TF/pytorch/caffe-CV/NLP/音频-全生态CPU部署实战演示-英特尔openVINO工具套件课程总结(下)
TF-pytorch-caffe~CV/NLP/音频-全生态CPU部署实战演示-英特尔openVINO工具套件课程总结(下)
在上中两篇中我们充分理解了openvino的基本原理以及其硬件基础,在这篇博客中主要通过演示在Linux系统下实现多个实例模型的演示,操作语言选择熟悉的python语言(C++、java都可以官方技术文档中找到)这次将会仅仅使用到CPU,不需要使用GPU,就可以实现模型部署与使用。
如果你想要在自己的电脑上运行这些程序,就需要在linux的环境下安装好openvino,下面是官方的教学文档链接,总的来说不算很难,后期可以参考我的博客截图教程。
https://docs.openvino.ai/latest/openvino_docs_install_guides_installing_openvino_linux.html
在这里我推荐大家使用CSDN的官方平台进行同步尝试,任意点开一个intel的实验平台都可以使用已经配置好环境的linux系统,可以更快速地开始学习
下面是云平台的的链接,点进去都可以免费使用1000分钟
https://lab.csdn.net/welcome
选择上面第二个或者第三个都是没有问题的

七个经典演示实例
这七个演示从多个角度包括视觉、音频、文本理解、自然语言的处理全面地演示openvino是如何完成人体姿态识别、音频处理、目标检测、文本识别与自问自答等等。这些演示完全不需要GPU,全部都会在CPU上实现。
1.人体动作姿势识别示例(CV-pytorch)
2.图像着色示例(CV- VGG caffe)
3.音频识别示例(音频处理-ACLnet)
4.手写公式/打印公式识别(CV)
5.环境深度识别(CV-medasnet-pytorch)
6.6.目标识别道路车流监控示例(CV-YOLO/SSD-TF)
7.替你做英语阅读理解(NLP)——自动回答问题
这七个实例都采用先整体认知,然后再给出所有步骤的源代码,在云平台上都保证能够跑通。

1.人体动作姿势识别示例
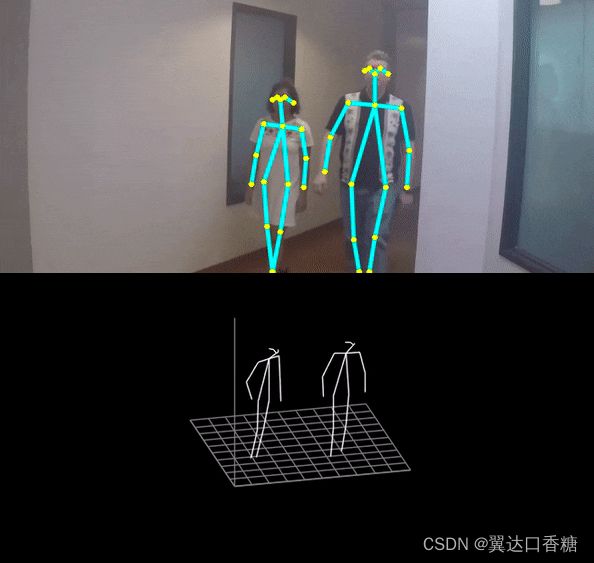
对人体姿势或者动作的理解主要归根于对人体关节点间关系的理解,下图你可以看到黄色的小黄点就是检测出来的人体关节点。人体姿态识别在安全、影视游戏甚至在现在的很火的一个热词–元宇宙中都有很广泛的应用。

对于这个关节点的检测虽然现在已经有了很多的算法已经能够实现,但是如果不使用GPU的条件下,能够满足FPS和精确度要求的可不算太多。在使用CPU的条件下,谷歌的mediapipe也拥有不俗
的性能,但是如果是对多路视频流检测,就很难保证FPS了。
openvino官方提供了一个标准的模型库,下载后就可以直接使用人体检测,当然后期我们更多会选择把自己的模型转化成部署在openvino上的模型。这是官方的下载模型的方法,需要的模型都可以通过下图或者按照官网指导下载,这个在后面会直接给出下载器的代码。

但是这些都可以在openVINO实现,以下是官方的产品文档,你可以在下面链接中找到整套的操作方法。如果想要实现,还需要根据上面的地址提示安装好openvino。
网址
https://docs.openvinotoolkit.org/latest/omz_demos_human_pose_estimation_3d_demo_python.html
二维码

1、设定实验路径
设定OpenVINO的路径:
export OV=/opt/intel/openvino_2021/
设定当前实验的路径:
export WD=~/OV-300/01/3D_Human_pose/
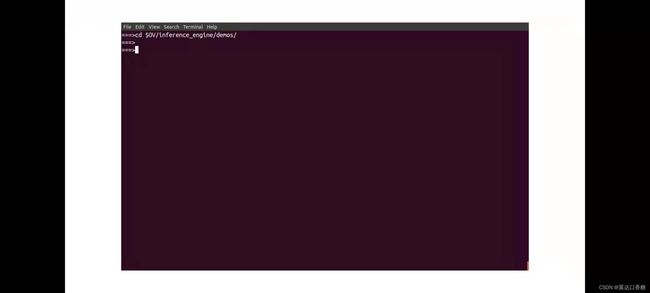
你还需要使用enable python 来构建示例,并且表示已经启动了python,输入以下的代码
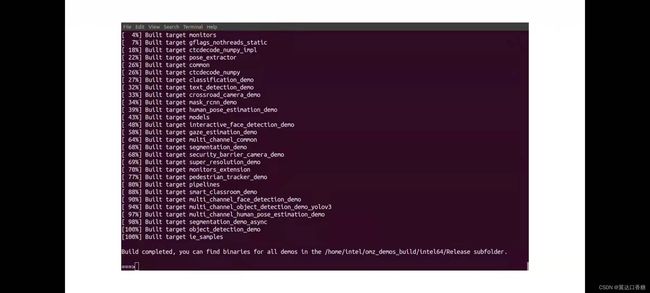
运行成功后如下图
上面两步简单来说就是两件事:导航到推理演示并且运行构建脚本。现在我们需要把库添加到python路径,如下图的代码
准备好后我们就可以使用python运行人体检测姿态模型,- i 输入的视频可以选择一段mp4的行人视频就行,- d 这里表示选择的设备,有显卡可以使用GPU,没显卡或者想用CPU就填CPU。

