本文地址:https://www.cnblogs.com/faranten/p/15917369.html
转载请注明作者与出处
1 二元变量
1.1 伯努利分布与二项分布
考虑一个最基本的试验:抛硬币试验。在一次实验中只有两个结果,即正面与反面,用随机变量\(x=1\)来表示抛掷硬币得到的是正面,\(x=0\)来表示抛掷硬币得到的是反面,且先验地猜测得到正面的概率是\(\mu\),那么
\[\begin{aligned} p(x=1|\mu)&=\mu\\ p(x=0|\mu)&=1-\mu \end{aligned} \]
那么\(x\)的概率分布可以写作
\[\text{Bern}(x|\mu)=\mu^x(1-\mu)^{1-x} \]
这称为二元变量的伯努利分布(Bernoulli distribution),容易得到
\[\begin{aligned} E(x|\mu)&=\mu\\ \text{var}(x|\mu)&=\mu(1-\mu) \end{aligned} \]
如果将试验次数增多到\(N\)次,实验数据集为\(D\),并以随机变量\(x\)记得到硬币正面的次数,由于各次试验是相互独立的,因此似然函数为
\[p(D|\mu)=\prod_{n=1}^Np(x_n|\mu)=\prod_{n=1}^N\mu^{x_n}(1-\mu)^{1-x_n} \]
对于频率主义来说,此时的实验数据集是确定的,因此确定参数\(\mu\)的方式就是最大化上述形如\(\mu^a(1-\mu)^b\)的似然函数,使用极大似然方法,对数化上述似然函数得到\(\ln p(D|\mu)=\sum_{n=1}^N\{x_n\ln\mu+(1-x_n)\ln(1-\mu)\}\),进而解得上式中\(\mu_{ML}=\frac1N\sum_{n=1}^Nx_n\),该值称为样本均值(sample mean),其实该值就是\(N\)次试验中得到正面的比例\(\frac{m}{N}\)。值得一提的是,该对数似然函数仅与\(\sum_{n=1}^Nx_n\)有关,因此可称该量为充分统计量(sufficient statistic)。后面将看到,二项分布作为伯努利分布的一般化形式,所以只需要对二项分布使用贝叶斯方法,就涵盖了贝叶斯方法处理伯努利分布的情况。
现在考虑\(N\)次试验中得到正面的次数\(m\),若将此作为随机变量,则它的分布为
\[\text{Bin}(m|N,\mu)=\left(\begin{array}{c}N\\m\end{array}\right)\mu^m(1-\mu)^{N-m}, \qquad\left(\begin{array}{c}N\\m\end{array}\right)\equiv\frac{N!}{(N-m)!m!} \]
该分布称为二项分布(binomial distribution),二项分布可以视作伯努利分布在试验次数上的推广,容易得到
\[\begin{aligned} E(m|N,\mu)&=N\mu\\ \text{var}(m|N,\mu)&=N\mu(1-\mu) \end{aligned} \]
在二项分布中,如果给定数据集,在频率方法下用极大似然方法求出\(\mu\)的估计值仍然是\(N\)次试验中得到正面的比例\(\frac{m}{N}\),当数据集规模较小的时候,这种思路很容易导致过拟合,这说明了贝叶斯方法的必要性。
1.2 Beta分布
在二项分布中,如果令\(N=1\),那么二项分布就变成了伯努利分布,因此可以认为二项分布是伯努利分布更加一般的形式,所以接下来只讨论二项分布而忽略伯努利分布的情况。对于贝叶斯主义而言,二项分布中的\(\mu\)是随机变量,我们应该用训练集来找到\(\mu\)的尽可能精确的分布,由于
\[p(\mu|D)=\frac{p(D|\mu)p(\mu)}{p(D)} \]
其中\(p(D)\)为常数\(N\),而似然函数为
\[p(D|\mu)=\prod_{n=1}^Np(x_n|\mu)=\prod_{n-1}^N\mu^{x_n}(1-\mu)^{1-x_n}=\mu^m(1-\mu)^{N-m} \]
其中\(m\)为得到正面的次数。如果先验分布和后验分布具有相似的函数形式,则这种性质称为共轭性(conjugacy)(这保证了顺序学习过程将会一直进行下去)。观察到似然函数仅与\(\mu\)与\((1-\mu)\)两个因子的幂指数成正比,所以如果我们选择一个正比于\(\mu\)与\((1-\mu)\)两个因子的幂指数,自然就能保证共轭性。所以选择如下形式的先验分布
\[\text{Beta}(\mu|a,b)=\frac{\Gamma(a+b)}{\Gamma(a)\Gamma(b)}\mu^{a-1}(1-\mu)^{b-1} \]
这称为Beta分布,其中参数\(a\)与\(b\)决定了分布的形态,因此是超参数。容易得到
\[\begin{aligned} E(\mu|a,b)&=\frac{a}{a+b}\\ \text{var}(\mu|a,b)&=\frac{ab}{(a+b)^2(a+b+1)} \end{aligned} \]
那么,参数\(\mu\)的后验分布\(p(\mu|m,l,a,b)\)满足
\[p(\mu|m,l,a,b)\varpropto p(m,l|\mu,a,b)\cdot p(\mu|a,b)\varpropto\mu^m(1-\mu)^{l}\cdot\mu^{a-1}(1-\mu)^{b-1}=\mu^{m+a-1}(1-\mu)^{l+b-1} \]
其中\(l=N-m\),和Beta分布的标准形式相比,很快得到归一化系数,于是就有
\[p(\mu|m,l,a,b)=\frac{\Gamma(m+l+a+b)}{\Gamma(m+a)\Gamma(l+b)}\mu^{m+a-1}(1-\mu)^{l+b-1} \]
直观来看:其中\(m\)和\(l\)是训练集中正面次数和反面次数,\(a\)和\(b\)是先验知道的正面次数和反面次数,在试验的时候可以简单地认为\(a\)的值变大了\(m\)、\(b\)的值变大了\(l\),可将超参数\(a\)与\(b\)分别看成是\(x=1\)和\(x=0\)的有效观测数(effective number of observation)。但是\(a\)和\(b\)具有更一般化的含义,不仅仅是整数。随机变量\(\mu\)的期望和方差分别为
\[\begin{aligned} E(\mu|m,l,a,b)&=\frac{m+a}{(m+a)+(l+b)}\\ \text{var}(\mu|m,l,a,b)&=\frac{(m+a)(l+b)}{((m+a)+(l+b))^2((m+a)+(l+b)+1)} \end{aligned} \]
上述内容暗示了学习过程中的顺序(sequential)方法是合理的,即每次将先验分布乘上似然函数,再进行归一化(找到合适的归一化参数)便得到了后验分布,这个后验分布将在下一次学习过程中扮演先验分布的角色。并且,随着试验次数\(N\rightarrow\infty\),\(m\)和\(l\)都将趋于正无穷,此时的\(E(\mu)\)和\(\text{var}(\mu)\)都将趋于各自的极大似然估计,并且与先验的参数\(a\)和\(b\)无关。
2 多项式变量
2.1 范畴分布与多项式分布
二元变量只能用来描述某两种取值的试验,现在给出一种新的变量:多项式变量(multinomial variable),可以用来描述具有多种离散情况的变量,比如
\[\mathbf{x}=(0,0,1,0,0,0)^T \]
描述的是一个具有六种离散状态的变量,并且此时该变量为第三种状态。多项式变量满足\(\sum_{k=1}^Kx_k=1\)。现用参数\(\mu_k\)来描述第\(k\)个变量\(x_k=1\)的概率,则有
\[p(\mathbf{x}|\pmb{\mu})=\prod_{k=1}^K\mu_k^{x_k} \]
该分布称为范畴分布(multinoulli distribution)或者分类分布(categotical distribution),该分布可以视作伯努利分布在试验“维数”上面的推广,其中\(\pmb{\mu}=(\mu_1,\mu_2,\cdots,\mu_k)^T\),显然\(\mu_k\geq0\)并且\(\sum_{k=1}^K\mu_k=1\)。可以得到
\[\begin{aligned} E(\mathbf{x}|\pmb{\mu})&=(\mu_1,\mu_2,\cdots,\mu_K)^T\\ \text{var}(\mathbf{x}|\pmb{\mu})&=(\mu_1(1-\mu_1),\mu_2(1-\mu_2),\cdots,\mu_K(1-\mu_K))^T\\ \text{cov}(\mathbf{x}|\pmb\mu)&=\text{diag}(\mu_1,\cdots,\mu_K)-\pmb\mu\pmb\mu^T \end{aligned} \]
在之前关于伯努利分布和二项分布的内容中,我们将伯努利分布视为单一试验中二元变量的概率分布情况,而将二项分布视为多次试验中二元变量的概率分布情况。现在,我们刚讨论完单一试验中多项式变量的概率分布情况,自然要考虑多次实验中多项式变量的概率分布情况。对于给定的数据集\(D=\{\mathbf{x}_1,\mathbf{x}_2,\cdots,\mathbf{x}_N\}\)而言,对应的似然函数的形式为
\[p(D|\pmb{\mu})=\prod_{n=1}^N\prod_{k=1}^K\mu_k^{x_{nk}}=\prod_{k=1}^K\mu_k^{\sum_{n=1}^Nx_{nk}}=\prod_{k=1}^K\mu_k^{m_k} \]
其中\(m_k\)描述了在数据集\(D\)中取第\(k\)种状态的数据点的数量,即\(x_k=1\)的次数,且这\(k\)个值是该似然函数的充分统计量。对此似然函数进行对数化处理,用极大似然方法,注意到约束条件\(\sum_{k=1}^K\mu_k=1\),可以解得参数\(\pmb\mu\)的极大似然估计为\(\mu_k^{ML}=\frac{m_k}N\)。
现在考虑每个状态的观测数量在参数\(\pmb\mu\)和总观测数量\(N\)条件下的分布,若将每个状态的观测数量作为一组随机变量,则它们的联合分布为
\[\text{Mult}(m_1,m_2,\cdots,m_K|\pmb\mu,N)= \left( \begin{array} {c} N\\ m_1m_2\cdots m_K \end{array} \right) \prod_{k=1}^K\mu_k^{m_k} \]
该分布称为多项式分布(multinomial distribution),约束条件为\(\sum_{k=1}^Km_k=N\)。多项式分布可以视作范畴分布在试验次数上的推广,其中归一化系数就是在PRML 基础知识 6.1节提到的“乘数”概念,具体意义是将\(N\)个物体分成大小为\(m_1,m_2,\cdots,m_K\)的\(K\)组的方案总数。可以得到
\[\begin{aligned} E(m_1,m_2,\cdots,m_K|\pmb\mu,N)&=N(\mu_1,\mu_2,\cdots,\mu_K)^T\\ \text{var}(m_1,m_2,\cdots,m_K|\pmb\mu,N)&=N(\mu_1(1-\mu_1),\mu_2(1-\mu_2),\cdots,\mu_K(1-\mu_K))^T\\ \text{cov}(m_1,m_2,\cdots,m_K|\pmb\mu,N)&=N\text{diag}(\mu_1,\cdots,\mu_K)-N\pmb\mu\pmb\mu^T \end{aligned} \]
2.2 Dirichlet分布
现在我们考虑多项式分布的先验分布的形式。考虑到多项式分布正比于一系列参数\(\mu_k\)的幂指数、或者统一起来说正比于参数\(\pmb\mu\)中每个元素各自的幂指数,因此为了保证先验分布和后验分布的共轭性,多项式分布的先验分布的形式为
\[\text{Dir}(\pmb\mu|\pmb\alpha)=\frac{\Gamma(\alpha_0)}{\Gamma(\alpha_1)\Gamma(\alpha_2)\cdots\Gamma(\alpha_K)}\prod_{k=1}^K\mu_k^{\alpha_k-1} \]
其中\(\sum_{k=1}^K\mu_k=1\),\(\pmb\alpha=(\alpha_1,\alpha_2,\cdots,\alpha_K)^T\)且\(\alpha_0=\sum_{k=1}^K\alpha_k\),该分布被称为Dirichlet分布。可以得到
\[\begin{aligned} E(\pmb\mu|\pmb\alpha)&=(\frac{\alpha_1}{\alpha_0},\frac{\alpha_2}{\alpha_0},\cdots,\frac{\alpha_K}{\alpha_0})^T=(\tilde{\alpha_1},\tilde{\alpha_2},\cdots,\tilde{\alpha_K})^T\\ \text{var}(\pmb\mu|\pmb\alpha)&=(\frac{\alpha_1(\alpha_0-\alpha_1)}{\alpha_0^2(\alpha_0+1)},\frac{\alpha_2(\alpha_0-\alpha_2)}{\alpha_0^2(\alpha_0+1)},\cdots,\frac{\alpha_K(\alpha_0-\alpha_K)}{\alpha_0^2(\alpha_0+1)})^T\\ &=(\frac{\tilde{\alpha_1}(1-\tilde{\alpha_1})}{\alpha_0+1},\frac{\tilde{\alpha_2}(1-\tilde{\alpha_2})}{\alpha_0+1},\cdots,\frac{\tilde{\alpha_K}(1-\tilde{\alpha_K})}{\alpha_0+1})^T\\ \text{cov}(\pmb\mu|\pmb\alpha)&=\frac{1}{\alpha_0^2(\alpha_0+1)}\text{diag}(\alpha_0,\alpha_0,\cdots,\alpha_0)\cdot\text{diag}(\alpha_1,\alpha_2,\cdots,\alpha_K)-\pmb\mu\pmb\mu^T\\ &=\frac{1}{\alpha_0+1}\text{diag}(\tilde{\alpha_1},\tilde{\alpha_2},\cdots,\tilde{\alpha_K})-\pmb\mu\pmb\mu^T \end{aligned} \]
那么,参数\(\pmb\mu\)的后验分布\(p(\pmb\mu|D,\pmb\alpha)\)满足
\[p(\pmb\mu|D,\pmb\alpha)\varpropto p(D|\pmb\mu)\cdot p(\pmb\mu|\pmb\alpha)\varpropto\prod_{k=1}^K\mu_k^{m_k}\cdot\prod_{k=1}^K\mu^{\alpha_k-1}=\prod_{k=1}^K\mu_k^{m_k+\alpha_k-1} \]
和Dirichlet分布的标准形式相比,很快得到归一化系数,于是就有
\[p(\pmb\mu|D,\pmb\alpha)=\frac{\Gamma(\alpha_0+N)}{\Gamma(\alpha_1+m_1)\Gamma(\alpha_2+m_2)\cdots\Gamma(\alpha_K+m_K)}\prod_{k=1}^K\mu_k^{m_k+\alpha_k-1} \]
此时可以分析各项参数实际表示的含义,其含义与Beta分布中各参数的直观解释类似,此处不再讨论。
3 高斯分布
先给出一维变量\(x\)和\(D\)维变量\(\mathbf{x}\)情况下的高斯分布通用形式
