sparksql将国家统计局csv文件解析并存储在hive表
sparksql将国家统计局csv文件解析并存储在hive表
- 目的
- 分析
-
- 数据下载
- 数据标准化
- 数据存储
- 开发环境集成
- 实现
-
- 项目创建
- 依赖
- 数据标准化
- DataFrame 行列转置
- 数据存储
- 主程序逻辑
- 验证
-
- 启动
- 本地存储
- 远程存储
- 总结
git地址:https://gitee.com/jyq_18792721831/sparkmaven.git
目的
学习大数据,那么数据从哪来?
国家统计局可以免费下载社会上的各种数据,所以从国家统计局下载数据就是一个不错的数据来源渠道。当然这种只是适合自己练习或者有针对性的分析数据。一般各个公司都有自己的收集数据的渠道和方式,不用考虑数据的来源,而是更多考虑如何使用数据。
国家统计局下载的数据一般有多种格式,csv,excel,txt,xml等,对于程序来说,最好的可能是csv和txt格式了。
下载的csv数据可以使用文本编辑器打开,或者是excel打开。但是这种只是适合用户操作,对于少量数据还行,对于多个文件,大量的数据的话就不合适了。
所以需要把国家统计局下载的csv数据写到hive中(或者其他数据库存储中)。
目的就非常的明确了,将国家统计局的csv数据写入到hive中。
分析
数据下载
从国家统计局下载一个csv文件,首先需要注册国家统计局账号,并查询需要的数据,以价格指数为例
默认查询最近13个月的数据,从界面上最多可以下载5年的数据,在时间那里输入201601-确定查询
然后点击下载
登录后记得重新指定查询时间条件,下载csv格式的文件
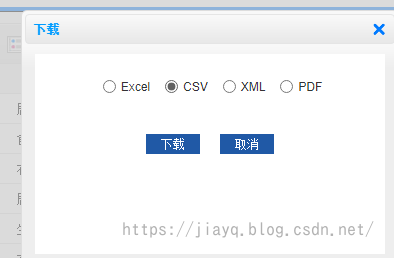
数据标准化
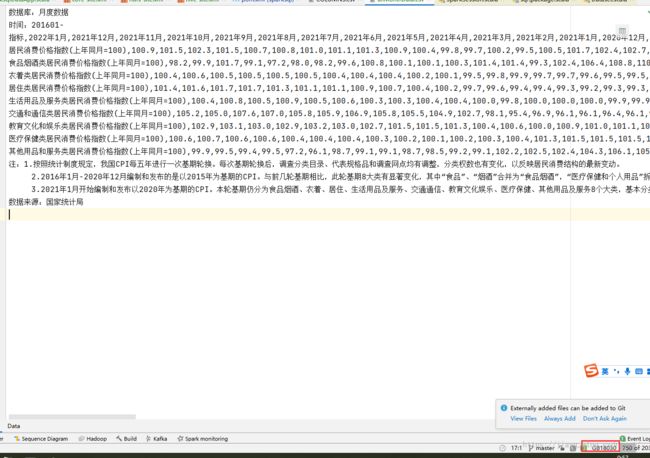
下载后用excel打开如下

数据表和数据库中的数据存在不同,比如在数据的上面和下面有说明信息,然后是数据是横向排列的,而不是纵向排列的
所以需要去除说明信息,并且把数据从横向排列转置为纵向排列。
数据存储
数据存储在hive中,有两种存储方式,第一种是把hive当做数据库使用,以数据库表的方式存储,第二种是把hive当做硬盘使用。
因为hive是可以直接查询文件,并且和hive表的使用并无不同,所以这两种存储方式在使用上并无不同。
开发环境集成
使用idea开发,就需要在idea中连接远程的hive和远程的hdfs,并且支持idea中写入,在其他的hive客户端中查询。
实现
项目创建
在idea中创建一个基于maven的spark项目,这部分可以参见 使用maven集成java和scala开发环境_a18792721831的博客-CSDN博客
整个项目结构如下
把数据存储在根项目的data/gov目录下
接着创建一个object文件
依赖
项目是spark项目,就需要增加spark的依赖
先把scala和spark的依赖引入
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-compilerartifactId>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-reflectartifactId>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.12artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.12artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.12artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>${mysql.jdbc.version}version>
dependency>
数据标准化
根据数据的展示,知道数据标准化需要做两步,第一步是文件编码的问题,下载的csv文件不知道是什么编码格式,当把数据文件放倒data/gov目录下后,使用idea打开csv文件
默认是utf-8编码打开csv文件

最新的idea中会自动尝试不同的编码方式,提示正确的编码方式。如果没有提示,可以不断尝试不同的常见的中文编码方式。
国家统计局下载的csv文件的编码方式为GB18030
但是在开发中,一般是使用UTF-8编码方式,而且spark读取文件,默认也是UTF-8的文件编码方式,所以需要把csv文件转为UTF-8格式。
第二步是需要将说明的信息去除,也就是一行只有一个单元格的行去除。
因为csv文件一般是以,分割数据单元格,所以可以按行读取文件,然后按照,分割行,如果分割后的单元格数量小于2,就是需要去除的行。
数据标准化的方法如下:
/**
* 去除单个单元格一行的数据(以行为单位)
*
* @param path 输入应该csv文件的全路径,以`.csv`结尾
* @param readEncoding 输入文件的编码,默认`GB18030`
* @param writeEncoding 输出文件的编码,默认`UTF-8`
* @param split csv文件的分隔符,默认`,`
* @return 新的csv文件的全路径
*/
def removeExplainCessCsv(path: String, readEncoding: String = "GB18030", writeEncoding: String = "UTF-8", split: Char = ','): String = {
// 1. 构造新csv文件的全路径