运行后你可以看到对人体检测以及三位人体骨骼视图
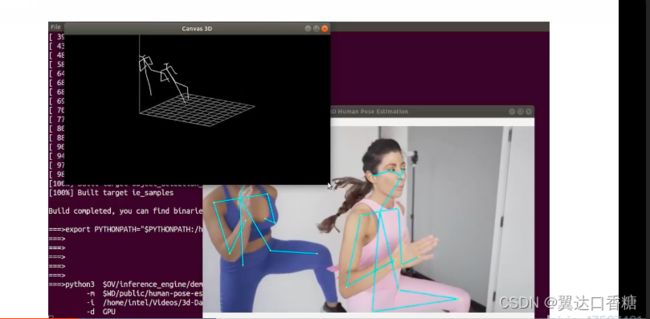
源码部分
1.人体动作姿势识别示例
设定实验路径
设定OpenVINO的路径:
export OV=/opt/intel/openvino_2021/
设定当前实验的路径:
export WD=~/OV-300/01/3D_Human_pose/
运行初始化OpenVINO的脚本
source $OV/bin/setupvars.sh
当你看到:[setupvars.sh] OpenVINO environment initialized 表示OpenVINO环境已经成功初始化。
运行OpenVINO依赖脚本的安装
进入脚本目录:
cd $OV/deployment_tools/model_optimizer/install_prerequisites/
安装OpenVINO需要的依赖:
sudo ./install_prerequisites.sh
PS:这个步骤是模拟开发机本地进行OpenVINO使用的步骤,所以 之后你在本地使用OpenVINO之前需要遵循此步骤。
安装OpenVINO模型下载器的依赖文件
进入到模型下载器的文件夹:
cd $OV/deployment_tools/tools/model_downloader/
安装模型下载器的依赖:
python3 -mpip install --user -r ./requirements.in
安装下载转换pytorch模型的依赖:
sudo python3 -mpip install --user -r ./requirements-pytorch.in
安装下载转换caffe2模型的依赖:
sudo python3 -mpip install --user -r ./requirements-caffe2.in
PS:此步骤为模拟开发机本地进行OpenVINO使用的步骤,所以 之后你在本地使用OpenVINO之前需要遵循此步骤。
通过模型下载器下载人体姿势识别模型
正式进入实验目录:
cd $WD
查看human_pose_estimation_3d_demo需要的模型列表:
cat /opt/intel/openvino_2021//deployment_tools/inference_engine/demos/human_pose_estimation_3d_demo/python/models.lst
通过模型下载器下载模型:
python3 $OV/deployment_tools/tools/model_downloader/downloader.py --list $OV/deployment_tools/inference_engine/demos/human_pose_estimation_3d_demo/python/models.lst -o $WD
使用模型转换器把模型转换成IR格式
OpenVINO支持把市面上主流的框架比如TensorFlow/Pytorch->ONNX/CAFFE等框架构建好的模型转换为IR格式:
python3 $OV/deployment_tools/tools/model_downloader/converter.py --list $OV/deployment_tools/inference_engine/demos/human_pose_estimation_3d_demo/python/models.lst
值得注意的是,OpenVINO的推理引擎只能够推理经过转换完成的IR文件,对市面上的语言框架是不能直接使用的,无法直接推理.pb/.caffemode/.pt等文件,所以这一步不要遗漏了。
编译OpenVINO的Python API
只需要编译一次:
source $OV/inference_engine/demos/build_demos.sh -DENABLE_PYTHON=ON
如果你需要使用OpenVINO的PythonAPI,请加入如下编译出来的库地址(否则会找不到库):
export PYTHONPATH="$PYTHONPATH:/home/dc2-user/omz_demos_build/intel64/Release/lib/"
播放待识别的实验视频
请手动输入如下命令来播放视频:
show 3d_dancing.mp4
(建议用键盘逐字母进行输入)
运行人体姿势识别Demo
python3 $OV/inference_engine/demos/human_pose_estimation_3d_demo/python/human_pose_estimation_3d_demo.py -m $WD/public/human-pose-estimation-3d-0001/FP16/human-pose-estimation-3d-0001.xml -i 3d_dancing.mp4 --no_show -o output.avi
时间会有几分钟的延迟,如果屏幕出现Inference Completed!! 则表示推理成功了,请输入“ls”罗列当前文件夹的所有文件,转换并播放识别结果视频。
由于平台限制,我们必须先将输出结果视频转换为MP4格式,使用如下命令:
ffmpeg -i output.avi output.mp4
手动输入如下命令进行推理结果视频播放:
show output.mp4
图像着色
在这个演示中你可以运用模型使用任意一张灰度图像,将这张灰度图片还原这张图像原来的颜色或者重新着色。

这其中所需要做的工作就是需要在没有颜色的情况下,判断出物体的颜色,对物体进行推测。一般来说马皮不太可能是黄色,大概率是棕色白色黑色,树叶是绿色的,这些都可以通过模型对大量训练集的学习来实现。
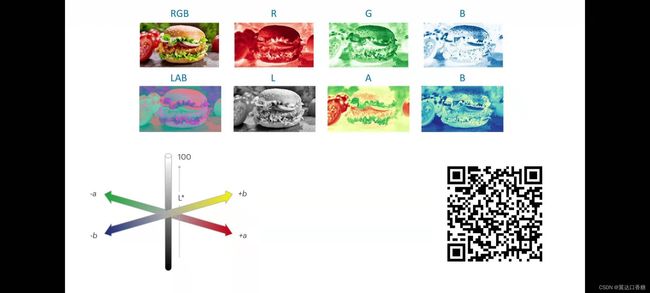
颜色在上篇有提到过图片的颜色主要是由三色(RGB)组成的:红黄蓝三种颜色,这三种颜色组成了图片的颜色通道,通过使用不同颜色的通道我们就可以合成任一种颜色。

同样图像也可以通过LAB来表示,下面是LAB图像范例,他可以由L、A、B三种通道组成。A通道表示红色和绿色的值,B通道表示黄色和蓝色的值,L通道表示白到黑的值变化。
在这个演示中使用的是RGB图像输入,然后提取L通道用作预测A和B通道,并且结合L通道重建RGB图像,扫描二维码就二维码可以获取指导。
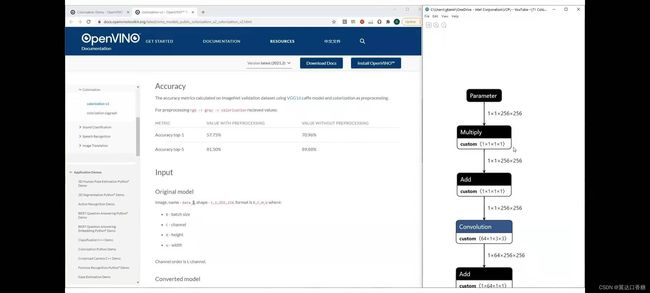
点开技术文档你可以了解到官方提供这样的可能模型有两个,你可以查看模型,规格,准确性等等。

