tf2.0学习(六)——过拟合
前边介绍了TensorFlow的基本操作和Keras的高层接口:
tf2.0学习(一)——基础知识
tf2.0学习(二)——进阶知识
tf2.0学习(三)——神经网络
tf2.0学习(四)——反向传播算法
tf2.0学习(五)——Keras高层接口
下面我们接好一下在训练过程中经常要面对的一个问题,过拟合,以及在TensorFlow这个框架中如何更好的处理这个问题。
tf2.0学习(六)——过拟合
-
- 6.0 简介
- 6.1 模型的容量
- 6.2 过拟合与欠拟合
-
- 6.2.1 欠拟合
- 6.2.2 过拟合
- 6.3 数据集划分
-
- 6.3.1 验证集与超参数
- 6.3.2 提前停止(early stopping)
- 6.4 模型设计
- 6.5 正则化
-
- 6.5.1 L0正则化
- 6.5.2 L1正则化
- 6.5.3 L2正则化
- 6.6 Dropout
- 6.7 数据增强
-
- 6.7.1 图像
- 6.7.2 生成数据
- 6.7.3 其他
6.0 简介
机器学习的主要目的,是通过训练集学习到数据的真实模型,从而在未见过的测试集上能有良好的表现,这种能力叫做模型的泛化能力。通常来说,训练集和测试集都采样自某个相同的数据分布p(x)。采样到的样本是相互独立的,但又来自同一个分布,我们把这种假设叫做独立同分布假设(简称:i.i.d)。
模型的表达能力,也叫做模型的容量。当模型的表达能力偏弱时,会导致无法充分学习到数据的特征,从而导致模型性能很差,这时候模型在训练集和测试集上的表现都很差。当模型的表达能力过强时,又会导致模型学习过于充分,甚至学到了训练集中的噪声,这时候模型在训练集上表现很好,但在测试集上的表现很差。
6.1 模型的容量
通俗的讲,模型的容量或表达能力,就是模型拟合复杂函数的能力。一种体现模型容量的指标叫做模型的假设空间,即模型可以表示的函数集的大小。假设空间越大越完备,就越有可能从假设空间中搜索到能够拟合真实数据的函数,相反,如果假设空间很小,就很难找到拟合真实数据的函数。
假设一数据集采样自如下分布:
p d a t a = { ( x , y ) ∣ y = s i n ( x ) , x ∈ [ − 5 , 5 ] } p_{data} = \left\{ (x, y) | y = sin(x), x \in [-5, 5] \right\} pdata={(x,y)∣y=sin(x),x∈[−5,5]}
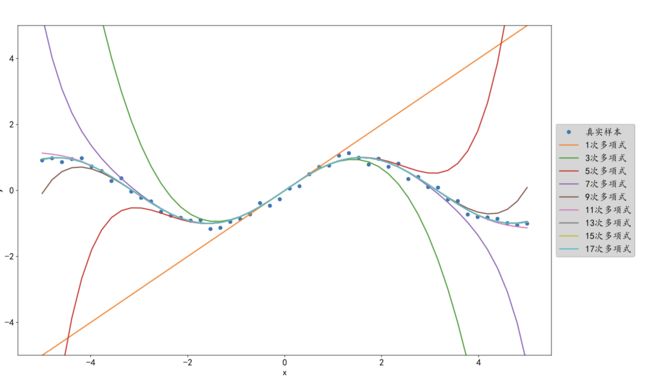
该数据集引入了一些观测误差,如下图小圆点所示。如果只搜索1次多项式的模型空间,那么最多能拟合出一条直线来,效果很差。如果搜索空间增加到3次多项式函数,此时假设空间明显大于1次多项式的情况,此时能拟合出一条曲线,效果能有些提升。如果继续增加多项式的幂次,那么假设空间越来越大,搜索的范围也越来越大,就约有可能找到拟合效果更好的模型。
但是过大的搜索空间,无疑会增加模型的搜索难度和计算代价。实际上在有限的计算资源下,较大的搜索空间并不一定能找出更好的函数模型。相反,随着假设空间中可能存在表达能力过强的模型,学习到了训练集中的噪声数据,从而伤害了模型的泛化能力。因此在实际情况中,往往根据具体任务,选择合适的假设空间的模型。
6.2 过拟合与欠拟合
