【知识图谱】07图谱可视化(使用neo4j)
目录
1、建立neo4j数据库
2、数据导入工作
2.1、导入 genre
2.2、导入movie
2.3、导入actor
3、生产关系信息
3.1、生成电影和类型关系
3.2、生成 演员和电影的关系
3.3、关系最终效果预览
4、推理实现
4.1、节点建立
4.2、关联关系
neo4j的安装配置参考:
https://blog.csdn.net/u012052268/article/details/89553588
先来一张预览图:
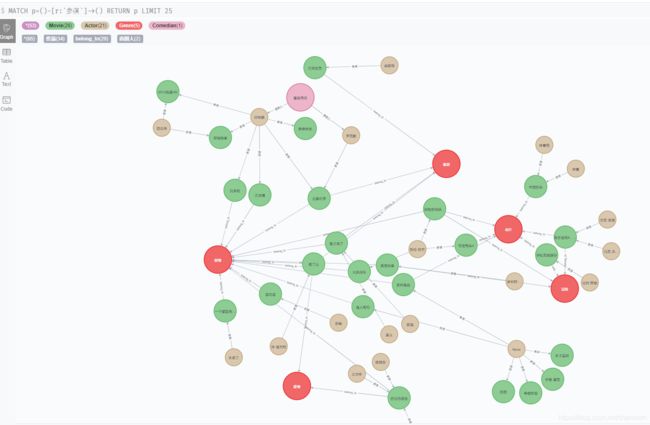
1、建立neo4j数据库
对conf文件右键进行编辑

搜索关键词 dbms.active_database=
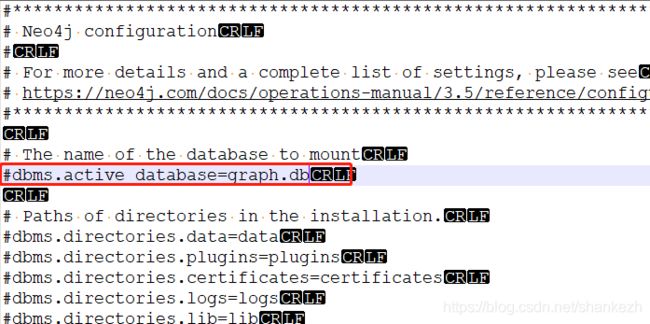
将#dbms.active_database=graph.db 修改成dbms.active_database=kg_movie.db,注意删除符号“#”

启动neo4j服务器
neo4j console可以看到在neo4jxxx/data/databases目录下新增了数据库kg_movie.db
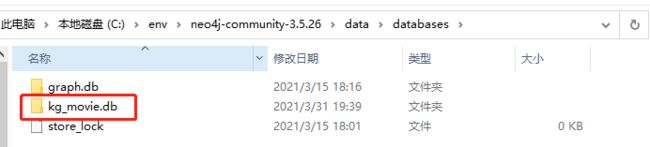
2、数据导入工作
2.1、导入 genre
使用如下命令:
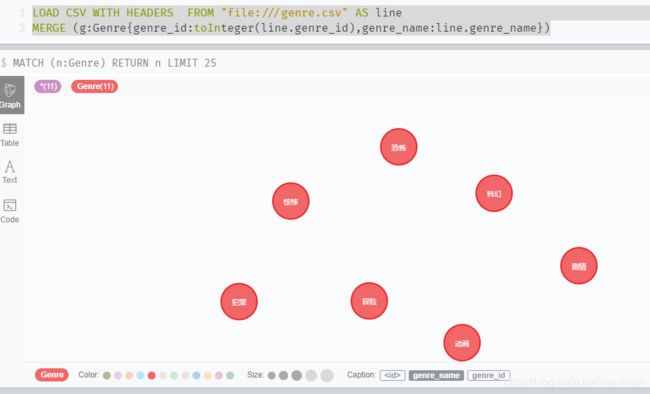
LOAD CSV WITH HEADERS FROM "file:///genre.csv" AS line
CREATE (g:Genre{genre_id:toInteger(line.genre_id),genre_name:line.genre_name})效果:
2.2、导入movie
使用如下命令:
LOAD CSV WITH HEADERS FROM "file:///movie.csv" AS line
CREATE (m:Movie{movie_id:toInteger(line.movie_id),movie_bio:line.movie_bio,movie_chName:line.movie_chName,movie_foreName:line.movie_foreName,movie_prodTime:line.movie_prodTime,movie_prodCompany:line.movie_prodCompany,movie_director:line.movie_director