右边这个图是在前面介绍过的可以查看模型结构的程序,你可以在此处看到图片的输入是11256256(像素)通道图像。
当然,在这里我们使用L输入,A和B通道也可以作为输入的。
在模型的最后你讲会得到一个12256256的输出JPG图片
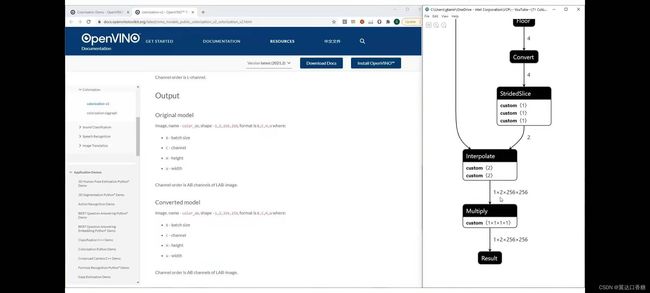
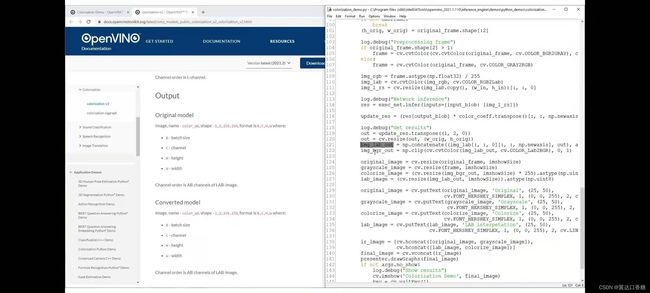
下图是官方的源代码,你可以在这里看到图像rgb,这是原始输入图像(img_rgb=*),我们正在提取lab(img_lab=)表示灰度图像,并使用(img_l_rs=**)调整大小的通道作为神经网络的输入

这是我们下达的推理指令
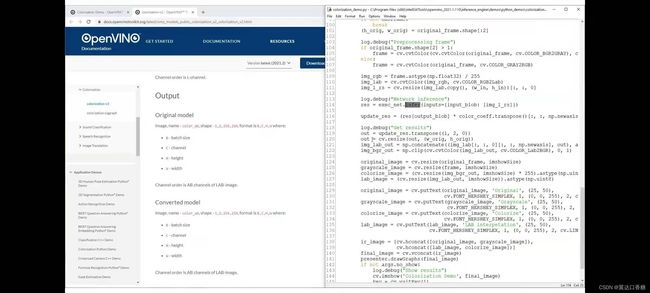
我们为了对比多个图像的效果,构建输出lab显示,输出rgb或bgr
这里如果是衔接着第一个实验实验的话就可以不用初始化openVINO(source指令)和定义OV、WD(非必须),这里直接进入了工作目录,使用cat可以查看demo的所需模型
你可以看到目录下的模型
调用模型下载器下载两个模型,并将他们放在我们的工作目录中下载第一个模型和第二个模型
下载成功后如下图
你可以在上面提示的路径中找到这两个模型
现在进行模型转化,将两个模型都转化为onex和IR,

然后运行着色演示就可以给灰度图像上色。
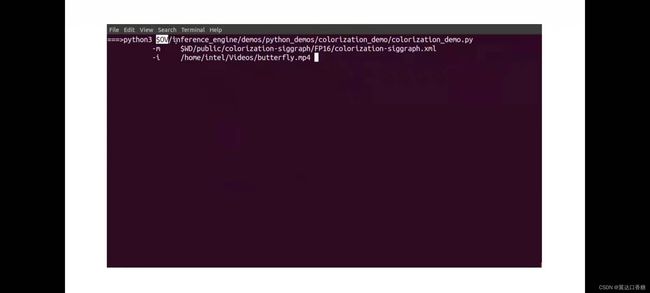

源码
2.图像着色示例
设置实验路径
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/Colorization/
初始化OpenVINO
source $OV/bin/setupvars.sh
开始实验
正式进入工作目录:
cd $WD
查看该demo的所需模型:
cat $OV/deployment_tools/inference_engine/demos/colorization_demo/python/models.lst
由于该实验模型较大,模型已经提前下载好了,请继续下一步。
查看原始视频
所有show命令都请手动输入:
show butterfly.mp4
运行着色Demo
python3 $OV/inference_engine/demos/colorization_demo/python/colorization_demo.py -m $WD/public/colorization-siggraph/colorization-siggraph.onnx -i butterfly.mp4 --no_show -o output.avi
这需要几分钟时间,你将会看到“Inference Completed”的字样。输出avi将保存于当前文件夹,使用小写“LL”命令查看当前文件夹。
查看着色实验的输出结果视频
请先使用ffmpeg将.avi转换为.mp4格式:
ffmpeg -i output.avi output.mp4
手动输入播放视频的指令:
show output.mp4
三、音频识别示例(音频处理)
官方文档的资料可以扫描下方的二维码进入技术文档

Demo,如何运行基于dl streaming的声音检测和分类。音频信号有时进入模型训练或者推理时需要大量的预处理,但是这个演示的一个亮点是音频是不需要与处理的。这里用的是wave文件,用作神经网络的输入,几乎没有预处理,只是在我们需要的时候,重新采样智所需的速率ACLnet是我们用于实验室的神经网络
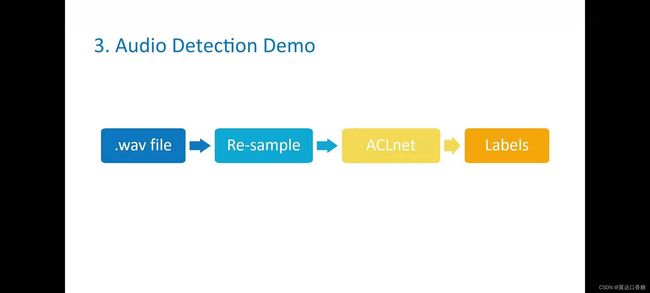
通过程序可以查看acl net神经网络的概况

