《动手学深度学习》Seq2Seq、attention、transformer相关问题的总结与反思
关于Seq2Seq相关问题的总结
这里主要总结对比的是原始的seq2seq问题、带有attention机制的seq2seq问题以及transformer架构。
不是知识点的罗列,而是相关芝士的梳理以及一些问题的自己思考总结。
相关博文
Attention Is All You Need论文精读笔记
《动手学深度学习》Seq2Seq代码可能出错的原因及适当分析
文章目录
- 关于Seq2Seq相关问题的总结
-
- 一、数据集相关
- 二、Embedding层
- 三、编码器-解码器架构
-
- 编码器-解码器API
- 普通seq2seq编码器
- 普通seq2seq解码器
- 带有attention机制的解码器
- Transformer编码器层
- Transformer编码器
- Transformer解码器层【*】
- Transformer解码器
- 四、两种Attention的实现
-
- 加性attention
- 缩放点积attention
- 五、训练及预测
-
- 调用接口代码(trans为例)
- 训练
-
- 对比seq2seq、attention-seq2seq、transformer在训练时得到输出的不同
- seq2seq
- attention-seq2seq:
- transformer
- summary
- 预测
-
- 关于dec_X
- Transformer相关架构及呆码
-
- 整体架构
- 细节
一、数据集相关
准备英文-法文翻译数据集
import os
#@save
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip',
'94646ad1522d915e7b0f9296181140edcf86a4f5')
#@save
def read_data_nmt():
"""载入“英语-法语”数据集"""
data_dir = d2l.download_extract('fra-eng')
with open(os.path.join(data_dir, 'fra.txt'), 'r',
encoding='utf-8') as f:
return f.read()
raw_text = read_data_nmt()
#@save
def preprocess_nmt(text):
"""预处理“英语-法语”数据集"""
def no_space(char, prev_char):
return char in set(',.!?') and prev_char != ' '
# 使用空格替换不间断空格
# 使用小写字母替换大写字母
text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()
# 在单词和标点符号之间插入空格
out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else char
for i, char in enumerate(text)]
return ''.join(out)
text = preprocess_nmt(raw_text)
#@save
def tokenize_nmt(text, num_examples=None):
"""词元化“英语-法语”数据数据集"""
source, target = [], []
for i, line in enumerate(text.split('\n')):
if num_examples and i > num_examples:
break
parts = line.split('\t')
if len(parts) == 2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))
return source, target
source, target = tokenize_nmt(text)
src_vocab = d2l.Vocab(source, min_freq=2,
reserved_tokens=['' , '' , '' ])
#@save
def truncate_pad(line, num_steps, padding_token):
"""截断或填充文本序列"""
if len(line) > num_steps:
return line[:num_steps] # 截断
return line + [padding_token] * (num_steps - len(line)) # 填充
#@save
def build_array_nmt(lines, vocab, num_steps):
"""将机器翻译的文本序列转换成小批量"""
lines = [vocab[l] for l in lines]
lines = [l + [vocab['' ]] for l in lines]
array = torch.tensor([truncate_pad(
l, num_steps, vocab['' ]) for l in lines])
valid_len = (array != vocab['' ]).type(torch.int32).sum(1)
return array, valid_len
#@save
def load_data_nmt(batch_size, num_steps, num_examples=600):
"""返回翻译数据集的迭代器和词表"""
text = preprocess_nmt(read_data_nmt())
source, target = tokenize_nmt(text, num_examples)
src_vocab = d2l.Vocab(source, min_freq=2,
reserved_tokens=['' , '' , '' ])
tgt_vocab = d2l.Vocab(target, min_freq=2,
reserved_tokens=['' , '' , '' ])
src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)
tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)
data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)
data_iter = d2l.load_array(data_arrays, batch_size)
return data_iter, src_vocab, tgt_vocab
调用的时候只需要:
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size, num_steps)
在每一个batch训练的时候,train_iter会返回原句、原句长、译句、译句长。
{例如batch_size = 2, 总长是5,返回的原句就类似于(其中1表示bos,3表示eos,2表示padding):
【 【1,4,5,3,2】
【1,4,3,2,2】】
}
二、Embedding层
为了更好的体现词之间的关系,我们放弃了使用最简单的one-hot编码。【理解:one-hot编码也可以看做一种embedding,最简单的】
关于embedding层相关的芝士不是这里的重点,可以看吴恩达相关视频(word2vec).
