【CentOS】安装 Hadoop (完全分布式)
文章目录
- 一、集群网络配置
-
- 1、克隆虚机,创建节点
- 2、配置节点网络环境
- 二、SSH 无密码验证配置
-
- 1、检查 openssh 和 rsync 服务安装
- 2、每个节点生成秘钥对
- 3、查看秘钥对
- 4、将 id_rsa.pub 追加到授权 key 文件中
- 5、修改文件"authorized_keys"权限
- 6、配置 SSH 服务
- 7、重启 SSH 服务
- 8、验证 SSH 登录本机
- 9、交换秘钥
- 10、验证 SSH 无密码登录
- 三、Hadoop 完全分布式搭建
-
- 1、在 Server 节点上安装 Hadoop
- 2、修改 hadoop-env.sh 配置文件
- 3、配置 hdfs-site.xml 文件参数
- 4、配置 core-site.xml 文件参数
- 5、配置 mapred-site.xml
- 6、配置 yarn-site.xml
- 7、配置 masters、slaves 文件
- 8、新建目录
- 9、同步配置文件到 Agent 节点
- 10、在每个 Slave 节点上配置 Hadoop 的环境变量
- 四、Hadoop 集群运行
-
- 1、配置 Hadoop 格式化 - NameNode 格式化
- 2、slave 启动 DataNode
- 3、server 启动 SecondaryNameNode
- 4、查看 HDFS 数据存放位置
- 5、查看 HDFS 的报告
- 6、使用浏览器查看节点状态
- 五、测试集群
- 六、停止集群
一、集群网络配置
关于节点的搭建可以参考:【CentOS】】创建从节点虚拟机及其配置
环境准备
- 集群(一主两从)
- hadoop-2.7.1.tar.gz 安装包
1、克隆虚机,创建节点
鉴于上一篇【CentOS】安装 Hadoop (单机版)已经存在现有的环境,所以我们选择拷贝虚拟机,首先将 Server 虚机关机:
右击管理找到克隆:
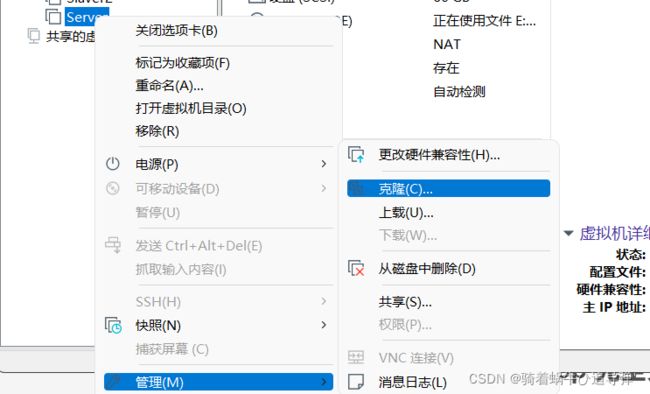
开始克隆,步骤如下:
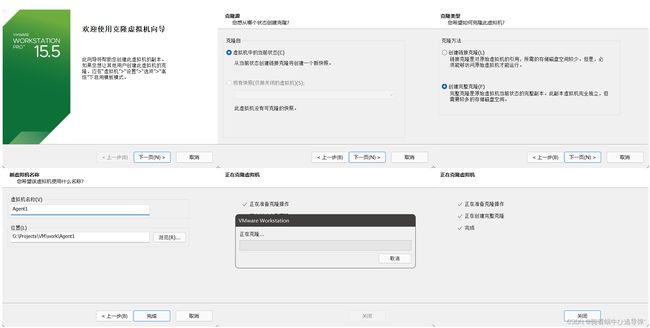
克隆两台虚机即可:
返回顶部
2、配置节点网络环境
根据实验环境下集群网络 IP 地址规划,为主机 server设置 IP 地址是“192.168.64.183”,掩码是“255.255.255.0”;agent1 设置 IP 地址是“192.168.64.184”,掩码是“255.255.255.0”;agent2 设置 IP 地址是“192.168.64.185”,掩码是“255.255.255.0”。
登陆 agent1、agent2 节点机(root:123456):

修改 hostname:
[root@server ~]# hostnamectl set-hostname 目标名称

修改好后,重启节点虚机:

通过 vi /etc/sysconfig/network-scripts/ifcfg-ens33 修改 ip 地址:
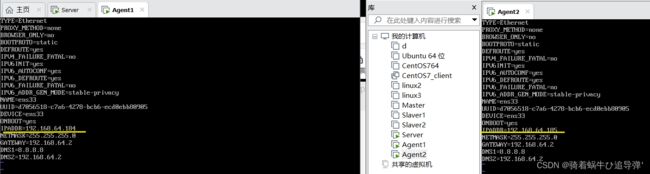
通过 vi /etc/hosts 配置 ip映射(注意一一对应):

节点虚机首先需要通过 service network restart 重新启动一下网络服务,然后测试集群互通:
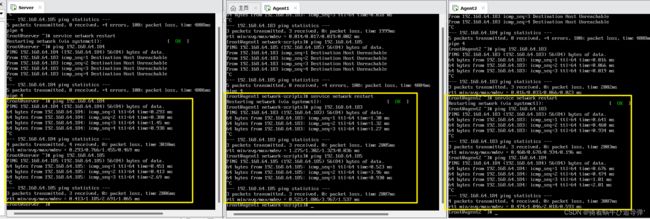
没有出现丢包的情况即为配置完成!