CLAnet将时域中包含16000个示例的向量作为输入前两个卷积层提取低级光谱特征,接下来是高级特征。在中篇中我们提到过声音是先转化成光谱再进行处理的。
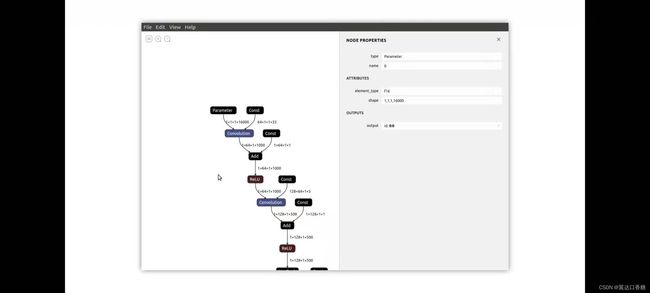
最后一程提供了所有53个类别的概率,看看这个声音是属于小猫小狗还是青蛙人类的。
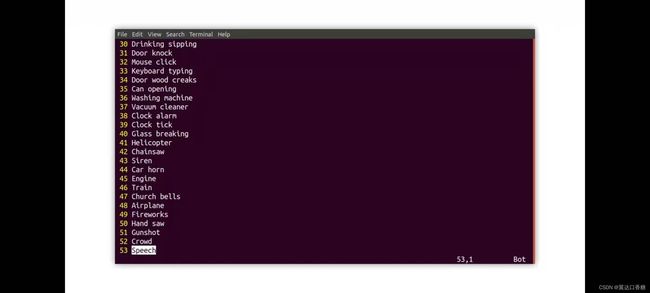
你可以查看标签文件,它是基于官方的数据集的,你可以用下图的指令去打开看下类别。

每行是一个类别,类别零是狗,然后是其余的农场动物,直到类别53是speech的声音
首先是运行这个demo实例,然后定义一个OV的路径,可以简化后面的数据表达。
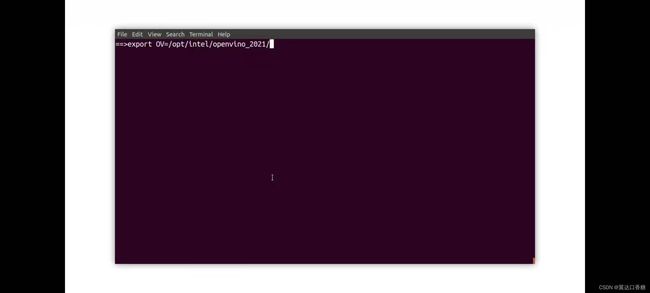
source是初始化openvino,将其转到处理dl stream实例,然后你可以进入到cd 这个路径下的文件夹,去看下我们的素材
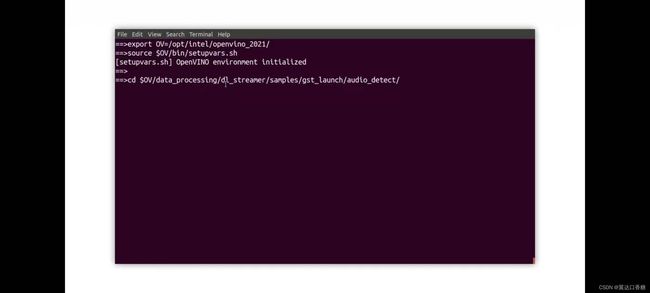
输入ll查看文件夹下的文件,可以停下分析音频什么样子。
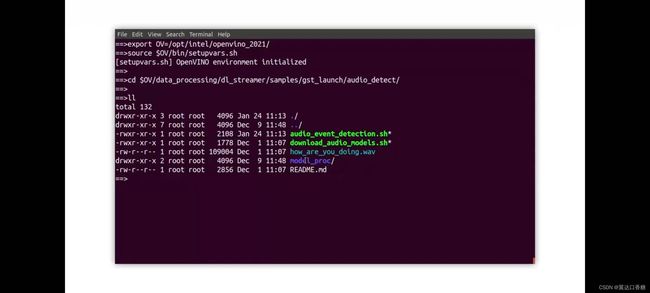
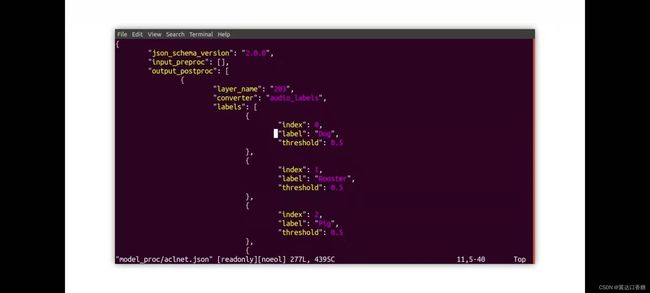
你也可以使用vi 进入到文件的内部,比如说下面的代码你可以进入到标签文件去查看一下。

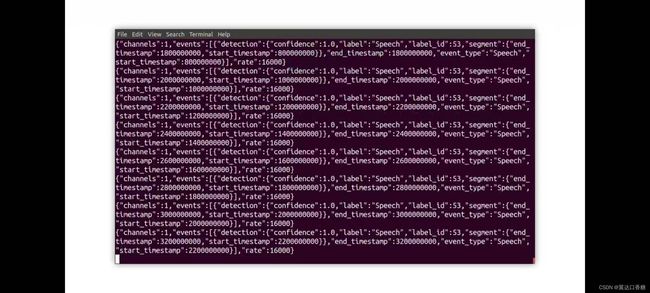
运行我们的示例

你会得到一系列的运行分析结果,下面三张图都是分析声道中所含有的声音,你可以看到有一些小动物生物,然后可能是来自于背景声音。

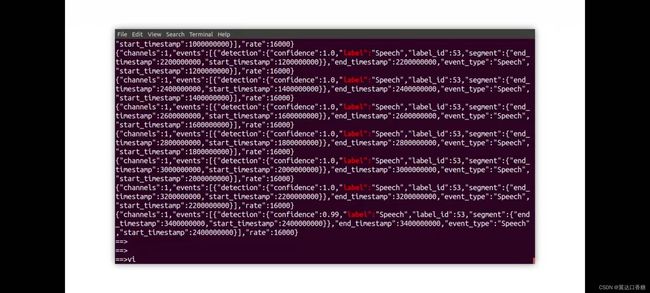
源码
3.音频检测示例
初始化环境
#初始化工作目录
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/Audio-Detection/
#初始OpenVINO
source $OV/bin/setupvars.sh
进入音频检测目录
#进入OpenVINO中自带的音频检测示例:
cd $OV/data_processing/dl_streamer/samples/gst_launch/audio_detect
#你可以查看检测的标签文件
vi ./model_proc/aclnet.json
#你也可以播放待会待检测的音频文件
show how_are_you_doing.mp3
运行音频检测
#运行示例
bash audio_event_detection.sh
分析音频检测结果
#结果并不是很适合观察,你可以运行如下命令
bash audio_event_detection.sh | grep "label\":" |sed 's/.*label"//' | sed 's/"label_id.*start_timestamp"://' | sed 's/}].*//'
#现在你可以看到在时间戳600000000的时候,我们检测到语音了,但并不知道内容是什么,因为它知识一个检测示例,并不是一个识别示例:“Speech”,600000000
4.手写公式/打印公式识别
第四个模型是运用模型去检测手写公式或latex编写的公式

