本文讲述基于 Redis 的序列号服务的设计,主要从序列号服务的概念、需求以及服务的设计思路与详细设计等方面对其进行阐述。
〇、前言
在笔者团队中,由于分布式 ID 具有单调递增、形成序列的特性,我们习惯将分布式 ID 称为序列号(Sequence),将分布式 ID 生产系统为序列号服务系统。因此,本文以“序列号”一词均指代分布式 ID 来进行讲述。
前些天在“开发者头条”的热门分享中有一篇携程技术中心大咖写的 《分布式架构系统生成全局唯一序列号的一个思路》,文章中对多种分布式 ID 系统设计方案进行了详细的优劣对比,并重点讲述了他们最终选择以 flicker 方案为基础进行优化改进。另外,网络上阐述分布式 ID 系统的设计与实现的文章数不胜数,其中不少文章同样干货满满,笔者拜读数遍,受益匪浅,其中包括美团点评 Leaf ,微信的 seqsvr。
在此,笔者基于团队的业务适用性继续对该主题进行补充,为读者提供一种基于 Redis 的序列号服务系统的设计思路(当时主要是参考微信的 seqsvr 做的简化方案)。
一、服务介绍
1.1 概念
分布式 ID 生成系统,顾名思义,是在分布式的架构环境中,生成全局唯一标识的系统。比如在常见的业务系统中,分布式 ID 可用来标记客户号、订单号、文件号、优惠券号等,以保证这些数据的全局唯一性。正如前文所述,笔者团队所使用的分布式 ID 具有单调递增、形成序列的特性(既满足全局唯一,又满足排序的特性),被称为序列号,而生成序列号的系统被称为序列号服务。
序列号服务业内有许多方案,比如基于 UUID,基于 Redis 的 INCR 自增,基于数据库 ID 自增,基于 snowflake 的 bit 分段等等,它们各有优缺点和适用性。基于团队当前的系统量级与业务适用性,笔者团队选择了基于 Redis 的方案。
1.2 需求
笔者团队中有些业务场景与日切相关,所以将序列号分为两类,一类是递增序列(Normal Sequence)、另一类是日切序列(Batch Sequence)。
- 永增序列:永远按升序生成新序列号
- 日切序列:按日切换批次的序列,同一天按升序生成新序列号,换批次后序列号重置从 1 开始
二、服务设计
2.1 设计思路
我们知道,序列号服务实现序列号全局唯一与单调递增可排序并非难事,它的难点在于如何设计好整体架构以满足高性能,高并发以及高可用等非功能特性。
2.1.1 Redis HINCRBY 命令
Redis 的 INCR 命令支持 Key 的 “INCR AND GET” 原子操作。利用这个特性,我们可以在 Redis 中存序列号,让分布式环境中多个取号方在集中的 Redis 中通过 INCR 命令来实现取号;同时 Redis 是单进程单线程的架构,不会因为多个取号方的 INCR 命令导致取号重复。那么基于 Redis 的 INCR 命令实现序列号的生产基本能满足全局唯一与单调递增的特性,并且性能还不错。