这里我们直接调用pytorch中的框架即可:
调用 torch.nn.Embedding(m, n) ,m 表示单词的总数目,n 表示词嵌入的维度,其实词嵌入就相当于是一个大矩阵,矩阵的每一行表示一个单词。
可以从头开始训练(沐神课程中都是这么做的),也可以利用别人已经训练好的【
15.2. 情感分析:使用递归神经网络 — 动手学深度学习 2.0.0-beta0 documentation (d2l.ai) <-- 这里面使用了预训练好的glove-100;
15.3. 情感分析:使用卷积神经网络 — 动手学深度学习 2.0.0-beta0 documentation (d2l.ai) <-- 这里面用了预训练好的glove-100, 也用了自己从头训练的embedding。
】
关于pytorch中embedding层的使用方法:
pytorch中的embedding词向量的使用方法_python_脚本之家 (jb51.net)
三、编码器-解码器架构
无论是原始seq2seq、采用attention机制的seq2seq还是transformer,均是采用编码器-解码器架构实现的。
编码器-解码器API
以下所有实现的编码器-解码器都是根据这个框架来修改的:
#@save
class Encoder(nn.Module):
"""编码器-解码器架构的基本编码器接口"""
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
# 给一个输入X, 返回一个输出self
def forward(self, X, *args):
raise NotImplementedError
#@save
class Decoder(nn.Module):
"""编码器-解码器架构的基本解码器接口"""
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
# 这里输入是Encoder的输出
def init_state(self, enc_outputs, *args):
raise NotImplementedError
# 解码器可以有输入
def forward(self, X, state):
raise NotImplementedError
#@save
class EncoderDecoder(nn.Module):
"""编码器-解码器架构的基类"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
普通seq2seq编码器
class Seq2SeqEncoder(d2l.Encoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwarg):
super(Seq2SeqEncoder, self).__init__(**kwarg)
# embed 是word2vec的思想,把词典里one-hot编码的字或者词,变成预训练(可能需要微调)的词向量
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout)
def forward(self, X, **args):
X = self.embedding(X)
X = X.permute(1, 0, 2)
output, state = self.rnn(X)
return output, state
分析:
注意这里encoder没有最后的dense全连接!因为不需要encoder输出做预测,所以没有最后串联一个全连接。
这里的output是指RNN“最上面”的部分,而state是RNN“最右边”的部分。
维度: output: (num_step, batch_size, num_hiddens); state: (num_layers, batch_size, num_hiddens).
值得一提,代码中经常出现的state[-1]的维度:(batch_size, num_hiddens), 对应的RNN最上角的那个H。
普通seq2seq解码器
class Seq2SeqDecoder(d2l.Decoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
# 解码器要有自己的embedding层,因为翻译一个英语一个法语
self.embedding = nn.Embedding(vocab_size, embed_size)
# 这里假设encoder隐藏层大小和decoder隐藏层大小是一样的
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout)
# 做一个vocab_size的分类
self.dense = nn.Linear(num_hiddens, vocab_size)
# enc的输出有两部分:outputs和state,只要state
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
# 如果没有上下文操作,那就是一个普通的rnn,没有什么区别。
def forward(self, X, state):
# 把时间步放到前面
X = self.embedding(X).permute(1, 0, 2)
'''
上下文操作。这里state[-1]拿到的是“最右上角的”H(这个H融合和所有的信息)如果state是【2,4,16】的,那state[-1]就是【4,16】的。repeat重复时间步次。这样,每一个时间步都可以用到最后的H信息,与新的输入X做concat操作(这也是为什么解码器的self.rnn是ebd_size + num_hiddens的原因)。如果state[-1]是【4,16】,时间步是7,那重复完之后就是【7,4,16】的(7个时间步,4是batch_size,16是state隐藏单元的个数)。
'''
context = state[-1].repeat(X.shape[0], 1, 1)
X_and_context = torch.cat((X, context), dim=2)
output, state = self.rnn(X_and_context, state)
# 再把维度调整回(batch_size, num_step, vocab_Size)
output = self.dense(output).permute(1, 0, 2)
return output, state
分析:
这里放的是沐神写的稍有问题的解码器架构,原因见:
《动手学深度学习》Seq2Seq代码可能出错的原因及适当分析_QIzikk的博客-CSDN博客
普通的seq2seq中,上下文的context需要的仅仅是编码器输出的state[-1],所以在init_state的时候,不需要编码器的output输出。
与带有attention的seq2seq不同,这里的context拼接的是输入X和固定的state[-1](在dim=2,即特征维度上concat,所以nn.GRU的第一个参数是num_hiddens + embed_size).
btw: nn.RNN()的初始化:(vocab_size,num_hiddens,num_layers)
由于在解码器中要预测翻译后的句子,所以要添加一个FC(num_hiddens, vocab_size)。由于output的维度是(num_step, batch_size, num_hiddens)的,返回时要手动permute一下,将batch_size放在第一个维度。
这里的FC其实也使用了pytorch的机制:如果输入矩阵不是二维的,那前面所有的维度都会被当做样本维,只有最后一个维度是特征维。所以output本来是(num_step, batch_size, num_hiddens),可以和self.dense(num_hiddens, vocab_size)相乘。
带有attention机制的解码器
由于attention仅在解码器使用,所以带有attention的编码器与上文相同。
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
# 只有这里加了个加性attention
self.attention = d2l.AdditiveAttention(
num_hiddens, num_hiddens, num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(
embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
# outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,num_hiddens)
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
def forward(self, X, state):
# enc_outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# 输出X的形状为(num_steps,batch_size,embed_size)
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
for x in X:
# hidden_state是上一个时刻最后一层rnn的输出,是decoder的,每次会变。 query的形状为(batch_size,1,num_hiddens)
# hidden_state[-1]的形状是(batch_size, num_hiddens).这里要把num_query这个维度加入,因为只有一个query,所以是1,而query的维度正好是num_hiddens
query = torch.unsqueeze(hidden_state[-1], dim=1)
# context的形状为(batch_size,1,num_hiddens)
# 这里query是上一次的输出,key values是一样的,是编码器的output(是上面那一层,不是state右面那一层)
# enc_valid_lens是一个长为batch_size的vector, 第i个元素表示第i个样本英文句子原句长是多少。
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# 在特征维度上连结(batch_size, 1, 特征维度)
