pandas nat_数据分析之numpy与pandas
如何跨界:在自己的本职工作以外,长时间聚焦于一件事情,投入时间与精力,克服困难,才能成功跨界。
个人见解:年轻的话,可以做自己喜欢的事情,给人生做加法,尝试不同的事情,前提是尝试,并坚持一段时间,再选择自己喜欢的事情;随着年岁的增长,需要聚焦,给人生做减法,不要什么都去尝试,因为试错成本太高,选择一件工作以外的兴趣,并取得一定的成就,就可以说是成功了。
numpy:数学计算,如线性代数中的矩阵计算以及机器学习
pandas:基于numpy的数据分析工具,为解决数据分析任务而创建的,提供了一套名为数据框的数据结构,可以方便的对表结构进行数据分析
matplotlib:图形绘制库,数据分析的可视化
一维数据分析
Numpy(numerical python):数据结构(array)
Pandas:数据结构(series),基于Numpy的array
#导入numpy和pandas
import numpy as np
import pandas as pd
#创建一维数组
a = np.array([2,3,4,5])
#查询数组元素
a[0]:下标查询
a[1:3]:切片查询
for i in a:循环查询
a.dtype:数值类型Numpy 一维数组与列表的区别:
1.统计功能:平均值mean()、标准差std()
2.向量化计算:一维数组的数据类型必须一致;列表的元素可以是不同类型
#如何定义Pandas的一维数组?
stockS = pd.Series([],index=[])
#如何获取这六家公司的平均股价?
stockS.describe()
二维数据分析
(1)Numpy:数组Array
#定义一个二维数组
a = np.array([
[1,2,3,4],[5,6,7,8],[9,10,11,12]
])
#查询元素;某一行;某一列
a[0,2]
a[0,:]
a[:,0]
#numpy数组参数
#axis=1:按行计算
#axis=0:按列计算
a.mean(axis=1)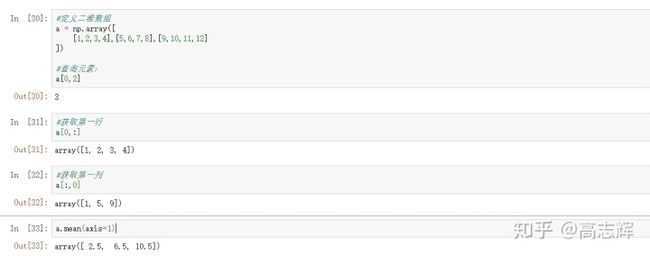
(2)Pandas:数据框DataFrame
- 定义有序字典与数据框
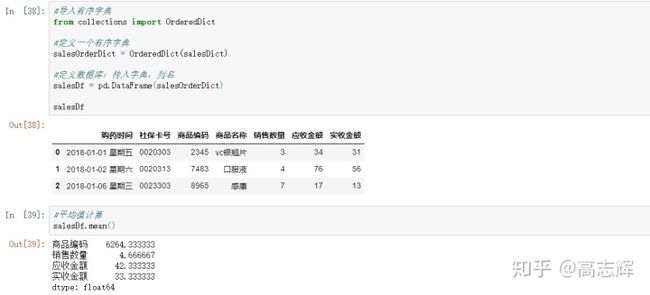
#第一步:定义一个字典,映射列名与对应列的值
salesDict = {
'购药时间':['2018-01-01 星期五','2018-01-02 星期六','2018-01-06 星期三'],
'社保卡号':['0020303','0020313','0023303'],
'商品编码':[2345,7483,8965],
'商品名称':['vc银翘片','口服液','感康'],
'销售数量':[3,4,7],
'应收金额':[34,76,17],
'实收金额':[31,56,13],
}
#导入有序字典
from collections import OrderedDict
#定义一个有序字典
salesOrderDict = OrderedDict(salesDict)
#定义数据框:传入字典,列名
salesDf = pd.DataFrame(salesOrderDict)
#输出数据框
salesDf
#计算平均值
salesDf.mean()
- iloc属性用于根据位置查询元素
#查询某个元素
salesDf.iloc[0,1]
#查询第一行
salesDf.iloc[0,:]
#查询第一列
salesDf.iloc[:,0]
- loc属性用于根据索引查询值
#元素
salesDf.loc[0,'商品名称']
#第一行
salesDf.loc[0,:]
#某一列
salesDf.loc[:,'商品名称']
- 其它查询
#查询某几列
salesDf[['商品名称','销售数量']]
#切片查询
salesDf[:,'商品名称':'销售数量']
#条件查询
querySer = salesDf[:,'销售数量']>1
#应用条件查询的结果
salesDf.loc[querySer,:]
读取excel数据
#读取excel数据
fileNameStr = 'D:/猴子/数据分析高级/第3关数据分析的基本过程/朝阳医院2018年销售数据.xlsx'
xls = pd.ExcelFile(fileNameStr)
salesDf = xls.parse('Sheet1')
#打印前5行
salesDf.head()
#查看某一列的数据类型
salesDf.loc[:,'销售数量'].dtype
#有多少行和多少列
salesDf.shape
#每一列的统计数
salesDf.describe()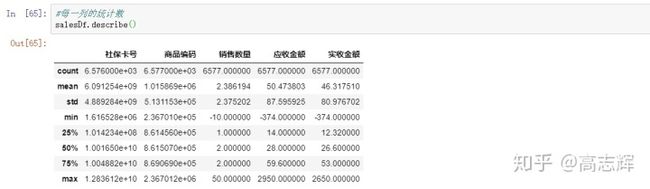
数据分析步骤:提出问题》理解数据》数据清洗》构建模型》数据可视化
数据清洗:选择子集》列名重命名》缺失数据处理》数据类型转换》数据排序》异常值处理
- 选择子集:选择需要用到的列
- 重命名:修改指定列的列名
- 缺失数据处理:删除缺失数据
- 数据类型转换:read_excel默认导入的数据是字符串类型
- 数据排序
- 异常值处理:使用条件语句删除异常值
#读取excel数据:统一先按照str读入,之后转换
fileNameStr = 'D:/猴子/数据分析高级/第3关数据分析的基本过程/朝阳医院2018年销售数据.xlsx'
