1、文件上传 -put
[root@mini3 ~]# echo duanchangrenzaitianya > cangmumayi.avi
//将cangmumayi.avi上传到hdfs文件系统的根目录下
[root@mini3 ~]# hadoop fs -put cangmumayi.avi /
hadoop是表示hadoop操作,fs表示hdfs,后面与linux命令差不多,会多出”-“。
注:上传的时候会根据配置
dfs.replication
2
来备份2份,存放在指定的工作目录下/root/hadoop/hdpdata(名称会变,藏的也很深)
指定进行工作的数据目录
hadoop.tmp.dir
/root/hadoop/hdpdata
比如我这里是三台进行集群,其中两个是datanode,那么在这两台都进行了备份,如果是三台datanode,那么其中有两台备份另外一台没有。
可以去页面查看
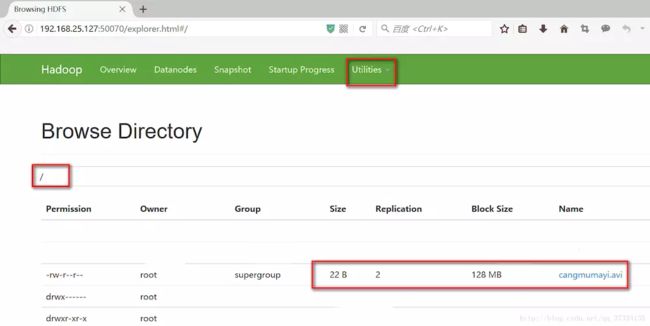
2、下载 -get
[root@mini3 ~]# rm -r cangmumayi.avi
rm:是否删除普通文件 "cangmumayi.avi"?yes
[root@mini3 ~]# ll
总用量 60
-rw-------. 1 root root 1131 9月 6 19:41 anaconda-ks.cfg
drwxr-xr-x. 4 root root 4096 9月 30 21:55 apps
drwxr-xr-x. 3 root root 4096 10月 1 19:29 hadoop
-rw-r--r--. 1 root root 12526 9月 6 19:41 install.log
-rw-r--r--. 1 root root 3482 9月 6 19:41 install.log.syslog
drwxr-xr-x. 2 root root 4096 9月 12 21:06 mini1
drwxr-xr-x. 3 root root 4096 9月 24 06:26 zkdata
-rw-r--r--. 1 root root 19113 9月 23 18:33 zookeeper.out
[root@mini3 ~]# hadoop fs -get /cangmumayi.avi
[root@mini3 ~]# ll
总用量 64
-rw-------. 1 root root 1131 9月 6 19:41 anaconda-ks.cfg
drwxr-xr-x. 4 root root 4096 9月 30 21:55 apps
-rw-r--r--. 1 root root 22 10月 3 21:21 cangmumayi.avi
drwxr-xr-x. 3 root root 4096 10月 1 19:29 hadoop
-rw-r--r--. 1 root root 12526 9月 6 19:41 install.log
-rw-r--r--. 1 root root 3482 9月 6 19:41 install.log.syslog
drwxr-xr-x. 2 root root 4096 9月 12 21:06 mini1
drwxr-xr-x. 3 root root 4096 9月 24 06:26 zkdata
-rw-r--r--. 1 root root 19113 9月 23 18:33 zookeeper.out
3、查看文件内容 -cat
[root@mini3 ~]# hadoop fs -cat /cangmumayi.avi
duanchangrenzaitianya
注:(1)HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M。
比如:我上传了一个hadoop(>128M)到hdfs中,假设有三个datanode,那么文件会切分为2个文件,存到其中两个hadoop的工作的数据目录中,假设编号分别为100026,100027,由于备份是2,那么同时第三个的工作数据目录中会存在100026,100027两个文件。但是下载的时候会自动给我们拼出来而不用我们收到去拼完整。
4、查看目录信息 -ls
[root@mini3 ~]# hadoop fs -ls /
-rw-r--r-- 2 root supergroup 22 2017-10-03 21:12 /cangmumayi.avi
5、创建文件夹 -mkdir
[root@mini3~]# hadoop fs -mkdir -p /wordcount/input(-p表示创建多级目录),页面查看可以看到多了个文件夹
6、从本地剪切到hdfs -moveFromLocal
[root@mini3 ~]# hadoop fs -moveFromLocal a.txt /
[root@mini3 ~]# hadoop fs -ls /
-rwxrwxrwx 3 root supergroup 85 2017-10-02 19:45 /a.txt
-rw-r--r-- 2 root supergroup 22 2017-10-03 21:12 /cangmumayi.avi
7、追加一个文件内容到已经存在的文件末尾 -appendToFile
[root@mini3 ~]# echo xxxxoooooxxoo > xxoo.txt
[root@mini3 ~]# hadoop fs -appendToFile xxoo.txt /a.txt
[root@mini3 ~]# hadoop fs -cat /a.txt
xiaoyu is a god
xiaoyu is beautiful
xioayu is my zhinv
xiaonv is smart
xxxxoooooxxoo
8、改权限和改组 -chgrp,-chmod,-chown
[root@mini2 ~]# hadoop fs -chmod 777 /a.txt