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
# x本来是(batch_size, 1, embed_size+num_hiddens)
# 将x变形为(1,batch_size,embed_size+num_hiddens).这里的1是时间步! 因为我们要attention,所以不能像之前s2s一样!要一步步来!
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
# 因为把时间维度认为拆开for了,所以要先append
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# 全连接层变换后,outputs的形状为
# (num_steps,batch_size,vocab_size)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights
分析:
由于要做attention的key,value均来自编码器的输出 【!误区!】并不是编码器最终输出的隐藏状态state! 而且state每个时间步都会迭代,我们并没有存下来。 所以我们在init_state的时候需要把 编码器的output以及enc_valid_len也一并返回(output在返回时需要将batch_size维度调整到第一维,而enc_valid_len的作用在于使用attention时,调整需要看的key-value对的个数,后面padding不会作为key-value对考虑)。
相关维度:
enc_outputs:(batch_size, num_steps, num_hiddens).
hidden_state:(num_layers,batch_size,num_hiddens)
X_permuted: (num_steps,batch_size,embed_size)
这里可以看出和普通seq2seq的不同:每一步的context不再是一样的,所以我们不能直接把输入丢进RNN进行隐式迭代,必须要自己写一个for循环显示迭代。
接下来逐句分析:
query = torch.unsqueeze(hidden_state[-1], dim=1)
hidden_state是上一个时刻最后一层rnn的输出状态,是decoder的(除了最后一个时间步是encoder最上层隐藏层的输出作为decoder第一次的q),随着时间步的更迭,每次会变。
hidden_state[-1]的形状是 (batch_size, num_hiddens).这里要把num_query这个维度加入(这也是对应到下文中Attention的实现中queries的维度是(batch_size, num_queries, query的特征维度)),因为只有一个query,所以是1,而query的维度正好是num_hiddens(在这里,我们代码中的k, v, q的特征维度均为num_hiddens).
context = self.attention(query, enc_outputs, enc_outputs, enc_valid_lens)
enc_valid_lens是一个长为batch_size的vector, 第i个元素表示第i个样本英文句子原句长是多少。
经过attention后,输出的结果应该是 (batch_size, num_queries, values的维度),对应到这里就是(batch_size, 1, num_hiddens).
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
x本来的维度是(batch_size, embed_size)的【注意这里x是for循环枚举的每一个时间步的X】,在dim=1上unsqueeze,然后在dim=2上concat,得到的结果就是 (batch_size, 1, embed_size+num_hiddens) 的(这里可以看到,nn.GRU第一个参数依然是embed_size+num_hiddens)。
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
交给RNN的参数分别是输入X、隐藏状态state,其中的X第一维度需要是时间维度。
调整顺序后的x维度为(1, batch_size,embed_size+num_hiddens),这里的1正好也可以理解成时间步长度为1(因为我们把时间维度手动用for循环展开了)。
这里注意,out的形状是(1, batch_size, num_hiddens)的,append之后的output是一个list,其实是把num_step个(1, batch_size, num_hiddens)的out放在一起了。
这里的output是多个tensor的集合,我们现在要把他们合并成一个tensor,所以下面:
outputs = self.dense(torch.cat(outputs, dim=0))
才有一个在dim=0维度上的concat,即在时间维度上concat起来,使得维度变成(num_step, batch_size, num_hiddens)的,才能有之后的permute操作。
【在注意力部分,num_step的理解很关键,经常num_queries 与 时间步长度是相等的(因为每一个时间步都是一个query,如self-attention)】
Transformer编码器层
#@save
class EncoderBlock(nn.Module):
"""transformer编码器块"""
# 最后key_size, query_size, value_size, num_hiddens,都是一个数
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout,use_bias)
self.addnorm1 = AddNorm(norm_shape, dropout)
# ffn的num_output设置为num_hiddens
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)
def forward(self, X, valid_lens):
# 层内的注意力是自注意力,所以q, k, v全是一样的
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))
return self.addnorm2(Y, self.ffn(Y))
transformer编码器中的任何层都不会改变其输入的形状.