,movie_screenwriter:line.movie_screenwriter,movie_genre:line.movie_genre,movie_star:line.movie_star,movie_length:line.movie_length,movie_releaseTime:line.movie_releaseTime,movie_language:line.movie_language,movie_achiem:line.movie_achiem})效果如图:
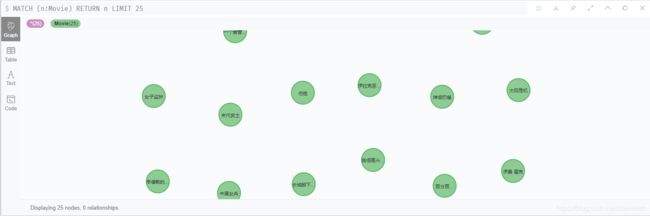
对于如果节点名称显示不是actor_chName的情况,如下操作可以解决:
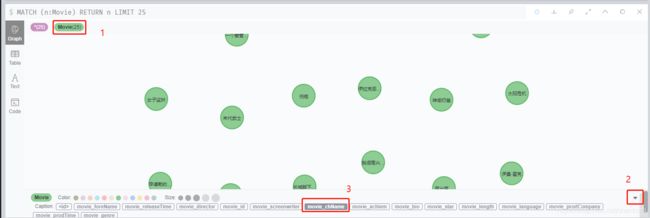
点击图中1处的节点,然后点击2处的展开按钮,选择3处的movie_chName属性作为节点名称显示即可。
2.3、导入actor
使用如下命令:
LOAD CSV WITH HEADERS FROM "file:///actor.csv" AS line
CREATE (a:Actor{actor_id:toInteger(line.actor_id),actor_chName:line.actor_chName,actor_foreName:line.actor_chName,actor_nationality:line.actor_nationality,actor_constellation:line.actor_constellation, actor_birthplace:line.actor_birthplace, actor_birthday:line.actor_birthday, actor_repWorsk:line.actor_repWorks, actor_achiem:line.actor_achiem,actor_brokerage:line.actor_brokerage})效果如下:

3、生产关系信息
生成关系信息,因为neo4j本身就属于数据库,所以我们没必要再利用关系文件生成了。
3.1、生成电影和类型关系
直接进行如下操作:
match (m:Movie),(g:Genre) where m.movie_genre contains g.genre_name create (m) - [r:belong_to] -> (g) return r关系标签可通过左侧导航栏进行快速选择:
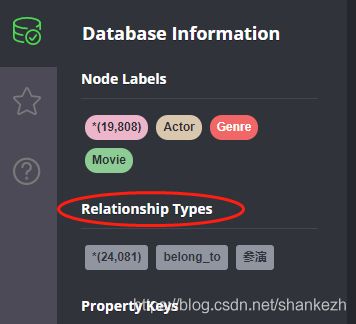
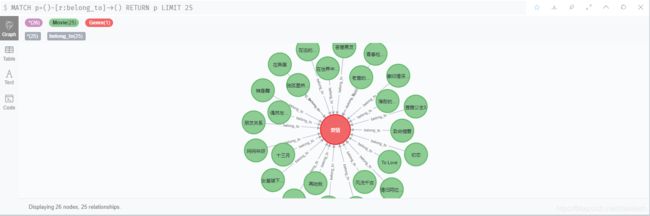
选择刚刚生产的belong_to关系,可看到如下效果:
3.2、生成 演员和电影的关系
如下操作:
match (m:Movie),(a:Actor) where m.movie_star contains a.actor_chName create (a) - [r:参演] -> (m) return r选择左侧参演关系,看到如下效果:
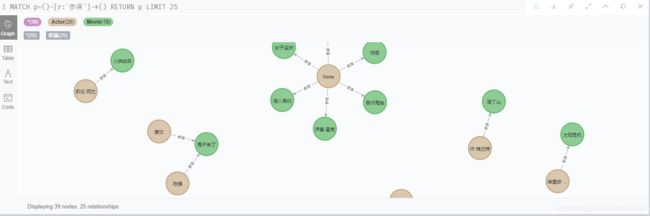
这里有个瑕疵要特殊说明下,这里就再次彰显了数据清洗的重要性,因为我们知道不可能有名字叫None,我们理应在数据准备环节对数据进行清洗,完成这种脏数据的删除工作,避免后续对分析工作的影响。
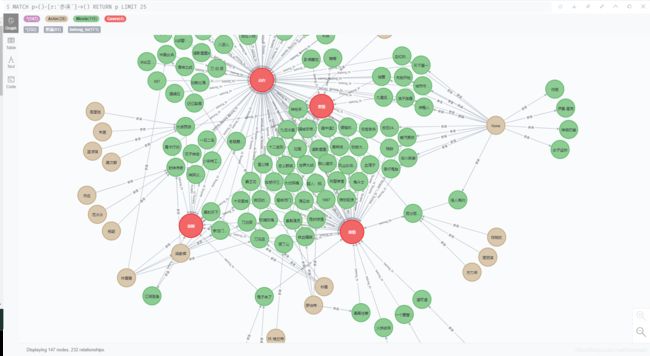
3.3、关系最终效果预览
如下:
4、推理实现
之前有通过Jena+Fuseki来实现自定义规则的推理机,在neo4j中,只能自行通过逻辑实现关系,例如,对于喜剧演员,我们想要实现和Jena+Fuseki一样的效果,则必须做两件事情:(1)建立喜剧演员节点;(2)根据逻辑关系,关联喜剧演员和演员的关系
4.1、节点建立
create (comedian:Comedian {name:'喜剧演员'})4.2、关联关系
喜剧演员推理实现:
match (comedian:Comedian),(m:Movie),(a:Actor) where m.movie_genre contains "喜剧" and m.movie_star contains a.actor_chName merge (comedian) - [r:喜剧人] -> (a) return r这里一定要使用merge而不是create来创建关系,避免节点之间多次指向。
效果图如下:
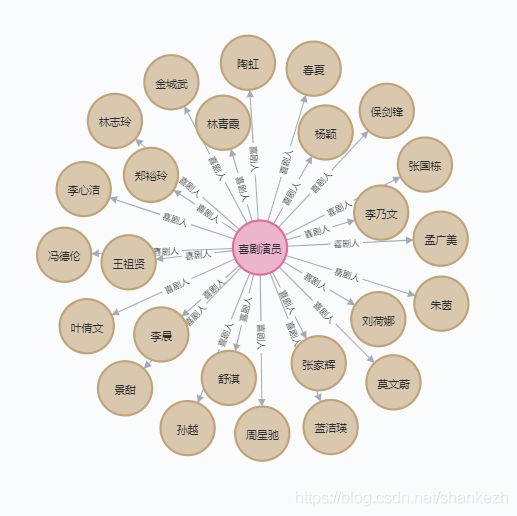
其他:
neo4j和jena+fuseki区别还是体现了出来,neo4j需要通过关系建立匹配,将所有数据跑一遍生成关系才可以完成推理,等于是已有数据的二次加工,而jena+fuseki则是不用对数据进行二次加工,直接关联规则就行了,省去对数据关系关联的处理时间,实时性较好。当然,从工具本身来看,neo4j在业务可读性上,完胜,毕竟自带GUI界面。
附:
关系的删除使用以下:
match p=()-[r:喜剧人]->() delete r完成。