返回顶部
二、SSH 无密码验证配置
1、检查 openssh 和 rsync 服务安装
实现 SSH 登录需要 openssh 和 rsync 两个服务,一般情况下默认已经装,可以通过下面命令查看结果(ip已经配置好,接下来的操作我们使用XShell进行)。
[root@server~]# rpm -qa | grep openssh
openssh-server-7.4p1-11.el7.x86_64
openssh-7.4p1-11.el7.x86_64
openssh-clients-7.4p1-11.el7.x86_64
[root@server~]# rpm -qa | grep rsync
可以看到 rsync 服务没有装配,我们通过 yum install rsync 进行手动装配:

装配完成:
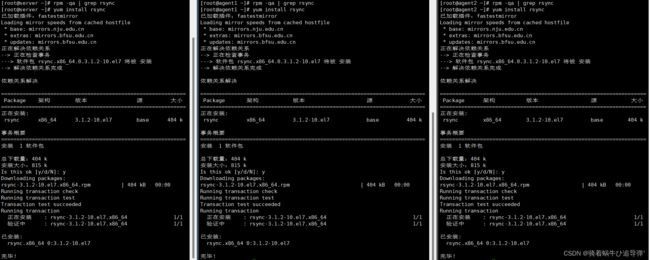
返回顶部
2、每个节点生成秘钥对
通过如下命令生成秘钥对:
ssh-keygen -t rsa -P ''
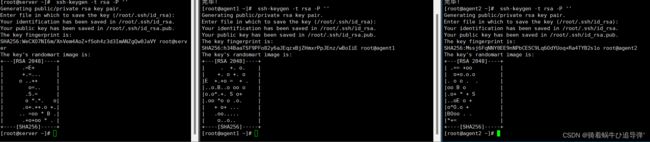
3、查看秘钥对
查看 /home/hadoop/ 下是否有".ssh"文件夹,且".ssh"文件下是否有两个刚生产的无密码密钥对。
![]()
4、将 id_rsa.pub 追加到授权 key 文件中
追加文件使用如下命令:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

返回顶部
5、修改文件"authorized_keys"权限
通过 ll 命令查看,可以看到修改后 authorized_keys 文件的权限为“rw------”,表示所有者可读写,其他用户没有访问权限。如果该文件权限太大,ssh 服务会拒绝工作,出现无法通过密钥文件进行登录认证的情况。
修改文件权限使用如下命令:
chmod 600 ~/.ssh/authorized_keys

6、配置 SSH 服务
使用 root 用户登录,修改 SSH 配置文件 /etc/ssh/sshd_config 的下列内容,需要将 #PubkeyAuthentication yes 配置字段前面的 # 号删除,启用公钥私钥配对认证方式。

7、重启 SSH 服务
systemctl restart sshd # 重启SSH服务
8、验证 SSH 登录本机
在 root 用户下验证能否嵌套登录本机,若可以不输入密码登录,则本机通过密钥登录认证成功。
![]()
注意:首次登录时会提示系统无法确认 host 主机的真实性,只知道它的公钥指纹,询问用户是否还想继续连接。需要输入“yes”,表示继续登录。第二次再登录同一个主机,则不会再出现该提示,可以直接进行登录。
返回顶部
9、交换秘钥
将 server 节点的公钥 id_rsa.pub 复制到每个 agent 节点,使用如下命令:
scp ~/.ssh/id_rsa.pub root@agent1:~/
scp ~/.ssh/id_rsa.pub root@agent2:~/
首次远程连接时系统会询问用户是否要继续连接。需要输入“yes”,表示继续。因为目前尚未完成密钥认证的配置,所以使用 scp 命令拷贝文件需要输入 agent1 节点 root 用户的密码。
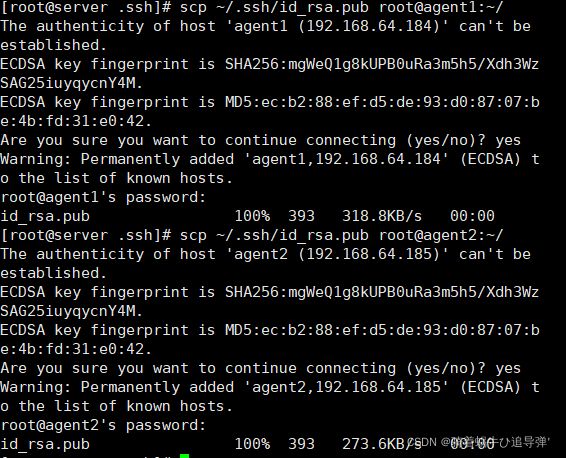
在每个 agent 节点把 server 节点复制的公钥复制到 authorized_keys 文件,使用如下命令:
cat ~/id_rsa.pub >>~/.ssh/authorized_keys
在每个 agent节点删除 id_rsa.pub 文件,使用如下命令:
rm -f ~/id_rsa.pub
将每个 agent节点的公钥保存到 server:使用如下命令:
scp ~/.ssh/id_rsa.pub root@server:~/
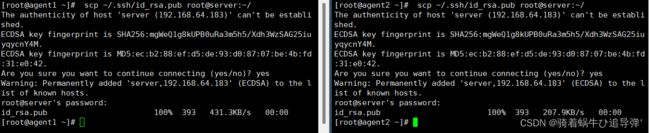
在 server 节点把从 agent 节点复制的公钥复制到 authorized_keys 文件,使用命令如下:
cat ~/id_rsa.pub >>~/.ssh/authorized_keys
![]()
注意:
- 如上图所示,先执行黄色,在执行紫色。
- 从
agent1、agent2复制过来的id_rsa.pub会重写覆盖,所以最后统一删除。
在 server 节点删除 id_rsa.pub 文件,使用命令如下:
rm -f ~/id_rsa.pub
同理,server与agent1、agent2 交换了秘钥,使用同样的操作,对angent1、agent2进行秘钥的交换:
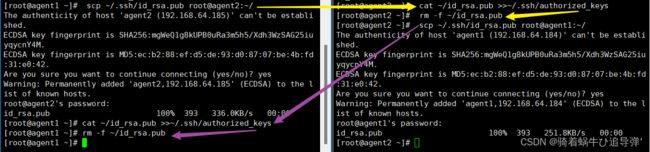
如上图所示进行 agent1 与 agent2 的密钥交换。
返回顶部
10、验证 SSH 无密码登录
查看 Master 节点 authorized_keys 文件,使用命令如下:
cat ~/.ssh/authorized_keys`在这里插入代码片`
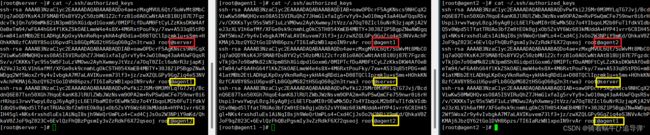
可以看到 server、agent 节点 authorized_keys 文件中包括 server、agent1、agent2 三个节点的公钥。
root 用户登录 server 节点,执行 SSH 命令登录 agent1 和 agent2 节点,可以观察到不需要输入密码即可实现 SSH 登录。同样的通过 root 用户登陆 agent 节点,,执行 SSH 命令登录 agent 和 server 节点,可以观察到也不需要输入密码即可实现 SSH 登录。

这样就实现了单台虚机的免密登陆(互通)!