\[\begin{aligned} \mathcal N(x|\mu,\sigma^2)&=\frac{1}{(2\pi\sigma^2)^{1/2}}\text{exp}\{-\frac{1}{2\sigma^2}(x-\mu)^2\}\\ \mathcal N(\mathbf{x}|\pmb\mu,\mathbf{\Sigma})&=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\mathbf{\Sigma}|^{1/2}}\text{exp}\{-\frac12(\mathbf{x}-\pmb\mu)^T{\mathbf{\Sigma}}^{-1}(\mathbf{x}-\pmb\mu)\} \end{aligned} \]
其中\(\mathbf{\Sigma}\)是一个\(D\times D\)的协方差矩阵。高斯分布是十分重要的,由中心极限定理知道,现实生活中很多情形都会推导出高斯分布。下面将从矩阵角度对熟知的高斯分布的一些性质进行重新推导,这不仅有利于将高斯分布从一元情形推广到多元情形,而且有利于理解后续章节的关键概念。
3.1 高斯分布的矩阵视角
从上面多元形式的高斯分布可以看出,多元高斯分布中对\(\mathbf{x}\)的依赖是通过二次型
\[\Delta^2=(\mathbf{x}-\pmb\mu)^T\mathbf{\Sigma}^{-1}(\mathbf{x}-\pmb\mu) \]
实现的,\(\Delta\)被称为马氏距离(Mahalanobis distance),当\(\mathbf{\Sigma}\)为单位矩阵时,马氏距离就退化为欧氏距离。如果在一个关于\(\mathbf{x}\)的空间中,马氏距离是常数,那么此时的多元高斯分布亦是常数。
对于矩阵\(\mathbf{\Sigma}\)的形式,我们不妨设其为对称矩阵,这是因为任何非对称项都会从多元高斯分布的指数项中消失,下面给出证明。记\(\Delta^2=(x-\mu)^T\mathbf{A}(x-\mu)\),其中\(\mathbf{A}=\mathbf{\Sigma}^{-1}\),接着令\(\mathbf{A}=\frac{1}{2}(\mathbf{A}+\mathbf{A}^T)+\frac{1}{2}(\mathbf{A}-\mathbf{A}^T)\)以及\(\mathbf{B}=\frac{1}{2}(\mathbf{A}+\mathbf{A}^T)\),\(\mathbf{C}=\frac{1}{2}(\mathbf{A}-\mathbf{A}^T)\),那么矩阵\(\mathbf{B}\)就是对称矩阵(即有\(b_{ij}=b_{ji}\)),而矩阵\(\mathbf{C}\)是反对称矩阵(即有\(c_{ij}=-c_{ji}\))且\(\mathbf{A}=\mathbf{B}+\mathbf{C}\)。现在将\(\Delta^2\)重新写作
\[\begin{aligned} \Delta^2&=(\mathbf{x}-\pmb\mu)^T(\mathbf{B}+\mathbf{C})(\mathbf{x}-\pmb\mu)\\ &=(\mathbf{x}-\pmb\mu)^T\mathbf{B}(\mathbf{x}-\pmb\mu)+(\mathbf{x}-\pmb\mu)^T\mathbf{C}(\mathbf{x}-\pmb\mu) \end{aligned} \]
现在如果能证明\((\mathbf{x}-\pmb\mu)^T\mathbf{C}(\mathbf{x}-\pmb\mu)=0\),则说明了任何非对称项都会从多元高斯分布的指数项中消失,事实证明确实如此,推导过程如下
\[\begin{aligned} (\mathbf{x}-\pmb\mu)^T\mathbf{C}(\mathbf{x}-\pmb\mu)&=(x_1-\mu_1,\cdots,x_D-\mu_D)\cdot \left( \begin{array} {ccc} c_{11}&\cdots&c_{1D}\\ \vdots& &\vdots\\ c_{D1}&\cdots&c_{DD} \end{array} \right) \cdot \left( \begin{array} {c} x_1-\mu_1\\ \vdots\\ x_D-\mu_D \end{array} \right)\\ &=\sum_{i=1}^D\sum_{j=1}^Dc_{ij}(x_i-\mu_i)(x_j-\mu_j)\\ &=\sum_{i=1}^D\sum_{j=i+1}^D(c_{ij}+c_{ji})(x_i-\mu_i)(x_j-\mu_j)\\ &=0 \end{aligned} \]
这就说明了\(\Delta^2=(\mathbf{x}-\pmb\mu)^T\mathbf{B}(\mathbf{x}-\pmb\mu)\),也就是任何非对称项都会从多元高斯分布的指数项中消失,在后续讨论中,我们默认矩阵\(\mathbf{\Sigma}\)是对称矩阵。
对于协方差矩阵\(\mathbf{\Sigma}\),考虑其特征方程\(\mathbf{\Sigma}\mathbf{u}_i=\lambda\mathbf{u}_i\),由于\(\mathbf{\Sigma}\)是实对称矩阵,那么其特征值也是实数,且其特征向量可以被选为单位正交的(即\(\mathbf{u}_i^T\mathbf{u}_j=\delta_{ij}\)),则协方差矩阵可以写作展开的形式
\[\mathbf{\Sigma}=\sum_{i=1}^D\lambda_i\mathbf{u}_i\mathbf{u}_i^T \]
下面给出该结论的证明。首先构造矩阵\(\mathbf{U}=(\mathbf{u}_1,\cdots,\mathbf{u}_D)\),即其中的每一列是特征向量,该矩阵满足\(\mathbf{U}\mathbf{U}^T=\mathbf{I}\)(或者等价条件\(\mathbf{U}^T\mathbf{U}=\mathbf{I}\)或\(\mathbf{U}^{-1}=\mathbf{U}^T\)),因此称为正交矩阵(orthogonal matrix),根据线性代数知识有\(\mathbf{\Sigma}\mathbf{U}=\mathbf U\mathbf \Lambda\),那么
\[\mathbf\Sigma\mathbf U=\mathbf U\mathbf \Lambda=(\mathbf{u}_1,\cdots,\mathbf{u}_D) \left( \begin{array} {ccc} \lambda_1&&\\ &\ddots&\\ &&\lambda_D \end{array} \right) =(\lambda_1\mathbf{u}_1,\cdots,\lambda_D\mathbf{u}_D) \]
因此
\[\mathbf\Sigma=\mathbf U\mathbf\Lambda\mathbf U^{-1}=\mathbf U\mathbf\Lambda\mathbf U^{T} =(\lambda_1\mathbf{u}_1,\cdots,\lambda_D\mathbf{u}_D) \left( \begin{array} {c} \mathbf{u}_1^T\\ \vdots\\ \mathbf{u}_D^T \end{array} \right) =\sum_{i=1}^D\lambda_i\mathbf{u}_i\mathbf{u}_i^T \]
因此\(\mathbf \Sigma=\sum_{i=1}^D\lambda_i\mathbf{u}_i\mathbf{u}_i^T\)得证。而在\(\mathbf\Sigma\mathbf U=\mathbf U\mathbf\Lambda\)两侧同时取逆矩阵得到\(\mathbf U^{-1}\mathbf\Sigma^{-1}=\mathbf\Lambda^{-1}\mathbf U^{-1}\),进而
\[\mathbf\Sigma^{-1}=(\mathbf U^{-1})^{-1}\mathbf\Lambda\mathbf U^{-1}=\mathbf U\mathbf\Lambda^{-1}\mathbf U^T=\sum_{i=1}^D\frac{1}{\lambda_i}\mathbf{u}_i\mathbf{u}_i^T \]
将此式代入二次型\(\Delta^2=(\mathbf{x}-\pmb\mu)^T\mathbf\Sigma^{-1}(\mathbf{x}-\pmb\mu)\)中得到
\[\Delta^2=\sum_{i=1}^D\frac{1}{\lambda_i}(\mathbf{x}-\pmb\mu)^T\mathbf{u}_i\mathbf{u}_i^T(\mathbf{x}-\pmb\mu)=\sum_{i=1}^D\frac{y_i^2}{\lambda_i},\quad y_i=\mathbf{u}_i^T(\mathbf{x}-\pmb\mu) \]
如果二次型的值为常数且所有的特征值\(\lambda_i\)为正数,那么该二次型可以视为一个椭球面,椭球中心位于\(\pmb\mu\)处,但是该椭球的各轴可能不沿着\(\mathbf{u}_i\)方向,该式的意义就在于给出了一组新的基底\(\mathbf{y}=\mathbf U(\mathbf{x}-\pmb\mu)\),使得椭球在此坐标系下的中心位于\((0,0,\cdots,0)^T\)处,且各轴的方向沿着\(\mathbf{u}_i\)方向,缩放因子为\(\lambda_i^{1/2}\)。在后面的“高斯分布的矩”一节中,将使用Dirac符号对此结论再给出一个推导。
如果一个矩阵的特征值全为正数,则称此矩阵正定的(positive definite);如果一个矩阵的特征值全为非负数,则称此矩阵是半正定的(positive semidefinite)。对于任意形式的高斯分布而言,其协方差矩阵必须是正定的。
对于新的基底\(\mathbf{y}=\mathbf U(\mathbf{x}-\pmb\mu)\)而言,高斯分布的形式又当如何?先定义Jacobian矩阵如下
\[\mathbf J= \left( \begin{array} {ccc} \frac{\partial x_1}{\partial y_1}&\cdots&\frac{\partial x_1}{\partial y_D}\\ \vdots&&\vdots\\ \frac{\partial x_D}{\partial y_1}&\cdots&\frac{\partial x_D}{\partial y_D} \end{array} \right) =\mathbf U^T \]
且有\(|\mathbf J|^2=|\mathbf U^T|^2=|\mathbf U^T||\mathbf U^T|=|\mathbf U^T||\mathbf U|=|\mathbf U^T\mathbf U|=|\mathbf I|=1\),以及\(|\mathbf\Sigma|=\prod_{i=1}^D\lambda_i^{1/2}\),所以
\[p(\mathbf{y})=p(\mathbf{x})|\mathbf J|=\prod_{i=1}^D\frac{1}{(2\pi\lambda_i)^{1/2}}\text{exp}\{-\frac{y_i^2}{2\lambda_i}\} \]
该式也可以理解为\(p(\mathbf{y})=\prod_{i=1}^Dp(y_i)\)。注意,在任意的坐标变换中,Jacobian矩阵都是十分重要的,它决定了坐标变换后整体的“放缩程度”。
3.2 题外话——Dirac符号
作为拓展内容,现在简要介绍首先Dirac符号的概念。Dirac符号是构成现代量子力学形式体系的重要组成部分,由Dirac在1939年提出,Dirac将“括号(bracket)”一词一分为二,得到的两个单词分别代表左右矢量。对于复向量空间\(\mathbb C^n\),其中的任意一个元素(列向量)记为
\[|u\rangle= \left( \begin{array} {c} x_1\\ \vdots\\ x_n \end{array} \right) \qquad\text{或}\qquad |u\rangle=(x_1,\cdots,x_n)^T \]
(其中\(x_i\in\mathbb C\))称为右矢(ket vector or ket),可以定义右矢的加法和数乘运算、并且可以引入线性相关与线性无关等概念,这和线性代数是一样的,此处不再单独叙述。而任意的行向量
\[\langle\alpha|=(\alpha_1,\cdots,\alpha_n) \]
(其中\(\alpha_i\in\mathbb C\))称为左矢(bra vector or bra)。并且右矢和左矢的乘积\(\langle\alpha|x\rangle=\sum_{i=1}^n\alpha_ix_i\)称为内积(inner product)。这样,如果保持左矢不变,通过内积运算便将\(\mathbb C^n\)中的任意元素\(|x\rangle\)映射到了\(\mathbb C\)中的某个元素\(\langle\alpha|x\rangle\),这可以看成是一种向量函数。如果在保持左矢不变的情况下,记此时的内积为一个从\(\mathbb C^n\)到\(\mathbb C\)的向量函数\(f\),且\(f\)满足线性条件(linearity condition),即
\[f(c_1|x\rangle+c_2|y\rangle)=c_1f(|x\rangle)+c_2f(|y\rangle),\\ \forall|x\rangle,|y\rangle\in\mathbb C^n,\forall c_1,c_2\in\mathbb C \]
那么称此时的\(f\)为线性函数(linear function)。容易验证,一个左矢和内积运算便构成了一个这样的\(f\)。并且,通过选取合适的左矢,可以表示出任何从\(\mathbb C^n\)到\(\mathbb C\)的线性函数,因为当一个线性函数作用在一个右矢上的时候,从内积运算的定义便知道它给出的结果\(f(|x\rangle)\)总是形如\(\langle\alpha|x\rangle=\sum_{i=1}^n\alpha_ix_i\),那么\(\langle\alpha|\)便可以代表此时的线性函数。在线性代数中我们学过:一组正交基(的线性组合)可以用来表示一个线性空间。对于向量空间来说,选取\(\mathbb C^n\)中的单位正交向量组\(\{|u_1\rangle,\cdots,|u_n\rangle\}\),则其满足\(\langle u_i|u_j\rangle=\delta_{ij}\),且\(\mathbb C^n\)中任意向量\(|x\rangle\)可以表示为\(\sum_{i=1}^nc_i|u_i\rangle\),在等式两侧进行内积运算便得到
\[\langle u_j|x\rangle=\sum_{i=1}^nc_i\langle e_j|u_i\rangle=\sum_{i=1}^nc_i\delta_{ij}=c_j \]
即有\(c_j=\langle u_j|x\rangle\),这给出了各个坐标的计算公式,将其代入\(|x\rangle\)的表达式便有
\[|x\rangle=\sum_{i=1}^nc_i|u_i\rangle=\sum_{i=1}^n\langle u_i|x\rangle|u_i\rangle=\sum_{i=1}^n|u_i\rangle\langle u_i|x\rangle= \left( \sum_{i=1}^n|u_i\rangle\langle u_i| \right) |x\rangle \]
于是便得到一个重要的关系式
\[\sum_{i=1}^n|u_i\rangle\langle u_i|=\mathbf I \]
该关系式称为完备性关系(completeness relation)。
最后介绍一个概念:投影算子(projection operator)被定义为\(P_k=|u_k\rangle\langle u_k|\),其含义是对任意向量\(|v\rangle\)左乘投影算子,必然得到该向量\(|v\rangle\)在方向\(|u_k\rangle\)上的分量,这是针对向量空间的讨论,向量空间是线性空间最简单的形式。对于矩阵空间来说,该空间仍然是线性空间(因为满足线性空间的八条原则),因此亦可以选择若干基底矩阵来生成该空间。对于\(D\times D\)矩阵而言,至多用\(D^2\)个基底矩阵便可以描述该矩阵空间。特别地,在之前的内容中,我们已经证明一个矩阵可以写成其特征向量的展开的形式,因此一组\(|u_k\rangle\langle u_k|\)总能够用来表示某一个特定的矩阵,即
