Spark:基础入门与环境搭建
目录
01:学习目标
02:分布式计算需求及发展
03:Spark的诞生及发展
04:Spark的功能及特点
05:Spark的应用场景
06:MR的设计回顾
07:Spark的基本设计
08:Spark与MR设计对比
09:环境部署:版本与编译
10:环境部署:运行模式
11:环境部署:集群架构
12:环境部署:本地模式环境
13:环境部署:本地模式测试
14:环境部署:Standalone集群搭建
15:环境部署:Standalone集群测试
16:环境部署:Standalone集群HA
17:Spark程序:基本组成
18:Spark程序:监控组件
附录一:导入Spark集群虚拟机
1、拷贝三台机器
2、导入三台机器
3、启动三台机器
4、Windows配置映射
附录一:Spark Maven依赖
01:学习目标
-
整体目标:初学入门
-
离线
-
SparkCore:类似于MapReduce,最核心的知识
-
SparkSQL:类似于Hive,最常用的内容,基于SparkCore封装的SQL计算层
-
-
实时
-
SparkStreaming:准实时计算,基于SparkCore用离线模拟实时:1天
-
StructStreaming:真实时计算,基于SparkSQL实现实时计算,归属于SparkSQL:1天
-
-
-
今天目标
-
分布式计算需求以及常见的分布式计算的技术有哪些?
-
==Spark的功能、特点【与MapReduce对比】、应用场景?==
-
与MR有什么区别?
-
为什么比MR要快?
-
Spark的核心设计思想?
-
-
Spark的集群和程序测试
-
分布式集群架构
-
分布式集群搭建
-
-
==Spark程序的基本组成和监控平台==
-
Master:主节点
-
Worker:从节点
-
Driver、Executor、Job、Stage、Task
-
-
02:分布式计算需求及发展
-
目标:了解分布式计算的需求及发展
-
为什么要有分布式计算?
-
常用分布式计算的技术有哪些?
-
-
路径
-
step1:分布式计算的需求
-
step2:分布式计算技术的发展
-
-
实施
-
需求
-
问题1:现在有一台机器,内存有4G,要对一个40G的文件内容进行排序,怎么办?
-
单机资源不足
-
-
问题2:现在有一台机器,内存有256G,要在ms级别实现一个100G的文件进行解析处理,怎么办?
-
单机性能较差
-
-
解决:分布式计算
-
-
发展
-
第一代计算:MapReduce
-
离线:文本计算
-
-
第二代计算:Tez/Storm
-
离线:Tez基于MR做了颗粒度拆分
-
实时:Storm
-
-
第三代计算:Spark
-
离线+实时:lambda架构
-
==目前在工作中主要使用的离线计算引擎==
-
-
第四代计算:Flink
-
所有计算全部通过实时来实现:Kappa架构
-
==目前在工作中主要使用实时计算引擎==
-
-
-
-
小结
-
分布式计算主要解决了单机计算资源不足和单机计算性能较差的问题
-
03:Spark的诞生及发展
-
目标:了解Spark的诞生及发展
-
实施
-
诞生
-
https://databricks.com/spark/about
-

-
-
发展
-
http://spark.apache.org/
-
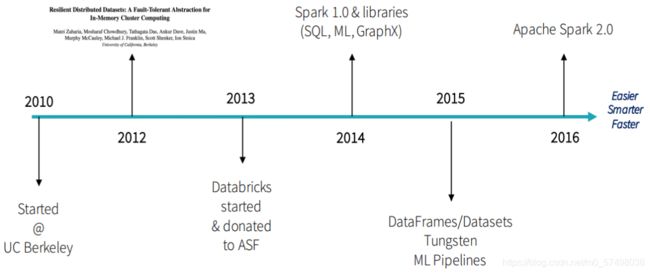
2014:Spark1.x
-
2016:Spark2.x
-
2020:Spark3.x
-
-
-
小结
-
了解Spark的诞生及发展
-
04:Spark的功能及特点
-
目标:掌握Spark的功能及特点
-
Spark可以解决哪些分布式计算的场景?