实际上,为了存储序列号的更多相关信息,我们使用了 Redis 的 Hash 数据结构,Redis 同样为 Hash 提供 HINCRBY 命令来实现 “INCR AND GET” 原子操作,详情稍后请看 Redis 的数据结构设计。
2.1.2 Redis 宕机序列号恢复问题
我们再想想,Redis 是内存数据库,在提供高性能存取的同时,在没有开启 RDB 或者 AOF 持久化的情况下一旦宕机序列号将会有丢失。

即便开启了 RDB 持久化,由于最近一次快照时间和最新一条 HINCRBY 命令的时间有可能存在时间差,宕机后通过 RDB 快照恢复数据集会发生取号重复的情况;
而 AOF 持久化通过追加写命令到 AOF 文件的方式记录所有 Redis 服务器的写命令,服务重启后通过执行这些写命令恢复数据,理论上数据集都能恢复到最新状态,不会发生取号重复的情况;然而 AOF 持久化会损耗性能并且在宕机重启后可能由于文件过大导致恢复数据时间过长;另外,即便能通过 AOF 重写来压缩文件,如果是在写 AOF 时发生宕机导致文件出错,则需要较多时间去人为恢复 AOF 文件;所以我们需要一个恢复方案来保证 Redis 序列号服务在 Redis 宕机后可快速恢复数据并且不会导致取号重复。
2.1.3 Redis 宕机序列号恢复方案

我们可以利用关系型数据库来记录一个短时内 最大可取序列号 max,取号方从 Redis 中取号时只能取小于 max 的序列号。另外,我们可以设计两个服务:一个定期地统计序列号消费速度,另一个定期获取统计值,当 Redis 中 当前可取序列号 cur 取号接近 max 时自动更新 max 到一个适当的值,存入数据库和 Redis。在 Redis 宕机的情况下,将从数据库将最大可取序列号 max 恢复成 Redis 当前已取序列号 cur,防止 Redis 取号重复。另外,也有可能关系型数据库发生宕机,不过由于主要的取号操作在 Redis,并且设计适当的最大可取序列号 max 能够提供足够时间恢复关系型数据库。
在笔者团队当前的系统量级要求以及业务需求下,这种设计思路经过一段时间的生产实践相对适用,接下来讲述详细的系统设计。
2.2 详细设计
由于日切序列在设计上与永增序列差异不大,只是多了一个日期的维度,所以在详细设计的讲述过程中将以永增序列为主,日切序列不再赘述。
2.2.1 架构图
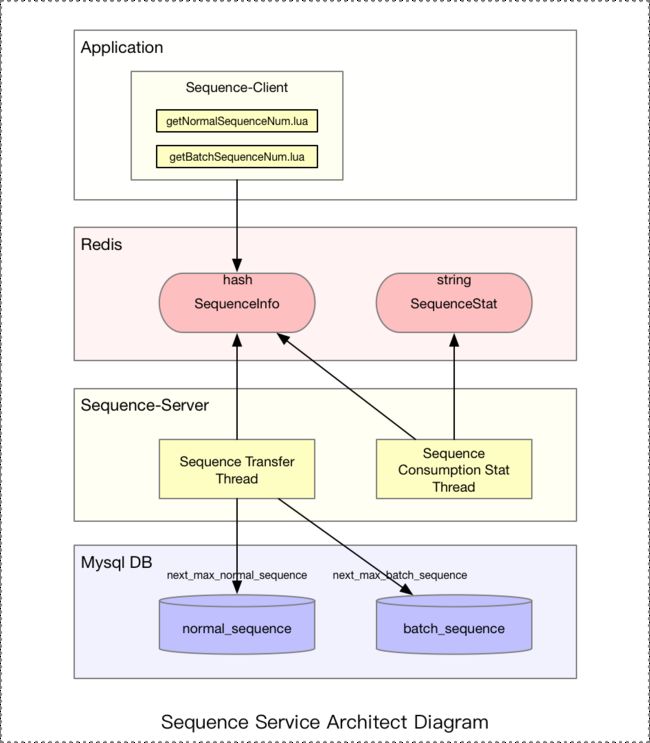
从上图可知,序列号服务分两部分:Sequence-Server 和 Sequence-Client,这两部分都依赖于 Redis 和 Mysql。我们先从 Redis 和 Mysql 的数据结构设计开始,然后再继续讲述 Server 和 Client 的部分。
2.2.2 Redis 数据结构
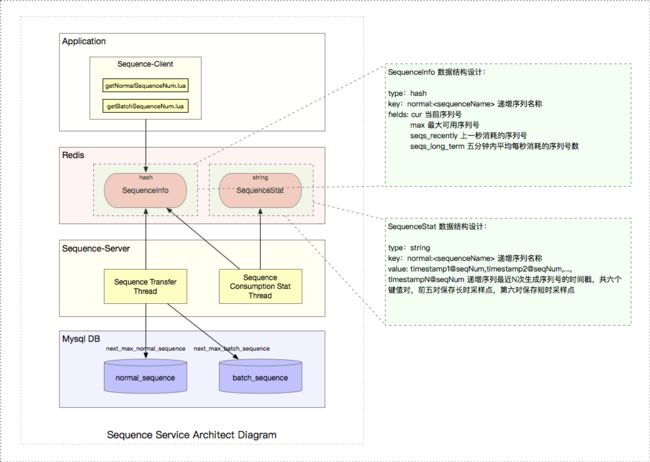
A. Sequence Info —— 序列号相关信息
1) 数据结构
| 类型 | 值 | 说明 |
|---|---|---|
| type | hash | 哈希数据结构 |