返回顶部
三、Hadoop 完全分布式搭建
1、在 Server 节点上安装 Hadoop
首先还是解压缩文件夹,对其进行重命名,然后配置 Hadoop 环境变量的时候在 Path 后面多加一个 :$PATH:

修改完成后,别忘了 source 一下~
2、修改 hadoop-env.sh 配置文件
在 /usr/local/src/hadoop/etc/hadoop/hadoop-env.sh 中添加如下内容:
export JAVA_HOME=/usr/local/src/java
返回顶部
3、配置 hdfs-site.xml 文件参数
执行以下命令修改 hdfs-site.xml 配置文件:
[root@server hadoop]# vi hdfs-site.xml
在文件中和一对标签之间追加以下配置信息:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
该配置文件中主要的参数、默认值、参数解释如下表所示:
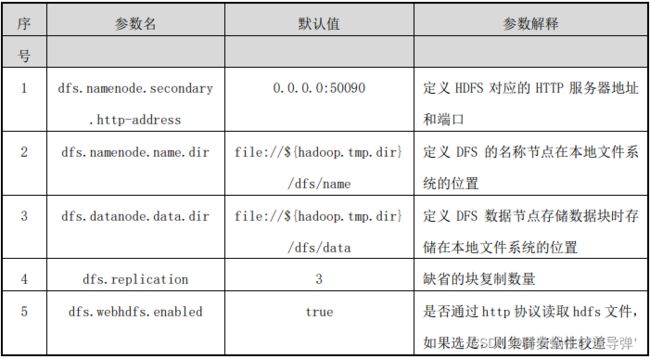
返回顶部
4、配置 core-site.xml 文件参数
执行以下命令修改 core-site.xml 配置文件:
[root@server hadoop]# vi core-site.xml
在文件中和一对标签之间追加以下配置信息:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.64.183:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop/tmp</value>
</property>
</configuration>
如没有配置 hadoop.tmp.dir 参数,此时系统默认的临时目为:/tmp/hadoop-hadoop。 该目录在每次 Linux 系统重启后会被删除,必须重新执行 Hadoop文件系统格式化命令,否则 Hadoop 运行会出错。
该配置文件中主要的参数、默认值、参数解释如下表所示:

返回顶部
5、配置 mapred-site.xml
在 /usr/local/src/hadoop/etc/hadoop 目录下有一个 mapred-site.xml.template,需要修改文件名称,把它重命名为 mapred-site.xml,命令如下:
cd /usr/local/src/hadoop/etc/hadoop
[root@server hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@server hadoop]# vi mapred-site.xml
在文件中和一对标签之间追加以下配置信息:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>server:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>server:19888</value>
</property>
</configuration>
该配置文件中主要的参数、默认值、参数解释如下表所示:
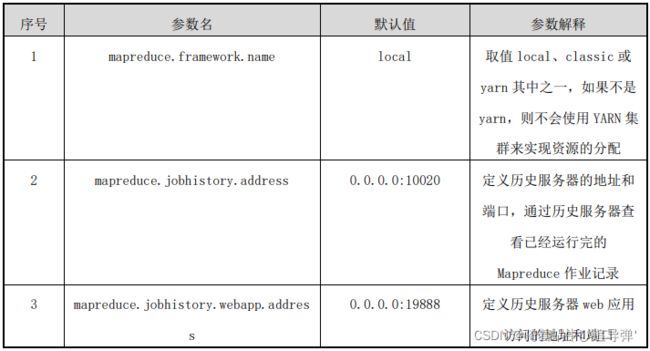
Hadoop 提供了一种机制,管理员可以通过该机制配置 NodeManager 定期运行管理员提供的脚本,以确定节点是否健康。
管理员可以通过在脚本中执行他们选择的任何检查来确定节点是否处于健康状态。如果脚本检测到节点处于不健康状态,则必须打印以字符串 ERROR 开始的一行信息到标准输出。NodeManager 定期生成脚本并检查该脚本的输出。如果脚本的输出包含如上所述的字符串ERROR,就报告该节点的状态为不健康的,且由 NodeManager 将该节点列入黑名单,没有进一步的任务分配给这个节点。但是,NodeManager 继续运行脚本,如果该节点再次变得正常,该节点就会从 ResourceManager 黑名单节点中自动删除。节点的健康状况随着脚本输出,如果节点有故障,管理员可用 ResourceManager Web 界面报告,节点健康的时间也在 Web 界面上显示。
返回顶部
6、配置 yarn-site.xml
执行以下命令修改 yarn-site.xml 配置文件:
[root@server hadoop]# vi yarn-site.xml
在文件中和一对标签之间追加以下配置信息:
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>server:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>server:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>server:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>server:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>server:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
该配置文件中主要的参数、默认值、参数解释如下表所示:
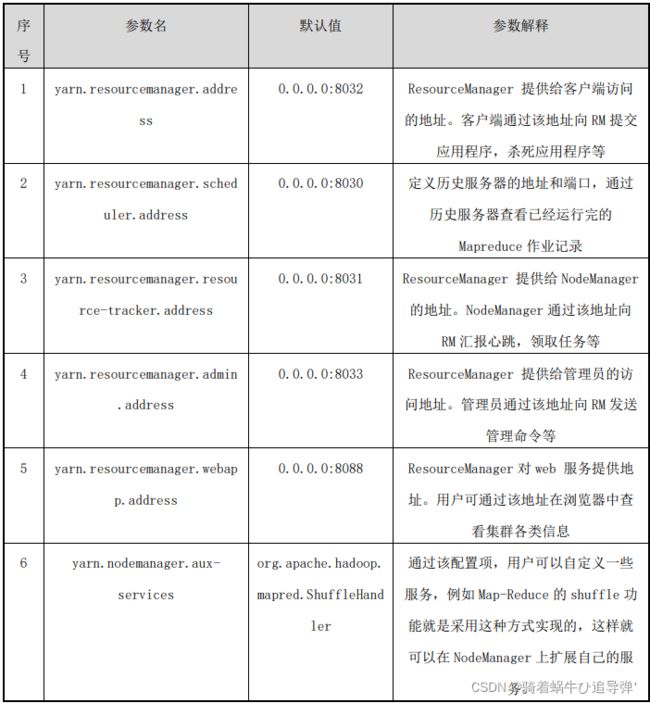
很显然,很多参数没有专门配置,多数情况下使用默认值。例如,可以追加以下两个参数配置项 yarn.resourcemanager.hostname( 即 资 源 管 理 器 主 机 ) 和“yarn.nodemanager.aux-services”(即 YARN 节点管理器辅助服务),若要将主节点也作为资源管理主机配置,则配置值分别为“Master_hadoop”、“mapreduce_shuffle”。