-
为什么用Spark而不用MapReduce?
-
-
路径
-
step1:定义
-
step2:功能
-
step3:特点
-
-
实施
-
定义
Apache Spark is a lightning-fast unified analytics engine for big data and machine learning. It was originally developed at UC Berkeley in 2009.-
Spark是一个光速的、统一化的分布式分析计算引擎和机器学习算法库
-
-
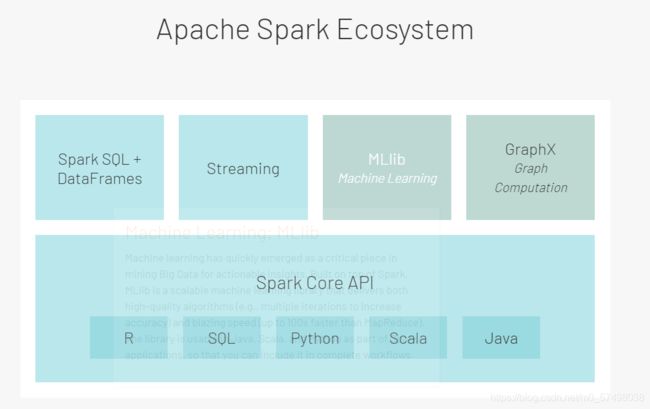
功能:数据分析引擎工具栈
-
实现离线数据批处理:SparkCore
-
代替MapReduce
-
-
实现交互式数据分析:SparkSQL
-
代替Hive实现SQL分布式计算
-
-
实现实时数据处理:SparkStreaming / StructStreaming
-
代替Storm/Flink
-
-
实现机器学习的开发:Spark ML lib
-
代替Python中机器学习库
-
-
-
特点
-
Speed:快
-
比MapReduce处理同样的数据的性能快上100倍以上
-
为什么很快?
-
积极使用内存:所有处理和计算尽量使用内存来实现
-
-
-
Easy Of Use:好使
-
支持多种开发接口
-
Java/Python/SQL/DSL/R/Scala
-
-
Generality:通用性
-
功能非常全面:任何一种大数据分析计算的场景都可以使用Spark来解决
-
-
SparkCore:基于代码的离线批处理计算,类似于MR
-
SparkSQL
-
离线:基于SQL实现离线批处理计算,类似于Hive
-
实时:StructStreaming,使用SQL实现实时数据计算
-
-
Streaming:基于SparkCore实现实时数据计算
-
MLlib:机器学习算法库
-
Graphx:图计算,数据结构中的图的计算
-
-
Runs Everywhere:随处运行
-
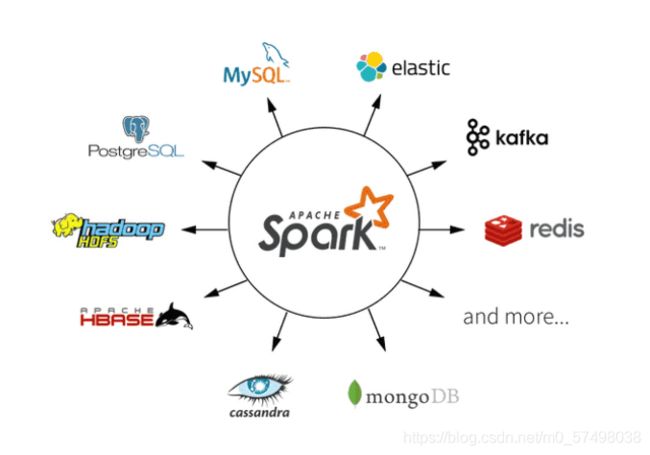
数据源接口非常丰富:==提供了各种读写数据源接口==
-
离线:HDFS、Hive、MySQL、Hbase
-
实时:Kafka
-
-
-
==Spark程序可以运行在各个资源平台上==
-
Standalone:Spark自带的资源平台
-
YARN:工作中主要使用的资源平台
-
Messos
-
K8s
-
-
-
-
-
小结
-
Spark的功能是什么?
