利用Python进行数据分析(Ⅲ)
利用Python进行数据分析(Ⅲ)
本文参考书籍:《利用Python进行数据分析》
目录
- 利用Python进行数据分析(Ⅲ)
-
- 7.数据清洗与准备
-
- 7.1 处理缺失值
-
- 7.1.1 过滤缺失值
- 7.1.2 补全缺失值
- 7.2 数据转换
-
- 7.2.1 删除重复值
- 7.2.2 使用函数或映射进行数据转换
- 7.2.3 替代值
- 7.2.4 重命名轴索引
- 7.2.5 离散化和分箱
- 7.2.6 检测和过滤异常值
- 7.2.7 置换和随机抽样
- 7.2.8 计算指标/虚拟变量
- 7.3 字符串操作
-
- 7.3.1 字符串对象方法
- 7.3.2 正则表达式
- 7.3.3 pandas中的向量化字符串函数
- 8. 数据规整:连接、联合与重塑
-
- 8.1 分层索引
-
- 8.1.1 重排序和层级排序
- 8.1.2 按层级进行汇总统计
- 8.1.3 使用DataFrame的列进行索引
- 8.2 联合与合并数据集
-
- 8.2.1 数据库风格的DataFrame连接
- 8.2.2 根据索引合并
- 8.2.3 沿轴向连接
- 8.2.4 联合重叠数据
- 8.3 重塑和透视
-
- 8.3.1 使用多层索引进行重塑
- 8.3.2 将“长”透视为“宽”
- 8.3.3 将“宽”透视为“长”
- 9.绘图与可视化
-
- 9.1 简明matplotlib API入门
-
- 9.1.1 图片与子图
-
- 9.1.1.1 调整子图周围的间距
- 9.1.2 颜色、标记和线类型
- 9.1.3 刻度、标签和图例
-
- 9.1.3.1 设置标题、轴标签、刻度和刻度标签
- 9.1.3.2 添加图例
- 9.1.4 注释与子图加工
- 9.1.5 将图片保存到文件
- 9.1.6 matplotlib设置
- 9.2 使用pandas和seaborn绘图
-
- 9.2.1 折线图
- 9.2.2 柱状图
- 9.2.3 直方图和密度图
- 9.2.4 散点图或点图
- 9.2.5 分面网格和分类数据
7.数据清洗与准备
7.1 处理缺失值
对于数值型数据,pandas使用浮点值NaN(Not a Number表示缺失值)

python内建的None值在对象数组中也被当作NA处理:

以下为处理缺失值的相关函数:

7.1.1 过滤缺失值
在Series上使用dropna,它会返回Series中所有的非空数据及其索引值:

当处理DataFrame对象时,dropna默认情况下会删除包含缺失值的行:

传入how='all’时,将删除所有值均为NA的行:

若要用同样的方式去删除列,传入参数axis=1:

若只想保留包含一定数量的观察值的行,可以用thresh参数表示:

7.1.2 补全缺失值
可使用fillna方法补全缺失值。调用fillna时,可使用一个常数来替代缺失值:

在调用fillna时使用字典,可为不同列设定不同的缺失值:

fillna返回的是一个新的对象,但也可以修改已经存在的对象:

用于重建索引的相同的插值方法也可用于fillna:


可将Series的平均值或中位数用于填充缺失值:

下列为fillna函数的参数:

7.2 数据转换
7.2.1 删除重复值

DataFrame的duplicated方法返回的是一个布尔值Series,该Series反映的是每一行是否存在重复(与之前出现过的行相同)情况:
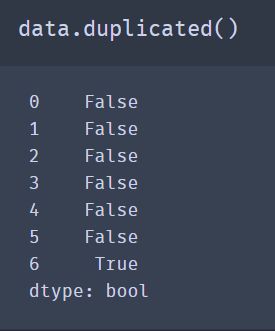
drop_duplicates返回的是DataFrame,内容是duplicated返回数组中为False的部分:

这些方法默认都是对列进行操作,可以指定数据的任何子集来检测是否有重复。假设有一个额外的列,并想基于’k1’列去除重复值:

duplicated和drop_duplicates默认都是保留第一个观测到的值。传入参数keep='last’将会返回最后一个:

7.2.2 使用函数或映射进行数据转换

若要添加一列用于表明每种食物的动物肉类型。先写下一个食物和肉类的映射:

Series的map方法接收一个函数或一个包含映射关系的字典型对象。先使用Series的str.lower方法将每个值都转换为小写:

也可以传入一个能够完成所有工作的函数:

7.2.3 替代值
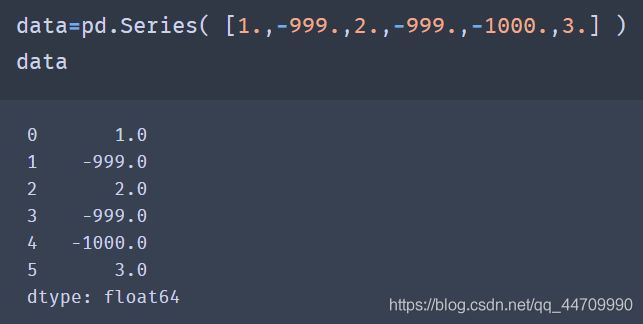
若要使用NA替代-999,可以使用replace方法生成新的Series(除非传入了inplace=True):

若想要一次替代多个值,可以传入一个列表和替代值:

要将不同的值替换为不同的值,可以传入替代值的列表:

参数也可以通过字典传递:

7.2.4 重命名轴索引
和Series中的值一样,可通过函数或某种形式的映射对轴标签进行类似的转换,生成新的且带有不同标签的对象。也可以在不生成新的数据结构的情况下修改轴:

若想要创建数据集转换后的版本,并且不修改原有的数据集,可使用rename:

rename可结合字典型对象使用,为轴标签的子集提供新的值:

若需修改原有的数据集,传入inplace=True:

7.2.5 离散化和分箱

若需将这些年龄分为18~25、26 ~35、36 ~60以及61及以上等若干组。可使用pandas中的cut:

pandas返回的对象是一个Categorical对象。你看到的输出描述了由pandas.cut计算出的箱。可以将它当作一个表示箱名的字符串数组;它在内部包含一个categories数组,它指定了不同的类别名称以及codes属性中的ages(年龄)数据标签:

pd.value_counts(cats)是对pandas.cut的结果中的箱数量的计数
可以通过传递right=False改变哪一边是闭区间:

可通过向labels选项传递一个列表或数组来传入自定义的箱名:

若传给cut整数个的箱来代替显式的箱边,pandas将根据数据中的最小值和最大值计算出等长的箱:(precision=2的选项将10进制精度限制在两位)

qcut基于样本分位数进行分箱。取决于数据的分布,使用cut通常不会使每个箱具有相同数据量的数据点。由于qcut使用样本的分位数,可以通过qcut获得等长的箱:

可以传入自定义的分位数:

7.2.6 检测和过滤异常值

若要找出一列中绝对值大于3的值:

要选出所有值大于3或小于-3的行,可以对布尔值DataFrame使用any方法:

值可以根据这些标准来设置,下列代码限制了-3到3之间的数值:(np.sign(data)根据数据中的值的正负分别生成1和-1的数值)


7.2.7 置换和随机抽样
使用numpy.random.permutation可对DataFrame中的Series或行进行置换(随机重排序)。在调用permutation时根据想要的轴长度可产生一个表示新顺序的整数数组:

整数数组可以用在基于iloc的索引或等价的take函数中:

要选出一个不含有替代值的随机子集,可使用Series和DataFrame的sample方法:

要生成一个带有替代值的样本(允许有重复选择),将replace=True传入sample方法:

7.2.8 计算指标/虚拟变量
若DataFrame中的一列有k个不同的值,则可以衍生出一个k列的值为1和0的矩阵或DataFrame。pandas中的get_dummies可完成该功能

若想在指标DataFrame的列上加入前缀,然后与其他数据合并。在get_dummies方法中有一个前缀参数可实现该功能:

DataFrame中的一行属于多个类别的情况:

首先,从数据集中提取出所有不同流派的列表:

使用全0的DataFrame是构建指标DataFrame的一种方式:

现在,遍历每一部电影,将dummies每一行的条目设置为1.使用dummies.columns来计算每一个流派的列指标:

之后,使用.loc根据这些指标设置值:

之后,可以将结果与movies进行联合:

将get_dummies与cut等离散化函数结合使用:

7.3 字符串操作
7.3.1 字符串对象方法
一个逗号分隔的字符串可以使用split方法拆分成多块:

split常和strip一起使用,用于清除空格(包括换行):

在字符串’::'的join方法中传入一个列表或元组可以使子字符串连接在一起:

使用python的in关键字可检测子字符串,index和find也能实现同样的功能:

count返回的是某个特定的子字符串在字符串中出现的次数:

replace用一种模式替代另一种模式,它通常也用于传入空字符串来删除某个模式:

下列为一些python字符串方法:

7.3.2 正则表达式
正则表达式提供了一种在文本中灵活查找或匹配(通常更为复杂的)字符串模式的方法。单个表达式通常被称为regex,是根据正则表达式语言形成的字符串。Python内建的re模块是用于将正则表达式应用到字符串上的库
re模块主要有三个主题:模式匹配、替代、拆分。一个正则表达式描述了在文本中需要定位的一种模式,可以用于多种目标。
假设我们想将含有多种空白字符(制表符、空格、换行符)的字符串拆分开。描述一个或多个空白字符的正则表达式是\s+:

当调用re.split(’\s+’,text),正则表达式首先会被编译,然后正则表达式的split方法在传入文本上被调用。可以使用re.compile自行编译,形成一个可复用的正则表达式对象:

若想获得一个所有匹配正则表达式的模式的列表,可以使用findall方法:

match和search与findall相关性很大。findall返回的是字符串中所有的匹配项,而search返回的仅仅是第一个匹配项。match更为严格,它只在字符串的起始位置进行匹配。

在文本上使用findall会生成一个电子邮件地址的列表:

search返回的是文本中第一个匹配到的电子邮件地址。对于前面的正则表达式,匹配对象只能告诉我们模式在字符串中起始和结束的位置:

regex.match只在模式出现于字符串起始位置时进行匹配,若没有匹配到,返回None:

sub会返回一个新的字符串,原字符串中的模式会被一个新的字符串替代:

若想查找电子邮件地址,并把每个地址分为3个部分:用户名、域名和域名后缀,可以用括号将模式包起来:

由这个修改后的正则表达式产生的匹配对象的groups方法,返回的是模式组件的元组:

当模式可以分组时,findall返回的是包含元组的列表:

sub也可以使用特殊符号,如\1和\2,访问每个匹配对象中的分组。符号\1代表的是第一个匹配分组,\2代表的是第二个匹配分组,以此类推:

下列为正则表达式方法:

7.3.3 pandas中的向量化字符串函数
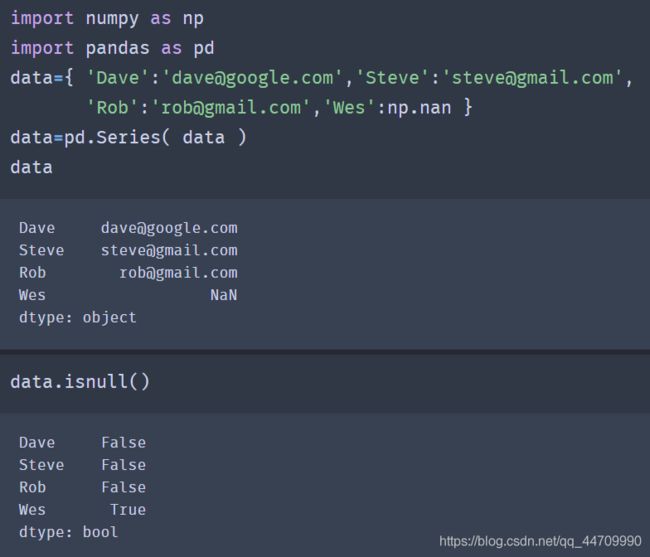
可以使用data.map将字符串和有效的正则表达式方法(以lambda或其他函数的方式传递)应用到每个值上,但是在NA(null)值上会失败。为解决该问题,Series有面向数组的方法用于跳过NA值的字符串操作。这些方法通过Series的str属性进行调用,例如,可以通过str.contains来检查每个电子邮件地址是否含有’gmail’:

正则表达式可结合任意的re模块选项使用,例如IGNORECASE:

有多种方法可以进行向量化的元素检索,可使用str.get或在str属性内部索引:

要访问嵌入式列表中的元素,可以将索引传递给这些函数中的任意一个:


可以使用字符串切片的类似语法进行向量化切片:

下列为pandas中部分向量化字符串方法:


8. 数据规整:连接、联合与重塑
8.1 分层索引
pandas的分层索引允许在一个轴向上拥有多个(两个或两个以上)索引层级。分层索引提供了一种在更低维度的形式中处理更高维度数据的方式
以一个简单的例子开始,先创建一个Series,以列表的列表(或数组)作为索引:

通过分层索引对象,也可称为部分索引,允许选出数据的子集:

在“内部”层级中进行选择也是可以的:

分层索引可在重塑数据和数组透视表等分组操作中发挥作用。如,可以使用unstack方法将数据在DataFrame中重新排列:

unstack的反操作是stack:

在DataFrame中,每个轴都可以有分层索引:

分层的层级可以有名称(可以是字符串或Python对象)。若层级有名称,这些名称会在控制台输出中显示:

通过部分列索引,可选出列中的组:

一个MultiIndex对象可以使用其自身的构造函数创建并复用:

8.1.1 重排序和层级排序
swaplevel接收两个层级序号或层级名称,返回一个进行了层级变更的新对象(但是数据不变):

sort_index只能在单一层级上对数据进行排序。在进行层级变换时,使用sort_index可使得结果按照层级进行字典排序:

8.1.2 按层级进行汇总统计
DataFrame和Series中很多描述性和汇总性统计有一个level选项,通过level选项可以指定想要在某个特定的轴上进行聚合。

8.1.3 使用DataFrame的列进行索引

DataFrame的set_index函数会生成一个新的DataFrame,新的DataFrame使用一个或多个列作为索引:
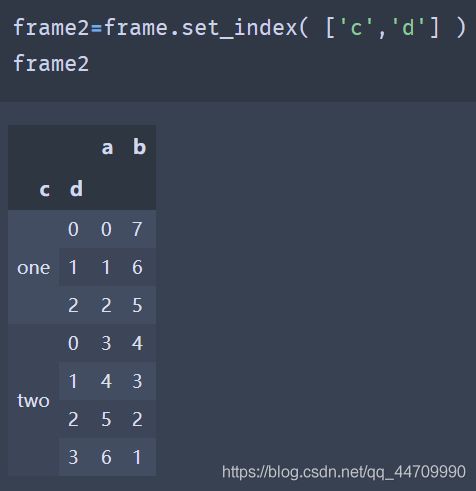
默认情况下,这些列会从DataFrame中移除,也可以将它们留在DataFrame中:

reset_index是set_index的反操作,分层索引的索引层级会被移动到列中:

8.2 联合与合并数据集
包含在pandas对象的数据可以通过多种方式联合在一起:
- pandas.merge根据一个或多个键将行进行连接。类似于数据库中的连接操作
- pandas.concat使对象在轴向上进行黏合或“堆叠”
- combine_first实例方法允许将重叠的数据拼接在一起,以使用一个对象中的值填充另一个对象中的缺失值
8.2.1 数据库风格的DataFrame连接
合并或连接操作通过一个或多个键连接行来联合数据集。pandas中的merge函数主要用于将各种join操作算法运用在你的数据上:


上例中没有指定在哪一列上进行连接。若连接的键的信息没有指定,merge会自动将重叠列名作为连接的键。可显式地指定连接键:

若每个对象的列名是不同的,可以分别为它们指定列名:

默认情况下,merge做的是内连接,结果中的键是两张表的交集。其他可选的选项有’left’、‘right’、‘outer’。外连接是键的并集,联合了左连接和右连接的效果:

how参数的不同连接类型如下:




使用多个键进行合并时,传入一个列名的列表:

merge有一个suffixes后缀选项,用于在左右两边DataFrame对象的重叠列名后指定需要添加的字符串:

merge函数的参数如下:

8.2.2 根据索引合并
在某些情况下,DataFrame中用于合并的键是它的索引。在这种情况下,可以传递left_index=True或right_index=True(或者都传)来表示索引需要用来作为合并的键:


在多层索引数据的情况下,在索引上连接是一个隐式的多键合并:

这种情况下,必须以列表的方式指明合并所需多个列(注意使用how='outer’处理重复的索引值):

可使用两边的索引进行合并:


DataFrame中的join方法可用于按照索引合并。该方法也可以用于合并多个索引相同或相似但没有重叠列的DataFrame对象:


对于一些简单索引-索引合并,可以向join方法传入一个DataFrame列表,这个方法可以替代concat函数:

8.2.3 沿轴向连接
另一种数据组合操作可称为拼接。Numpy的concatenate函数可以在NumPy数组上实现该功能:

假设我们有三个索引不存在重叠的Series:

用列表中的这些对象调用concat方法会将值和索引粘在一起:

默认情况下,concat方法是沿着axis=0的轴向生效的,生成另一个Series。若传递axis=1,返回的结果是一个DataFrame:
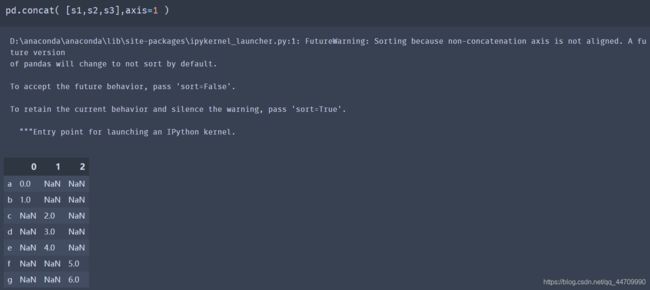
在上述例子中另一个轴向上没有重叠,可以看到排序后的索引合集(外连接)。也可以传入join=‘inner’:



可以用join_axes来指定用于连接其他轴向的轴:

假设想在连接轴向上创建一个多层索引,可以使用keys参数实现:

沿着轴向axis=1连接Series的时候,keys则成为DataFrame的列头:

将相同的逻辑拓展到DataFrame对象:

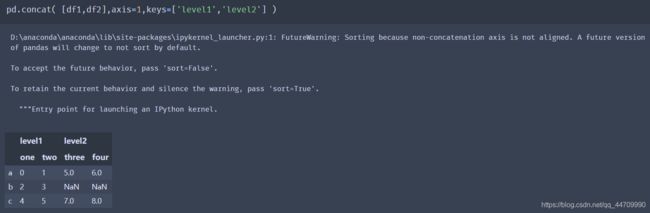
若传递的是对象的字典而不是列表的话,则字典的键会用于keys选项:

还有一些额外的参数负责多层索引生成。例如,可以使用names参数命名生成的轴层级:

考虑行索引中不包含任何相关数据的DataFrame:

传入ignore_index=True:

concat函数的参数如下:

8.2.4 联合重叠数据
可能有两个数据集,这两个数据集的索引全部或部分重叠。作为一个示例,考虑Numpy的where函数,这个函数可以进行面向数组的if-else等价操作:

Series有一个combine_first方法:

在DataFrame中,combine_first逐列做相同的操作,可以认为它是根据传入的对象来“修补”调用对象的缺失值:


8.3 重塑和透视
8.3.1 使用多层索引进行重塑
多层索引在DataFrame中提供了一种一致性方式用于重排列数据。以下是两个基础操作:
stack(堆叠):
该操作会“旋转”或将列中的数据透视到行
unstack(拆堆):
该操作会将行中的数据透视到列
考虑一个带有字符串数组作为行和列索引的DataFrame:

在这份数据上使用stack方法会将列透视到行,产生一个新的Series:

从一个多层索引序列中,可以使用unstack方法将数据重排列后放入一个DataFrame中:

默认情况下,最内层是已拆堆的(与stack方法一样)。可以传入一个层级序号或名称来拆分一个不同的层级:

若层级中的所有值并未包含于每个子分组中时,拆分可能会引入缺失值:

默认情况下,堆叠会过滤出缺失值,因此堆叠拆堆的操作是可逆的:
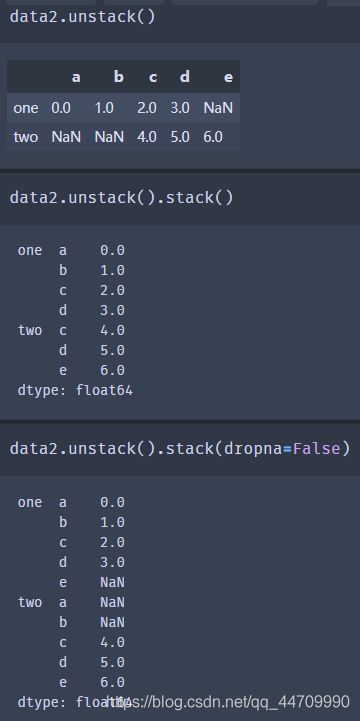
当在DataFrame中拆堆时,被拆堆的层级会变为结果中最低的层级:

在调用stack方法时,可以指明需要堆叠的轴向名称:

8.3.2 将“长”透视为“宽”


可能想获取一个按date列时间戳索引的且每个不同的item独立一列的DataFrame,DataFrame的pivot方法可进行这种转换:

传递的前两个值是分别用作行和列索引的列,然后是可选的数值列以填充DataFrame。假设有两个数值列,想同时进行重塑:

若遗漏最后一参数,会得到一个含有多层列的DataFrame:

pivot方法等价于使用set_index创建分层索引,然后调用unstack:

8.3.3 将“宽”透视为“长”
在DataFrame中,pivot方法的反操作是pandas.melt。与将一列变换为新的DataFrame中的多列不同,它将多列合并成一列,产生一个新的DataFrame,其长度比输入更长。

key列可以作为分组指标,其他列均为数据值。当使用pandas.melt时,必须指明哪些列是分组指标。此处,使用’key’作为唯一的分组指标:

使用pivot方法,可以将数据重塑回原先的布局:

由于pivot的结果根据作为行标签的列生成了索引,可以使用reset_index来将数据回移一列:
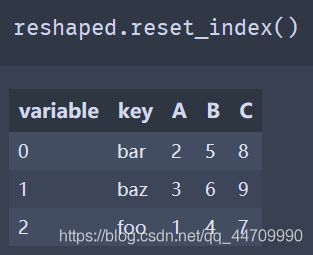
也可以指定列的子集作为值列:

pandas.melt的使用也可以无须任何分组指标:

9.绘图与可视化
在jupyter notebook中使用交互式绘图,在进行设置时,需执行:
![]()
9.1 简明matplotlib API入门


9.1.1 图片与子图
matplotlib所绘制的图位于图片(Figure)对象中。可以使用plt.figure生成一个新的图片:

plt.figure有一些选项,如figsize是确保图片有一个确定的大小以及存储到硬盘时的长宽比
可使用add_subplot创建一个或多个子图(subplot):


当输入绘图命令plt.plot([1.5,3.5,-2,1.6]),matplotlib会在最后一个图片和子图(如果需要的话就创建一个)上进行绘制,从而隐藏图片和子图的创建。

'k–'是用于绘制黑色分段线的style选项。fig.add_subplot返回的对象是AxesSubplot对象,使用这些对象可以直接在其他空白的子图上调用对象的实例方法进行绘图:


matplotlib中的方法plt.subplots将创建一个新的图片,然后返回包含了已生成子图对象的Numpy数组:


数组axes可以像二维数组那样方便地进行索引,如,axes[0,1]。也可以通过使用sharex和sharey来表明子图分别拥有相同的x轴或y轴。
pyplot.subplots的选项如下:

9.1.1.1 调整子图周围的间距
默认情况下,matplotlib会在子图的外部和子图之间留出一定的间距。这个间距都是相对于图的高度和宽度来指定的,所以如果通过编程或手动使用GUI窗口来调整图的大小,那么图就会自动调整。可以使用图对象上的subplots_adjust方法更改间距,也可用作顶层函数:


9.1.2 颜色、标记和线类型
matplotlib的主函数plot接收带有x和y轴的数组以及一些可选的字符串缩写参数来指明颜色和线类型。例如,要用绿色破折号绘制x对y的线,需执行:

同样的图表可以使用更为显式的方式来表达:
![]()
折线图可以有标记用于凸显实际的数据点。由于matplotlib创建了一个连续性折线图,插入点之间有时并不清楚点在哪。标记可以是样式字符串的一部分,样式字符串中线类型、标记类型必须跟在颜色后面:


上述代码可以显式表示为:
![]()
对于折线图,注意到后续的点默认是线性内插的。可通过drawstyle选项进行更改:


这里,由于向plot传递了label,可以使用plt.legend为每条线生成一个用于区分的图例
9.1.3 刻度、标签和图例
pyplot接口设计为交互式使用,包含了像xlim、xticks、xticklabels等方法。这些方法分别控制了绘图范围、刻度位置以及刻度标签。我们可以在两种方式中使用:
- 在没有函数参数的情况下调用,返回当前的参数值(例如plt.xlim()返回当前的x轴绘图范围)
- 传入参数的情况下调用,并设置参数值(例如plt.xlim([0,10])会将x轴的范围设置为0到10)
所有的这些方法都会在当前活动的或最近创建的AxesSubplot生效。这些方法中的每一个对应于子图自身的两个方法。如xlim对应于ax.get_lim和ax.set_lim。
9.1.3.1 设置标题、轴标签、刻度和刻度标签

可使用set_xticks和set_xticklabels改变x轴刻度。set_xticks表示在数据范围内设定刻度的位置,set_xticklabels为标签赋值:


轴的类型有一个set方法,允许批量设置绘图属性:

9.1.3.2 添加图例


9.1.4 注释与子图加工
可以使用text、arrow和annote方法来添加注释和文本。text在图表上给定的坐标(x,y),根据可选的定制样式绘制文本:
![]()
注释可以同时绘制文本和箭头


ax.annotate方法可以在指定的x和y坐标上绘制标签。可以使用set_xlim和set_ylim方法手动设置图表的边界
matplotlib含有表示多种常见图形的对象,这些对象的引用是patches。一些图形,如Rectangle和Circle,可以在matplotlib.pyplot中找到,但图形的全集位于matplotlib.patches
想在图表中添加图形时,需要生成patch对象shp,并调用ax.add_patch(shp)将它加入到子图中:


9.1.5 将图片保存到文件
可以使用plt.savefig将活动图片保存到文件。这个方法等价于图片对象的savefig实例方法。例如将图片保存为SVG:

savefig的选项如下:

9.1.6 matplotlib设置
可使用rc方法修改配置。例如,要将全局默认数字大小设置为10X10,可以输入:

rc的第一个参数是想要自定义的组件,比如’figure’、‘axes’、‘xtick’、‘ytick’、‘grid’、'legend’等。之后,可以按照关键字参数的序列指定新参数。字典是一种在程序中设置选项的简单方式:

9.2 使用pandas和seaborn绘图
9.2.1 折线图
Series和DataFrame都有一个plot属性,用于绘制基本的图形。默认情况下,plot()绘制的是折线图:

Series对象的索引传入matplotlib作为绘图的x轴,可以通过传入use_index=False来禁用这个功能。x轴的刻度和范围可以通过xticks和xlim选项进行调整。plot的选项如下:

DataFrame的plot方法在同一个子图中将每一列绘制为不同的折线,并自动生成图例:


DataFrame有多个选项,允许灵活地处理列。例如,是否将各列绘制在同一个子图中,或为各列生成独立的子图。DataFrame的plot参数如下:

9.2.2 柱状图
plot.bar()和plot.barh()可以分别绘制垂直和水平的柱状图。在绘制柱状图时,Series或DataFrame的索引将会被用作x轴刻度(bar)或y轴刻度(barh)


选项color='k’和alpha=0.7将柱子的颜色设置为黑色,并将图像的填充色设置为部分透明
在DataFrame中,柱状图将每一行中的值分组到并排的柱子中的一组:


可以通过传递stacked=True来生成堆积柱状图,会使得每一行的值堆积在一起:

使用value_counts:s.value_counts().plot.bar()可以对Series值频率进行可视化
假设想要绘制一个堆积柱状图,用于展示每个派对在每天的数据点占比:

之后,进行标准化以确保每一行的值和为1,然后进行绘图:


对于在绘图前需要聚合或汇总的数据,使用seaborn包会使工作更简单。用seaborn进行按星期日期计算小费百分比:


seaborn中的绘图函数使用一个data参数,这个参数可以是pandas的DataFrame。其他的参数则与列名有关。因为day列中有多个观测值,柱子的值是tip_pct的平均值。柱子上画出的黑线代表的是95%的置信区间(置信区间可以通过可选参数进行设置)
seaborn.barplot有一个hue选项,允许我们通过一个额外的分类值将数据分离:

9.2.3 直方图和密度图
可以使用Series的plot.hist方法制作小费占总费用百分比的直方图:
![]()

密度图是一种与直方图相关的图表类型,它通过计算可能产生观测数据的连续概率分布估计而产生。通常的做法是将这种分布近似为“内核”的混合,也就是像正态分布那样简单的分布。因此,密度图也被称为内核密度估计图(KDE)。plot.kde使用传统法定混合法估计绘制密度图:

distplot方法可以绘制直方图和连续密度估计,通过distplot方法seaborn使直方图和密度图的绘制更为简单。考虑由两个不同的标准正态分布组成的双峰分布:

9.2.4 散点图或点图

seaborn的regplot方法可以绘制散点图,并拟合出一条线性回归线:
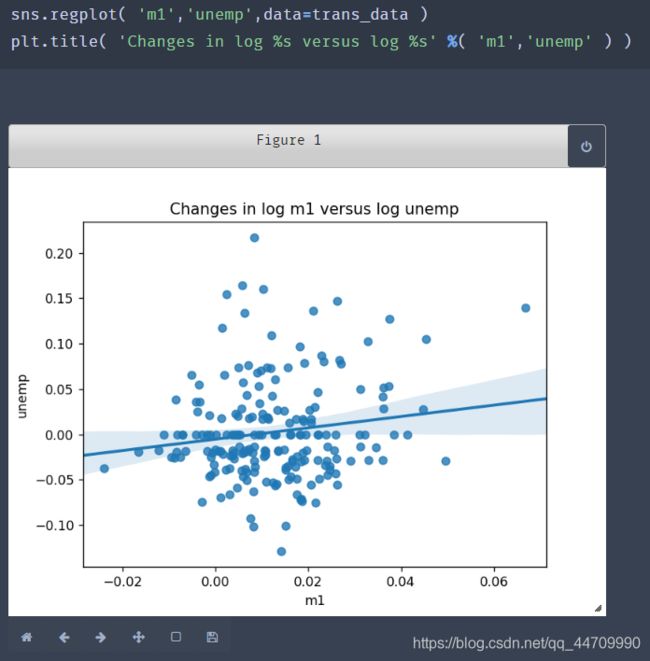
在探索性数据分析中,能够查看一组变量中的所有散点图是有帮助的,这被称为成对图或散点图矩阵。seaborn的pairplot函数支持在对角线上放置每个变量的直方图或密度估计值:

9.2.5 分面网格和分类数据
使用分面网格是利用多种分组变量对数据进行可视化的方式。seaborn拥有一个有效的内建函数factorplot,它可以简化多种分面绘图:
![]()

除了根据’time’在一个面内将不同的柱分组为不同的颜色,还可以通过每个时间值添加一行来扩展分面网格:
![]()

factorplot支持其他图类型,如箱型图(显示中位值、四分位数和异常值):
![]()