val outPath = (path substring(0, path.length - 4)) + NO_EXPLAIN
// 如果文件已经存在,那么直接返回
if (new File(outPath) exists()) {
log info s"no explain csv file ${outPath} exists."
return outPath
}
// 2. 构造文件读取,写入
val reader = new FileReader(path, Charset.forName(readEncoding))
val writer = new FileWriter(outPath, Charset.forName(writeEncoding))
// 3. 获取待缓冲区的读取,写入
val buffReader = new BufferedReader(reader)
val buffWriter = new BufferedWriter(writer)
// 4. 读取一行,根据传入的分隔符分割
buffReader lines() filter (_.split(split).size > 1) forEach (a => buffWriter.write(s"${a}\n"))
// 5. 资源刷新关闭
buffWriter flush()
buffWriter close()
buffReader close()
reader close()
writer close()
outPath
}
这个方法的作用是读取csv文件,然后去除说明行,并进行文件编码转换后的文件用新的文件存储,存储在源文件目录下,需要注意的是如果传入的是已经标准化的文件,那么跳过。
方法的返回值是新csv文件的全路径。
DataFrame 行列转置
读取新的csv文件后,此时数据的排列方式还是横向的,不符合数据库的排列方式。需要将数据做行列转置,将数据的排列方式从横向转置为纵向。
具体思路:
DataFrame可以查询某一个列,将某个列转置为行,将全部的列进行转置,就实现了行列转置。
/**
* DF行列转置,采用每次查询一列的方式
*
* @param data 需要做行列转置的DF
* @param header 指定表头名字,默认为空,为空取 c0,c1...
* @param startCol 开始的列
* @param endCol 结束的列
* @return 行列转置后的DF
*/
def transposeDS(data: DataFrame, header: Array[String] = Array[String](), startCol: Int = 1, endCol: Int = -1) = {
// 1. 获取DF的行数,行数做新DS的列数
val rowCount = if (endCol == -1) data count() else if (endCol > data.count()) data count() else endCol
val rowNo = if (startCol < 0) 0 else startCol
// 2. 根据获取的行数构建schema
var fields = Array[StructField]()
if (header nonEmpty) {
for (h <- header) {
fields = fields :+ StructField(h, StringType, true)
}
} else {
for (i <- Range(0, rowCount toInt)) {
fields = fields :+ StructField(s"c${i}", StringType, true)
}
}
val schema = StructType(StructField("id", StringType, false) +: fields)
// 3. 新的行
var rows = List[Row]()
// 4. 获取每一行
import data.sparkSession.implicits._
for (i <- Range(rowNo, rowCount toInt)) {
// 获取列的数据
val line = data select (s"_c${i}") map (_ getString (0)) collect()
rows = rows :+ Row.fromSeq(UUID.randomUUID().toString.replaceAll("-", "").toUpperCase +: line)
}
// 5. 构造新的DF
data.sparkSession createDataFrame(rows asJava, schema)
}
为了区别,在转置的时候,去除第一列,并新增id列。
在下载的csv文件中,第一列是表头,而这个表头是中文,且比较长,所以需要去除原来的表头,使用指定的表头。
为了防止数据重复导致的问题,新增一个唯一的索引列id
数据存储
在程序中,将转置后的DataFrame存储到hive中,首先以表的方式存储
/**
* 解析一个csv文件,将文件内容去除说明单元格并进行行列转置后,以文件名创建表存储在Hive上
*
* @param sparkSession
* @param file
*/
def parseCsvFile2Hive(sparkSession: SparkSession, file: File): Unit = {
// 如果传入的文件已经是没有说明的文件,表示已经被处理了,直接返回
if (file.getPath.contains(NO_EXPLAIN)) {
log info s"${file getPath} is no explain file, skip it!"