-
定义:Spark一个光速的,统一化的分布式数据分析引擎和机器学习算法库
-
功能:离线批处理、SQL交互式处理、实时计算、机器学习、图计算
-
-
Spark有哪些特点?
-
快、接口非常丰富、功能非常全面、随处运行
-
-
05:Spark的应用场景
-
目标:掌握Spark目前在工作中的主要应用场景
-
大数据开发工作中什么时候会用到Spark进行开发?
-
-
实施
-
离线
-
数据采集:Flume、Sqoop、FileBeats、Logstash
-
数据存储:HDFS/Hive
-
数据处理:SparkCore【ETL】、SparkSQL【分析处理】
-
-
实时
-
数据采集:Flume、Logstash、Canal
-
数据存储:Kafka
-
数据处理:SparkStreaming/StructStreaming【流式数据处理】
-
-
-
小结
-
Spark主要应用于哪些场景下?
-
==离线:利用SparkCore和SparkSQL==
-
实时:利用SparkStreaming和StructStreaming
-
目前工作中主要用Flink来代替Spark
-
-
-
06:MR的设计回顾
-
目标:回顾MapReduce的设计流程
-
路径
-
step1:MR的实现设计
-
step2:MR的缺点
-
-
实施
-
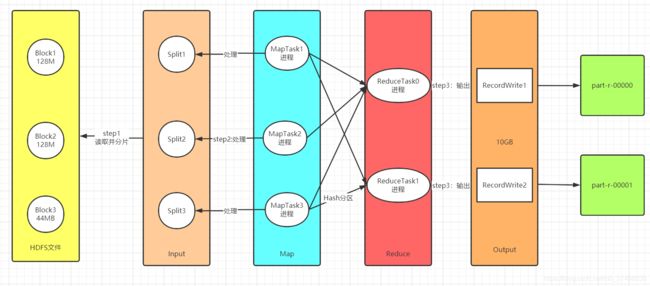
MR的实现设计
-
Input:负责读取数据:InputFormat:TextInputFormat、DBInputFormat、TableInputFormat
-
功能一:实现分片,将读取到的数据进行划分,将不同的数据才能分给不同Task
-
功能二:转换KV
-
-
Map:负责数据处理:一对一的转换,多对一的过滤
-
功能一:构建分布式并行Task,每个分片对应一个MapTask【进程】
-
功能二:每个MapTask负责自己处理的分片的数据的转换,转换逻辑由map方法来决定
-
-
Shuffle:负责数据处理
-
Map输出写入数据:磁盘
-
功能:实现全局的:排序、分组
-
Reduce读取Map输出的数据:读取磁盘
-
-
Reduce:负责数据处理:多对一的聚合
-
功能:默认由一个ReduceTask【进程】来实现数据的聚合处理
-
-
Output:负责保存结果:OutputFormat:TextOutputFormat、DBOutputFormat、TableOutputFormat
-
功能:将上一步的结果写入外部系统
-
-
-
MR的缺点
-
优点:开发简单,学习成本低,对硬件要求不高
-
缺点:灵活性和性能都比较差,无法实现数据的持续性处理,中间结果必须落地磁盘,Task以进程方式维护
-
灵活性差:最多只能有一个Map和一个Reduce,无法实现Map Reduce Map Reduce Map Map Reduce Reduce
-
性能较差
-
基于磁盘:每个阶段的结果必须写入磁盘,下一个阶段必须读磁盘
-
进程级别:每个Task的运行启动处理都必须构建一个进程,进程的启动、维护和销毁都是非常慢的过程
-
-
-
-
-
小结
-
了解MapReduce整体的设计实现过程及优缺点
-
07:Spark的基本设计
-
目标:了解Spark的基本设计及实现过程和优缺点
-
路径
-
step1:Spark的设计流程
-
step2:Spark的优点
-
-
实施
-
Spark的设计流程
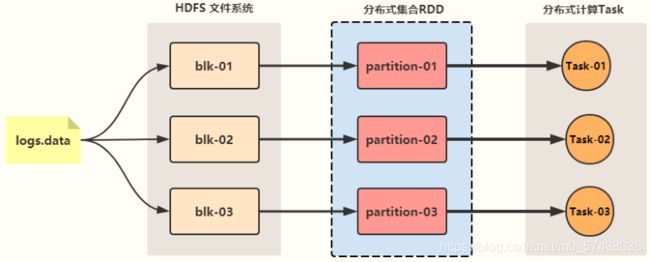