在 yarn-site.xml 中可以配置相关参数来控制节点的健康监测脚本。如果只有一些本地磁盘出现故障,健康检查脚本不应该产生错误。NodeManager 有能力定期检查本地磁盘的健康状况(特别是检查 NodeManager 本地目录和 NodeManager 日志目录),并且在达到基于“yarn.nodemanager.disk-health-checker.min-healthy-disks”属性的值设置的坏目录数量阈值之后,整个节点标记为不健康,并且这个信息也发送到资源管理器。无论是引导磁盘受到攻击,还是引导磁盘故障,都会在健康检查脚本中标识。
返回顶部
7、配置 masters、slaves 文件
执行以下命令修改 masters 配置文件:
#加入以下配置信息
[root@server hadoop]# vi masters
#master 主机 IP 地址
192.168.64.183
需要把所有数据节点的主机名写入该文件,每行一个,默认为 localhost(即把本机作为数据节点),所以,在伪分布式配置时,就采用了这种默认的配置,使得节点既作为名称节点也作为数据节点。在进行分布式配置时,可以保留 localhost,让 Master 节点同时充当名称节点和数据节点,或者也可以删掉 localhost 这行,让 Master 节点仅作为名称节点使用。
执行以下命令修改 slaves 配置文件:
#删除 localhost,加入以下配置信息
[root@server hadoop]# vi slaves
#agent1 主机 IP 地址
192.168.64.184
#agent2 主机 IP 地址
192.168.64.185
返回顶部
8、新建目录
执行以下命令新建文件夹:
[root@server hadoop]# mkdir /usr/local/src/hadoop/tmp
[root@server hadoop]# mkdir /usr/local/src/hadoop/dfs/name -p
[root@server hadoop]# mkdir /usr/local/src/hadoop/dfs/data -p
返回顶部
9、同步配置文件到 Agent 节点
上述配置文件全部配置完成以后,需要执行以下命令把 Master 节点上的“/usr/local/src/hadoop”文件夹复制到各个 Agent 节点上。
将 Server上的 Hadoop 安装文件同步到 agent1、agent2,使用如下命令:
[root@server hadoop]# scp -r /usr/local/src/hadoop/ root@agent1:/usr/local/src/
[root@server hadoop]# scp -r /usr/local/src/hadoop/ root@agent2:/usr/local/src/

10、在每个 Slave 节点上配置 Hadoop 的环境变量

最后 source 一下~
返回顶部
四、Hadoop 集群运行
1、配置 Hadoop 格式化 - NameNode 格式化
将 NameNode 上的数据清零,第一次启动 HDFS 时要进行格式化,以后启动无需再格式化,否则会缺失 DataNode 进程。另外,只要运行过 HDFS,Hadoop 的工作目录(本书设置为/usr/local/src/hadoop/tmp)就会有数据,如果需要重新格式化,则在格式化之前一定要先删除工作目录下的数据,否则格式化时会出问题。
执行如下命令,格式化 NameNode:
[root@server hadoop]# cd /usr/local/src/hadoop/
[root@server hadoop]# bin/hdfs namenode –format
出现如下信息即可:
22/02/20 21:47:26 INFO namenode.NameNode: createNameNode [–format]
Usage: java NameNode [-backup] |
[-checkpoint] |
[-format [-clusterid cid ] [-force] [-nonInteractive] ] |
[-upgrade [-clusterid cid] [-renameReserved ] |
[-finalize] |
[-importCheckpoint] |
[-initializeSharedEdits] |
[-bootstrapStandby] |
[-recover [ -force] ] |
[-metadataVersion ] ]
22/02/20 21:47:26 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at server/192.168.64.183
************************************************************/
执行如下命令,启动 NameNode:
[root@server hadoop]# hadoop-daemon.sh start namenode
starting namenode, logging to /usr/local/src/hadoop/logs/hadoop-root-namenode-server.out
启动完成后,可以使用 JPS 命令查看是否成功。JPS 命令是 Java 提供的一个显示当前所有 Java 进程 pid 的命令。
[root@server hadoop]# jps
3091 Jps
3022 NameNode
返回顶部
2、slave 启动 DataNode
执行如下命令,启动 DataNode:
[root@agent1 hadoop]# hadoop-daemon.sh start datanode
starting datanode, logging to /usr/local/src/hadoop/logs/hadoop-root-datanode-agent1.out
[root@agent2 hadoop]# hadoop-daemon.sh start datanode
starting datanode, logging to /usr/local/src/hadoop/logs/hadoop-root-datanode-agent2.out

返回顶部
3、server 启动 SecondaryNameNode
执行如下命令,启动 SecondaryNameNode:
[root@server hadoop]# hadoop-daemon.sh start secondarynamenode
starting secondarynamenode, logging to /usr/local/src/hadoop/logs/hadoop-root-secondarynamenode-server.out
[root@server hadoop]# jps
3185 Jps
3142 SecondaryNameNode
3022 NameNode
查看到有 NameNode 和 SecondaryNameNode 两个进程,就表明 HDFS 启动成功。
返回顶部
4、查看 HDFS 数据存放位置
执行如下命令,查看 Hadoop 工作目录:
[root@server hadoop]# ll dfs/
总用量 0
drwxr-xr-x. 2 root root 6 2月 20 22:54 data
drwxr-xr-x. 3 root root 40 2月 20 22:58 name
[root@server hadoop]# ll ./tmp/dfs
总用量 0
drwxr-xr-x. 3 root root 40 2月 20 23:17 namesecondary
可以看出 HDFS 的数据保存在 /usr/local/src/hadoop/dfs 目录下,NameNode、DataNode 和 /usr/local/src/hadoop/tmp/ 目录下,SecondaryNameNode 各有一个目录存放数据。
返回顶部
5、查看 HDFS 的报告
使用如下命令查看 HDFS 的报告:
[root@server hadoop]# hdfs dfsadmin -report
Configured Capacity: 82201755648 (76.56 GB)
Present Capacity: 77787983872 (72.45 GB)
DFS Remaining: 77787967488 (72.45 GB)
DFS Used: 16384 (16 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (2):
Name: 192.168.64.184:50010 (agent1)
Hostname: agent1
Decommission Status : Normal
Configured Capacity: 41100877824 (38.28 GB)
DFS Used: 8192 (8 KB)
Non DFS Used: 2206896128 (2.06 GB)
DFS Remaining: 38893973504 (36.22 GB)
DFS Used%: 0.00%
DFS Remaining%: 94.63%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sun Feb 20 23:21:11 CST 2022
Name: 192.168.64.185:50010 (agent2)
Hostname: agent2
Decommission Status : Normal
Configured Capacity: 41100877824 (38.28 GB)
DFS Used: 8192 (8 KB)
Non DFS Used: 2206875648 (2.06 GB)
DFS Remaining: 38893993984 (36.22 GB)
DFS Used%: 0.00%
DFS Remaining%: 94.63%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sun Feb 20 23:21:09 CST 2022
返回顶部
6、使用浏览器查看节点状态
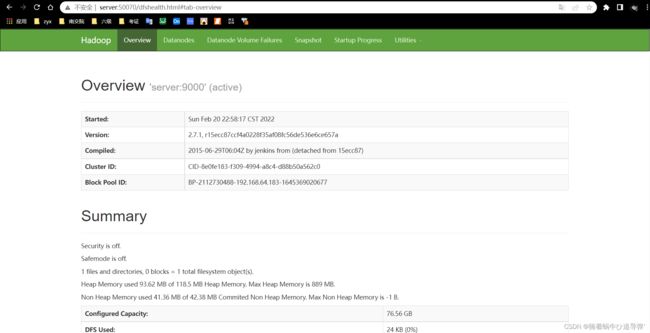
在浏览器的地址栏输入http://server:50070,进入页面可以查看NameNode和DataNode信息,如图所示:
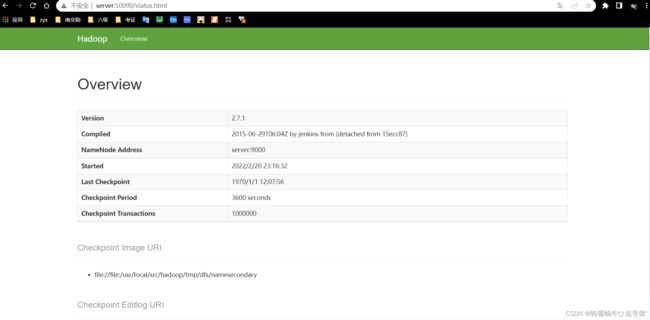
在浏览器的地址栏输入http://server:50090,进入页面可以查看SecondaryNameNode信息,如图所示:
注意:
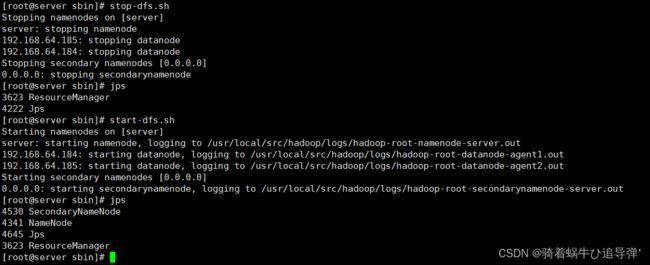
可以使用 start-dfs.sh 命令启动 HDFS,这时需要配置 SSH 免密码登录,否则在启动过程中系统将多次要求确认连接和输入 Hadoop 用户密码。(这里已经配置好了SSH免密登录)
返回顶部
五、测试集群
确保 dfs 和 yarn 都启动成功:
[root@server sbin]# start-yarn.sh
starting yarn daemons
resourcemanager running as process 3623. Stop it first.