\[\mathbf\Sigma=\sum_{i=1}^D\lambda_i|u_i\rangle\langle u_i| \]
其中\(\lambda_i|u_i\rangle\langle u_i|\)可认为是基底\(|u_i\rangle\langle u_i|\)上的分量。
Dirac符号的一个简单用途就是速记代数形式对应的具体结构:\(\langle\cdots\rangle\)对应的是具体的数;\(\langle\cdots|\)对应的是行向量;\(|\cdots\rangle\)对应的是列向量;\(|\cdots|\)对应的是矩阵(方阵)。
3.3 题外话——矩阵微分
现在来介绍矩阵微分的概念。给定向量\(\mathbf{a}\)和\(\mathbf{b}\)以及标量\(x\)、向量\(\mathbf{x}\)和矩阵\(\mathbf A\)与\(\mathbf B\),则有以下重要定义
\[\begin{aligned} \frac{\partial\text{标量}}{\partial\text{标量}}&\qquad \text{略}\\ \frac{\partial\text{标量}}{\partial\text{向量}}&\qquad (\frac{\partial x}{\partial\mathbf{a}})_i=\frac{\partial x}{\partial a_i}\\ \frac{\partial\text{标量}}{\partial\text{矩阵}}&\qquad \frac{\partial x}{\partial \mathbf A}= \left( \begin{array} {cccc} \frac{\partial x}{\partial A_{11}}&\frac{\partial x}{\partial A_{12}}&\cdots&\frac{\partial x}{\partial A_{1n}}\\ \frac{\partial x}{\partial A_{21}}&\frac{\partial x}{\partial A_{22}}&\cdots&\frac{\partial x}{\partial A_{2n}}\\ \vdots&\vdots&&\vdots\\ \frac{\partial x}{\partial A_{n1}}&\frac{\partial x}{\partial A_{n2}}&\cdots&\frac{\partial x}{\partial A_{nn}} \end{array} \right) \\ \frac{\partial\text{向量}}{\partial\text{标量}}&\qquad (\frac{\partial\mathbf{a}}{\partial x})_i=\frac{\partial a_i}{\partial x}\\ \frac{\partial\text{向量}}{\partial\text{向量}}&\qquad (\frac{\partial\mathbf{a}}{\partial\mathbf{b}})_{ij}=\frac{\partial a_i}{\partial b_j}\\ \frac{\partial\text{向量}}{\partial\text{矩阵}}&\qquad \text{无}\\ \frac{\partial\text{矩阵}}{\partial\text{标量}}&\qquad \frac{\partial \mathbf A}{\partial x}= \left( \begin{array} {cccc} \frac{\partial A_{11}}{\partial x}&\frac{\partial A_{12}}{\partial x}&\cdots&\frac{\partial A_{1n}}{\partial x}\\ \frac{\partial A_{21}}{\partial x}&\frac{\partial A_{22}}{\partial x}&\cdots&\frac{\partial A_{2n}}{\partial x}\\ \vdots&\vdots&&\vdots\\ \frac{\partial A_{n1}}{\partial x}&\frac{\partial A_{n2}}{\partial x}&\cdots&\frac{\partial A_{nn}}{\partial x} \end{array} \right) \\ \frac{\partial\text{矩阵}}{\partial\text{向量}}&\qquad \text{无}\\ \frac{\partial\text{矩阵}}{\partial\text{矩阵}}&\qquad \text{无}\\ \end{aligned} \]
容易得到下面的结论
\[\begin{aligned} (\text{i})&\quad\frac{\partial}{\partial\mathbf{x}}(\mathbf{x}^T\mathbf{a})=\frac{\partial}{\partial\mathbf{x}}(\mathbf{a}^T\mathbf{x})=\mathbf{a}\\ (\text{ii})&\quad\frac{\partial}{\partial\mathbf{x}}(\mathbf A\mathbf B)=\frac{\partial \mathbf A}{\partial\mathbf{x}}\mathbf B+\mathbf A\frac{\partial \mathbf B}{\partial\mathbf{x}}\\ (\text{iii})&\quad\frac{\partial}{\partial x}(\mathbf A^{-1})=-\mathbf A^{-1}\frac{\partial \mathbf A}{\partial x}\mathbf A^{-1}\\ (\text{iv})&\quad\frac{\partial}{\partial x}\ln|\mathbf A|=\text{Tr}(\mathbf A^{-1}\frac{\partial\mathbf A}{\partial x})\\ (\text{v})&\quad\frac{\partial}{\partial A_{ij}}\text{Tr}(\mathbf A\mathbf B)=B_{ji}\\ (\text{vi})&\quad\frac{\partial}{\partial\mathbf A}\text{Tr}(\mathbf A\mathbf B)=\mathbf B^T\\ (\text{vii})&\quad\frac{\partial}{\partial\mathbf A}\text{Tr}(\mathbf A^T\mathbf B)=\mathbf B\\ (\text{viii})&\quad\frac{\partial}{\partial\mathbf A}\text{Tr}(\mathbf A)=\mathbf I\\ (\text{ix})&\quad\frac{\partial}{\partial\mathbf A}\text{Tr}(\mathbf A\mathbf B\mathbf A^T)=\mathbf A(\mathbf B+\mathbf B^T)\\ (\text{x})&\quad\frac{\partial}{\partial\mathbf A}\ln|\mathbf A|=(\mathbf A^{-1})^T \end{aligned} \]
3.4 高斯分布的矩
在多元高斯分布中,我们从矩阵视角来分析矩。对于多元高斯分布
\[\mathcal N(\mathbf{x}|\pmb\mu,\mathbf\Sigma)=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\mathbf\Sigma|^{1/2}}\text{exp}\{-\frac12(\mathbf{x}-\pmb\mu)^T{\mathbf\Sigma}^{-1}(\mathbf{x}-\pmb\mu)\} \]
来说,它的一阶矩为
\[\begin{aligned} E(\mathbf{x})=\int\mathcal N(\mathbf{x}|\pmb\mu,\mathbf\Sigma)\mathbf{x}d\mathbf{x}&=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\mathbf\Sigma|^{1/2}}\int\text{exp}\{-\frac12(\mathbf{x}-\pmb\mu)^T{\mathbf\Sigma}^{-1}(\mathbf{x}-\pmb\mu)\}\mathbf{x}d\mathbf{x}\\ &=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\mathbf\Sigma|^{1/2}}\int\text{exp}\{-\frac{1}{2}\mathbf{z}^T\mathbf\Sigma^{-1}\mathbf{z}\}(\mathbf{z}+\pmb\mu)d(\mathbf{z}+\pmb\mu)\\ &=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\mathbf\Sigma|^{1/2}}\int(\text{exp}\{-\frac{1}{2}\mathbf{z}^T\mathbf\Sigma^{-1}\mathbf{z}\}\mathbf{z}+\text{exp}\{-\frac{1}{2}\mathbf{z}^T\mathbf\Sigma^{-1}\mathbf{z}\}\pmb\mu)d\mathbf{z} \end{aligned} \]
由于指数部分是关于\(\mathbf{z}\)的偶函数且整个积分区间为\((-\infty,+\infty)\),因此\(\text{exp}\{-\frac{1}{2}\mathbf{z}^T\mathbf\Sigma^{-1}\mathbf{z}\}\mathbf{z}\)部分关于\(\mathbf{z}\)的积分为零,故\(E(\mathbf{x})=\pmb\mu\),因此将其称为高斯分布的均值,这和我们的直观感觉是一致的。现在来看二阶矩。在一元情况下,二阶矩由\(E(x^2)\)给出。对于多元变量而言,有\(D^2\)个由\(E(x_i\cdot x_j)\)给出的二阶矩,可以聚在一起写成矩阵形式,即多元情况下的二阶矩为
\[\begin{aligned} E(\mathbf{x}\mathbf{x}^T)&=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\mathbf\Sigma|^{1/2}}\int\text{exp}\{-\frac12(\mathbf{x}-\pmb\mu)^T{\mathbf\Sigma}^{-1}(\mathbf{x}-\pmb\mu)\}\mathbf{x}\mathbf{x}^Td\mathbf{x}\\ &=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\mathbf\Sigma|^{1/2}}\int\text{exp}\{-\frac12\mathbf{z}^T{\mathbf\Sigma}^{-1}\mathbf{z}\}(\mathbf{z}+\pmb\mu)(\mathbf{z}+\pmb\mu)^Td\mathbf{z} \end{aligned} \]
注意到\((\mathbf{z}+\pmb\mu)(\mathbf{z}+\pmb\mu)^T=(\mathbf{z}+\pmb\mu)(\mathbf{z}^T+\pmb\mu^T)=\mathbf{z}\mathbf{z}^T+\mathbf{z}\pmb\mu^T+\pmb\mu\mathbf{z}^T+\pmb\mu\pmb\mu^T\),其中涉及到\(\mathbf{z}\pmb\mu^T\)和\(\pmb\mu\mathbf{z}^T\)的积分值都将因为对称性(和一元情况类似)而等于零,涉及到常数\(\pmb\mu\pmb\mu^T\)的积分值将等于\(\pmb\mu\pmb\mu^T\),下面讨论涉及到\(\mathbf{z}\mathbf{z}^T\)的积分值。取单位正交基\(\{|u_1\rangle,|u_2\rangle,\cdots,|u_D\rangle\}\)使得\(\mathbf\Sigma^{-1}=\sum_{i=1}^D\frac{1}{\lambda_i}|u_i\rangle\langle u_i|\),且\(|z\rangle=\sum_{i=1}^Dy_i|u_i\rangle\)(其中\(y_i=\langle u_i|z\rangle\)),那么有对于指数部分有
\[\begin{aligned} \mathbf{z}^T{\mathbf\Sigma}^{-1}\mathbf{z}&=\sum_{i=1}^D\langle u_i|z\rangle\langle u_i|\cdot\sum_{j=1}^D\frac{1}{\lambda_j}| u_j\rangle\langle u_j|\cdot\sum_{k=1}^D\langle u_k|z\rangle|u_k\rangle\\ &=\sum_{i=1}^D\sum_{j=1}^D\sum_{k=1}^D\frac{1}{\lambda_j}\langle u_i|z\rangle\langle u_i|u_j\rangle\langle u_j|u_k\rangle\langle u_k|z\rangle\\ &=\sum_{i=1}^D\sum_{j=1}^D\sum_{k=1}^D\frac{1}{\lambda_j}\langle u_i|z\rangle\delta_{ij}\delta_{jk}\langle u_k|z\rangle\\ &=\sum_{i=1}^D\frac{1}{\lambda_i}\langle u_i|z\rangle\langle u_i|z\rangle=\sum_{i=1}^D\frac{y_i^2}{\lambda_i}(=\mathbf{y}^T\mathbf\Lambda^{-1}\mathbf{y}) \end{aligned} \]
其中\(\mathbf{y}=(y_1,y_2,\cdots,y_D)^T\),故\(\mathbf{z}=\mathbf U\mathbf{y}\),其中\(\mathbf U=(|u_1\rangle~~|u_2\rangle~~\cdots~~|u_D\rangle)\)且\(|\mathbf U|=1\),于是有\(d\mathbf{z}=d\mathbf{y}\),进而