-
step1:读取数据:调用TextInputFormat类
-
将所有数据源的数据全部封装在一个分布式集合中:RDD
-
一个RDD中有多个分区,每个分区存储在不同的机器上的内存中
-
RDD的一个分区就相当于MR中的一个分片
-
-
-
step2:处理数据
-
对RDD这个集合中的数据进行处理:调用集合函数对集合的数据进行处理
-
map、flatMap、foreach、reduce、fold、sortBy、zip
-
-
本质上:启动多个Task对这个RDD的每个分区进行处理
-
-
step3:保存结果
-
将每个Task处理的结果进行保存
-
-
-
Spark的优点
-
RDD:理解RDD就是一个分布式List集合,RDD集合的数据分布式的存储在不同机器的内存中
-
所有处理的都是基于RDD的函数转换处理:所有RDD的处理结果会返回一个的RDD
-
所有RDD的构建都是Lazy模式的,为了避免RDD没有被使用,占用分布式内存
-
-
DAG:有向无环图,基于整个程序的不同的操作实现复杂程序逻辑
-
任意实现一个程序中有多个Map和多个Reduce
-
多个Map操作之间的数据转换全部在内存中完成
-
-
Task:基于线程级别,RDD的一个分区对应一个Task,一个Task对应一个线程,一个线程使用CPU的1Core来处理
-
所有分区的所有Map和Reduce的操作全部直接以Task形式放在进程中运行
-
进程只需要构建一次即可
-
-
-
-
小结
-
了解Spark的基本设计及实现过程和优缺点
-
08:Spark与MR设计对比
-
目标:了解Spark与MapReduce的差异性
-
实施
-
为什么Spark要比MapReduce更好?
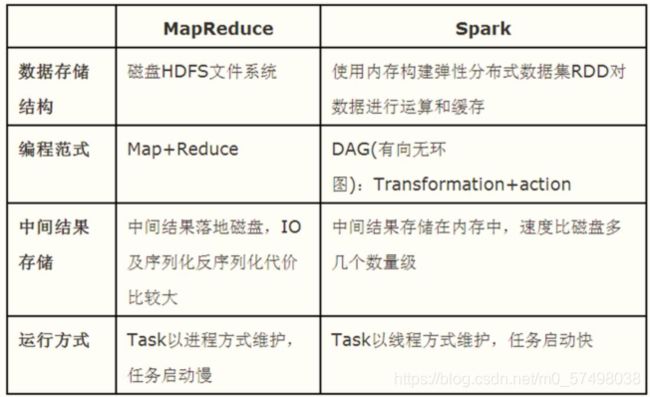
-
-
小结
-
了解Spark与MapReduce的差异性
-
09:环境部署:版本与编译
-
目标:了解Spark的版本与编译
-
实施
-
版本
-
1.x:1.6,2016年之前
-
2.x:对1.x做了重构,引入了很多新的流式计算的特性
-
目前工作中主要的版本:2.4+版本
-
-
3.x:对2.x的一些流式计算做了重构,引入一些新的特性,性能更好
-
目前一些大的公司在投产使用
-
-
发型厂商
-
Apache:不建议小公司使用,如果用建议自己编译,基于自己环境版本
-
Hadoop、Zookeeper、Hbase、Hive版本
-
-
Cloudera:官方编译好的Spark是阉割版本:没有SparkSQL
-
基于Cloudera的其他工具版本,自己编译
-
-
-
-
编译
-
Maven编译
-
step1:下载源码
-
step2:修改pom文件中的依赖版本
-
step3:通过maven编译即可
-
-
-
小结
-
了解Spark的版本与编译
-
10:环境部署:运行模式
-
目标:掌握Spark的常用运行模式
-
实施
-
本地模式
-
程序运行在本地【当前这台机器】,只启动一个进程来运行所有Task
-
应用:测试开发:代码的逻辑
-
开发:IDEA
-
运行:右键运行
-
-
-
集群模式
-
程序提交到集群运行【分布式运行多台机器上】,将程序的Task运行在不同机器的不同进程中
-
应用
-
测试集群:测试环境是否有问题
-
生产环境:生产运行的平台
-
开发:jar包
-
运行
-
Hadoop:yarn
-
Spark:spark-submit
-
-
-
-
-
小结
-
Spark的运行模式有几种?