这个识别任务分为两个独立模型的模型来完成。第一个模型称为编码器,是一个卷积神经网络,用于图像中提取特征,一般来说,基本上是识别字母或符号的边界框。
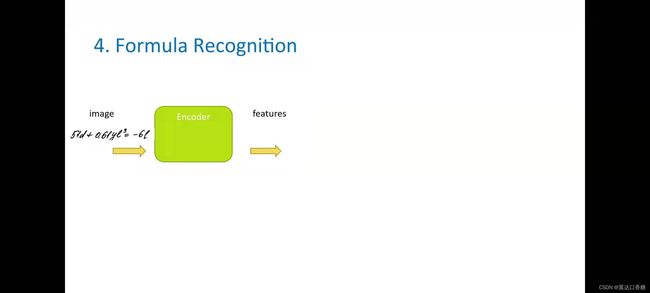
第二个模型是LSTM模型,因为上下文特征很重要,所以我们需要一个可以记住这些符号的模型,并了解完整的序列和符号历史,所以在达到可以在命令行中定义的最大公式长目之前,他将前一个编码器模型提供的模型输入去查找下一个符号。

官方提供了多个不同的任务linux模型:latex模型可以检测大小写字母、英文、数字和一些数学函数。手写模型可以预测手写模型的数学字符
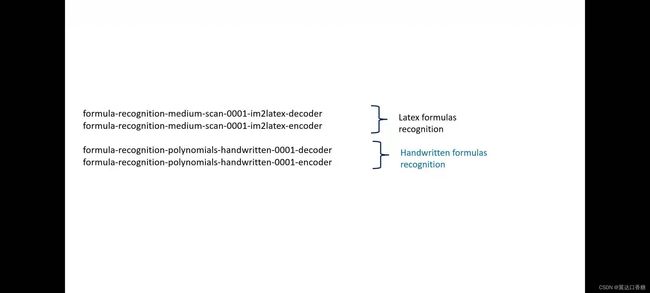
首先还是定义工作目录OV和WD,方便后面的路径使用,初始化openvino。

初始化成功
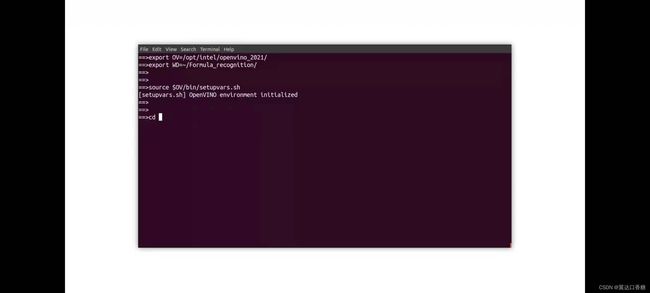
接下里你可以切换路径到SWD
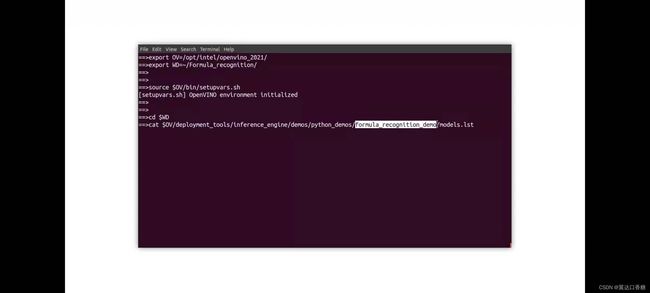
在这里你可以看到latex和手写识别模型文件
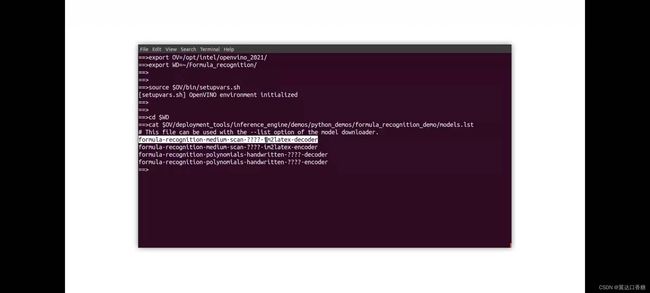
然后使用模型下载器下载这些文件,特别地,这里将模型下载为F16的模型,这里说下这个模型格式,不同的模型格式在不同的硬件上支持是不一样的,但是CPU支持所有格式的模型,但是GPU和VPU不一定都支持。
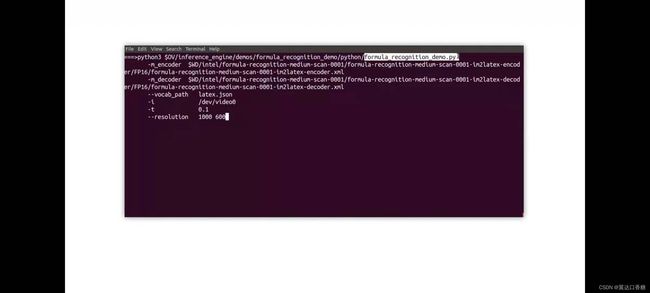
下载成功后的页面,接下来就是我们的两个词汇文件,把他们添加到工作目录。

画白的地方就是其中一个的对应地址

到这里所有的准备工作就完成了。

当你再打开工作目录时就可以发现有两个latex图像和自由格式的书写公式,模型等
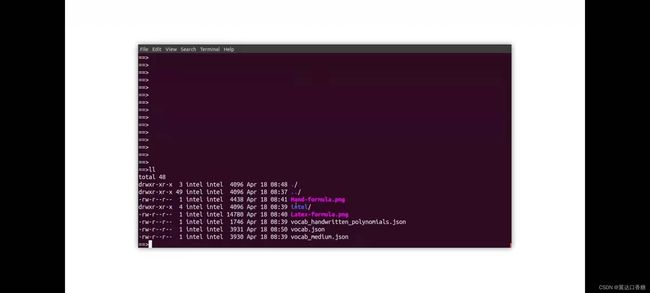
我们开始运行我们的编码器和解码器模型
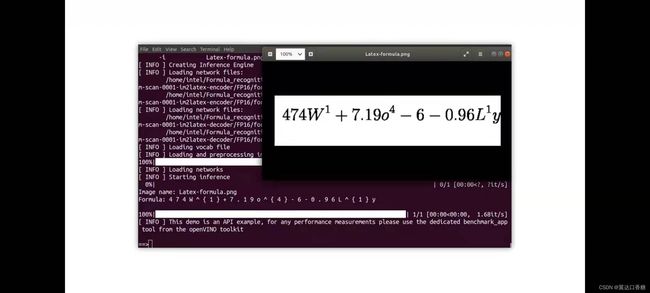
latex效果
我们接下来运行手写模型