192.168.64.185: nodemanager running as process 2181. Stop it first.
192.168.64.184: nodemanager running as process 2211. Stop it first.
[root@server sbin]# jps
4530 SecondaryNameNode
4341 NameNode
3623 ResourceManager
4744 Jps
如果是第一次运行 MapReduce 程序,需要先在 HDFS 文件系统中创建数据输入目录,存放输入数据。这里指定/input 目录为输入数据的存放目录:
[root@server sbin]# hdfs dfs -mkdir /input
[root@server sbin]# hdfs dfs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2022-02-20 23:48 /input
注意:此处创建的/input 目录是在 HDFS 文件系统中,只能用 HDFS 命令查看和操作。
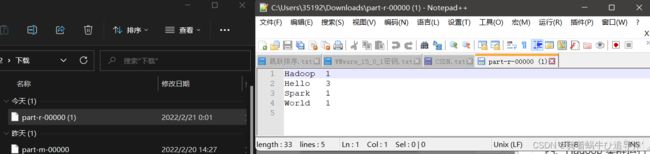
测试用数据文件仍然是之前所用的测试数据文件~/input/data.txt,内容如下所示:
[root@server sbin]# cat ~/input/data.txt
Hello World
Hello Hadoop
Hello Spark
执行如下命令,将输入数据文件复制到 HDFS 的 /input 目录中:
[root@server sbin]# hdfs dfs -put ~/input/data.txt /input
[root@server sbin]# hdfs dfs -ls /input
Found 1 items
-rw-r--r-- 3 root supergroup 37 2022-02-20 23:50 /input/data.txt
运行 MapReduce 命令需要指定数据输出目录,该目录为 HDFS 文件系统中的目录,会自动生成。如果在执行 MapReduce 命令前,该目录已经存在,则执行MapReduce 命令会出错。例如 MapReduce 命令指定数据输出目录为 /output,/output 目录在 HDFS 文件系统中已经存在,则执行相应的 MapReduce 命令就会出错。所以如果不是第一次运行 MapReduce,就要先查看HDFS中的文件,是否存在/output目录。如果已经存在/output目录,就要先删除 /output 目录,再执行上述命令。
执行如下命令运行 WordCount 案例:
[root@server bin]# cd /usr/local/src/hadoop/
[root@server hadoop]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /input/data.txt /output
22/02/20 23:55:34 INFO client.RMProxy: Connecting to ResourceManager at server/192.168.64.183:8032
22/02/20 23:55:35 INFO input.FileInputFormat: Total input paths to process : 1
22/02/20 23:55:35 INFO mapreduce.JobSubmitter: number of splits:1
22/02/20 23:55:36 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1645371261727_0001
22/02/20 23:55:36 INFO impl.YarnClientImpl: Submitted application application_1645371261727_0001
22/02/20 23:55:36 INFO mapreduce.Job: The url to track the job: http://server:8088/proxy/application_1645371261727_0001/
22/02/20 23:55:36 INFO mapreduce.Job: Running job: job_1645371261727_0001
22/02/20 23:55:49 INFO mapreduce.Job: Job job_1645371261727_0001 running in uber mode : false
22/02/20 23:55:49 INFO mapreduce.Job: map 0% reduce 0%
22/02/20 23:56:04 INFO mapreduce.Job: map 100% reduce 0%
22/02/20 23:56:09 INFO mapreduce.Job: map 100% reduce 100%
22/02/20 23:56:09 INFO mapreduce.Job: Job job_1645371261727_0001 completed successfully
22/02/20 23:56:09 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=55
FILE: Number of bytes written=231029