-
本地模式:在本地这台机器直接运行【启动一个进程运行】,测试:代码逻辑
-
集群模式:多台机器的分布式运行
-
测试:测试环境
-
生产:生产运行
-
-
-
11:环境部署:集群架构
-
目标:掌握Spark集群模式的集群架构
-
实施
-
架构
-
分布式主从架构
-
主:管理从节点,资源管理和任务调度
-
从:管理自己这台机器的资源,运行Task
-
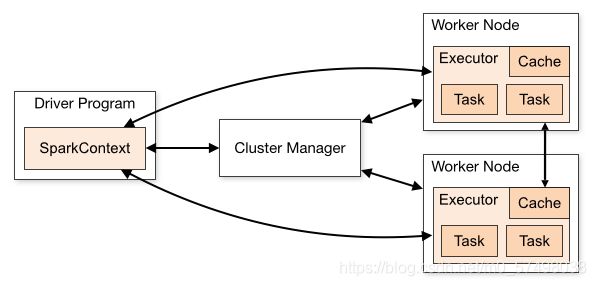
-
-
角色
-
Cluster Manager:主节点
-
YARN:ResourceManager
-
Standalone:Master
-
-
Worker Node:从节点
-
YARN:NodeManager
-
Standalone:Worker
-
-
Driver:每个Spark程序都会包含这个特殊的进程
-
这个进程负责整个程序的资源申请、Task解析、分配、监控
-
类似于YARN中的ApplicationMaster
-
-
Executor:每个Spark程序都会至少有1个Executor进程
-
这个进程负责运行整个程序的所有Task【线程】
-
运行在从节点上
-
类似于Mapreduce中的MapTask和ReduceTask
-
-
Task:运行的线程,处理任务的线程
-
每个Task运行在Executor中
-
-
-
-
小结
-
Spark的架构是什么架构及架构中有哪些基本概念?
-
架构:分布式主从架构
-
Standalone集群
-
主:Master
-
从:Worker
-
-
Application
-
Driver进程:申请资源,Task解析、分配、监控
-
Executor进程:负责运行Task的进程
-
Executor进程运行在Worker节点上,这个进程使用的资源来资源Worker资源
-
-
Task:每个Task处理RDD的一个分区的数据,由1CoreCPU来实现
-
Task运行在Executor中
-
-
-
-
-
12:环境部署:本地模式环境
-
目标:实现Spark本地模式环境的部署
-
实施
-
导入虚拟机
-
参考附录一
-
-
配置本地模式
-
【以第一台机器为例】,第一台机器恢复到快照3
-
解压安装
tar -zxvf /export/software/spark-2.4.5-bin-cdh5.16.2-2.11.tgz -C /export/server/ ln -s /export/server/spark-2.4.5-bin-cdh5.16.2-2.11 /export/server/spark
-
bin:客户端脚本
-
sbin:服务端脚本
-
conf:配置文件
-
jars:放jar包的目录
-
-
-
修改配置
cd /export/server/spark/conf mv spark-env.sh.template spark-env.sh vim spark-env.sh#22行-23行 JAVA_HOME=/export/server/jdk SCALA_HOME=/export/server/scala #30行 HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
-
-
小结
-
实现Spark本地模式环境的部署
-
13:环境部署:本地模式测试
-
目标:实现本地模式的开发测试
-
实施
-
启动HDFS
hadoop-daemon.sh start namenode hadoop-daemon.sh start datanode -
上传测试文件
cd /export/server/spark hdfs dfs -mkdir -p /datas hdfs dfs -put wordcount.data /datas -
启动Spark-shell
bin/spark-shell --master local[2] -
观察Spark-shell日志
Setting default log level to "WARN". #设置日志级别为WARN To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). #更改日志级别 Spark context Web UI available at http://node1.itcast.cn:4040 #启动了一个监控页面:4040 Spark context available as 'sc' (master = local[2], app id = local-1625986999490). #SparkContext对象叫sc Spark session available as 'spark'. #SparkSession对象spark-
Spark为每个程序分配了一个监控页面:端口从4040开始
-
第一个程序的监控端口:4040
-
第二个程序的监控端口:4041
-
……
-
-
默认创建了一个SparkContext对象:sc
-
对象由Driver进程复责管理
-
所有Spark程序读取外部数据,解析、分配Task等操作都由SparkContext对象构建
-