【其实可以直接看两个residual块,因为X可以直接由residual结构直达输出,所以维度肯定是不变的】
测试
# batch_size, 查询的个数, 特征维度 = 2, 100, 24
X = torch.ones((2, 100, 24))
valid_lens = torch.tensor([3, 2])
# 经过self.attention之后,维度变成:(batch_size, 查询的个数,num_hiddens)), 即2, 100, 24
# 做LN的参数是后两层,(100, 24)。经过LN不改变形状,仍然是2, 100, 24,做ffn,输出是(2, 100, 24)
encoder_blk = EncoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5)
encoder_blk.eval()
encoder_blk(X, valid_lens).shape
torch.Size([2, 100, 24])
Transformer编码器
class TransformerEncoder(Encoder):
def __init__(self, vocab_size, key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, usebias=False, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout=dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block" + str(i),
EncoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, usebias=False))
def forward(self, X, valid_lens, *args):
# 因为位置编码值在-1和1之间,因此嵌入值乘以嵌入维度的平方根进行缩放,然后再与位置编码相加。
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self.attention_weights = [None] * len(self.blks)
for i, blk in enumerate(self.blks):
X = blk(X, valid_lens)
self.attention_weights[i] = blk.attention.attention.attention_weights
return X
分析:
这里把embedding_size也设置成num_hiddens了。
num_layers是指有多少个transformer的block.
注意这里乘math.sqrt(self.num_hiddens):embedding层出来一个长为d的东西,一般会把他的L2-norm设置为1,那么d越大,每个位置的数就越小;但是pos-encoding都是(-1, 1)的数,比较大,所以把emd扩大些,使之和pos-coding差不多大。
Transformer解码器层【*】
class DecoderBlock(nn.Module):
"""解码器中第i个块, 这里的i是指的从下往上第几个i"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, i, **kwargs):
super(DecoderBlock, self).__init__(**kwargs)
self.i = i
self.attention1 = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads,dropout)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.attention2 = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads,dropout)
self.addnorm2 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm3 = AddNorm(norm_shape, dropout)
def forward(self, X, state):
'''
训练阶段,输出序列的所有词元都在同一时间处理,因此state[2][self.i]初始化为None。
预测阶段,输出序列是通过词元一个接着一个解码的,因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示
'''
enc_outputs, enc_valid_lens = state[0], state[1]
# 这里对应预测的第一个词和训练的情况
if state[2][self.i] is None:
key_values = X
else:
key_values = torch.cat((state[2][self.i], X), axis=1)
state[2][self.i] = key_values
# 训练的话,已知所有的数据,只需人造valid_len即可。
if self.training:
batch_size, num_steps, _ = X.shape
# dec_valid_lens:(batch_size,num_steps), 其中每一行是[1,2,...,num_steps]
dec_valid_lens = torch.arange(1, num_steps + 1, devide=X.device).repeat(batch_size, 1)
else:
dec_valid_lens = None
# 自注意力
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
Y = self.addnorm1(X, X2)
# 编码器-解码器注意力,k, v都是编码器的输出
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
Z = self.addnorm2(Y, Y2)
return self.addnorm3(Z, self.ffn(Y)), state
分析:
其中的state是包含3个内容:编码器的输出、编码器的valid_len、state[2].
其中的state[2]针对训练和预测是完全不一样的。
对于训练,输入的X是完全已知的,所以我们可以手动直接设置valid_len为1, 2, 3… num_step,并且由于是self-attention, q, k, v都是这个输入X;
对于预测,我们是不知道长度的,所以valid_len设置为none;输出序列是通过词元一个接着一个解码的,所以把state[2]设置成“包含着直到当前时间步第i个块解码的输出表示(沐神)”。
怎么理解这句话?其实就是预测的时候,我们是一个一个预测的,没法像训练那样一下子知道所有的信息,所以要每一次把信息存下来,state[2] [self.i]存的其实就是所有到目前为止之前层给自己的输入。
我们把输入在dim = 1的维度上concat起来(3个维度分别是batch_size, num_step, num_hiddens,在预测的时候batch_size = 1),也就起到了下图的效果:
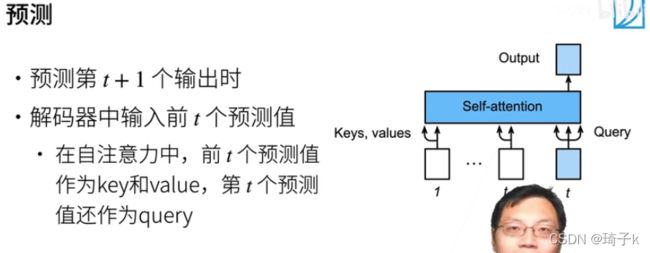
这里放一下预测的部分代码(节选自seq2seq):
# 添加批量轴
dec_X = torch.unsqueeze(torch.tensor(
[tgt_vocab['' ]], dtype=torch.long, device=device), dim=0)
output_seq, attention_weight_seq = [], []
for _ in range(num_steps):
Y, dec_state = net.decoder(dec_X, dec_state)
# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入
dec_X = Y.argmax(dim=2)
pred = dec_X.squeeze(dim=0).type(torch.int32).item()
# 保存注意力权重(稍后讨论)
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# 一旦序列结束词元被预测,输出序列的生成就完成了
if pred == tgt_vocab['' ]:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
[tgt_vocab[’’]] 其实就是一个数,unsqueeze之后其实加入的是batch_Size = 1的维度,所以dec_X一开始的时候维度是[1, 1]的
(理解: 预测的时候batch_size, num_step = 1, 1)
然后经过解码器各个层之后(下面代码节选自Transformer解码器):
def forward(self, X, state):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self._attention_weights = [[None] * len(self.blks) for _ in range (2)]
for i, blk in enumerate(self.blks):
X, state = blk(X, state)
# 解码器自注意力权重
self._attention_weights[0][
i] = blk.attention1.attention.attention_weights
# “编码器-解码器”自注意力权重
self._attention_weights[1][
i] = blk.attention2.attention.attention_weights
return self.dense(X), state
在预测里:
Y, dec_state = net.decoder(dec_X, dec_state)
这一句得到的Y就是self.dense(X), dec_state得到的就是state.【这个state仍然是3部分,编码器输出、编码器valid_len和 “截止到目前为止记录的输出结果”】
这个dense就是一个FC,然后在预测的代码里的Y其实是(batch_size, num_step, vocab_size)的【其实就是(1, 1, vocab_size)】.做完argmax并squeeze之后,dec_X维度仍然是[1, 1].