return
}
// 1. 说明单元格去除,以及文件编码的处理
val path = removeExplainCessCsv(file getPath)
log info s"${file getPath} remove explain cell csv success, new file is ${path}"
// 2. 读取新的csv文件,并进行行列转置
val df = transposeDS(sparkSession.read format ("csv") load ("file:\\" + path))
log info s"${path} transpose success!"
// 3. 解析表名
val tableName = path substring(path.lastIndexOf('\\') + 1, path lastIndexOf ('.')) replaceAll(NO_EXPLAIN substring(0, NO_EXPLAIN lastIndexOf '.'), "")
log info s"${path} parse table name is ${tableName}"
// 4. 注册临时视图
df createOrReplaceTempView tableName
// 5. 写入hive
(sparkSession sql s"select * from ${tableName}" write) mode SaveMode.Overwrite saveAsTable tableName
log info s"${tableName} data with mode ${SaveMode.Overwrite name()} save success!"
}
在创建hive表存储的时候,希望使用源csv文件的文件名作为数据库表名。
在写入的时候,指定写入模式为Overwrite
使用saveAsTable为写入数据库表,使用save则是写入hdfs。
主程序逻辑
希望在调用程序的时候,可以指定csv文件或者csv文件的目录(一次处理多个csv文件),需要对传入的路径做处理
def main(args: Array[String]): Unit = {
// 指定hive存储数据库表的所有者,或是hive存储的用户名
System.setProperty("HADOOP_USER_NAME", "hive")
val sparkSession = (SparkSession
builder()
master ("local")
appName ("SparksqlDataApp")
// 配置hive的warehouse目录为远程的hdfs目录
config("spark.sql.warehouse.dir", "hdfs://hadoop01:8020/user/hive/warehouse")
// 启用hive
enableHiveSupport()
getOrCreate())
// 数据的路径,或者是数据的全路径
val rootPath = args(0)
if (rootPath isBlank) {
log error "input param should be a path for csv file or csv files directory! not blank."
return
}
// 切换hive的database为hello数据库
sparkSession sql "use hello"
val rootFile = new File(rootPath)
if (rootFile isDirectory) {
for (file <- rootFile listFiles()) {
parseCsvFile2Hive(sparkSession, file)
}
} else {
parseCsvFile2Hive(sparkSession, rootFile)
}
}
验证
启动