\[\begin{aligned} &\quad\frac{1}{(2\pi)^{D/2}}\frac{1}{|\mathbf\Sigma|^{1/2}}\int\text{exp}\{-\frac12\mathbf{z}^T{\mathbf\Sigma}^{-1}\mathbf{z}\}\mathbf{z}\mathbf{z}^Td\mathbf{z}\\ &=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\mathbf\Sigma|^{1/2}}\int\text{exp}\{-\frac12\sum_{k=1}^D\frac{y_k^2}{\lambda_k}\}\cdot(\sum_{i=1}^D\langle u_i|z\rangle|u_i\rangle)\cdot(\sum_{j=1}^D\langle u_j|z\rangle\langle u_j|)d\mathbf{y}\\ &=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\mathbf\Sigma|^{1/2}}\int\text{exp}\{-\frac12\sum_{k=1}^D\frac{y_k^2}{\lambda_k}\}\cdot\sum_{i=1}^D\sum_{j=1}^D\langle u_i|z\rangle\langle u_j|z\rangle|u_i\rangle\langle u_j|d\mathbf{y}\\ &=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\mathbf\Sigma|^{1/2}}\int\text{exp}\{-\frac12\sum_{k=1}^D\frac{y_k^2}{\lambda_k}\}\cdot\sum_{i=1}^D\sum_{j=1}^Dy_iy_j|u_i\rangle\langle u_j|d\mathbf{y}\\ &=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\mathbf\Sigma|^{1/2}}\sum_{i=1}^D\sum_{j=1}^D|u_i\rangle\langle u_j|\int\text{exp}\{-\frac12\sum_{k=1}^D\frac{y_k^2}{\lambda_k}\}\cdot y_iy_jd\mathbf{y}\\ &=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\mathbf\Sigma|^{1/2}}\sum_{i=1}^D|u_i\rangle\langle u_i|\int\text{exp}\{-\frac12\sum_{k=1}^D\frac{y_k^2}{\lambda_k}\}y_i^2d\mathbf{y}\\ &=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\mathbf\Sigma|^{1/2}}\sum_{i=1}^D|u_i\rangle\langle u_i|\iint\cdots\int\text{exp}\{-\frac12\sum_{k=1}^D\frac{y_k^2}{\lambda_k}\}y_i^2dy_1dy_2\cdots dy_D \end{aligned} \]
其中倒数第三个等号到倒数第二个等号的原因是:当\(i\neq j\)时,被积函数中必定有一项形如\(\text{exp}\{-\frac12y_i^2\}y_i\),而这是奇函数,且积分区间是\((-\infty,+\infty)\),因此会等于零。注意,关于矢量的积分应该化成上述多重积分的形式。上述积分可以拆成
\[\iint\cdots\int\text{exp}\{-\frac{y_1^2}{2\lambda_1}\}\cdot\text{exp}\{-\frac{y_2^2}{2\lambda_2}\}\cdots\text{exp}\{-\frac{y_D^2}{2\lambda_D}\}y_i^2dy_1dy_2\cdots dy_D \]
并且易证下述两个结论
\[\begin{aligned} \int\text{exp}\{-\frac{y_k^2}{2\lambda_k}\}dy_i&= \begin{cases} \begin{aligned} 0,\qquad\qquad\quad&k\neq i\\ (2\pi\lambda_i)^{1/2},\quad~~~&k=i \end{aligned} \end{cases}\\ \int\text{exp}\{-\frac{y_k^2}{2\lambda_k}\}y_i^2dy_j&= \begin{cases} \begin{aligned} 0,\qquad\qquad\quad&k\neq i~\text{or}~i\neq j\\ (2\pi\lambda_i)^{1/2}\lambda_i,\quad&k=i=j \end{aligned} \end{cases}\\ \end{aligned} \]
将这两个结论代入拆解之后的式子,并进行整理,便可以求出
\[E(\mathbf{x}\mathbf{x}^T)=\text{涉及到}\pmb\mu\pmb\mu^T\text{的积分值}+\text{涉及到}\mathbf{z}\mathbf{z}^T\text{的积分值}=\pmb\mu\pmb\mu^T+\mathbf\Sigma \]
当然,对于多项式变量情形的二阶矩,我们也可以求二阶中心矩,即为
\[\text{var}(\mathbf{x})=E((\mathbf{x}-E(\mathbf{x}))(\mathbf{x}-E(\mathbf{x})))=\mathbf\Sigma \]
这即为协方差矩阵。
一个协方差矩阵衡量了各变量之间的制约关系,如果协方差矩阵的自由参数越多、则描述的模型越复杂,如果协方差矩阵的自由参数越少、则描述的模型越简单。通常而言,一个任意的对称协方差矩阵有\(\frac{D(D+1)}{2}\)各自由参数,加之\(D\)个自由的\(\mu_1,\cdots,\mu_D\)参数,该模型共有\(\frac{D(D+3)}{2}\)个独立参数。如果协方差矩阵是对角矩阵,那么该模型共有\(2D\)个独立参数。如果进一步限制协方差矩阵为单位矩阵的倍数,即\(\mathbf\Sigma=\sigma^2\mathbf I\),则此时的协方差矩阵被称为是各向同性的(isotropic),此时模型共有\(D+1\)个独立参数。
3.5 条件高斯分布
条件分布就是已知部分信息的情况下的概率分布,对于多项式变量\(\mathbf{x}\)而言,将其分为两部分\(\mathbf{x}_a\)和\(\mathbf{x}_b\),即\(\left(\begin{array}{c}\mathbf{x}_a\\\mathbf{x}_b\end{array}\right)\),分别对应\(D\)个变量中的前\(M\)个变量后\(D-M\)个变量,那么此时的均值划分为\(\pmb\mu=\left(\begin{array}{c}\pmb\mu_a\\\pmb\mu_b\end{array}\right)\),协方差矩阵划分为\(\mathbf\Sigma=\left(\begin{array}{cc}\mathbf\Sigma_{aa}&\mathbf\Sigma_{ab}\\\mathbf\Sigma_{ba}&\mathbf\Sigma_{bb}\end{array}\right)\),注意\(\mathbf\Sigma_{ba}=\mathbf\Sigma_{ab}^T\),并且\(\mathbf\Sigma_{aa}\)和\(\mathbf\Sigma_{bb}\)都是对称的。在之前我们已经多次使用\(\mathbf\Sigma^{-1}\)这个矩阵,现在对其命名如下
\[\mathbf\Lambda\equiv\mathbf\Sigma^{-1} \]
这被称为精度矩阵(precision matrix),并且此时有\(\mathbf\Lambda=\left(\begin{array}{cc}\mathbf\Lambda_{aa}&\mathbf\Lambda_{ab}\\\mathbf\Lambda_{ba}&\mathbf\Lambda_{bb}\end{array}\right)\),当然\(\mathbf\Lambda_{ba}=\mathbf\Lambda_{ab}^T\)并且\(\mathbf\Lambda_{aa}\)和\(\mathbf\Lambda_{bb}\)都是对称的。
现在来寻找条件概率分布\(p(\mathbf{x}_a|\mathbf{x}_b)\)的表达式。对于二次型\(\Delta^2\)而言
\[\begin{aligned} \Delta^2=&-\frac12(\mathbf{x}-\pmb\mu)^T\mathbf\Sigma^{-1}(\mathbf{x}-\pmb\mu)\\ =&-\frac12(\mathbf{x}_a-\pmb\mu_a)^T\mathbf\Lambda_{aa}(\mathbf{x}_a-\pmb\mu_a)-\frac12(\mathbf{x}_a-\pmb\mu_a)^T\mathbf\Lambda_{ab}(\mathbf{x}_b-\pmb\mu_b)\\ &-\frac12(\mathbf{x}_b-\pmb\mu_b)^T\mathbf\Lambda_{ba}(\mathbf{x}_a-\pmb\mu_a)-\frac12(\mathbf{x}_b-\pmb\mu_b)^T\mathbf\Lambda_{bb}(\mathbf{x}_b-\pmb\mu_b) \end{aligned} \]
若将此二次型视为\(\mathbf{x}_a\)的函数,则这又是一个二次型,因此对应的分布\(p(\mathbf{x}_a|\mathbf{x}_b)\)亦是一个高斯分布。由于任意二次型可以重新写为
\[\begin{aligned} \Delta^2&=-\frac12\mathbf{x}^T\mathbf\Sigma^{-1}\mathbf{x}+\frac12\mathbf{x}^T\mathbf\Sigma^{-1}\pmb\mu+\frac12\pmb\mu^T\mathbf\Sigma^{-1}\mathbf{x}+\text{对于}\mathbf{x}\text{而言是常数}\\ &=\frac12\mathbf{x}^T\mathbf\Sigma^{-1}\mathbf{x}+\mathbf{x}^T\mathbf\Sigma^{-1}\pmb\mu+\text{对于}\mathbf{x}\text{而言是常数} \end{aligned} \]
根据Dirac符号,\(\langle x|\pmb\Sigma^{-1}|\pmb\mu\rangle\)和\(\langle\pmb\mu|\pmb\Sigma^{-1}|\mathbf{x}\rangle\)均为实数且两式互为转置关系,而实数的转置是它本身,因此两项可以合并。现在,只要将任意二次型整理成上述形式,就能在一次项中直接看出均值\(\pmb\mu\)、在二次项中直接看出精度矩阵\(\mathbf\Lambda\)(即协方差矩阵\(\mathbf\Sigma\)的逆矩阵),而条件概率分布的二次型可以写为
\[\Delta^2=-\frac12\mathbf{x}_a^T\mathbf\Lambda_{aa}\mathbf{x}_{a}+\mathbf{x}_a^T\mathbf\Lambda_{aa}(\pmb\mu_a-\mathbf\Lambda_{aa}^{-1}\mathbf\Lambda_{ab}(\mathbf{x}_b-\pmb\mu_b))+\text{对于}\mathbf{x}_a\text{而言是常数} \]
因此条件概率分布\(p(\mathbf{x}_a|\mathbf{x}_b)\)的均值和协方差矩阵分别为
\[\begin{aligned} \pmb\mu_{a|b}&=\pmb\mu_a-\mathbf\Lambda_{aa}^{-1}\mathbf\Lambda_{ab}(\mathbf{x}_b-\pmb\mu_b)\\ \mathbf\Sigma_{a|b}&=\mathbf\Lambda_{aa}^{-1} \end{aligned} \]
从上面的过程中可以看出,使用精度矩阵是十分方便的,对于分块矩阵的逆与各个分块的关系,有如下等式
\[\left( \begin{array} {cc} \mathbf A&\mathbf B\\ \mathbf C&\mathbf D \end{array} \right)^{-1}= \left( \begin{array} {cc} \mathbf M&-\mathbf M\mathbf B\mathbf D^{-1}\\ -\mathbf D^{-1}\mathbf C\mathbf M&\mathbf D^{-1}+\mathbf D^{-1}\mathbf C\mathbf M\mathbf B\mathbf D^{-1} \end{array} \right) \]
其中\(\mathbf M=(\mathbf A-\mathbf B\mathbf D^{-1}\mathbf C)^{-1}\),并且称\(\mathbf M^{-1}\)为左侧矩阵关于子矩阵\(\mathbf D\)的舒尔补(Schur complement)。用该等式可以求得条件概率分布\(p(\mathbf{x}_a|\mathbf{x}_b)\)的均值和协方差矩阵的另一种形式
\[\begin{aligned} \pmb\mu_{a|b}&=\pmb\mu_a+\mathbf\Sigma_{ab}\mathbf\Sigma_{bb}^{-1}(\mathbf{x}_b-\pmb\mu_b)\\ \mathbf\Sigma_{a|b}&=\mathbf\Sigma_{aa}-\mathbf\Sigma_{ab}\mathbf\Sigma_{bb}^{-1}\mathbf\Sigma_{ba} \end{aligned} \]
从上面可以看出,条件概率分布的均值仅与\(\mathbf{x}_b\)线性相关且协方差与\(\mathbf{x}_b\)无关,这是线性高斯(linear-Gaussian)模型的一个例子。
3.6 边缘高斯分布
当给定联合分布\(p(\mathbf{x}_a,\mathbf{x}_b)\)的时候,依照上面的办法可以求出\(p(\mathbf{x}_b|\mathbf{x}_a)\),现在来考虑边缘分布
\[p(\mathbf{x}_a)=\int p(\mathbf{x}_a,\mathbf{x}_b)d\mathbf{x}_b \]
显然边缘分布亦是高斯分布,现在的任务就是求出边缘高斯分布的均值和协方差矩阵。先提取出其中关于\(\mathbf{x}_b\)的项,对二次型\(\Delta^2\)进行整理得到
\[\begin{aligned} \Delta^2&=-\frac12\mathbf{x}_b^T\mathbf\Lambda_{bb}\mathbf{x}_b+\mathbf{x}_b^T\mathbf{m}+\text{对于}\mathbf{x}_b\text{而言是常数}\\ &=-\frac12(\mathbf{x}_b-\mathbf\Lambda_{bb}^{-1}\mathbf{m})^T\mathbf\Lambda_{bb}(\mathbf{x}_b-\mathbf\Lambda_{bb}^{-1}\mathbf{m})+\frac12\mathbf{m}^T\mathbf\Lambda_{bb}^{-1}\mathbf{m}+\text{对于}\mathbf{x}_b\text{而言是常数} \end{aligned} \]
其中\(\mathbf{m}=\mathbf\Lambda_{bb}\pmb\mu_b-\mathbf\Lambda_{ba}(\mathbf{x}_a-\pmb\mu_{a})\)。若取上式右侧第一项,就将被积函数整理成了关于\(\mathbf{x}_b\)的标准形式,此积分值的结果是归一化系数的倒数,从\(N(\mathbf{x}|\pmb\mu,\mathbf\Sigma)=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\mathbf\Sigma|^{1/2}}\text{exp}\{-\frac12(\mathbf{x}-\pmb\mu)^T{\mathbf\Sigma}^{-1}(\mathbf{x}-\pmb\mu)\}\)中可知均值与协方差和归一化系数无关,因此不影响讨论。现在把上式右侧第二项与对于\(\mathbf{x}_b\)而言是常数的项合并得到