Y.shape, dec_X.shape
torch.Size([1, 1, 201]) torch.Size([1, 1])
所以每一次
key_values = torch.cat((state[2][self.i], X), axis=1)
就是把输入(来自前一层的输出,第一个Decoder块的X就是输入(上一次预测的单词)经过embedding + positional_coding之后的结果,维度为(1, 1, num_hiddens))在时间维度上concat起来。
state[2]预测初始化时是[None,None,None…,None],第一次输出时是[[X00],[X01],[X02]…[X0n]],再往后就是 [[X00,X10…],[X01,X11…],[X02,X12…]…[X0n,X1n…]] (每一层都存下来)
编码器和解码器的特征维度都是num_hiddens,而且所有的block都是什么shape进来,什么shape出去。
Transformer解码器
class TransformerDecoder(d2l.AttentionDecoder):
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block" + str(i),
DecoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, i))
# 最后要加入一个全连接层用于预测结果
self.dense = nn.Linear(num_hiddens, vocab_size)
# 初始化的时候state[2]都设置为None, 方便预测使用
def init_state(self, enc_outputs, enc_valid_lens, *args):
return [enc_outputs, enc_valid_lens, [None] * self.num_layers]
def forward(self, X, state):
X = self.pos_encoding(self.embedding(X) * torch.sqrt(self.num_hiddens))
self._attention_weights = [[None] * len(self.blks) for _ in range (2)]
for i, blk in enumerate(self.blks):
# 每次用输出、新状态来更新下一次的输入、旧状态
X, state = blk(X, state)
# 解码器自注意力权重
self._attention_weights[0][
i] = blk.attention1.attention.attention_weights
# “编码器-解码器”自注意力权重
self._attention_weights[1][
i] = blk.attention2.attention.attention_weights
return self.dense(X), state
@property
def attention_weights(self):
return self._attention_weights
四、两种Attention的实现
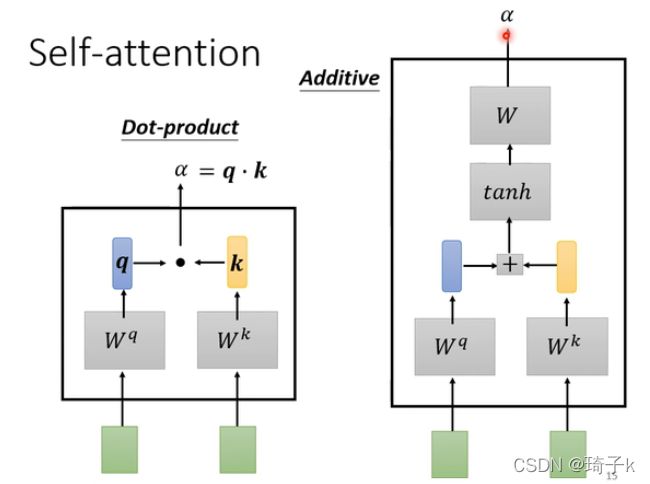
加性attention

一般用于q, k, v的维度不同的情况。且加性attention可学习参数多,效果较好。
# num_hiddens就是讲义里的h
class AdditiveAttention(nn.Module):
def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):
super(AdditiveAttention, self).__init__(**kwargs)
# 以key为例,keys是1*k的,Wk是k * h的,结果是1 * h的
self.W_k = nn.Linear(key_size, num_hiddens, bias=False) # k->h
self.W_q = nn.Linear(query_size, num_hiddens, bias=False) # q->h
self.W_v = nn.Linear(num_hiddens, 1, bias=False) # h->1
self.dropout = nn.Dropout(dropout)
# valid_len是:有多少对k-v对是需要的,把padding的k-v忽略
def forward(self, queries, keys, values, valid_len):
queries, keys = self.W_q(queries), self.W_k(keys)
# queries的结果:(batch, num_queries, h); keys:(batch, num_keys, h).需要对每一个query和每一个key都加起来
# 在维度扩展后,
# queries的形状:(batch_size,查询的个数,1,num_hidden)
# key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)
# 使用广播方式进行求和,自动扩展成(batch_size, num_queries, num_keys, h)
features = queries.unsqueeze(2) + keys.unsqueeze(1)
features = torch.tanh(features)
# scores的形状:(batch_size,查询的个数,“键-值”对的个数)
scores = self.W_v(features).squeeze(-1) # (batch_size, num_queries, num_keys)
self.attention_weight = masked_softmax(scores, valid_len)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# 对a_w那一维度做dropout,把更多项变成0