第一次启动会什么都不做,因为需要传入一个路径,直接启动是没有传入的,所以什么都不做,直接结束。
第一次启动后,就可以配置启动信息了
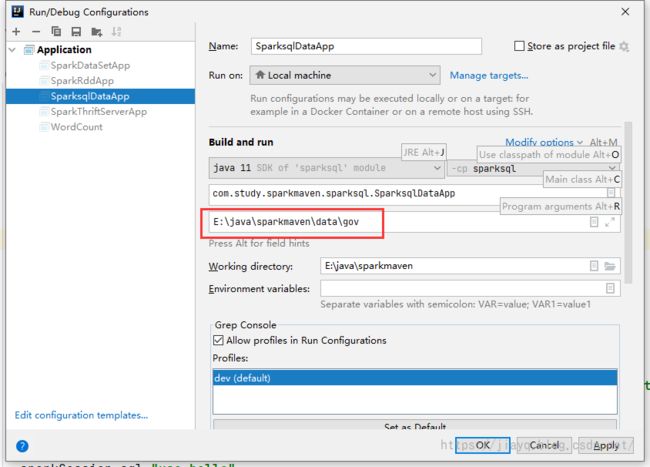
设置启动参数为数据的目录。
本地存储
如果没有设置warehouse目录,那么默认是本地的项目根目录。
直接存储
直接存储是使用save方法
这样保存是在项目根目录下创建表名目录,然后将数据写入这个目录
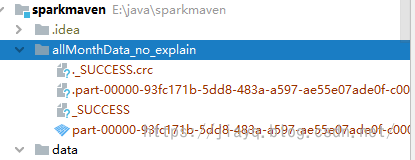
在程序中继续使用这个表,数据的读取来源就是这里。
数据库表存储
数据存储是使用saveAsTable方法
会在wareouse目录下创建指定数据库的文件夹,然后存储,实际数据存储的格式和直接存储相同。
远程存储
要使用远程存储,需要将远程的hive和远程的hdfs的配置文件拷贝到项目的resources目录下
hdfs配置文件hdfs-site.xml
<configuration>
<property>
<name>namename>
<value>hadoop01value>
property>
<property>
<name>dfs.namenode.http-addressname>
<value>hadoop01:9870value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/hadoop/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/hadoop/dfs/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.blocksizename>
<value>2097152value>
property>
<property>
<name>dfs.hostsname>
<value>/hadoop/etc/hadoop/slavesvalue>
property>
<property>
<name>dfs.hosts.excludename>
<value>/hadoop/etc/hadoop/mastersvalue>
property>
configuration>
hadoop的core-site.xml配置
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop01:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/hadoop/tmpvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>hadoop.proxyuser.root.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.root.groupsname>
<value>*value>
property>
configuration>
hive的配置hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.cj.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123456value>
property>
<property>
<name>hive.metastore.schema.verificationname>
<value>falsevalue>
property>
<property>
<name>hive.server2.enable.doAsname>
<value>falsevalue>
property>
<property>
<name>hive.server2.thrift.min.worker.threadsname>
<value>2value>
property>
<property>