每个Spark程序都需要一个SparkContext对象
-
-
SparkSession作用类似于SparkContext,用于在SparkSQL中代替SparkContext
-
-
测试WordCount
-
step1:读取数据
val inputRdd = sc.textFile("/datas/wordcount.data") -
step2:处理数据
val wcRdd = inputRdd.flatMap(line => line.trim.split("\\s+")) .map(word => (word,1)) .reduceByKey((tmp,item) => tmp+item)-
reduceByKey = groupBy + reduce
-
-
step3:保存结果
wcRdd.foreach(println) wcRdd.saveAsTextFile("/output/wc1")
-
问题1:有些代码会触发task的运行,有些代码不触发task运行?
-
RDD的转换代码:不会产生Task,Lazy模式的
-
操作使用了RDD的数据:才会产生Task,触发Task的运行
-
-
问题2:为什么有的stage是灰色的,不执行?
-

-
-
测试运行Jar包
SPARK_HOME=/export/server/spark ${SPARK_HOME}/bin/spark-submit \ --master local[2] \ --class org.apache.spark.examples.SparkPi \ ${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \ 1000
-
-
小结
-
实现本地模式的开发测试
-
14:环境部署:Standalone集群搭建
-
目标:实现Spark Standalone集群的搭建
-
实施
-
step1:架构及环境准备
-
架构:分布式主从架构
-
主:Master:第一台机器
-
从:Worker:三台机器
-
-
将三台机器恢复到《4、分布式环境》
-
第一台机器解压安装
tar -zxvf /export/software/spark-2.4.5-bin-cdh5.16.2-2.11.tgz -C /export/server/ ln -s /export/server/spark-2.4.5-bin-cdh5.16.2-2.11 /export/server/spark
-
-
step2:修改配置文件spark-env.sh
cd /export/server/spark/conf/ mv spark-env.sh.template spark-env.sh vim spark-env.sh #22行-23行 JAVA_HOME=/export/server/jdk SCALA_HOME=/export/server/scala #30行 HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop #60行 #指定Master启动的地址 SPARK_MASTER_HOST=node1 #指定Master的通信端口 SPARK_MASTER_PORT=7077 #Master的Web端口 SPARK_MASTER_WEBUI_PORT=8080 #指定每个Work能使用这台机器的多少核CPU SPARK_WORKER_CORES=1 #指定每个Work能使用这台机器的多少内存 SPARK_WORKER_MEMORY=1g #Work的端口 SPARK_WORKER_PORT=7078 #Work的web端口 SPARK_WORKER_WEBUI_PORT=8081 #配置Spark程序日志的记录位置 SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/spark/eventLogs/ -Dspark.history.fs.cleaner.enabled=true"-
MapReduce:JobHistoryServer:查看在YARN中运行过的MR的程序的信息
-
搭配YARN日志聚集
-
-
Spark:HistoryServer:查看在SparkStandalone集群中运行过的Spark程序
-
spark.history.fs.logDirectory:指定运行过的程序日志记录在HDFS什么位置
-
spark.history.fs.cleaner.enabled=true:开启日志的自动清理
-
-
-
step3:修改配置文件spark-defaults.conf
cd /export/server/spark/conf/ mv spark-defaults.conf.template spark-defaults.conf vim spark-defaults.conf #28行 #启用日志存储 spark.eventLog.enabled true #日志存储位置 spark.eventLog.dir hdfs://node1:8020/spark/eventLogs/ #启用压缩存储日志 spark.eventLog.compress true -