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=143
HDFS: Number of bytes written=33
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=11920
Total time spent by all reduces in occupied slots (ms)=2468
Total time spent by all map tasks (ms)=11920
Total time spent by all reduce tasks (ms)=2468
Total vcore-seconds taken by all map tasks=11920
Total vcore-seconds taken by all reduce tasks=2468
Total megabyte-seconds taken by all map tasks=12206080
Total megabyte-seconds taken by all reduce tasks=2527232
Map-Reduce Framework
Map input records=3
Map output records=6
Map output bytes=61
Map output materialized bytes=55
Input split bytes=106
Combine input records=6
Combine output records=4
Reduce input groups=4
Reduce shuffle bytes=55
Reduce input records=4
Reduce output records=4
Spilled Records=8
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=590
CPU time spent (ms)=5570
Physical memory (bytes) snapshot=434831360
Virtual memory (bytes) snapshot=4201480192
Total committed heap usage (bytes)=272629760
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=37
File Output Format Counters
Bytes Written=33
由上述信息可知 MapReduce 程序提交了一个作业,作业先进行 Map,再进行 Reduce 操作。
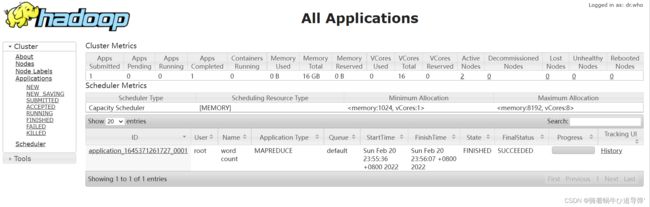
MapReduce 作业运行过程也可以在 YARN 集群网页中查看。在浏览器的地址栏输入:http://server:8088,页面如下图所示,可以看到 MapReduce 程序刚刚完成了一个作业:
除了可以用 HDFS 命令查看HDFS文件系统中的内容,也可使用网页查看 HDFS 文件系统。在浏览器的地址栏输入 http://master:50070,进入页面,在 Utilities 菜单中选择 Browse the file system,可以查看 HDFS 文件系统内容。如下图所示,查看 HDFS 的根目录,可以看到 HDFS 根目录中有三个目录,input、output 和 tmp:
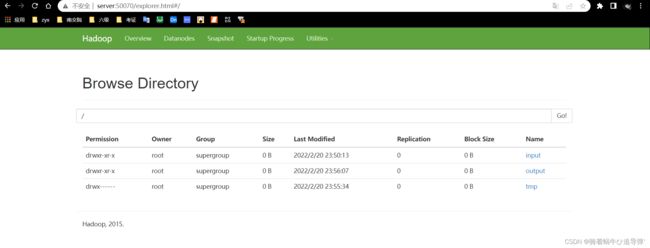
查看 output 目录,如下图 所示,发现有两个文件。文件_SUCCESS 表示处理成功,处理的结果存放在 part-r-00000 文件中。在页面上不能直接查看文件内容,需要下载到本地系统才行:
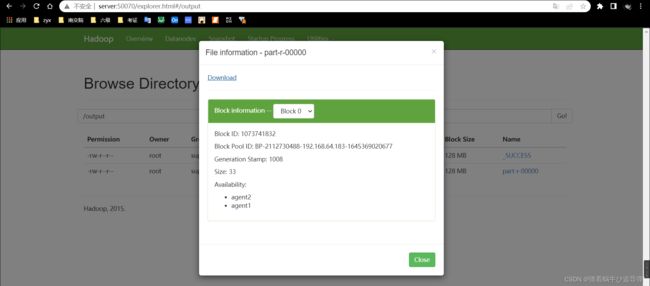
下载后查看:
返回顶部
六、停止集群
停止 yarn:
[root@server hadoop]# stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
192.168.64.184: stopping nodemanager
192.168.64.185: stopping nodemanager
192.168.64.184: nodemanager did not stop gracefully after 5 seconds: killing w
192.168.64.185: nodemanager did not stop gracefully after 5 seconds: killing w
no proxyserver to stop
停止 DataNode:
[root@agent1 src]# hadoop-daemon.sh stop datanode
stopping datanode
[root@agent2 src]# hadoop-daemon.sh stop datanode
stopping datanode
停止 NameNode:
[root@server hadoop]# hadoop-daemon.sh stop namenode
stopping namenode
停止 SecondaryNameNode:
[root@server hadoop]# hadoop-daemon.sh stop secondarynamenode
stopping secondarynamenode
查看 JAVA 进程,确认 HDFS 进程已全部关闭:
![]()
返回顶部