<name>hive.server2.thrift.max.worker.threadsname>
<value>5value>
property>
<property>
<name>hive.server2.thrift.portname>
<value>10000value>
property>
<property>
<name>hive.server2.thrift.bind.hostname>
<value>0.0.0.0value>
property>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
property>
configuration>
需要注意远程的mysql需要支持远程访问,可以参考Hive 安装、配置、数据导入和使用_a18792721831的博客-CSDN博客
直接存储
此时启动如果是直接存储,会在hdfs中存储和直接存储类似的数据
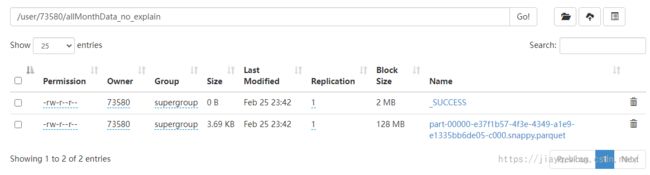
如果没有指定HADOOP_USER_NAME则会以当前登录的windows用户名作为用户名的目录下以表名的目录存储
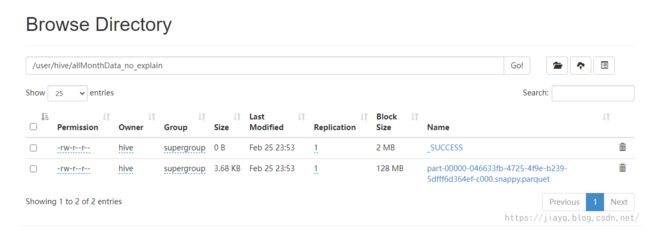
数据库表存储
如果你的hive的元数据不是使用mysql存储,那么会在hdfs上的用户名中以database创建目录,以表名再次创建目录,然后存储
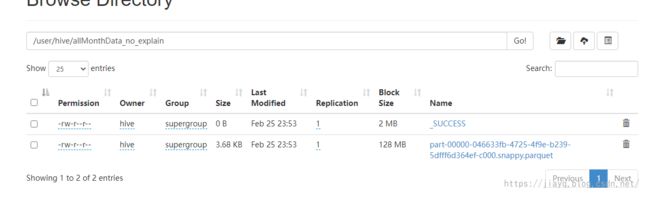
如果是用mysql存储hive的元数据,则会在mysql中存储数据库表的元数据
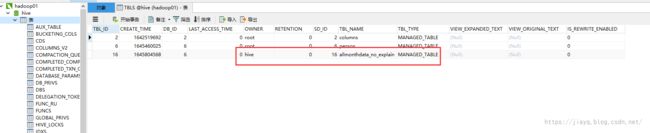
真正的数据存储在warehouse目录下
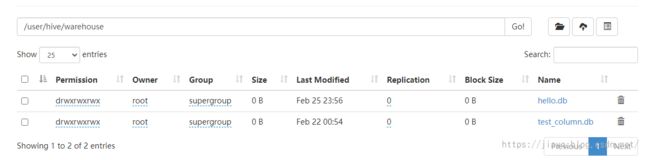
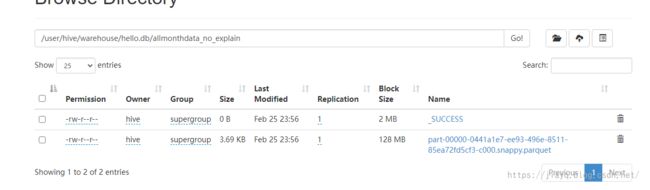
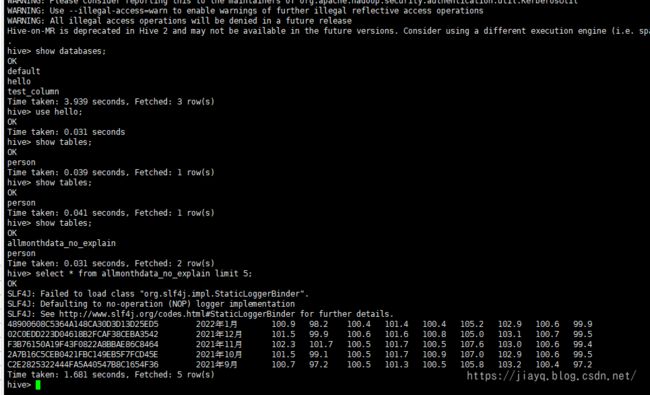
存储为数据库表就可以在hive的客户端中查询了
总结
在实现这个项目的时候,有些难点。
首先是数据如何读取到程序中,因为无法确定文件编码,导致读取的中文总是乱码,后面慢慢尝试,终于找到了正确的编码方式,为了后面处理更加方便,直接使用程序进行转码,将GB18030转为更常用的UTF-8编码。
第二个难点是对说明信息的去除,以及新的csv文件的写入,刚开始完全不知道该如何处理,后来想到scala和java是无缝使用的,那么就直接用java的类进行处理不就好了吗。
第三个难点是DataFrame的行列转置,网上的很多资料都是使用透视实现,可惜我不会使用,好在前面学习了Rdd和DataFrame的相关处理spark sql 创建rdd以及DataFrame和DataSet互转_a18792721831的博客-CSDN博客,就使用最基本的方式处理行列转置。
第四个难点是开发环境集成远程的hdfs和远程的hive,因为刚开始一直是存储在本地,无法存储到集群中,后面根据网上的资料,终于实现了开发环境存储到远程集群中。
虽然难点不少,但是却也是一个不错的例子。
未实现的功能:
首先是只能处理本地文件系统中的数据,无法处理hdfs文件系统中的文件,这块涉及到hdfs文件系统在编码中的使用,暂时还未接触到,所以没有实现。
其次是这应该是个工具类,应该打包放倒集群服务器上,这样就直接使用jar的方式使用,打包操作还未实现。
最后是数据清洗不够彻底,应该把时间中的中文去掉,因为暂时还未想好如何使用这些数据,所以未实现。
原本是打算把数据用可视化的方式展示出来,这部分涉及到数据可视化,还未实现。
不过不用担心,上面这些知识点,比如打包,之前就研究过,只是在这个例子中不是重点,所以没有实现,其他的后面应该会逐渐用到把。
总的来说,实际上做了数据的存储,也就是数仓功能,将数据做简单处理后存储到hive中,提供给其他功能使用。
像类似的框架有Sqoop,后面有机会研究研究。