return torch.bmm(self.dropout(self.attention_weight), values)
分析:【以下用h表示num_hiddens】
这里的广播机制用的非常巧妙。
queries, keys, values的维度是:(batch_size, num_of_q、k、v,q、k、v_size),这里的size是指特征维度。
经过Wq、Wk矩阵后,queries的维度:(batch, num_queries, h); keys:(batch, num_keys, h)
但是我们需要对每一个queries考虑每一个keys,而现在的维度根本不相等,无法相加,所以考虑使用unsqueeze增加维度。
使用广播方式进行求和,自动扩展成 (batch_size, num_queries, num_keys, h)。
这样的形式可以理解成“对于每一个queries,我们用一个二维矩阵表示所有的keys,每一行表示一个key,这一行是这个key的特征维度”。
将features与Wv矩阵相乘,可以得到 (batch_size, num_queries, num_keys, 1) 的结果,将最后一维squeeze掉,就得到了需要的scores.
可以理解成:“一个二维矩阵的每一行是一个query,每一列是对应key的得分”。然后结合valid_len对需要考虑的key-value进行masked_softmax,就可以得到最后的alpha. 最后返回结果的维度:(batch_size, num_queries, 值的维度)。
缩放点积attention
(lhy:哒啪哒

#@save
class DotProductAttention(nn.Module):
"""缩放点积注意力"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# queries的形状:(batch_size,查询的个数,d)
# keys的形状:(batch_size,“键-值”对的个数,d)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# 设置transpose_b=True为了交换keys的最后两个维度
scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
五、训练及预测
调用接口代码(trans为例)
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4
key_size, query_size, value_size = 32, 32, 32
norm_shape = [32]
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size, num_steps)
encoder = TransformerEncoder(
len(src_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
decoder = TransformerDecoder(
len(tgt_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
训练
#@save
# 这里的net是一个封装了encoder\decoder的模型
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
"""训练序列到序列模型"""
def xavier_init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(xavier_init_weights)
net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
net.train()
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs])
for epoch in range(num_epochs):
timer = d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失总和,词元数量
for batch in data_iter:
optimizer.zero_grad()
# 每一个batch有原句、原句长、翻译后句、句长
X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]
bos = torch.tensor([tgt_vocab['' ]] * Y.shape[0],
device=device).reshape(-1, 1)
# 在每一个Y输入的前面加上,并把最后一个去掉。bos预测第一个词,倒数第二个词预测最后一个,最后一个词没用,拿掉。
dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学
# 这里没有用到X_vaild_len.这里写了是因为之后attention要用
Y_hat, _ = net(X, dec_input)
l = loss(Y_hat, Y, Y_valid_len)
l.sum().backward() # 损失函数的标量进行“反向传播”
d2l.grad_clipping(net, 1)
num_tokens = Y_valid_len.sum()
optimizer.step()
with torch.no_grad():
metric.add(l.sum(), num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')
分析:
使用data_iter每一次我们获得 原句、原句长、译句、译句长并把每一个译句前面加上句子的开始符号< bos >.
得到的原句和译句均是(batch_size, 规定句子长)的,这里规定句子长取10,大于的截断,小于的padding(见上面数据集相关).
这里把译句的最后一个< eos >去掉,是因为:我们用< bos > 去预测第一个词,用第一个词去预测第二个词……用最后一个词去预测< eos > ,就结束了,用不到< eos >.