手写模型
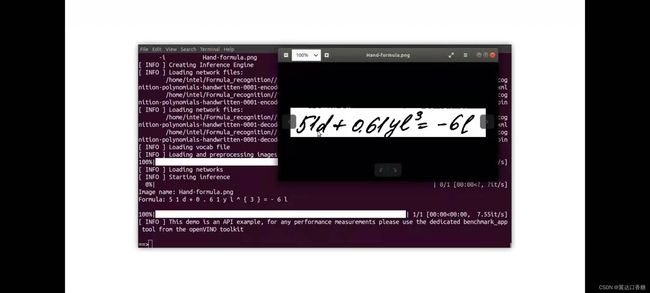
你也可以试试用摄像头的来接入识别的图像


源码
4.公式识别
初始化环境
#初始化环境
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/Formula_recognition/
#初始化OpenVINO
source $OV/bin/setupvars.sh
查看可识别的字符
cd $WD
#手写字符:
vi hand.json
#打印字符:
vi latex.json
查看待识别的公式
#进入材料目录
cd $WD/…/Materials/
#查看打印公式
show Latex-formula.png
#查看手写公式
show Hand-formula.png
运行公式识别
cd $WD
识别打印公式
python3 $OV/inference_engine/demos/formula_recognition_demo/python/formula_recognition_demo.py -m_encoder $WD/intel/formula-recognition-medium-scan-0001/formula-recognition-medium-scan-0001-im2latex-encoder/FP16/formula-recognition-medium-scan-0001-im2latex-encoder.xml -m_decoder $WD/intel/formula-recognition-medium-scan-0001/formula-recognition-medium-scan-0001-im2latex-decoder/FP16/formula-recognition-medium-scan-0001-im2latex-decoder.xml --vocab_path latex.json -i $WD/…/Materials/Latex-formula.png -no_show
识别手写公式
python3 $OV/inference_engine/demos/formula_recognition_demo/python/formula_recognition_demo.py -m_encoder $WD/intel/formula-recognition-polynomials-handwritten-0001/formula-recognition-polynomials-handwritten-0001-encoder/FP16/formula-recognition-polynomials-handwritten-0001-encoder.xml -m_decoder $WD/intel/formula-recognition-polynomials-handwritten-0001/formula-recognition-polynomials-handwritten-0001-decoder/FP16/formula-recognition-polynomials-handwritten-0001-decoder.xml --vocab_path hand.json -i $WD/…/Materials/Hand-formula.png -no_show
#对比原始图片,检查识别是否正确。
5.环境深度识别
在这个实例中你可以从一个简单的图像中创建一个具有三维深度的3D图像,想要更深入的信息,可以扫描二维码,找到完整文档,

对于人类来说,我们从三维视角观察世界,我们都认为我们可以看到的深度是我们大脑判断的结果,我们的大脑正接收两只眼睛捕捉的略有不同的图像病,推断深度。但是即使你闭上一只眼睛看那个图像,你也可以清楚的识别深度,因为我们已经学会了根据阴影大小来确定深度。

这个演示项目是基于intel实验室的研究,这个项目能够混合不同的3D数据集,可以参考下图的左侧。单对于openvino而言,深度学习模型和加载的运行方式是完全相同的,你可以在这个文档中找到模型详细信息,该模型称为midasnet

你可以官网查看这个模型的详细信息,输入输出、模型结构、精确度等等。

你可以在这里找到规格和准确度模型的输入,是rgb图像
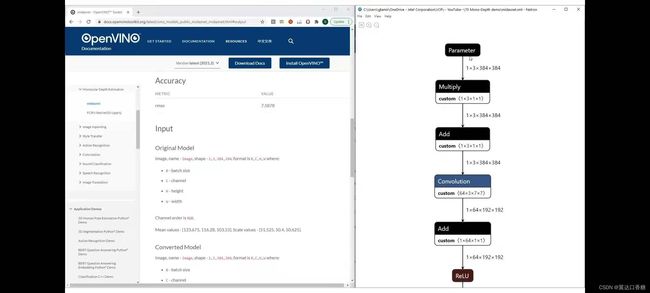
最终输出的是逆向深度图像,所以你在这里得到一个数组,与输入图像的大小相同,图像中每个像素具有逆向深度值

在monodepth_demo下,你可以找到python的脚本和模型列表
让我们使使用模型下载器下载这个模型,成功后如下图
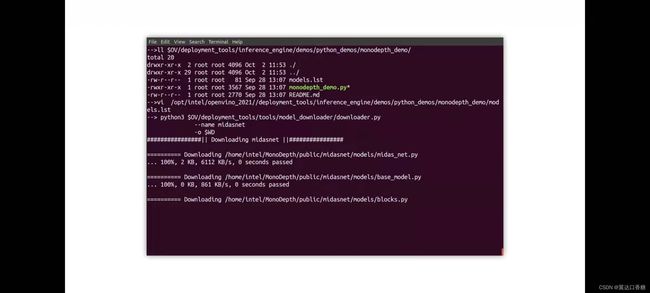
然后我们输入如下命令进行模型转化,pytorch转成IR模型