由于真实数据的分布往往是未知又复杂的,而且无法推断出其分布函数的类型和参数,因此人们在学习模型时,往往根据根据经验选择较大的模型容量。
但模型容量过大时,搜索到的模型,可能由于表达能力过强,不仅学到了数据本省的模态,还学到了数据中的观测误差,这就会导致模型在训练集上的表现很好,但在未见的新样本上表现不佳,泛化能力弱,这种现象叫做模型的过拟合。当模型容量过小时,模型可能不能很好的学习到数据的模态,就会导致模型在训练集上表现不佳,在未见过的新样本上表现也很差,这种现象叫做欠拟合。
那么如何选择合适的模型容量呢?统计学习理论给我们提供了一些思路,VC维是机器学习领域,一个比较通用的度量模型容量的方法。尽管这些方法给机器学习提供了一些理论保证,但在深度学习领域却很难应用,一部分原因是神经网络的机构复杂,很难确定网络背后的数学模型的VC维度。
但是,我们可以根据奥卡姆剃刀原则,指导神经网络的设计和训练。“切勿浪费较多东西,去做‘用较少的东西,同样可以做好的事 情’”。也就是说,如果两层的神经网络结构能够很好的表达真实模型,那么三层的神经 网络也能够很好的表达,但是我们应该优先选择使用更简单的两层神经网络,因为它的参 数量更少,更容易训练,也更容易通过较少的训练样本获得不错的泛化误差。
6.2.1 欠拟合
欠拟合的原因,往往是模型容量不足,导致在假设空间内找不到一个合适的函数很好的拟合数据。表现是在训练集上误差很好,在测试集上的表现也很差。遇到这种情况,我们一般考虑增加模型的复杂度,增加数据维度等办法处理。但由于以深度学习为代表的很多模型,可以轻易达到很深的维度,模型复杂度往往很高,所以欠拟合的问题一般不如过拟合的问题常见。
6.2.2 过拟合
现在说一下过拟合。当模型容量很大,可供搜索的假设空间也就会很大,这时候模型的表达能力过于强大,很可能会学习到训练数据中的观测误差,导致在训练集上的表现很好,但在测试集上的表现却很差。这时候往往就是过拟合了。本章接下来的内容更多用于介绍如何避免过拟合。
6.3 数据集划分
我们在做机器学习任务过程中,数据集要划分为训练集和测试集,但为了选择模型超参数和检测过拟合现象,往往再将训练集划分为训练集和验证集。也就是一个数据集会被划分成训练集、验证集、测试集三部分。
6.3.1 验证集与超参数
前边已经介绍了训练集和测试集,训练集主要用来训练模型,测试集主要用来验证模型的泛化能力。测试集的样本不能出现在训练集中,防止模型学到测试集的信息,导致测试集不能真正反应模型的泛化能力,是一种有损模型泛化的行为。训练集和测试集一般都采样自同一分布的数据,对应比例可以根据情况调节。
但只将数据分为训练集和测试集是不够的,由于测试集不参与到模型训练中,所以测试集不能用来作为模型训练的实时反馈,而模型训练过程中,我们需要挑选合适的参数模型,需要有个数据集对模型性能进行实时反馈,判断模式是否过拟合。因此一般再将训练集划分为训练集和验证集。划分后的训练集主要用来训练模型,验证集主要用来进行超参数的选择。
验证集和测试集的主要区别在于,开发人员可以根据验证集的反馈结果进行模型参数的调整,而训练集一般只是用来验证模型整体泛化能力。
6.3.2 提前停止(early stopping)
一般来说,把训练集的一个Batch运算更新一次叫做一个step,对训练集的所有样本循环迭代一次叫做一个Epoch,整个训练过程可能会进行多个Epoch。验证集一般可以在间隔数次Step或数次Epoch之后,对模型进行验证。如果验证过于频繁,虽然能清楚的记录模型性能,但会带来额外的计算消耗,所以一般建议间隔几个Epoch进行一次验证。