在训练阶段,是强制教学的,即无论预测的结果是什么,我们都会用正确的译句作为输入,然后最后把预测的输出和标准的输出做masked_crossentropy计算损失。
对比seq2seq、attention-seq2seq、transformer在训练时得到输出的不同
Y_hat, _ = net(X, dec_input)
输入X是(batch_size, num_step)的。
seq2seq与attention-seq2seq都是基于RNN的,而transformer是纯注意力机制的。
seq2seq
output, state = self.rnn(X_and_context, state)
由于state[-1]完全一致,所以可以直接将state[-1]和输入X拼接起来,然后直接丢进RNN,在RNN内会进行类似如下的运算:
# 计算。给一个小批量,将里面所有的时间步都算一遍,得到输出。
# input里包括所有的时间步(X_0到X_t),state是上一次运算的隐藏状态, params是可以学习的参数
def rnn(inputs, state, params):
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state # 这里是一个tuple,但是只有一个元素
outputs = []
for X in inputs: # inputs是一个三维的矩阵:(时间步,batch_size, one_hot长),这样循环会按时间步分,所以前面要转置
H = torch.tanh(torch.matmul(X, W_xh) + torch.matmal(H, W_hh) + b_h)
Y = torch.matmul(H, W_hq) + b_q # Y是当前时间步预测下一个单词是谁,但是这里是一个for循环,所以要append
outputs.append(Y)
# cat之后是一个二维矩阵,可以认为是n个矩阵按照竖着摞起来的。列数还是vocab_size,行数是batch_size * 时间步数
return torch.cat(outputs, dim=0), (H, )
在RNN内部,会有一个隐式的for循环,自动按照时间步迭代更新state并产生output
output, state = self.rnn(X_and_context, state)
# 再把维度调整回(batch_size, num_step, vocab_Size)
output = self.dense(output).permute(1, 0, 2)
return output, state
在解码器接口获得output后,调整维度,返回Y_hat(batch_size, num_step, vocab_size).
attention-seq2seq:
节选解码器里的关键代码:
for x in X:
......
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
# 因为把时间维度认为拆开for了,所以要先append
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# 全连接层变换后,outputs的形状为
# (num_steps,batch_size,vocab_size)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
和seq2seq类似,只是把时间步拆开了,每次给RNN的都是单步的。
out.shape: (1, batch_size, num_hiddens), 而 【!误区!】outputs现在是一个list,并不是torch.tensor!
a = [[1, 2], [3, 4]]
b = torch.tensor(a)
type(a), type(b)
(list, torch.Tensor)
在经过self.dense层之后, outputs才变成了torch.tensor,经过permute后,维度变成(batch_size, num_step, vocab_size)后返回。
transformer
节选自transformer解码器。
def forward(self, X, state):
'''
训练阶段,输出序列的所有词元都在同一时间处理,因此state[2][self.i]初始化为None。
预测阶段,输出序列是通过词元一个接着一个解码的,因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示
'''
enc_outputs, enc_valid_lens = state[0], state[1]
# 这里对应预测的第一个词和训练的情况
if state[2][self.i] is None:
key_values = X
else:
key_values = torch.cat((state[2][self.i], X), axis=1)
state[2][self.i] = key_values
# 训练的话,已知所有的数据,只需人造valid_len即可。
if self.training:
batch_size, num_steps, _ = X.shape
# dec_valid_lens:(batch_size,num_steps), 其中每一行是[1,2,...,num_steps]
dec_valid_lens = torch.arange(1, num_steps + 1, devide=X.device).repeat(batch_size, 1)
else:
dec_valid_lens = None
# 自注意力
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
Y = self.addnorm1(X, X2)
# 编码器-解码器注意力,k, v都是编码器的输出
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
Z = self.addnorm2(Y, Y2)
return self.addnorm3(Z, self.ffn(Y)), state
在训练阶段,我们的数据是完全已知的,所以可以直接获得每一个时间步的数据,而不需要像预测那样一步步来。这里先设置valid_len分别为1,2,3…num_step,表示第i个时间步的query只能看到前i个时间步的key-value.训练阶段的k,v,q全都是输入X,做self-attention,得到的输出结果为 (batch_size, num_step, num_hiddens),其中的num_step即num_queries. 然后在经过编码器-解码器attention、FFN等得到一个块的输出;串联多个块之后,得到最终的输出。

对应这张图,输出的yi就是以xi作为query, x1,x2…xi作为k-v时的结果。
因为译句长度为num_step,我们也同样会得到使用self-attention得到的num_step个结果. 在解码器中会返回self.dense(X),即y_hat.