\[\begin{aligned} &\quad\frac12\mathbf{m}^T\mathbf\Lambda_{bb}^{-1}\mathbf{m}-\frac12\mathbf{x}_a^T\mathbf\Lambda_{aa}\mathbf{x}_a+\mathbf{x}_a^T(\mathbf\Lambda_{aa}\pmb\mu_{a}+\mathbf\Lambda_{ab}\pmb\mu_b)+\text{对于}\mathbf{x}_a\text{和}\mathbf{x}_b\text{而言是常数}\\ &=-\frac12\mathbf{x}_a^T(\mathbf\Lambda_{aa}-\mathbf\Lambda_{ab}\mathbf\Lambda_{bb}^{-1}\mathbf\Lambda_{ba})\mathbf{x}_a+\mathbf{x}_a^T(\mathbf\Lambda_{aa}-\mathbf\Lambda_{ab}\mathbf\Lambda_{bb}^{-1}\mathbf\Lambda_{ba})\pmb\mu_a+\text{对于}\mathbf{x}_a\text{和}\mathbf{x}_b\text{而言是常数} \end{aligned} \]
与高斯分布的标准形式相比,可以看到边缘分布\(p(\mathbf{x}_a)\)的均值和协方差分别由下面两式给出
\[\mathbf\Sigma_a=(\mathbf\Lambda_{aa}-\mathbf\Lambda_{ab}\mathbf\Lambda_{bb}^{-1}\mathbf\Lambda_{ba})^{-1}\\ \mathbf\Sigma_a(\mathbf\Lambda_{aa}-\mathbf\Lambda_{ab}\mathbf\Lambda_{bb}^{-1}\mathbf\Lambda_{ba})\pmb\mu_a=\pmb\mu_a \]
使用关于分块矩阵逆的恒等式有\((\mathbf\Lambda_{aa}-\mathbf\Lambda_{ab}\mathbf\Lambda_{bb}^{-1}\mathbf\Lambda_{ba})^{-1}=\mathbf\Sigma_{aa}\),因此
\[\begin{aligned} E(\mathbf{x}_a)&=\pmb\mu_a\\ \text{cov}(\mathbf{x}_a)&=\mathbf\Sigma_{aa} \end{aligned} \]
在条件高斯分布中,用分块精度矩阵表示均值和协方差更加简便,但是对于边缘高斯分布而言,采用分块协方差矩阵更加简便。在条件高斯分布中,我们只需要分离出唯一变量\(\mathbf{x}_a\),剩下的所有部分(包括\(\mathbf{x}_b\))都可以认为是已知的、可以用在均值和协方差表达式中的;但是在边缘高斯分布中,两个变量\(\mathbf{x}_a\)和\(\mathbf{x}_b\)是平等的、都是未知的,因此变量\(\mathbf{x}_a\)的均值和协方差的表达式中不能出现\(\mathbf{x}_b\),所以先分离出变量\(\mathbf{x}_b\),再分离出\(\mathbf{x}_a\)就可以求解,注意,这里的变量分离顺序不能改变。
3.7 高斯变量的贝叶斯定理
现在给出如下形式的边缘高斯分布和条件高斯分布
\[\begin{aligned} p(\mathbf{x})&=N(\mathbf{x}|\pmb\mu,\mathbf\Lambda^{-1})\\ p(\mathbf{y}|\mathbf{x})&=N(\mathbf{y}|\mathbf A\mathbf{x}+\mathbf{b},\mathbf L^{-1}) \end{aligned} \]
其中,如果\(\mathbf{x}\)的维度为\(M\)、\(\mathbf{y}\)的维度为\(D\),那么矩阵\(\mathbf A\)的大小为\(D\times M\)。对于联合自变量\(\mathbf{z}=\left(\begin{array}{c}\mathbf{x}\\\mathbf{y}\end{array}\right)\)而言,联合概率分布的对数为
\[\begin{aligned} \ln p(\mathbf{z})&=\ln p(\mathbf{x})+\ln p(\mathbf{y}|\mathbf{x})\\ &=-\frac12(\mathbf{x}-\pmb\mu)^T\mathbf\Lambda(\mathbf{x}-\pmb\mu)-\frac12(\mathbf{y}-A\mathbf{x}-\mathbf{b})^T\mathbf L^{-1}(\mathbf{y}-A\mathbf{x}-\mathbf{b})+\text{对于}\mathbf{x}\text{和}\mathbf{y}\text{而言是常数} \end{aligned} \]
这是\(\mathbf{z}\)的分量的一个二次函数,因此亦是高斯分布,为了找到这个高斯分布的均值和协方差,需要将此二次型整理成\(\text{二次项}+\text{一次项}+\text{常数}\)的形式,先看二次项,得到
\[\begin{aligned} &\quad-\frac12\mathbf{x}^T(\mathbf\Lambda+\mathbf A^T\mathbf L\mathbf A)\mathbf{x}-\frac12\mathbf{y}^T\mathbf L\mathbf{y}+\frac12\mathbf{y}^T\mathbf L\mathbf A\mathbf{x}+\frac12\mathbf{x}^T\mathbf A^T\mathbf L\mathbf{y}\\ &=-\frac12\left(\begin{array}{c}\mathbf{x}\\\mathbf{y}\end{array}\right)^T\left(\begin{array}{cc}\mathbf\Lambda+\mathbf A^T\mathbf L\mathbf A&-\mathbf A^T\mathbf L\\-\mathbf L\mathbf A&\mathbf L\end{array}\right)\left(\begin{array}{c}\mathbf{x}\\\mathbf{y}\end{array}\right)=-\frac12\mathbf{z}^T\mathbf R\mathbf{z} \end{aligned} \]
因此高斯分布的精度矩阵(协方差矩阵的逆矩阵)为
\[\mathbf R=\left(\begin{array}{cc}\mathbf\Lambda+\mathbf A^T\mathbf L\mathbf A&-\mathbf A^T\mathbf L\\-\mathbf L\mathbf A&\mathbf L\end{array}\right) \]
使用关于分块矩阵逆的恒等式可以得到协方差矩阵为
\[\text{cov}(\mathbf{z})=\mathbf R^{-1}= \left( \begin{array} {cc} \mathbf\Lambda^{-1}&\mathbf\Lambda^{-1}\mathbf A^T\\ \mathbf A\mathbf\Lambda^{-1}&\mathbf L^{-1}+\mathbf A\mathbf\Lambda^{-1}\mathbf A^T \end{array} \right) \]
类似地,找到二次型中的一次项为
\[\mathbf{x}^T\mathbf\Lambda\pmb\mu-\mathbf{x}^T\mathbf A^T\mathbf L\mathbf{b}+\mathbf{y}^T\mathbf L\mathbf{b}= \left(\begin{array}{c}\mathbf{x}\\\mathbf{y}\end{array}\right)^T \left( \begin{array} {c} \mathbf\Lambda\pmb\mu-\mathbf A^T\mathbf L\mathbf{b}\\ \mathbf L\mathbf{b} \end{array} \right) =\mathbf{z}^T\cdot\mathbf R\cdot E(\mathbf{z}) \]
于是均值为
\[E(\mathbf{z})=\mathbf R^{-1} \left( \begin{array} {c} \mathbf\Lambda\pmb\mu-\mathbf A^T\mathbf L\mathbf{b}\\ \mathbf L\mathbf{b} \end{array} \right) =\left( \begin{array} {c} \pmb\mu\\ \mathbf A\mathbf{x}+\mathbf{b} \end{array} \right) \]
接下来来看边缘分布\(p(\mathbf{y})\)的均值和协方差,使用已经得到的结论,可以推得
\[\begin{aligned} E(\mathbf{y})&=\mathbf A\pmb\mu+\mathbf{b}\\ \text{cov}(\mathbf{y})&=\mathbf L^{-1}+\mathbf A\mathbf\Lambda^{-1}\mathbf A^T \end{aligned} \]
最后来寻找条件分布\(p(\mathbf{x}|\mathbf{y})\)的表达式,在“条件高斯分布”一节中已经给出了\(\pmb\mu_{a|b}\)和\(\mathbf\Sigma_{a|b}\)的一般表达式,现在直接带入可以得到
\[\begin{aligned} E(\mathbf{x}|\mathbf{y})&=(\mathbf\Lambda+\mathbf A^T\mathbf L\mathbf A)^{-1}\{\mathbf A^T\mathbf L(\mathbf{y}-\mathbf{b})+\mathbf\Lambda\pmb\mu\}\\ \text{cov}(\mathbf{x}|\mathbf{y})&=(\mathbf\Lambda+\mathbf A^T\mathbf L\mathbf A)^{-1} \end{aligned} \]
这给出了先验分布参数与后验分布参数的精确关系。
3.8 高斯分布的最大似然估计
给定数据集\(\mathbf{X}=(\mathbf{x}_1,\mathbf{x}_2,\cdots,\mathbf{x}_N)^T\),且满足多元高斯分布,那么对数似然函数为
\[\ln p(\mathbf{X}|\pmb\mu,\mathbf\Sigma)=-\frac{ND}{2}\ln(2\pi)-\frac{N}{2}\ln|\mathbf\Sigma|-\frac12\sum_{n=1}^N(\mathbf{x}_n-\pmb\mu)^T\mathbf\Sigma^{-1}(\mathbf{x}_n-\pmb\mu) \]
经过简单的重新排列,我们可以发现这个对数似然函数的充分统计量为\(\sum_{n=1}^N\mathbf{x}_n\)和\(\sum_{n=1}^N\mathbf{x}_n\mathbf{x}_n^T\)。该对数似然函数对参数\(\pmb\mu\)的导数为
\[\frac{\partial}{\partial\pmb\mu}\ln p(\mathbf{X}|\pmb\mu,\mathbf\Sigma)=\sum_{n=1}^N\mathbf\Sigma^{-1}(\mathbf{x}_n-\pmb\mu) \]
令此导数为零,便得到参数\(\pmb\mu\)的极大似然估计为
\[\pmb\mu_{ML}=\frac1N\sum_{n=1}^N\mathbf{x}_n \]
这和我们的直觉是相符的,并且有\(E(\pmb\mu_{ML})=\pmb\mu\),即这个估计是无偏的。下面我们不加证明地指出参数\(\pmb\Sigma\)的极大似然估计为
\[\mathbf\Sigma_{ML}=\frac1N\sum_{n=1}^N(\mathbf{x}_n-\pmb\mu_{ML})(\mathbf{x}_n-\pmb\mu_{ML})^T \]
这也和我们的直觉是相符的,但是\(E(\mathbf\Sigma_{ML})=\frac{N-1}{N}\mathbf\Sigma\),即这个估计是有偏的,当给定数据集的时候,参数\(\pmb\Sigma\)的一个无偏估计为
\[\tilde{\mathbf\Sigma}=\frac{1}{N-1}\sum_{n=1}^N(\mathbf{x}_n-\pmb\mu_{ML})(\mathbf{x}_n-\pmb\mu_{ML})^T \]
3.9 顺序估计
对于上一节中得到的\(\pmb\mu_{ML}\)而言,如果我们想定量分析最后一个数据点的贡献时
\[\begin{aligned} \pmb\mu_{ML}^{(N)}&=\frac1N\sum_{n=1}^N\mathbf{x}_n\\ &=\frac1N\mathbf{x}_N+\frac1N\sum_{n=1}^{N-1}\mathbf{x}_n\\ &=\frac1N\mathbf{x}_N+\frac{N-1}{N}\pmb\mu_{ML}^{(N-1)}\\ &=\pmb\mu_{ML}^{(N-1)}+\frac1N(\mathbf{x}_N-\pmb\mu_{ML}^{(N-1)}) \end{aligned} \]
该式给出了每次得到一个新数据点之后修正参数\(\pmb\mu_{ML}\)的方法:将已经得到的参数\(\pmb\mu_{ML}^{(N-1)}\)沿着方向\(\mathbf{x}_N-\pmb\mu_{ML}^{(N-1)}\)移动一小段距离,且这段距离会随着数据集的不断扩大而减小。
在上面的例子中,参数\(\pmb\mu\)的极大似然估计\(\pmb\mu_{ML}\)可以分离出最后一个数据点的贡献,但是在实际应用中,参数的极大似然估计的形式是十分多样的,不能确保一定能够从中分离出最后一个数据点的贡献。下面我们介绍一个更加普适的顺序学习方法:Robbins-Monro方法。一个参数的极大似然估计就是对应的负对数似然函数的一个驻点,即导数值等于零的解,现在先从纯数学角度进行分析:考虑随机变量\(\theta\)和\(z\),它们的联合分布为\(p(z,\theta)\),那么在已知\(\theta\)的情况下,\(z\)的条件期望定义了一个关于\(\theta\)的函数\(f(\theta)\)
\[f(\theta)\equiv E(z|\theta)=\int zp(z|\theta)dz \]
通过这种方式定义的函数被称为回归函数(regression function),它的含义是:每给定一个具体的\(\theta_0\)时,\(z\)的期望仅由\(\theta_0\)表示。我们的目标是寻找根\(\theta^*\)使得\(f(\theta^*)=0\),Robbins-Monro方法给出了在顺序观测的情况下找到\(\theta^*\)的方法。假设\(z\)的条件方差是有穷的,因此
\[E((z-f)^2|\theta)<\infty \]
并且设当\(\theta<\theta^*\)时\(f(\theta)<0\),当\(\theta>\theta^*\)时\(f(\theta)>0\),Robbins-Monro方法通过定义下述序列给出了根\(\theta^*\)的估计为
\[\theta^{(N)}=\theta^{(N-1)}-\alpha_{N-1}z(\theta^{N-1}) \]
其中\(z(\theta^{N-1})\)是当\(\theta\)取值为\(\theta^{N-1}\)时的观测值,系数\(\{\alpha_n\}\)表示满足下述三个条件的正数序列
\[\lim_{N\rightarrow\infty}\alpha_N=0,\quad \sum_{N=1}^\infty\alpha_N=\infty,\quad \sum_{N=1}^\infty\alpha_N^2<\infty \]
第一个条件保证了根的修正幅度会逐渐减小(因此能够收敛到一个有限值),第二个条件保证了不会收敛不到根的值(因此能够收敛到根的值),第三个条件保证了累计的噪声具有一个有限的方差(因此不会导致收敛失败)。
对于任意一个负对数似然函数而言,它的参数\(\theta\)的极大似然估计满足
\[\frac{\partial}{\partial\theta}\{\frac1N\sum_{n=1}^N-\ln p(x_n|\theta)\}=0 \]
交换导数与求和并取极限\(N\rightarrow\infty\),得到
\[-\lim_{N\rightarrow\infty}\frac1N\sum_{n=1}^N\frac{\partial}{\partial\theta}\ln p(x_n|\theta)=E_x(-\frac{\partial}{\partial\theta}\ln p(x_n|\theta)) \]