[root@mini2 ~]# hadoop fs -ls /
-rwxrwxrwx 2 root supergroup 85 2017-10-02 19:45 /a.txt
-rw-r--r-- 2 root supergroup 7 2017-10-01 20:22 /canglaoshi_wuma.avi
drwx------ - root supergroup 0 2017-10-01 23:36 /tmp
drwxr-xr-x - root supergroup 0 2017-10-02 19:31 /wordcount
[root@mini2 ~]# hadoop fs -chown angelababy:mygirls /canglaoshi_wuma.avi
[root@mini2 ~]# hadoop fs -ls /
-rwxrwxrwx 2 root supergroup 85 2017-10-02 19:45 /a.txt
-rw-r--r-- 2 angelababy mygirls 7 2017-10-01 20:22 /canglaoshi_wuma.avi
drwx------ - root supergroup 0 2017-10-01 23:36 /tmp
drwxr-xr-x - root supergroup 0 2017-10-02 19:31 /wordcount
hdfs弱的权限控制不会管权限是否合法的
9、合并下载多个文件 -getmerge,/wordcount/input文件夹下有a.txt和b.txt文件
[root@mini2 ~]# hadoop fs -getmerge /wordcount/input/*.* merg.file
[root@mini2 ~]# ll
总用量 17352
-rw-------. 1 root root 1131 9月 12 03:59 anaconda-ks.cfg
drwxr-xr-x. 4 root root 4096 9月 30 21:55 apps
-rw-r--r--. 1 root root 71 10月 1 21:01 b.tx
-rw-r--r--. 1 root root 7 10月 1 20:20 canglaoshi_wuma.avi
drwxr-xr-x. 3 root root 4096 10月 1 19:26 hadoop
-rw-r--r--. 1 root root 12526 9月 12 03:59 install.log
-rw-r--r--. 1 root root 3482 9月 12 03:59 install.log.syslog
-rw-r--r--. 1 root root 142 10月 2 19:57 merg.file
-rw-r--r--. 1 root root 14 10月 2 19:45 xxoo.txt
drwxr-xr-x. 3 root root 4096 9月 12 19:31 zkdata
-rw-r--r--. 1 root root 17699306 6月 20 15:55 zookeeper-3.4.6.tar.gz
-rw-r--r--. 1 root root 11958 9月 23 18:33 zookeeper.out
10、统计文件夹的大小信息 -du
[root@mini2 ~]# du -sh * linxu命令,为了形成与hadoopshell操作的对比
4.0K anaconda-ks.cfg
266M apps
4.0K b.tx
4.0K canglaoshi_wuma.avi
16M hadoop
16K install.log
4.0K install.log.syslog
4.0K merg.file
4.0K xxoo.txt
152K zkdata
17M zookeeper-3.4.6.tar.gz
12K zookeeper.out
[root@mini2 ~]# hadoop fs -du -s -h hdfs://mini1:9000/*
85 hdfs://mini1:9000/a.txt
7 hdfs://mini1:9000/canglaoshi_wuma.avi
22 hdfs://mini1:9000/cangmumayi.avi
13.5 M hdfs://mini1:9000/tmp
217 hdfs://mini1:9000/wordcount
hadoop fs -du -s /*这样写会出现bug,出现的是linux下的文件大小
11、设置副本的数量 -setrep
[root@mini2 ~]# hadoop fs -setrep 3 /a.txt
Replication 3 set: /a.txt
注:这里设置的副本数只是记录在namenode的元数据中,是否真的会有这么多副本,还得看datanode的数量,比如这个时候去页面查看就有三个副本了但是如果只有三台机器最多只能有三个,即使设置了10个显示了是个副本也没用。
另外还有一些其他的常用命令就不详细写了
12、从本地文件系统中拷贝文件到hdfs路径去 -copyFromLocal
hadoop fs -copyFromLocal a.txt /wordcount
13、从hdfs拷贝到本地 -copyToLocal
14、从hdfs的一个路径拷贝hdfs的另一个路径 -cp
hadoop fs -cp /wordcount/a.txt /bbb/b.txt
15、在hdfs目录中移动文件 -mv
hadoop fs -mv /wordcount/a.txt /
16、删除文件或者文件夹 -rm
hadoop fs -rm -r /aaa/a.txt
17、统计文件系统的可用空间信息 -df
hadoop fs -df -h /
能看出hadoop的shell操作与linux命令大部分都是一样的。
而对于操作是否成功很多都是可以直接在页面看到。
谢谢