更好。
- 将网络的整体结构改为了encode-decode的编解码结构,使得特征得到充分利用,提升输出精细程度
- 同时保留了ASPP模块
网络结构思想如下©:

具体的网络结构:
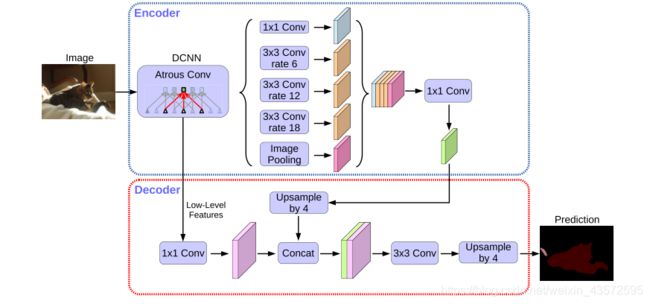
文章提出了一个简单而有效的解码器模块,如上所示。首先对编码器特征进行双线性上采样,放大倍数为4,然后将其与来自Xception构成的网络主干的具有相同特征的相应低层特征串联在一起。 由于相应的低级特征通常包含大量通道(例如256或512),因此会对低级特征进行另一次1×1卷积以减少通道数量。 串联后,应用一些3×3卷积来细化特征,然后再进行简单的双线性上采样(系数为4)。
思想不同于上一个版本Deeplabv3的地方可能只是将backbone网络的特征加到了所谓的编码器输出,提升输出的精细程度,因为Deeplabv3只是在上图中的encode最后的1*1Conv后经过上采样的结果,就是输出的最终结果了。
总结
-
空洞卷积提高感受野(large field-of-view,LargeFOV)
-
多尺度预测(MSc)
-
条件随机场(CRF)
-
基于并行或者cascade的空洞空间金字塔(ASPP),可以获得不同尺度的更丰富的纹理信息。
-
更深的网络结构效果可能更好
-
Encoder-Decoder结构可以充分利用提取到的各级特征信息,decoder模块的设计可以获得更好的边界分割效果
-
骨干网络的选择很重要,考虑新的网络Xception等。
-
思考为什么轻量级网络的效果为什么没那么好?