1.输入python,点击查询,检查,找接口数据

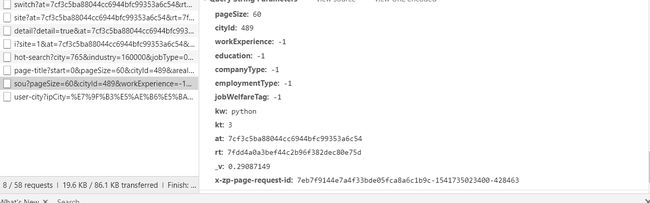

2.分析结果:
此接口的url ="https://fe-api.zhaopin.com/c/i/sou"
要爬取3页的内容 for i in range(1,4):
lastUrlQuery = {"p": i,"pageSize":"60","jl":"489","kw":"python","kt":"3"}
寻找params参数,用于拼接
```
params = {"start": (i -1) *60,
"pageSize":"60",
"cityId":"489",
"workExperience":"-1",
"education":"-1",
"companyType":"-1",
"employmentType":"-1",
"jobWelfareTag":"-1",
"kw":"python",
"kt":"3"
}
```
3.数据提取
```
from utilzimport util
import json,re,time
def getInfo():
url ="https://fe-api.zhaopin.com/c/i/sou"
# print(url)
for iin range(1,4):
lastUrlQuery = {"p": i,"pageSize":"60","jl":"489","kw":"python","kt":"3"}
params = {"start": (i -1) *60,
"pageSize":"60",
"cityId":"489",
"workExperience":"-1",
"education":"-1",
"companyType":"-1",
"employmentType":"-1",
"jobWelfareTag":"-1",
"kw":"python",
"kt":"3",
"lastUrlQuery": lastUrlQuery
}
r = util.get(url=url,parmas=params)
if r["code"] ==1:
jsondata = json.loads(r["msg"].decode())
result=jsondata["data"]["results"]
for itemin result:
jobName=item["jobName"]
salary=item["salary"]
eduname=item["eduLevel"]["name"]
workExpname=item["workingExp"]["name"]
city=item["city"]["display"]
companyName=item["company"]["name"]
url=item["positionURL"]
time.sleep(2)
print(url,jobName,salary,eduname,workExpname,city,companyName)
getDetail(url)
# def getDetail(url,jobName,salary,eduname,workExpname,city,companyName):
def getDetail(url):
r=util.get(url)
if r["code"]==1:
body=r["msg"].decode().replace('\n','').replace('\r','').replace('\t','')
res=re.findall('职位描述.*?岗位职责(.*?)工作地址:',body)
if len(res)>0:
# print("*"*100)
# print(res[0])
# print("=" * 100)
pass
if __name__ =='__main__':
#爬取三页信息
# for i in range(1, 4):
getInfo()
```
代码补充,自己封装的util如下
import datetime
import time
# https://www.cnblogs.com/tianyiliang/p/8270509.html
import uuid
import requests
import re
'''
如果要请求的网站,没有太多限制,为了代码写起来更好看一些,进行封装,
如果涉及到登录的时候,则不能使用此方法:
其中代理和timeout的设置是requests的,而非session
'''
def get(url, parmas=None, head=None, cookie=None, pro=None, verfiy=None):
ret = {}
ret["code"] =0
ret["msg"] =""
s = requests.session()
try:
if parmas !=None:
s.params = parmas
if head !=None:
s.headers = head
if cookie !=None:
s.cookies = cookie
if verfiy !=None:
s.verify = verfiy
if pro !=None:
r = s.get(url=url,proxies=pro,timeout=10)
else:
r = s.get(url=url,timeout=10)
ret["code"] =1
ret["msg"] = r.content
except Exception as e:
print(e)
finally:
if s:
s.close()
return ret
'''
如果要请求的网站,没有太多限制,为了代码写起来更好看一些,进行封装,
如果涉及到登录的时候,则不能使用此方法:
post与get的不同在于:post方式有两个必传参数,url,data,而get则没有data参数
'''
def post(url, data, parmas=None, headers=None, cookie=None, pro=None, verfiy=None):
ret = {}
ret["code"] =0
ret["msg"] =""
ret["cookie"] =None
s = requests.session()
try:
if parmas !=None:
s.params = parmas
if headers !=None:
s.headers = headers
if cookie !=None:
s.cookies = cookie
if verfiy !=None:
s.verify = verfiy
if pro !=None:
r = s.post(url=url,data=data,proxies=pro,timeout=10)
else:
r = s.post(url=url,data=data,timeout=10)
ret["code"] =1
ret["msg"] = r.content
ret["cookie"] = r.cookies
except Exception as e:
print(e)
finally:
if s:
s.close()
return ret
def getNoHtml(body):
dr = re.compile(r'<[^>]+>', re.S)
dd = dr.sub('', body)
return dd
def getUUID():
'''
生成UUID
:return:
'''
return str(uuid.uuid4())
```