summary
上述三种方法在训练阶段得到的结果均为 (batch_size, num_step, vocab_size),即y_hat,只是方式有所不同,seq2seq是调用rnn内部隐式的循环获得的;attention-seq是人为将时间步拆开,在output中一步步append结果得到的;transformer是经过若干块后得到的输出,在每一个块中,xi会和x1,x2…xi做self-attention,而后经过若干其他操作(如ffn等)。
预测
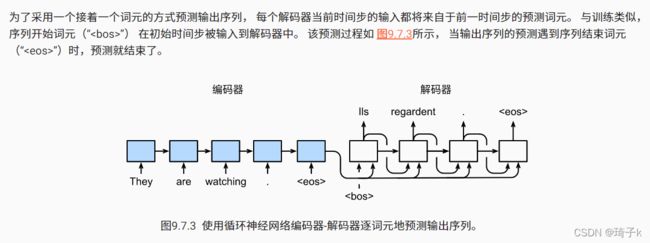
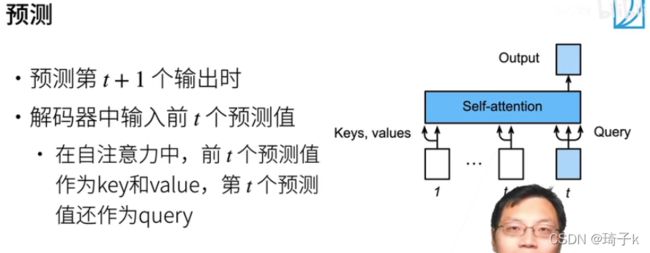
#@save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):
"""序列到序列模型的预测"""
# 在预测时将net设置为评估模式
net.eval()
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [
src_vocab['' ]]
enc_valid_len = torch.tensor([len(src_tokens)], device=device)
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['' ])
# 添加批量轴
enc_X = torch.unsqueeze(
torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)
enc_outputs = net.encoder(enc_X)
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
# 添加批量轴
dec_X = torch.unsqueeze(torch.tensor(
[tgt_vocab['' ]], dtype=torch.long, device=device), dim=0)
output_seq, attention_weight_seq = [], []
for _ in range(num_steps):
Y, dec_state = net.decoder(dec_X, dec_state)
# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入
dec_X = Y.argmax(dim=2)
pred = dec_X.squeeze(dim=0).type(torch.int32).item()
# 保存注意力权重(稍后讨论)
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# 一旦序列结束词元被预测,输出序列的生成就完成了
if pred == tgt_vocab['' ]:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
关于dec_X
[tgt_vocab[’< bos >’]] 其实就是一个数,unsqueeze之后其实加入的是batch_Size = 1的维度,所以dec_X一开始的时候维度是[1, 1]的
(理解: 预测的时候batch_size, num_step = 1, 1)
然后经过解码器各个层之后(下面代码节选自Transformer解码器):
def forward(self, X, state):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self._attention_weights = [[None] * len(self.blks) for _ in range (2)]
for i, blk in enumerate(self.blks):
X, state = blk(X, state)
# 解码器自注意力权重
self._attention_weights[0][
i] = blk.attention1.attention.attention_weights
# “编码器-解码器”自注意力权重
self._attention_weights[1][
i] = blk.attention2.attention.attention_weights
return self.dense(X), state
在预测里:
Y, dec_state = net.decoder(dec_X, dec_state)
这一句得到的Y就是self.dense(X) ,这个dense就是一个FC,然后在预测的代码里的Y其实是(batch_size, num_step, vocab_size)的【其实就是(1, 1, vocab_size)】.做完argmax并squeeze之后,dec_X维度仍然是[1, 1].
Transformer相关架构及呆码
编码器-解码器架构,和Seq2Seq类似,不过是纯基于self-attention的架构。
整体架构
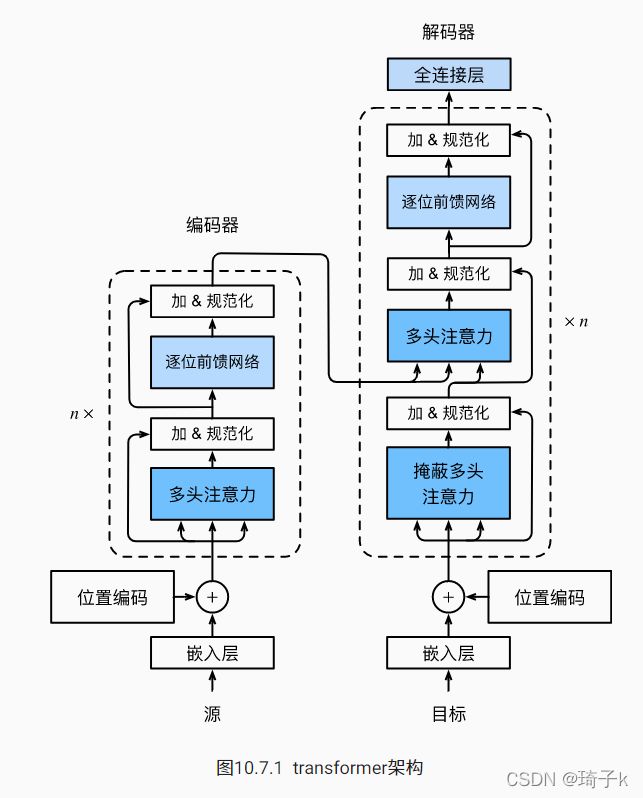
一般来说,编码器和解码器的个数是一样的(原始论文中使用了6个),经过每一个块后,数据维度并不发生任何变化,仍然是(batch_size, num_step, num_hiddens)的。
需要注意的是,在“信息传递”部分,并不是“【!误区!】第一个编码器块的输出传给第一个解码器块”这样对应着来的,而是最后一个编码器把信息输入到全部解码器。
对应代码可以看出:

编码器的forward会循环经过所有的编码器块,每一个块的输出作为下一个块的输入,然后最后返回总的输出,作为解码器中的enc_outputs,中间层编码器块的输出结果只是作为下一个块的输出使用,并没有存下来。
细节
详见Attention Is All You Need论文精读笔记