| key | normal: |
递增序列名称 |
| fields | cur | 当前序列号 |
| - | max | 最大可用序列号 |
| - | seqs_recently | 上一秒消耗的序列号数 |
| - | seqs_long_term | 五分钟内平均每秒消耗的序列号数 |
取号方应用通过 Sequence-Client 获取序列号的时候,通过 HINCRBY 命令增加 cur 的值并且取出,然后校验当前值是否超出了最大可用序列号 max。seqs_recently 和 seqs_long_term 记录了 sequenceName 这个序列近期(上一秒)和长期(五分钟内平均每秒)消耗的序列号数,Sequence Server 用它来计算每次增大 max 的步长。
2) 数据样例

上图显示最大可用序列号 max为 36100,当前已取序列号 cur为 18105,上一秒消耗的序列号数 seqs_recently为 0,五分钟内平均每秒消耗的序列号数seqs_long_term为 0。
B. Sequence Stat —— 序列号采样信息
1) 数据结构
| 类型 | 值 | 说明 |
|---|---|---|
| type | String Value | 字符串 |
| key | normal: |
递增序列名称 |
| value | timestamp1@seqNum,...,timestamp6@seqNum | 递增序列最近N次生成序列号的时间戳,共六个键值对,前五对保存长时采样点,第六对保存短时采样点 |
2) 数据样例

2.2.3 MySql 数据结构
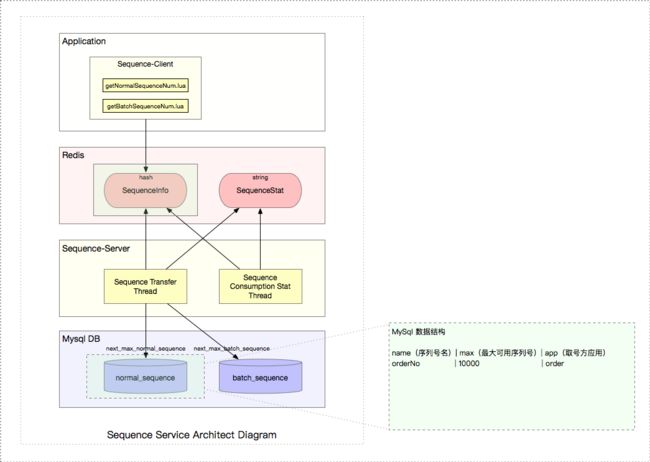
另外,编写数据库自定义函数 —— 更新数据库 最大可取序列号 max(其中 last_insert_id(max + step) 为了保证事务),如下:
CREATE FUNCTION `next_max_normal_sequence`(sequence_name varchar (50), step int(11))
RETURNS bigint(20)
BEGIN
update normal_sequence set max = last_insert_id(max + step) where name = sequence_name;
return last_insert_id();
END;
2.2.4 Sequence-Server
Sequence-Server 依赖 MySql 数据库生成和更新 最大可取序列号 max,并开启两个常驻线程把序列号相关信息和统计信息更新到 Redis。
A. Sequence Transfer Thread