在训练过程中,我们会同时关心训练集和验证集的误差、准确率等指标。如果模型的训练误差 较低,训练准确率较高,但是验证误差较高,验证准确率较低,那么可能出现了过拟合现 象。如果训练集和验证集上面的误差都较高,准确率较低,那么可能出现了欠拟合现象。
当发现模型过拟合时,可以通过重新设计模型容量,如减少网络层数,添加正则化项等方式。
实际上,由于模型是随着训练不断变化的,因此同一个模型可能会出现不同的过拟合、欠拟合。可以看到在训练的前期,训练集和测试集准确率都在不断提升,没有出现过拟合现象。但随着训练的持续,在某个Epoch出,会出现过拟合现象,具体表现如下图所示,训练集准确率不断升高,而测试集准确率却在不断下降。
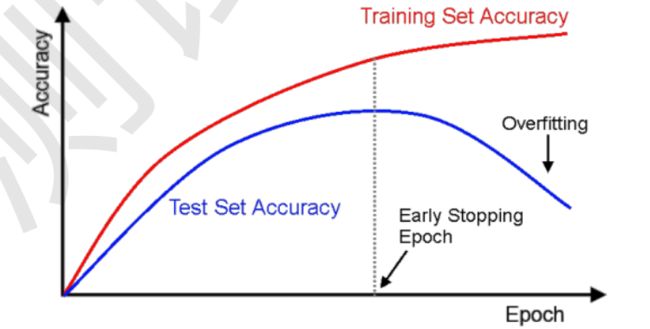
那么可不可以,在模型训练到合适的Epoch时,就停止训练,从而只过拟合现象的发生呢。我们可以通过观察验证集的准确率,找到合适的Epoch,当验证集在连续几个Epoch都没有准确率的提升时,我们可以认为已经到了最合适的Epoch附近,从而提前挺尸训练,避免训练过度,发生过拟合。
6.4 模型设计
通过验证集可以判断网络模型是否过拟合或欠拟合,从而为调整网络模型的容量提供依据。对于神经网络来说,网络的层数和参数量时衡量网络容量的重要参考指标。当网络过拟合时,可以适当减少网络层数或减少网络层的参数量,从而降低网络容量。反之如果发现模型欠拟合,择可以加大模型容量。
6.5 正则化
通过不同层数和参数的网络模型,可为优化算法提供初始的函数假设空间,但函数的假设空间时随着训练而不断变化的。我们以多项式模型为例。
y = β 0 + β 1 x + β 2 x 2 + . . . + β n x n + ϵ y = \beta_0 + \beta_1 x + \beta_2 x^2 +... + \beta_n x^n + \epsilon y=β0+β1x+β2x2+...+βnxn+ϵ
上述模型的容量,可以简单的用n来衡量,但如果我们限制了 β k + 1 . . . β n \beta_{k+1} ... \beta_n βk+1...βn都为0的话,那么该模型的容量就变为k。因此可以通过限制网络参数的稀疏性,限制网络容量。
这种约束一般是在损失函数上添加额外的惩罚项。添加惩罚项之前的优化目标是:
m i n L ( f θ ( x ) , y ) , ( x , y ) ∈ D t r a i n min L(f_{\theta}(x), y), (x, y) \in \mathbb{D}^{train} minL(fθ(x),y),(x,y)∈Dtrain
添加惩罚项之后的优化目标是:
m i n L ( f θ ( x ) , y ) + λ Ω ( θ ) , ( x , y ) ∈ D t r a i n min L(f_{\theta}(x), y) + \lambda \Omega(\theta), (x, y) \in \mathbb{D}^{train} minL(fθ(x),y)+λΩ(θ),(x,y)∈Dtrain
其中,惩罚项约束一般通过参数的范数来量化:
Ω ( θ ) = ∑ θ i ∣ ∣ θ i ∣ ∣ l \Omega(\theta) = \sum_{\theta_i} ||\theta_i||_l Ω(θ)=θi∑∣∣θi∣∣l
$ ||\theta_i||_l 叫 做 参 数 叫做参数 叫做参数\theta_i$的l范数。
常用的正则化项有L0、L1、L2正则化。
6.5.1 L0正则化
Ω ( θ ) = ∑ θ i ∣ ∣ θ i ∣ ∣ 0 \Omega(\theta) = \sum_{\theta_i} ||\theta_i||_0 Ω(θ)=θi∑∣∣θi∣∣0
对于L0正则化项,定义是所有 θ \theta θ中,非零元素的个数。但由于L0范数不可导,因此在神经网络中使用的并不多。
6.5.2 L1正则化
Ω ( θ ) = ∑ θ i ∣ ∣ θ i ∣ ∣ 1 \Omega(\theta) = \sum_{\theta_i} ||\theta_i||_1 Ω(θ)=θi∑∣∣θi∣∣1
L1 正则化也叫 Lasso Regularization。它是连续可导的,在神经网络中使用广泛。
w1 = tf.random.uniform([4, 3])
w2 = tf.random.uniform([4, 3])
loss_reg = tf.reduce_sum(tf.math.abs(w1) + tf.math.abs(w2))
6.5.3 L2正则化
Ω ( θ ) = ∑ θ i ∣ ∣ θ i ∣ ∣ 2 \Omega(\theta) = \sum_{\theta_i} ||\theta_i||_2 Ω(θ)=θi∑∣∣θi∣∣2
L2 正则化也叫 Ridge Regularization,它和 L1 正则化一样,也是连续可导的,在神经网络中使用广泛。
w1 = tf.random.uniform([4, 3])
w2 = tf.random.uniform([4, 3])
loss_reg = tf.reduce_sum(tf.square(w1) + tf.square(w2))
6.6 Dropout
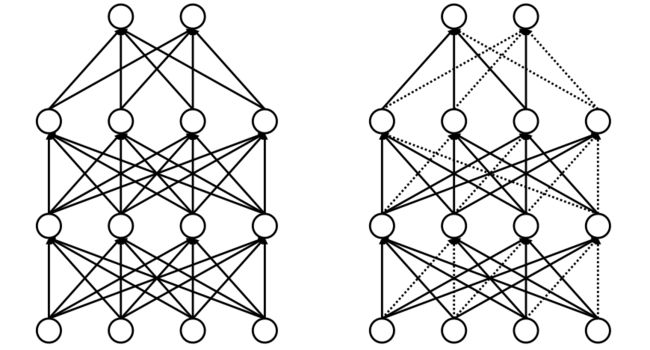
Dropout是一种在神经网络里经常用到的防止过拟合的方法。在训练阶段随机断开一部分神经网络的连接,减少每次训练时实际参与计算的参数量(如下图右所示);但在测试阶段,会恢复所有链接。
在TensorFlow中,可以通过增加dropout操作和添加dropout层来实现dropout。
# 增加dropout操作
x = tf.nn.dropout(x, rage=0.5)
# 增加dropout层
model.add(tf.keras.layers.Dropout(0.5))
6.7 数据增强
还有一种简单直接的防止过拟合的方式,就是增加训练数据。但实际上收集数据成本高昂,我们可以在已有的数据集上,通过数据增强,获取更多的训练数据。数据增强(Data Augmentation)是指在维持样本标签不变的前提下,根据先验知识,改变样本的特征,使得新生成的样本也符合或近似符合数据的真实分布。
6.7.1 图像
在图像领域,可以通过对图片进行旋转、翻转、裁剪等方式,将一张图片衍生出多张图片。
6.7.2 生成数据
如GAN网络等,将在后边章节介绍。
6.7.3 其他
可以对数据增加少量噪声,同义词替换,多次翻译等方式。