因此我们看到寻找极大似然估计对应于寻找回归函数的根。于是我们可以应用Robbins-Monro方法,此时它的形式为
\[\theta^{(N)}=\theta^{(N-1)}-\alpha_{N-1}\frac{\partial}{\partial\theta^{(N-1)}}[-\ln p(x_N|\theta^{(N-1)})] \]
下面以高斯分布为例来看看该方法在实际情况中的应用。随机变量\(z\)为
\[z=-\frac{\partial}{\partial\mu_{ML}}\ln p(x|\mu_{ML},\sigma^2)=-\frac{1}{\sigma^2}(x-\mu_{ML}) \]
因此\(z\)的分布仍是高斯分布,将此结果代入Robbins-Monro方法,得到
\[\mu_{ML}^{(N)}=\mu_{ML}^{(N-1)}-\frac{\sigma^2}{N-1}(-\frac{1}{\sigma^2}(x_N-\mu_{ML}^{(N-1)})) \]
其中,令\(\alpha_N=\frac{\sigma^2}{N}\)。该结果很容易推广到多元情形。
3.10 高斯分布的贝叶斯推断
极大似然估计给出了均值和方差的点估计,现在引入这些参数的先验分布。首先对于一组随机变量\(\mathbf{x}\)而言,假设方差已知,需要推断均值,则有似然函数
\[p(\mathbf{x}|\mu)=\prod_{n=1}^Np(x_n|\mu)=\frac{1}{(2\pi\sigma^2)^{N/2}}\text{exp}\{-\frac{1}{2\sigma^2}\sum_{n=1}^N(x_n-\mu)^2\} \]
为了保证先验分布和后验分布的共轭性,现令先验分布为\(p(\mu)=N(\mu|\mu_0,\sigma_0^2)\),从而后验概率满足
\[p(\mu|\mathbf{x})\varpropto p(\mathbf{x}|\mu)p(\mu)=N(\mu|\mu_N,\sigma_N^2) \]
其中
\[\mu_N=\frac{\sigma^2}{N\sigma_0^2+\sigma^2}\mu_0+\frac{N\sigma_0^2}{N\sigma_0^2+\sigma^2}\mu_{ML},\qquad\frac{1}{\sigma_N^2}=\frac{1}{\sigma^2}+\frac{N}{\sigma_0^2} \]
其中\(\mu_{ML}\)是\(\mu\)的极大似然估计,即为\(\mu_{ML}=\frac1N\sum_{n=1}^Nx_n\)。从上式自然可以看出:随着数据集规模\(N\)的增加,\(\mu_N\)会越来越接近\(\mu_{ML}\)。此外,由此式可以发现:精度(方差的倒数)是可以直接叠加的,随着数据集规模\(N\)的增加,精度会越来越大(即方差会越来越小)。该结论容易推广到多项式变量的情况。若从顺序角度来看高斯分布的贝叶斯推断,从后验分布中分离出最后一个数据点\(x_N\)得到
\[p(\mu|\mathbf{x})\varpropto[p(\mu)\prod_{n=1}^{N-1}p(x_N|\mu)]p(x_N|\mu) \]
该式明显揭示了每增加一个数据点所能带来的贡献。
上面假设方差已知并推断均值,下面假设均值已知推断方差,保持似然函数和先验分布的共轭性,得到
\[\begin{aligned} p(\lambda|\mathbf{x})&\varpropto p(\mathbf{x}|\lambda)\cdot\text{Gam}(\lambda|a,b)\\ &\varpropto\lambda^{N/2}\text{exp}\{-\frac{\lambda}{2}\sum_{n=1}^N(x_n-\mu)^2\}\cdot\frac{1}{\Gamma(a)}b^a\lambda^{a-1}\text{exp}(-b\lambda)\\ &\equiv\text{Gam}(\lambda|a_N,b_N) \end{aligned} \]
其中\(\lambda\equiv\frac{1}{\sigma^2}\),Gamma分布的形式为
\[\text{Gam}(\lambda|a,b)=\frac{1}{\Gamma(a)}b^a\lambda^{a-1}\text{exp}(-b\lambda) \]
并且可以得到
\[\begin{aligned} E(\lambda|a,b)&=\frac{a}{b}\\ \text{var}(\lambda|a,b)&=\frac{a}{b^2} \end{aligned} \]
上述参数\(a_N\)和\(b_N\)为
\[a_N=a_0+\frac{N}{2},\qquad b_N=b_0+\frac12\sum_{n=1}^N(x_n-\mu)^2=b_0+\frac{N}{2}\sigma_{ML}^2 \]
其中\(\sigma_{ML}^2\)是方差的最大似然估计,即为\(\sigma_{ML}^2=\frac1N\sum_{n=1}^N(x_n-\mu)^2\)(此时假设\(\mu\)已知)。从\(a_N\)的表达式知道,当我们观测\(N\)个数据点的时候,使得参数\(a_N\)增加了\(\frac{N}{2}\),因此可以将先验参数\(a_0\)解释为\(2a_0\)个先验的有效观测。在Beta分布中我们也将先验参数解释为有效观测,实际上,对于指数族分布而言,把共轭先验视为有效假想数据点是一个很通用的思路。
如果在分析问题的时候考虑的是\(\sigma^2\)而非\(\lambda\),那么引入的是逆Gamma(inverse gamma)分布,此处不介绍。
在具体分析问题的时候,一个重要的技巧就是不需要始终注意一个概率的归一化系数,比如此处Gamma分布的归一化系数可以在任何时候与标准Gamma分布的形式相比较而得到。
之前先后讨论了方差已知推断均值、均值已知推断方差两种情况,现在先来看均值和方差都未知时的情况。为了找到共轭先验,先考虑似然函数
\[p(\mathbf{x}|\mu,\lambda)=\prod_{n=1}^N(\frac{\lambda}{2\pi})^{1/2}\text{exp}\{-\frac{\lambda}{2}(x_n-\mu)^2\}\varpropto[\lambda^{1/2}\text{exp}(-\frac{\lambda\mu^2}{2})]^N\text{exp}\{\lambda\mu\sum_{n=1}^Nx_n-\frac{\lambda}{2}\sum_{n=1}^Nx_n^2\} \]
故假设先验分布为
\[p(\mu,\lambda)\varpropto[\lambda^{1/2}\text{exp}(-\frac{\lambda\mu^2}{2})]^\beta\text{exp}\{c\lambda\mu-d\lambda\}=\text{exp}\{-\frac{\beta\lambda}{2}(\mu-\frac{c}{\beta})\}\lambda^{\beta/2}\cdot\text{exp}\{-(d-\frac{c^2}{2\beta})\lambda\} \]
其中参数\(c\),\(d\)和\(\beta\)都为常数,由于\(p(\mu,\lambda)=p(\mu|\lambda)\cdot p(\lambda)\),将上式整理为
\[p(\mu,\lambda)=\mathcal N(\mu|\mu_0,(\beta\lambda)^{-1})\cdot\text{Gam}(\lambda|a,b)=p(\mu|\lambda)\cdot p(\lambda) \]
其中
\[\mu_0=\frac{c}{\beta},\quad a=\frac{1+\beta}{2},\quad b=d-\frac{c^2}{2\beta} \]
该先验分布称为被称为正态-Gamma(normal-gamma)分布或者高斯-Gamma(Gaussian-gamma)分布。
对于\(D\)维多项式变量\(\mathbf{x}\)的高斯分布\(\mathcal N(\mathbf{x}|\pmb\mu,\mathbf\Lambda^{-1})\),如果精度\(\mathbf\Lambda\)已知,那么均值\(\pmb\mu\)的先验分布仍为高斯分布;如果均值\(\pmb\mu\)已知,那么精度\(\mathbf\Lambda\)的先验分布定义如下
\[\mathcal{W}(\mathbf\Lambda|\mathbf W,\nu)=B|\mathbf\Lambda|^{(\nu-D-1)/2}\text{exp}(-\frac12\text{Tr}(\mathbf W^{-1}\mathbf\Lambda)) \]
该分布称为Wishart分布,其中\(\nu\)被称为分布的自由度数量,\(\mathbf W\)是一个\(D\times D\)的标量矩阵,\(\text{Tr}(\cdot)\)表示矩阵的迹,归一化系数\(B(\mathbf W,\nu)\)为
\[B(\mathbf W,\nu)=|\mathbf W|^{-\nu/2}(2^{(\nu D)/2}\pi^{D(D-1)/4}\prod_{i=1}^D\Gamma(\frac{\nu+1-i}{2}))^{-1} \]
和之前一样,此处也可以用\(\pmb\Sigma\)而非\(\mathbf\Lambda\)参与讨论,那么引入的是逆Wishart(inverse Wishart)分布。
如果均值\(\pmb\mu\)和\(\mathbf\Lambda\)都是未知的,那么共轭先验为
\[p(\pmb\mu,\mathbf\Lambda|\pmb\mu_0,\beta,\mathbf W,\nu)=\mathcal N(\pmb\mu|\pmb\mu_0,(\beta\mathbf\Lambda)^{-1})\cdot\mathcal{W}(\mathbf\Lambda|\mathbf W,\nu) \]
这被称为正态-Wishart(normal-Wishart)分布或者高斯-Wishart(Gaussian-Wishart)分布。
3.11 学生t分布
高斯-Gamma用于均值和方差都未知时的参数估计,现在令\(\mathcal N(x|\mu,\tau^{-1})\)和\(\text{Gam}(\tau|a,b)\),如果对\(\tau\)积分则得到
\[\begin{aligned} p(x|\mu,a,b)&=\int_0^\infty\mathcal N(x|\mu,\tau^{-1})\cdot\text{Gam}(\tau|a,b)d\tau\\ &=\int_0^\infty\frac{b^ae^{-b\tau}\tau^{a-1}}{\Gamma(a)}(\frac{\tau}{2\pi})^{1/2}\text{exp}\{-\frac\tau2(x-\nu)^2\}d\tau\\ &=\frac{b^a}{\Gamma(a)}(\frac{1}{2\pi})^{1/2}[b+\frac{(x-\mu)^2}{2}]^{-a-1/2}\Gamma(a+\frac12) \end{aligned} \]
现在定义新的参数\(\nu=2a\)和\(\lambda=\frac{a}{b}\),则分布\(p(x|\mu,a,b)\)为
\[\text{St}(x|\mu,\lambda,\nu)=\frac{\Gamma(\frac\nu2+\frac12)}{\Gamma(\frac\nu2)}(\frac{\lambda}{\pi\nu})^{1/2}[1+\frac{\lambda(x-\mu)^2}{\nu}]^{-\nu/2-1/2} \]
该分布被称为学生t分布(Student's t-distribution)。参数\(\lambda\)可称为t分布的精度,即使它通常不等于方差的倒数。参数\(\nu\)称为t分布的自由度。当\(\nu=1\)时,t分布变为柯西分布(Cauchy distribution);当\(\nu\rightarrow\infty\)时,t分布\(\text{St}(x|\mu,\lambda,\nu)\)变为高斯分布\(p(x|\mu,\lambda^{-1})\),此时均值为\(\mu\)、精度为\(\lambda\)。
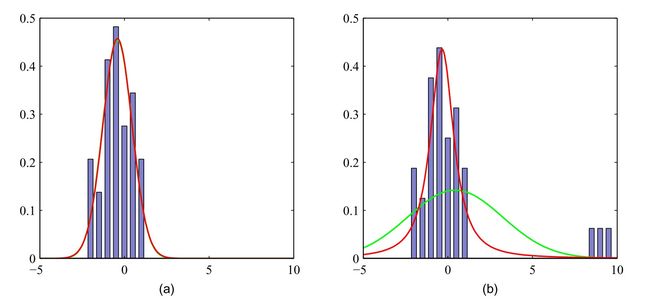
t分布可以视为无限多个同均值不同精度的高斯分布相加得到的,因此t分布比高斯分布具有更好的鲁棒性(robustness),即t分布更加集中于均值附近,因此更少受到少数离群点(outlier)的影响,下图红线表示使用t分布进行拟合,而绿线表示使用高斯分布进行拟合
下面令\(\nu=2a\),\(\lambda=\frac{a}{b}\)以及\(\eta=\frac{\tau b}{a}\),从而给出t分布的另一种写法
\[\text{St}(x|\mu,\lambda,\nu)=\int_0^\infty\mathcal N(x|\mu,(\eta\lambda)^{-1})\cdot\text{Gam}(\eta|\frac\nu2,\frac\nu2)d\eta \]
之后便容易将此结果推广到\(D\)维多元高斯分布的情况并积分得到
\[\begin{aligned} \text{St}(\mathbf{x}|\pmb\mu,\mathbf\Lambda,\nu)&=\int_0^\infty\mathcal N(\mathbf{x}|\pmb\mu,(\eta\mathbf\Lambda)^{-1})\cdot\text{Gam}(\eta|\frac\nu2,\frac\nu2)d\eta\\ &=\frac{\Gamma(\frac{D}{2}+\frac\nu2)}{\Gamma(\frac\nu2)}\frac{|\mathbf\Lambda|^{1/2}}{(\pi\nu)^{D/2}}[1+\frac{\Delta^2}{\nu}]^{-D/2-\nu/2} \end{aligned} \]
其中\(\Delta^2\)是马氏距离的平方,\(\Delta^2=(\mathbf{x}-\pmb\mu)^T\mathbf\Lambda(\mathbf{x}-\pmb\mu)\)。且可以得到
\[\begin{aligned} E(\mathbf{x})&=\pmb\mu\\ \text{cov}(\mathbf{x})&=\frac{\nu}{\nu-2}\mathbf\Lambda^{-1}\\ \text{mode}(\mathbf{x})&=\pmb\mu \end{aligned} \]
其中\(\text{mode}(\mathbf{x})\)表示众数。一元情况的结论可以类似得到,此处略去。
3.12 周期变量
周期变量常使用极坐标进行描述,这时用高斯分布不能很好地描述该变量。一个容易想到的处理周期变量的思路是在\(0\leq\theta\leq2\pi\)中选定一个方向作为原点,然后用传统的概率分布方法进行拟合,事实证明该思路在实际应用中局限颇大。对于周期变量的观测数据集\(D=\{\theta_1,\cdots,\theta_N\}\),其均值\(\frac{\theta_1+\cdots+\theta_N}{N}\)严重依赖于坐标系的选择,为了找到均值的一个不变的度量。现将此观测视为单位圆上的点,即用模值为\(1\)的二维向量\(\mathbf{x}\)来描述变量\(\theta\),对向量\(\mathbf{x}\)求平均得到\(\bar{\mathbf{x}}=\frac1N\sum_{n=1}^N\mathbf{x}_n\),注意此时的\(||\bar{\mathbf{x}}||\leq1\),即\(\bar{\mathbf{x}}\)通常位于单位圆的内部,对应的\(\bar{\theta}\)与极坐标原点的选择无关,这样将样本均值写为\(\bar{\mathbf{x}}=(\bar{r}\cos\bar\theta,\bar{r}\cos\bar\theta)\),设\(\bar{\mathbf{x}}=(\bar{x}_1,\bar{x}_2)\),则