常驻线程 Sequence Transfer Thread 负责定时(每秒一次)通过上一秒消耗序列号数 seqs_recently 和近五分钟平均每秒消耗序列号数 seqs_long_term,预估下一秒消耗的序列号数,从而预估未来十五分钟将消耗的序列号数。如果当前剩余序列号数不足以支撑十五分钟,则计算未来三十分钟将消耗的序列号数作为步长,更新 max 到 MySql 和 Redis,保证取号方应用每次都能获取到有效的序列号。
B. Sequence Stat Thread

常驻线程 Sequence Stat Thread 负责定时(每秒一次)统计取号速率,以便自动调整 Mysql 与 Redis 中的 最大可取序列号 Max)。
2.2.5 Sequence-Client
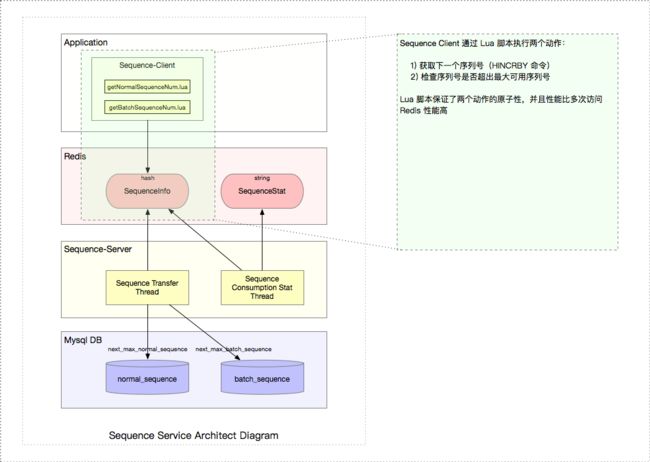
Sequence-Client 以 jar 包的形式被取号方的应用所引用,它通过封装 “INCR AND GET、校验序列号是否在有效范围” 这两个操作到 Lua 脚本中实现原子性以及避免多次访问redis造成的性能消耗。
-- Sequence-Client Lua 脚本
local maxSeqNumStr = redis.pcall("HGET", KEYS[1], "max")
if type(maxSeqNumStr) == 'boolean' and maxSeqNumStr == false then
return nil
end
local maxSeqNum = tonumber(maxSeqNumStr)
local seqNum = redis.pcall("HINCRBY", KEYS[1], "cur", 1)
if seqNum <= maxSeqNum then
return seqNum
else
return nil
end
三、服务总结
当前序列号服务方案满足:
- 序列号全局唯一
- 日切序列单日内序列号全局唯一
- 序列号单调递增可排序
- 高并发
- 可用性
- Redis(主备) + Mysql
在本机的性能测试如下:
| 线程数 | 平均响应时间(毫秒) | 吞吐量(个/秒) |
|---|---|---|
| 1 | 4 | 233 |
| 10 | 5 | 1989 |
| 100 | 16 | 5923 |
| 500 | 19 | 5505 |
总的来讲,当前我们设计的序列号服务依旧能适用于业务需要。随着系统量级的增大以及业务需求的变更与演进,序列号服务也会随之做出调整。比如 Redis 性能可能成为瓶颈,那么可以在 sequence client 的 HINCRBY 命令上增加大于 1 的增量,提供批量获取序列号的功能(需要调整统计序列号消费速率来协助自动调整 max 值);也可以为取号方提供 Redis 的分片功能,不同的取号方在各自 Redis 中取序列号等等。
至此本文结束,希望可以为读者提供一种基于 Redis 的序列号服务系统的设计思路。当然,其中方案的优缺点以及改进点,读者亦可自行思考总结,找到适用于自己的方案。
转载声明:未经授权不得转载,授权后转载请注明出处并附上原文链接。
更多阅读请关注【泛金融技术】微信公众号。