salesDf = pd.read_excel(fileNameStr,sheet_name = 'Sheet1',dtype = str)
#列名重命名
#字典:旧列名和新列名对应关系
colNameDict = {'购药时间':'销售时间'}
"""inplace = False,数据框本身不会改变,而会创建一个改动后新的数据框,默认的inplace是False
inplace=True,数据框本身会改动"""
salesDf.rename(columns = colNameDict,inplace=True)
#删除列(销售时间,社保卡号)中为空的行
#how='any',在给定列中任何一列有缺失值就删除
salesDf = salesDf.dropna(subset=['销售时间','社保卡号'],how='any')
#数据类型转换
salesDf[['销售数量']] = salesDf[['销售数量']].astype('float')
salesDf[['应收金额']] = salesDf[['应收金额']].astype('float')
salesDf[['实收金额']] = salesDf[['实收金额']].astype('float')
salesDf[['销售时间']] = salesDf[['销售时间']].astype('str')处理日期数据
- 定义日期分割函数
"""定义函数:分割销售时间,获取销售日期
输入:timeColSer销售时间这一列,是个Series数据类型
输出:分割后的时间,返回也是个Series数据类型"""
def splitSaleTime(timeColSer):
timeList = []
for value in timeColSer:
dataStr = value.split(' ')[0]
timeList.append(dataStr)
#将列表转行为一维数组
timeSer = pd.Series(timeList)
return timeSer- 处理日期数据
#获取“销售时间”这一列
timeSer = salesDf.loc[:,'销售时间']
dataSer = splitSaleTime(timeSer)
#修改销售时间这一列的值
salesDf.loc[:,'销售时间'] = dataSer
#errors='coerce'如果原始数据不符合日期的格式,转换后的值为NaT
#format是你原始数据中日期的格式
salesDf.loc[:,'销售时间'] = pd.to_datetime(salesDf.loc[:,'销售时间'],format='%Y-%m-%d',
errors='coerce')删除空值
salesDf = salesDf.dropna(subset=['销售时间','社保卡号'],how='any')排序
#by:按哪几列排序
#ascending=True 表示升序排列
#ascending=False表示降序排列
#按销售日期的升序排列
salesDf = salesDf.sort_values(by='销售时间',ascending = True)删除异常值
#查询条件
querySer = salesDf.loc[:,'销售数量']>0
#应用查询条件
print('删除异常值前:',salesDf.shape)
salesDf = salesDf.loc[querySer,:]
print('删除异常值后:',salesDf.shape)计算业务指标
- 月均消费次数
#获取总消费次数
kpil_Df = salesDf.drop_duplicates(subset = ['销售时间','社保卡号'])
totalI = kpil_Df.shape[0]
#获取月份数
kpil_Df = kpil_Df.sort_values(by = '销售时间',ascending = True,na_position = 'first')
kpil_Df = kpil_Df.reset_index(drop = True)
startTime = kpil_Df.loc[0,'销售时间']
endTime = kpil_Df.loc[totalI-1,'销售时间']
daysI = (endTime-startTime).days
#计算
monthsI = daysI//30
kpil_I = totalI//monthsI
print('业务指标1:月均消费次数=',kpil_I)- 月均消费金额
#总消费金额
totalMoneyF = salesDf.loc[:,'实收金额'].sum()
monthMoneyF = totalMoneyF//monthsI
print('业务指标2:月均消费金额:',monthMoneyF)- 客单价
#客单价
pct = totalMoneyF/totalI
print('客单价:',pct)总结
学习了基础的一维数组与二维数组,以及如何读取excel中的数据。
掌握了数据分析的基本流层,以及一些数据清洗的函数,如
- .rename(column=,inplace=)
- dropna(subset='',how='any')
- .to_datetime(列名,format=,error=coerce)
- .sort_values(by='列名',ascending=True)
- .drop_duplicates(subset=[])
- .reset_index(drop=True)