\[\bar{x}_1=\bar{r}\cos\bar\theta=\frac1N\sum_{n=1}^N\cos\theta_n,\quad\bar{x}_2=\bar{r}\sin\bar\theta=\frac1N\sum_{n=1}^N\sin\theta_n \]
求两者的比值并代入反三角函数便可得到
\[\bar\theta=\arctan(\frac{\sum_n\sin\theta_n}{\sum_n\cos\theta_n}) \]
下面介绍高斯分布对周期变量的一种推广,该推广满足以下三个条件
\[p(\theta)\geq0,\quad\int_0^{2\pi}p(\theta)d\theta=1,\quad p(\theta+2\pi)=p(\theta) \]
因此对于变量\(\mathbf{x}=(x_1,x_2)\)而言,若均值为\(\pmb\mu=(\mu_1,\mu_2)\),协方差矩阵为\(\mathbf\Sigma=\sigma^2\mathbf I_{2\times 2}\),因此有
\[p(x_1,x_2)=\frac{1}{2\pi\sigma^2}\text{exp}\{-\frac{(x_1-\mu_1)^2+(x_2-\mu_2)^2}{2\sigma^2}\} \]
显然,如果此处的\(p(\mathbf{x})\)为常数,那么对应的轮廓线是一个圆。下面将此分布从笛卡尔坐标\((x_1,x_2)\)转换到极坐标\((r,\theta)\)得到的,即代入\(x_1=r\cos\theta\)和\(x_2=r\sin\theta\),并且设\(\mu_1=r_0\cos\theta_0\)和\(\mu_2=r_0\sin\theta_0\),从而得到
\[p(\theta|\theta_0,m)=\frac{1}{2\pi I_0(m)}\text{exp}\{m\cos(\theta-\theta_0)\} \]
其中\(m=\frac{r_0}{\sigma^2}\)。该分布称为von Mises分布或者环形正态(circular normal)分布,参数\(\theta_0\)对应分布的均值,参数\(m\)称为concentration参数(类似于高斯分布方差的倒数、即精度),参数\(I_0(m)\)称为零阶修正的第一类Bessel函数(zeroth-order Bessel function of the first kind),定义为
\[I_0(m)=\frac{1}{2\pi}\int_0^{2\pi}\text{exp}\{m\cos\theta\}d\theta \]
现在考虑环形正态分布参数\(\theta_0\)和参数\(m\)的极大似然估计,对数似然函数为
\[\ln p(D|\theta_0,m)=-N\ln(2\pi)-N\ln I_0(m)+m\sum_{n=1}^N\cos(\theta_n-\theta_0) \]
可以解得参数\(\theta_0\)的极大似然估计为
\[\theta_0^{ML}=\arctan(\frac{\sum_n\sin\theta_n}{\sum_n\cos\theta_n}) \]
现设\(A(m)=\frac{I_0'(m)}{I_0(m)}=\frac{I_1(m)}{I_0(m)}\),则参数\(m\)的极大似然估计\(m_{ML}\)满足下面的式子
\[A(m_{ML})=(\frac1N\sum_{n=1}^N\cos\theta_n)\cos\theta_0^{ML}+(\frac1N\sum_{n=1}^N\sin\theta_n)\sin\theta_0^{ML} \]
至于建立周期概率分布的通用方法,最简单的思路是使用观测的直方图:极坐标被划分成了固定大小的箱子,但是该思路具有较大的局限性。另一种方法类似于环形正态分布:先考察欧式空间的高斯分布,但是这会使得概率分布的形式异常复杂。最后⼀种方法的思想是,在实数轴上的任何合法的分布(例如高斯分布)都可以转化成周期分布,转化的方法是连续地把宽度为\(2\pi\)的区间映射为周期变量\((0,2\pi)\),这相当于把实数轴沿着单位圆进行缠绕,该方法最终求出的概率分布在计算上较为复杂。
环形正态分布的⼀个局限性是这个分布是单峰的,但是通过将环形正态分布混合,我们可以得到一些应用性更广的模型。
3.13 混合高斯模型
由于高斯分布只是单峰的,因此许多复杂的模型都不能仅只用朴素的高斯分布来描述,现在引入混合高斯(mixture of Gaussians)分布的概念,混合高斯分布是指高斯分布的线性叠加,即这样一个分布
\[p(\mathbf{x})=\sum_{k=1}^K\pi_k\mathcal N(\mathbf{x}|\pmb\mu_k,\mathbf\Sigma_k) \]
其中每个\(\mathcal N(\mathbf{x}|\pmb\mu_k\mathbf\Sigma_k)\)称为混合分布的一个成分(component),并且都有自己的均值\(\pmb\mu_k\)和协方差\(\mathbf\Sigma_k\),特别地,\(\pi_k\)被称为混合系数(mixing coefficient),满足\(\sum_{k=1}^K\pi_k=1\)以及\(0\leq\pi_k\leq1\)。
这种加权平均的思路很容易让我们想到全概率公式,也就是\(p(\mathbf{x})=\sum_{k=1}^Kp(k)p(\mathbf{x}|k)\),将其中\(\pi_k\)视为选择第\(k\)个成分的先验概率\(p(k)\),把密度\(\mathcal N(\mathbf{x}|\pmb\mu_k,\mathbf\Sigma_k)\)视为\(k\)条件下的条件密度,那么此时的\(p(\mathbf{x})\)在实际意义上就反映了后验概率\(p(k|\mathbf{x})\),即正比于(但不等于)后验概率\(p(k|\mathbf{x})\)。后续章节将讲述该后验概率的重要应用,它也被称为责任(responsibility),根据贝叶斯定理,后验概率可以被表示为
\[\begin{aligned} \gamma_k(\mathbf{x})&\equiv p(k|\mathbf{x})\\ &=\frac{p(k)p(\mathbf{x}|k)}{\sum_lp(l)p(\mathbf{x}|l)}\\ &=\frac{\pi_k\mathcal N(\mathbf{x}|\pmb\mu_k\mathbf\Sigma_k)}{\sum_l\pi_l\mathcal N(\mathbf{x}|\pmb\mu_l,\mathbf\Sigma_l)} \end{aligned} \]
可以近似地认为,这就是将之前介绍的\(p(\mathbf{x})\)关于参数\(k\)做了归一化处理,使其反映随机变量\(k\)的概率分布而非随机变量\(\mathbf{x}\)的概率分布。
现在,我们已经发现,混合高斯分布由以下三个参数控制
\[\begin{aligned} \pmb\pi&\equiv\{\pi_1,\pi_2,\cdots,\pi_K\}\\ \pmb\mu&\equiv\{\pmb\mu_1,\pmb\mu_2,\cdots,\pmb\mu_K\}\\ \mathbf\Sigma&\equiv\{\mathbf\Sigma_1,\mathbf\Sigma_2,\cdots,\mathbf\Sigma_K\} \end{aligned} \]
那么混合高斯分布的对数似然函数就是
\[\ln p(\mathbf{X}|\pmb\pi,\pmb\mu,\mathbf\Sigma)=\sum_{n=1}^N\ln\{\sum_{k=1}^K\pi_kN(\mathbf{x}_n|\pmb\mu_n,\mathbf\Sigma_n)\} \]
其中\(\mathbf{X}=\{\mathbf{x}_1,\mathbf{x}_2,\cdots,\mathbf{x}_N\}\)。这样就可以使用极大似然法确定各个参数的极大似然估计了,具体内容将在后面的章节讨论。
4 指数族分布
本章到目前为止我们正式接触到的分布均为指数族分布(exponential family)的具体的例子,参数\(\pmb\eta\)关于变量\(\mathbf{x}\)的一般情形的指数族分布的形式为
\[p(\mathbf{x}|\pmb\eta)=h(\mathbf{x})g(\pmb\eta)\text{exp}\{\pmb\eta^Tu(\mathbf{x})\} \]
其中\(\mathbf{x}\)可能是标量、也可能是向量,可能是离散的、也可能是连续的。函数\(g(\pmb\eta)\)充当了归一化系数的作用。下面来讨论已经遇到的三种主要分布的指数族分布标准形式。
4.1 伯努利分布的指数族分布形式
有如下推导
\[\begin{aligned} p(x|\mu)&=\text{Bern}(x|\mu)=\mu^x(1-\mu)^{1-x}\\ &=\text{exp}\{x\ln\mu+(1-x)\ln(1-\mu)\}\\ &=(1-\mu)\text{exp}\{\ln(\frac{\mu}{1-\mu})\cdot x\} \end{aligned} \]
容易得到\(\eta=\ln(\frac{\mu}{1-\mu})\),从中解出\(\mu=\sigma(\eta)=\frac{1}{1+\text{exp}(-\eta)}\),\(\sigma(\eta)\)被称为logistic sigmoid函数,那么就有
\[p(x|\mu)=\sigma(-\eta)\text{exp}(\eta x)\\ u(x)=x,\quad h(x)=1,\quad\eta=\ln(\frac{\mu}{1-\mu}),\quad g(\eta)=\sigma(-\eta) \]
4.2 多项式分布的指数族形式
有如下推导
\[\begin{aligned} p(\mathbf{x}|\pmb\mu)&=\text{Mult}(\mathbf{x}|\pmb\mu)=\prod_{k=1}^M\mu_k^{x_k}=\text{exp}\{\sum_{k=1}^Mx_k\ln\mu_k\}\\ &=\text{exp}(\pmb\eta^T\mathbf{x}) \end{aligned} \]
容易得到
\[u(\mathbf{x})=\mathbf{x},\quad h(\mathbf{x})=1,\quad\pmb\eta=(\ln\mu_1,\cdots,\ln\mu_M)^T,\quad g(\pmb\eta)=1 \]
由于参数\(\mu_k\)受到\(\sum_{k=1}^M\mu_k=1\)的限制,因此我们可以用前\(M-1\)个参数去表示出最后一个参数\(\mu_M\),那么就有
\[\begin{aligned} p(\mathbf{x}|\pmb\mu)&=\text{Mult}(\mathbf{x}|\pmb\mu)=\prod_{k=1}^M\mu_k^{x_k}=\text{exp}\{\sum_{k=1}^Mx_k\ln\mu_k\}\\ &=\text{exp}\{\sum_{k=1}^{M-1}x_k\ln\mu_k+(1-\sum_{k-1}^{M-1}x_k)\ln{(1-\sum_{k-1}^{M-1}x_k)}\}\\ &=\text{exp}\{\sum_{k=1}^{M-1}x_k\ln(\frac{\mu_k}{1-\sum_{j=1}^{M-1}\mu_j})+\ln(1-\sum_{k-1}^{M-1}x_k)\} \end{aligned} \]
可以令\(\eta_k=\ln(\frac{\mu_k}{1-\sum_{j=1}^{M-1}\mu_j})\),在此式两侧对\(k\)求和,反解得\(\mu_k=\frac{\text{exp}(\eta_k)}{1+\sum_{j}\text{exp}(\eta_j)}\),这被称为这被称为softmax函数或者归一化指数(normalized exponential),那么就有
\[p(\mathbf{x}|\pmb\eta)=(1+\sum_{k=1}^{M-1}\text{exp}(\eta_k))^{-1}\text{exp}(\pmb\eta^T\mathbf{x})\\ u(\mathbf{x})=\mathbf{x},\quad h(\mathbf{x})=1\\ \pmb\eta=(\ln(\frac{\mu_1}{1-\sum_{j=1}^{M-1}\mu_j}),\cdots,\ln(\frac{\mu_{M-1}}{1-\sum_{j=1}^{M-1}\mu_j}),0)^T\\ g(\pmb\eta)=(1+\sum_{k=1}^{M-1}\text{exp}(\eta_k))^{-1} \]
4.3 高斯分布的指数族分布形式
有如下推导
\[\begin{aligned} p(x|\mu,\sigma^2)&=\mathcal N(x|\mu,\sigma^2)=\frac{1}{(2\pi\sigma^2)^{1/2}}\text{exp}\{-\frac{1}{2\sigma^2}(x-\mu)^2\}\\ &=\frac{1}{(2\pi\sigma^2)^{1/2}}\text{exp}\{-\frac{1}{2\sigma^2}x^2+\frac{\mu}{\sigma^2}x-\frac{1}{2\sigma^2}\mu^2\} \end{aligned} \]
经过推导可以得到
\[u(x)=\left(\begin{array}{c}x\\x^2\end{array}\right),\quad h(x)=(2\pi)^{-1/2},\quad\pmb\eta=\left(\begin{array}{c}{\mu}/{\sigma^2}\\{-1}/{2\sigma^2}\end{array}\right),\quad g(\pmb\eta)=(-2\eta_2)^{1/2}\text{exp}(\frac{\eta_1^2}{4\eta_2}) \]
4.4 最大似然估计
下面来看参数\(\pmb\eta\)的最大似然估计的一般形式,对指数族分布的一般形式\(p(\mathbf{x}|\pmb\eta)=h(\mathbf{x})g(\pmb\eta)\text{exp}\{\pmb\eta^Tu(\mathbf{x})\}\)而言,其似然函数为
\[p(\mathbf{X}|\pmb\eta)=\prod_{n=1}^Np(\mathbf{x}_n|\pmb\eta)=\prod_{i=1}^Nh(\mathbf{x}_i)\cdot(g(\pmb\eta))^N\cdot\text{exp}\{\pmb\eta^T(\sum_{j=1}^Nu(\mathbf{x}_j))\} \]
两侧对\(\pmb\eta\)取偏导得到
\[N(g(\pmb\eta))^{N-1}\cdot\nabla g(\pmb\eta)\cdot\text{exp}\{\pmb\eta^T(\sum_{j=1}^Nu(\mathbf{x}_j))\}+(g(\pmb\eta))^N\cdot\text{exp}\{\pmb\eta^T(\sum_{j=1}^Nu(\mathbf{x}_j))\}\cdot(\sum_{k=1}^Nu(\mathbf{x}_k))=0 \]
整理得到
\[-\frac{\nabla g(\pmb\eta)}{g(\pmb\eta)}=\frac{u(\mathbf{x}_1)+\cdots+u(\mathbf{x}_N)}{N} \]
也就是
\[-\nabla\ln g(\pmb\eta_{ML})=\frac1N\sum_{n=1}^Nu(\mathbf{x}_n)=E(u(\mathbf{x})),\quad\text{在等概率情况下最后一个等号成立} \]
由于参数\(\pmb\eta\)极大似然估计仅由\(\sum_{n=1}^Nu(\mathbf{x}_n)\)产生,因此这个量就是指数族分布的充分统计量。在具体应用的时候,我们不需要存储整个数据集,只需要存储充分统计量的值即可。例如,在伯努利分布中,\(u(x)=x\),那么充分统计量为\(\sum_{n=1}^Nx_n\),所以我们只需要存储数据点\(\{x_n\}\)的和即可。类似地,在高斯分布中,\(u(x)=(x,x^2)^T\),因此我们只需要存储\(\{x_n\}\)的和以及\(\{x_n^2\}\)的和即可。