运行演示,这里图像自备一张

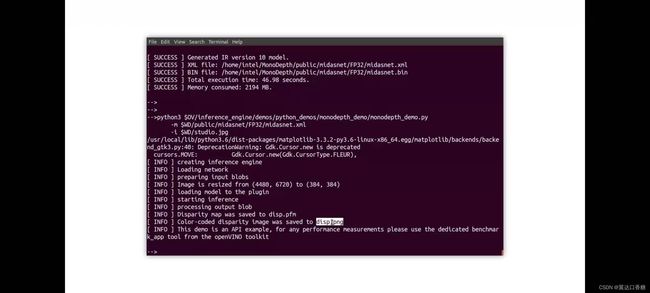
运行成功如下图,然后下方是运行的结果与保存的路径
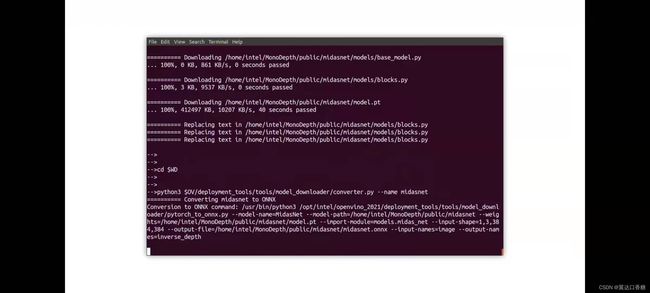
根据设置的路径找到两张图形
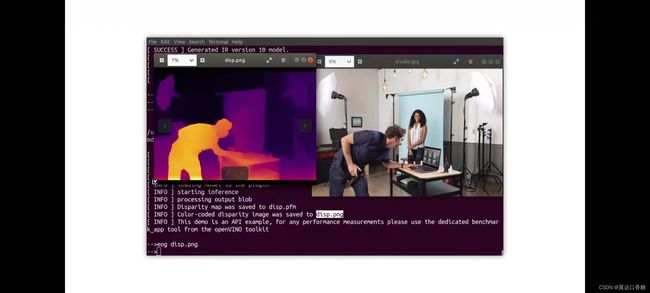
我们可以看下运行后的3D图像
5.环境深度识别
初始化环境
#环境目录
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/MonoDepth_Python/
#初始化OpenVINO
source $OV/bin/setupvars.sh
转换原始模型文件为IR文件
进入工作目录
cd $WD
#下载好的模型为TensorFlow格式,使用converter准换为IR格式:
python3 $OV/deployment_tools/tools/model_downloader/converter.py --list $OV/deployment_tools/inference_engine/demos/monodepth_demo/python/models.lst
查看需要被识别的原始图片
#查看原始文件
show tree.jpeg
运行深度识别示例
#进入工作目录
cd $WD
#运行示例,该示例的作用是自动分离图片中景深不同的地方:
python3 $OV/inference_engine/demos/monodepth_demo/python/monodepth_demo.py -m $WD/public/midasnet/FP32/midasnet.xml -i tree.jpeg
查看显示结果
show disp.png
6.目标识别道路车流监控示例
在这个演示中将使用多个不同的神经网络架构运行对象检测推理,可以选择YOLO,SSD或其他并下载该框架匹配的模型,更多信息可以关注二维码

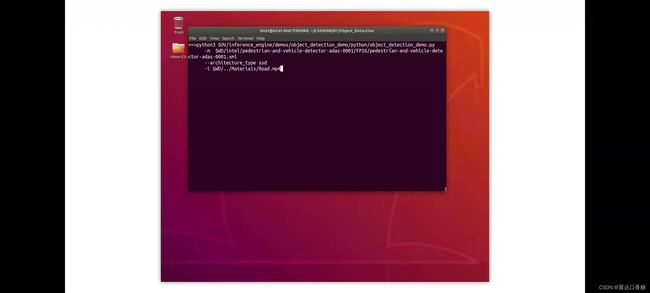
让我们运行演示,第一个用的架构是ssd,所以需要一个基于ssd的模型使用接警视频作为输入
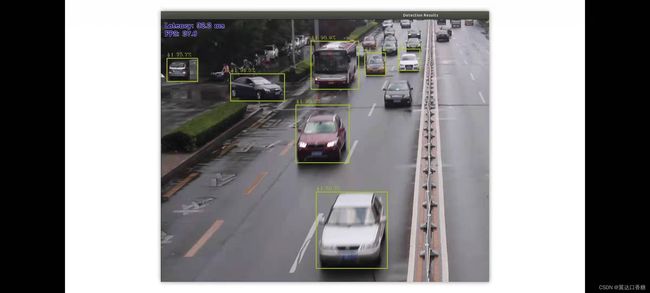
检测到了很多汽车行人的对象
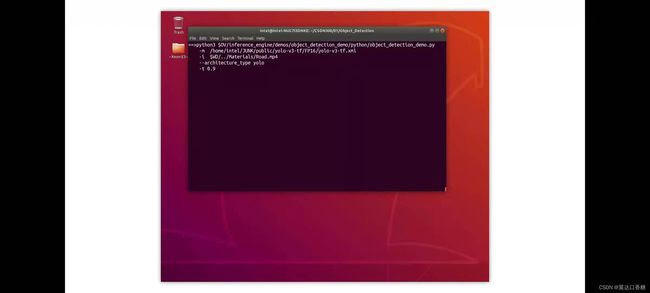
将把架构更改为YOLO的模型
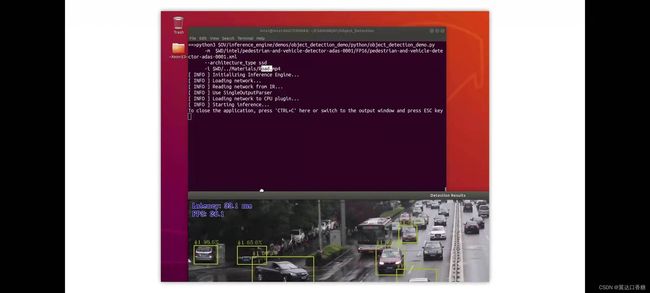
稍微更改一下检测域值
运行成功,所有检测到的汽车行人,这是完全不同的拓扑结构,但是效果还是相当理想的。
6.目标识别示例
初始化环境
#定义OpenVINO 目录
export OV=/opt/intel/openvino_2021/
#定义工作目录
export WD=~/OV-300/01/Object_Detection/
#初始化OpenVINO
source $OV/bin/setupvars.sh
#进入工作目录
cd $WD
选择适合你的模型
#由于支持目标检测的模型较多,你可以在不同拓扑网络下选择适合模型:
vi $OV/inference_engine/demos/object_detection_demo/python/models.lst
注:关于SSD, Yolo, centernet, faceboxes or Retina拓扑网络的区别,本课程不会继续深入,有兴趣的同学可以自行上网了解。在OpenVINO中的deployment_tools/inference_engine/demos/的各个demo文件夹中都有model.lst列出了该demo支持的可直接通过downloader下载使用的模型
转换模型至IR格式
#本实验已经事先下完成:pedestrian-and-vehicle-detector-adas 与 yolo-v3-tf
#使用Converter进行IR转换,由于pedestrian-and-vehicle-detector-adas 为英特尔预训练模型,已经转换IR完成,只需要对yolo-v3进行转换:
python3 $OV/deployment_tools/tools/model_downloader/converter.py --name yolo-v3-tf
查看待检测的视频
cd $WD/…/Materials/Road.mp4
#播放视频:
show Road.mp4
使用SSD模型运行目标检测示例
cd $WD
#运行 OMZ (ssd) model
python3 $OV/inference_engine/demos/object_detection_demo/python/object_detection_demo.py -m $WD/intel/pedestrian-and-vehicle-detector-adas-0001/FP16/pedestrian-and-vehicle-detector-adas-0001.xml --architecture_type ssd -i $WD/…/Materials/Road.mp4 --no_show -o $WD/output_ssd.avi
#转换为mp4格式进行播放
ffmpeg -i output_ssd.avi output_ssd.mp4
show output_ssd.mp4
运行Yolo-V3下的目标检测示例
#运行 the Yolo V3 model
python3 $OV/inference_engine/demos/object_detection_demo/python/object_detection_demo.py -m $WD/public/yolo-v3-tf/FP16/yolo-v3-tf.xml -i $WD/…/Materials/Road.mp4 --architecture_type yolo --no_show -o $WD/output_yolo.avi
#转换为mp4格式进行播放
ffmpeg -i output_yolo.avi output_yolo.mp4
show output_yolo.mp4
!请对比两个模型在相同代码下的检测性能
7.替你做英语阅读理解(NLP)——自动回答问题
最后一个是NLP(自然语言处理)部分,这个演示使用bert模型来处理文件,并根据文本内容使用模型自动回答问题,这里可以使用任何你喜欢的文本

