ConcurrentHashMap并发安全的实现原理~java8
前言
上一篇聊到Java7,今天来聊聊Java8是怎么保证并发安全的。
ConcurrentHashMap in Java8
jdk版本:jdk1.8.0_41
构造器
/**
* Creates a new, empty map with the default initial table size (16).
* 创建一个新的空Map,默认初始hash表大小为16(这里依然是延迟实例化,所以构造器中并没有任何代码)
*/
public ConcurrentHashMap() {
}
/**
* Creates a new, empty map with an initial table size based on
* the given number of elements ({@code initialCapacity}), table
* density ({@code loadFactor}), and number of concurrently
* updating threads ({@code concurrencyLevel}).
*
* @param initialCapacity the initial capacity. The implementation
* performs internal sizing to accommodate this many elements,
* given the specified load factor.
* @param loadFactor the load factor (table density) for
* establishing the initial table size
* @param concurrencyLevel the estimated number of concurrently
* updating threads. The implementation may use this value as
* a sizing hint.
* 并发级别,预估的并发更新线程数量。本实现可能会使用该值作为hash表大小参考。
* @throws IllegalArgumentException if the initial capacity is
* negative or the load factor or concurrencyLevel are
* nonpositive
*/
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
// 初始容量至少为并发线程的个数
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
// 计算hash表的大小=预估容量/负载因子,这么做,是为了降低hash冲突概率
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
// 调整容量为2的幂次
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
/**
* Initializes table, using the size recorded in sizeCtl.
*/
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
// hash表大小
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
// 创建hash表
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
// 计算扩容阈值,等价于n-1/4n,反映的是负载因子0.75,也是利用了大小为2的幂次的便利。
sc = n - (n >>> 2);
}
} finally {
// 赋值给到阈值成员变量
sizeCtl = sc;
}
break;
}
}
return tab;
}
- 默认构造器就不必多说了
- 带并发级别的构造器
- 并发级别只是作为hash表大小的参考了,不再像Java7那样决定有多少把锁了
- sizeCtl的巧用。在构造器中,表现的是初始化hash表的大小/容量,而在初始化数组后,就一直是阈值了。这也是为啥要取名为sizeCtl,而不是size,也不是threshold了,因为它包含两层含义。
不管是默认的构造器,还是其他带参构造器,都没有实例化hash表,都是延迟实例化,在put方法中检查并通过上面的initTable来实例化的。
put操作
/**
* Maps the specified key to the specified value in this table.
* Neither the key nor the value can be null.
*
* The value can be retrieved by calling the {@code get} method
* with a key that is equal to the original key.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with {@code key}, or
* {@code null} if there was no mapping for {@code key}
* @throws NullPointerException if the specified key or value is null
*/
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 将hash值进一步分散。让高位跟低位信息充分保留下来。
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
// 实例化hash表
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 该槽位恰好为空,则通过CAS保存
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 该位置不为空,则锁住该位置所有元素
// 锁对象f,则为链表的第一个元素
synchronized (f) {
// doubleCheck,避免在取锁后发生改变了
if (tabAt(tab, i) == f) {
// hash值有几个特殊的定义,见:D:/InfoTechHome/Tools/java-se-8u41-ri/src.zip!/java/util/concurrent/ConcurrentHashMap.java:594
// -1~-3都表示特定的场景,例如ConcurrentHashMap#TREEBIN=-2,表示为红黑树。而红黑数的第一个元素的hash值为该值。
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// key是同一个对象,更新value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// 否则,继续检查链表的后一个元素,如果没有相同的key,则追加到链表的末尾
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
// 红黑树
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
// 超过树化阈值8,则转为红黑树。这里会将树的第一个元素的hash设置为-2,进行标识
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 通过CAS操作,更新计数器。但注意,是每一个槽都有自己的一个计数器,同样也是通过减小锁粒度,来减小竞争。
addCount(1L, binCount);
return null;
}
上图
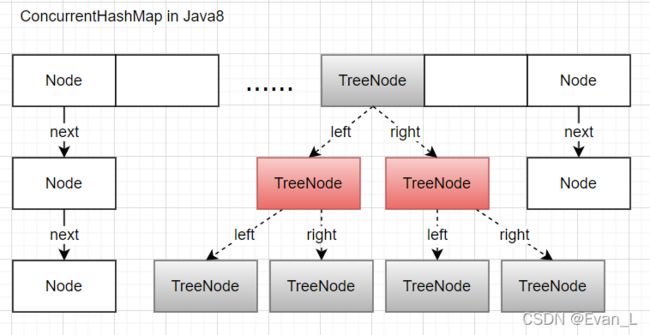
小结:
- Java8中的数据结构为数组+链表/红黑树。
- 当某一次的put操作,使得某个槽位发生hash冲突的次数大于等于8(即,该链表长度达到了8个),则会将该槽位转为红黑树。
- 当发生transfer时(例如:数组扩容),检查到某个槽位中的元素已经少于6个了,那么则退化为链表。
- 每次操作某个槽位时,都以该槽位的第一个元素作为锁对象,通过synchronized关键字上锁。以此来保证put操作的并发安全性。
- 通过counterCells:CounterCell[],让计数器也没竞争。
- 在Java7中的并发级别参数,几乎失去了意义。
- 在Java8中,不再使用Segment。通过Synchronized+CAS保证并发安全。
总结
相比与Java7的Segment各自管理一张hash表,Java8直接让每一个槽位都有一把锁,并且不需要额外创建锁对象,直接使用槽中的第一个元素作为锁对象。这是多么顺其自然,却又多么巧妙。需要锁的时候,锁对象天然存在,不需要锁的时候,也没有锁对象,用户需要保存的元素就是锁对象!这就是synchronized(f)所代表的含义!而这背后,还是分段锁思想!把锁粒度降低!妙啊!!!