4.5 共轭先验
在伯努利分布与二项分布中,共轭先验是Beta分布;在范畴分布与多项式分布中,共轭先验是Dirichlet分布;在高斯分布中,对于不同情况而言,共轭先验分别为高斯分布、Gamma分布、高斯-Gamma分布、Wishart分布或高斯-Wishart分布。实际上,对于指数族分布而言,有如下统一形式的共轭先验
\[p(\pmb\eta|\chi,\nu)=f(\chi,\nu)g(\pmb\eta)^\nu\text{exp}\{\nu\pmb\eta^T\chi\} \]
其中\(f(\chi,\nu)\)是归一化系数,\(g(\pmb\eta)\)充当了归一化系数的作用。将此先验分布与似然函数\(p(\mathbf{X}|\pmb\eta)\)相乘得到
\[p(\pmb\eta|\mathbf{X},\chi,\nu)\varpropto g(\pmb\eta)^{\nu+N}\text{exp}\{\pmb\eta^T(\sum_{n=1}^Nu(\mathbf{x}_n)+\nu\chi)\} \]
容易发现这满足共轭性。参数\(\nu\)可以看成是先验分布中假想观测的有效观测数,在给定\(\chi\)的情况下,每个假想观测都对充分统计量有贡献\(\nu\chi\)。
4.6 无信息先验
到目前为止,我们得到先验分布的思路都是从结构上根据共轭性而来的,并没有说明先验分布中各个参数具体取值的选择方法。从之前的内容可以知道,先验分布中各个参数的取值会对后验分布产生一定的影响,现在考虑是否可以选择合适形式的先验分布从而尽可能减小先验分布中参数值对后验分布的影响,这种形式的先验分布称为被称为无信息先验(noninformative prior)。
现在假设我们有一个由参数\(\lambda\)控制的分布\(p(x|\lambda)\),对于先验分布\(p(\lambda)\),一个最朴素的想法就是取为常数\(K\),如果\(\lambda\)的取值为有限个\(N\)个离散变量,那么\(p(\lambda)=K\)是合理的,这相当于\(NK=1\);如果\(\lambda\)的取值为某个有限连续区间\((a,b)\)上的连续值,那么\(p(\lambda)=K\)仍然是合理的,这相当于\((b-a)K=1\);但是,如果\(\lambda\)的取值是无限个离散值或者无限区间上的连续值,\(p(\lambda)=K\)就是不合理的,此时先验分布无法被正确地归一化,因为对\(\lambda\)的积分是发散的,这样的先验分布被称作是反常的(improper)。并且,将\(p(\lambda)\)取为常数\(K\)可能会在变量替换的时候出现问题,比如令\(\lambda=\eta^2\),则\(p_\eta(\eta)=p_\lambda(\lambda)\cdot|\frac{d\lambda}{d\eta}|=p_\lambda(\eta^2)\cdot2\eta\varpropto\eta\neq K\)。
下面来看无信息先验的两个简单例子。第一,如果概率密度的形式为\(p(x|\mu)=f(x-\mu)\),参数\(\mu\)被称为位置参数(location parameter)。如果这一类概率具有平移不变性(translation invariance),则说明我们选择的先验分布\(p(\mu)\)必须对区间\((a,b)\)和区间\((a-c,b-c)\)赋予相同的概率密度,即
\[\int_a^bp(\mu)d\mu=\int_{a-c}^{b-c}p(\mu)d\mu=\int_a^bp(\mu-c)d\mu \]
并且这对任意选择的\(a\)与\(b\)都成立,因此\(p(\mu)=p(\mu-c)\),故\(p(\mu)\)的取值为常数,这是平移不变性的重要性质。以高斯分布为例,均值\(\mu\)是一种位置参数,由“高斯分布的贝叶斯推断”一节中的表达式
\[\mu_N=\frac{\sigma^2}{N\sigma_0^2+\sigma^2}\mu_0+\frac{N\sigma_0^2}{N\sigma_0^2+\sigma^2}\mu_{ML} \]
可知,随着数据集规模\(N\)的不断增加,先验参数\(\mu_0\)对后验参数\(\mu_N\)的影响不断减小。
第二,如果概率密度的形式为\(p(x|\sigma)=\frac1\sigma f(\frac{x}{\sigma})\),那么参数\(\sigma\)被称为缩放参数(scale parameter)。如果这一类概率具有缩放不变性(scale invariance),则说明我们选择的先验分布\(p(\sigma)\)必须对区间\((a,b)\)和区间\((\frac{a}{c},\frac{b}{c})\)赋予相同的概率密度,即
\[\int_a^bp(\sigma)d\sigma=\int_{\frac{a}{c}}^{\frac{b}{c}}p(\sigma)d\sigma=\int_a^bp(\frac1c\sigma)\frac1cd\sigma \]
并且这对任意选择的\(a\)与\(b\)都成立,因此\(p(\sigma)=p(\frac1c\sigma)\frac1c\),故\(p(\sigma)\varpropto\frac1\sigma\),这是一个反常先验分布,因为对于\(0\leq\sigma\leq\infty\)上的积分是发散的,但\(p_{\ln\sigma}(\ln\sigma)=p_\sigma(\ln\sigma)\cdot|\frac{d\ln\sigma}{d\sigma}|\varpropto\frac1\sigma\cdot\sigma=1\),即\(p_{\ln\sigma}(\ln\sigma)\)的值为常数,这是缩放不变性的重要性质。以高斯分布为例,方差\(\sigma\)是一种缩放参数,由“高斯分布的贝叶斯推断”一节中的表达式
\[\frac{1}{\sigma_N^2}=\frac{1}{\sigma^2}+\frac{N}{\sigma_0^2} \]
可知,随着数据集规模\(N\)的不断增加,先验参数\(\sigma_0\)对后验参数\(\sigma_N\)的影响不断减小。
5 非参数化方法
我们已经详细地从贝叶斯主义的角度介绍了一些概率分布的具体形式,它们通常由一些参数控制,且这些参数通常由数据集推得。但是在实际应用中,这种参数化(parametric)方法有时具有较强的局限性。现在介绍如何从频率主义的角度进行建模。
5.1 直方图方法
直方图方法的核心是分割出数个区域,并分别分析每个区域具有的特征。对于离散数据点,该方法很好理解,即将每个数据点放入对应的区域即可。对于连续的情况,我们将连续变量分割称若干个区域\(\Delta_i\),将数据点放入对应的区域,得到每个区域的概率为
\[p_i=\frac{n_i}{N\Delta_i} \]
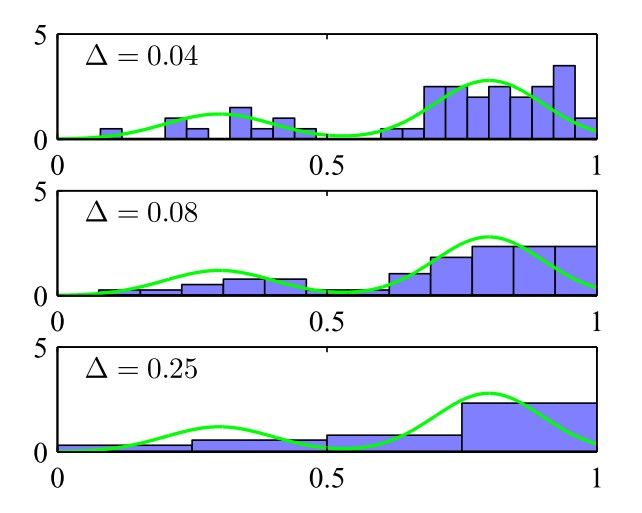
这就完成了建模,特别地,常令每个区域的覆盖范围的大小相同,即令\(\Delta_1=\Delta_2=\cdots\equiv\Delta\)。对于维数较低的情形(比如一元变量\(x\)),该方法是有效的;但对于维数较高的情形,该方法会导致维数灾难(小区域的数量为\(M^D\),每一维都分成\(M\)个区间)。在直方图方法中,\(\Delta\)的选择是十分关键的,这将直接影响到建模的优劣程度,比如
上图中绿线表示真实的分布,蓝色方框表示使用直方图方法建立的模型。另外,在原则上,区域边界的选择也会影响模型的有效性,但影响程度通常小于\(\Delta\)的选取。
直方图方法的核心在于用离散形式取考虑连续形式的性质,通过考虑某一点及其邻域的数据点从而得到该区域的特征,并且为了保证各区域之间的连贯性(即尽可能降低离散性的影响),还需要考虑局部区域的空间扩展(即这里的区域大小\(\Delta\))。一方面,较大的\(\Delta\)会尽可能保证该区域内性质的准确性,另一方面,较小的\(\Delta\)会尽可能保证各个区域之间的连贯性(因为当若干数据点被放入同一个区域时,它们之间的差异性被忽略了,这就导致各个区域之间数据点的差异性被放大了,从而导致各个区域之间的连贯性变差)。接下来将介绍两个常用的密度估计的非参数化方法,这两种方法与直方图方法的核心理念是相通的,但对于维数的放大具有更好的适应性。
5.2 核密度方法
先来讨论核密度方法与近邻方法的公共前提。对于\(D\)维欧氏空间而言,一个小区域的概率质量为
\[P=\int_Rp(\mathbf{x})d\mathbf{x} \]
现在假设数据集中有服从\(p(\mathbf{x})\)的\(N\)个数据点,那么位于区域\(R\)内部的数据点的数量\(K\)满足二项分布
\[\text{Bin}(K|N,P)=\frac{N!}{K!(N-K)!}P^K(1-P)^{N-K} \]
当区域\(R\)的体积\(V\)较小(从而\(p(\mathbf{x})\)在\(R\)内近似为常数)、且数据点的数量\(N\)较大时,我们有区域\(R\)上的概率密度的估计式为
\[p(\mathbf{x})=\frac{K}{NV} \]
接下来有两个思路进行下面的处理:一是核密度方法,即固定\(V\)然后从数据中确定\(K\);二是近邻方法,即固定\(K\)然后从数据中确定\(V\)的值。可以证明,在\(N\rightarrow\infty\)的情况下,如果\(V\)随着\(N\)而合适地收缩,并且\(K\)随着\(N\)而增大,那么两种方法得到的概率密度估计值都会收敛到真实的概率密度。
先来看核密度方法。如果我们取区域\(R\)以\(\mathbf{x}\)为中心且边长为\(1\)的小超立方体,为了统计落在该小超立方体中的数据点的数量,则可以设
\[k(\mathbf{u})= \begin{cases} 1,\quad|u_i|\leq\frac12,\quad i=1,\cdots,D\\ 0,\quad\text{others} \end{cases} \]
这是核函数(kernel function)的一个例子,也被称为Parzen窗。对于规模为\(N\)的数据集而言,位于小区域内的数据点的总数为
\[K=\sum_{n=1}^Nk(\frac{\mathbf{x}_n-\mathbf{x}}{h}) \]
由此式给出的估计称为核密度估计(kernel density estimator)或者Parzen估计。对于以\(\mathbf{x}\)为中心且边长为\(1\)的小超立方体区域、且选择上述核函数而言,其中\(h=1\)表示小超立方体的边长,则\(\mathbf{x}\)点处的核密度估计为
\[p(\mathbf{x})=\frac1N\sum_{n=1}^N\frac{1}{h^D}k(\frac{\mathbf{x}_n-\mathbf{x}}{h}) \]
但是核密度方法也具有直方图方法的一个重要缺陷:人为造成的区域间的连贯性变差,如果选择一个较为平滑的核函数(即:距离\(\mathbf{x}\)不同远近的数据点被放入区域内的条件不同),那么就能得到一个较好的模型。一个常见的选择就是高斯核函数,从而得到
\[p(\mathbf{x})=\frac1N\sum_{n=1}^N\frac{1}{(2\pi h^2)^{D/2}}\text{exp}\{-\frac{||\mathbf{x}_n-\mathbf{x}||^2}{2h^2}\} \]
其中\(h\)表示高斯分布的标准差,如果\(h\)过小则会模型对噪声过于敏感,如果\(h\)过大则会造成模型过于平滑。
事实上,核函数的选取是任意的,只需要满足下面两个条件
\[k(\mathbf{u})\geq0,\qquad\int k(\mathbf{u})d\mathbf{u}=1 \]
5.3 近邻方法
核密度方法的一个局限是对于所有区域的数据都给定了同样的核参数\(h\),在数据点密集的区域,这可能导致模型过于平滑,而在数据点稀疏的区域,这又可能导致模型对噪声过于敏感,所以一个合理的思路就是根据数据空间的位置确定不同的核参数\(h\),这通过近邻方法来具体处理。
对于概率密度估计式
\[p(\mathbf{x})=\frac{K}{NV} \]
而言,现在考虑固定\(K\)然后从数据中确定\(V\)的值。考虑以\(\mathbf{x}\)为中心的小超球体,其半径可以自由变化直到该区域内包含了\(K\)个数据点,但是这样得到的模型并不是真实的概率密度模型,因为它在整个空间的积分是发散的。
近邻方法可以推广到分类问题,对于每个具体的分类\(C_k\)而言,有
\[p(\mathbf{x}|C_k)=\frac{K_k}{N_kV} \]
并且无条件概率密度为
\[p(\mathbf{x})=\frac{K}{NV} \]
并且类先验概率密度为
\[p(C_k)=\frac{N_k}{N} \]
则根据贝叶斯定理得到后验概率密度为
\[p(C_k|\mathbf{x})=\frac{p(\mathbf{x}|C_k)p(C_k)}{p(\mathbf{x})}=\frac{K_k}{K} \]
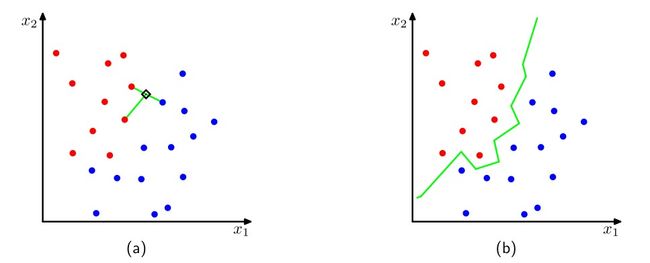
现在,如果我们想最小化错误分类的概率,则将测试点\(\mathbf{x}\)分配给具有最大后验概率密度的类别,这对应于最大的\(\frac{K_k}{K}\)。当\(K=1\)时,分类规则被称为最近邻规则(nearest-neighbour rule),因为测试点简单地被分类为训练数据集中距离最近的数据点的类别,下图是一个例子。
图(a)中\(K=3\),此时新输入一个测试点(图中黑色菱形)时,找到与之最近的三个数据点,发现红色数据点多,因此测试点为红色数据点。图(b)中\(K=1\),此时新输入一个测试点时,找到与之最近的两个数据点,观察其距离哪个数据点更近则说明它属于哪一个类别,图中所有类间点对的平分线生成上图中的绿线,在实际应用中,只需要观察它在绿线的哪一侧即可确定其是红色数据点还是蓝色数据点。
核密度方法和近邻方法都需要存储整个训练集。如果训练集很大则会造成很大的计算代价。我们可以建立⼀个基于树的搜索结构,使得(近似)近邻可以高效地被找到,而不必遍历整个数据集。尽管这样,这些非参数化方法仍然有较大的局限性。另外,简单的参数化模型非常受限,因为它们只能表示某一种形式的概率分布。因此,我们 需要寻找⼀种概率密度模型,这种模型既要有灵活性、又要保证它的复杂度可以被控制为与训练数据的规模无关。我们在后续章节中将会看到如何找到这种概率密度模型。
6 参考资料
- Christopher M. Bishop, Pattern Recognition and Machine Learning, Springer, 2006
- Markus Svensen, Christopher M. Bishop, Pattern Recognition and Machine Learning - Solutions to the Exercises: Tutors’ Edition, Springer, 2009
- 马春鹏,《模式识别与机器学习》(本文部分名词翻译来自此书),PRML的网传中文版,2014
- Multinoulli分布与多项式分布
- Multinomial Distribution
- Dirichlet Distribution
- Why: "we note that the matrix Σ can be taken to be symmetric, without loss of generality"?
- Mikio Nakahara, Tetsuo Ohmi, Quantum Computing - From Linear Algebra to Physical Realizations, CRC press, 2008
- 向量或矩阵的微分计算
- Matrix Spaces; Rank 1; Small World Graphs
- Expressing a matrix as an expansion of its eigenvalues
- Expected value of xx^{T} for multidimensional Gaussian
- PRML 模式识别和机器学习 从零开始的公式推导 2.3高斯分布
- PRML 模式识别和机器学习 从零开始的公式推导 2.3.1条件高斯分布
- Kernel Density Estimation