这里以有关巴黎的维基百科页面,(下面有官网)。首先需要加载模型,并将其转换为ir,然后运行演示
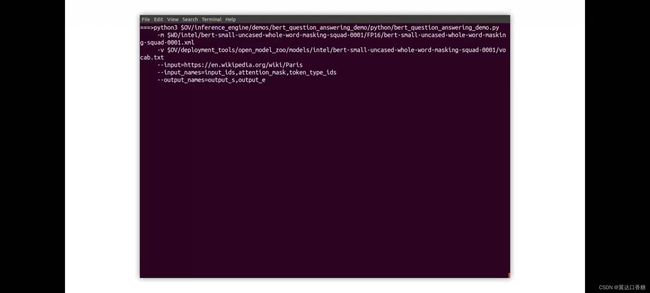
输入是维基百科、模型、配置参数等,和上面六个演示一样
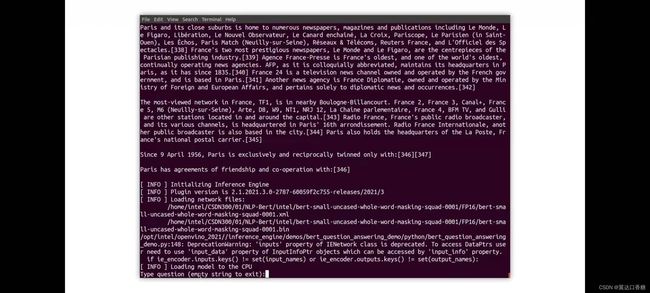
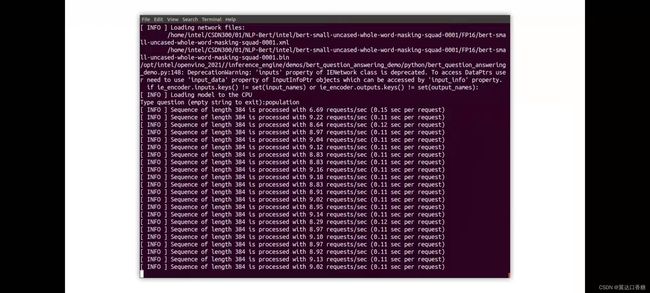
一旦我们运行演示文本就会被处理,现在也是正在等待一个问题,现在我们可以提出一些问题,例如,巴黎的人口是多少?模型正在工作,因为这是一个长文本,每384个单词,就会调用一次模型。所以你可以看到很多解释,其中你可以看到有几个可能的答案以及概率
最后从下面那句信息中知道巴黎的人口略多于200万人
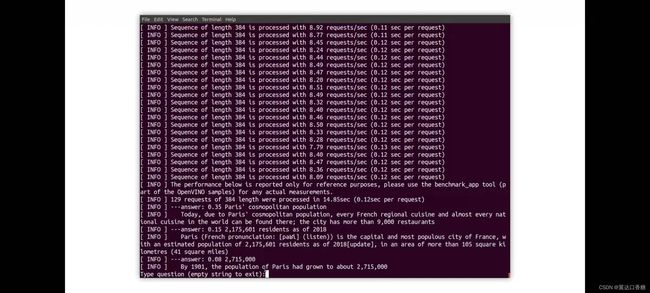
7.自然语言处理示例(NLP)——自动回答问题
初始化环境
#定义工作目录
export OV=/opt/intel/openvino_2021/
export WD=~/OV-300/01/NLP-Bert/
#初始化OpenVINO
source $OV/bin/setupvars.sh
#进入目录
cd $WD
查看支持的模型列表
#可用列表:
cat $OV/deployment_tools/inference_engine/demos/bert_question_answering_demo/python/models.lst
注:在OpenVINO中的deployment_tools/inference_engine/demos/的各个demo文件夹中都有model.lst列出了该demo支持的可直接通过downloader下载使用的模型,且我们已经事先下载好全部模型为IR格式。
打开待识别的网址
#使用浏览器打开一个英文网址进行浏览,例如Intel官网:https://www.intel.com/content/www/us/en/homepage.html
运行NLP示例
python3 $OV/inference_engine/demos/bert_question_answering_demo/python/bert_question_answering_demo.py -m $WD/intel/bert-small-uncased-whole-word-masking-squad-0001/FP16/bert-small-uncased-whole-word-masking-squad-0001.xml -v $OV/deployment_tools/open_model_zoo/models/intel/bert-small-uncased-whole-word-masking-squad-0001/vocab.txt --input=https://www.intel.com/content/www/us/en/homepage.html --input_names=input_ids,attention_mask,token_type_ids --output_names=output_s,output_e
#在Type question (empty string to exit): 输入core。即可查看当前对于core(酷睿)的可知信息,例如: Intel® Core™ processors provide a range of performance from entry-level to the highest level 。当然你也可以输入别的问题。对比网站上的相关描述
注:–input=https://www.intel.com/content/www/us/en/homepage.html 为我们需要访问的英文网站