step4:修改配置文件slaves
cd /export/server/spark/conf/ mv slaves.template slaves vim slaves node1 node2 node3 -
step5:修改日志级别log4j
cd /export/server/spark/conf/ mv log4j.properties.template log4j.properties vim log4j.properties #修改19行 log4j.rootCategory=WARN, console -
step6:分发
-
所有节点配置免秘钥登录
ssh-copy-id node1 ssh-copy-id node2 ssh-copy-id node3 -
分发Spark
cd /export/server/ scp -r spark-2.4.5-bin-cdh5.16.2-2.11 node2:$PWD scp -r spark-2.4.5-bin-cdh5.16.2-2.11 node3:$PWD -
第二台和第三台创建软连接
ln -s /export/server/spark-2.4.5-bin-cdh5.16.2-2.11 /export/server/spark
-
-
-
小结
-
实现Spark Standalone集群的搭建
-
15:环境部署:Standalone集群测试
-
目标:实现Standalone分布式集群测试
-
路径
-
step1:集群启动与关闭
-
step2:集群计算测试
-
-
实施
-
集群启动与关闭
-
启动HDFS:第一台机器执行
start-dfs.sh hdfs dfs -mkdir -p /spark/eventLogs/ -
启动Master:第一台机器
/export/server/spark/sbin/start-master.sh
-
启动Worker:第一台机
/export/server/spark/sbin/start-slaves.sh
-
访问Spark Master WebUI
node1:8080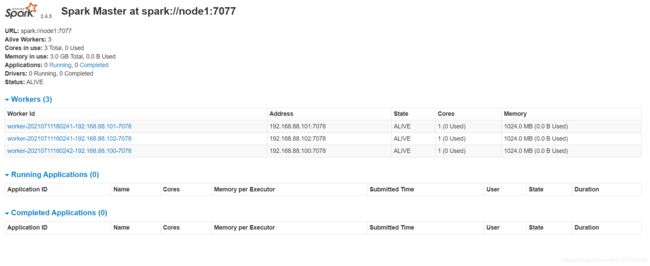
-
启动HistoryServer
/export/server/spark/sbin/start-history-server.sh -
访问Spark HistoryServer WebUI
node1:18080
-
-
集群计算测试
SPARK_HOME=/export/server/spark ${SPARK_HOME}/bin/spark-submit \ --master spark://node1:7077 \ --class org.apache.spark.examples.SparkPi \ ${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \ 100
-
-
小结
-
实现Standalone分布式集群测试
-
知识点16:环境部署:Standalone集群HA
-
目标:实现Spark Standalone集群的Master HA的搭建测试
-
实施
-
关闭所有Spark进程
/export/server/spark/sbin/stop-slaves.sh /export/server/spark/sbin/stop-master.sh /export/server/spark/sbin/stop-history-server.sh -
修改配置文件
cd /export/server/spark/conf/ vim spark-env.sh #注释60行 #SPARK_MASTER_HOST=node1 #添加68行 SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha" -
分发
cd /export/server/spark/conf scp -r spark-env.sh node2:$PWD scp -r spark-env.sh node3:$PWD -
启动ZK
zookeeper-daemons.sh start zookeeper-daemons.sh status -
启动Master
-
第一台
/export/server/spark/sbin/start-master.sh -
第二台
/export/server/spark/sbin/start-master.sh
-
-
启动Worker
/export/server/spark/sbin/start-slaves.sh -
测试
SPARK_HOME=/export/server/spark ${SPARK_HOME}/bin/spark-submit \ --master spark://node1:7077,node2:7077 \ --class org.apache.spark.examples.SparkPi \ ${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \ 100 -
测试完成,==修改配置文件,后面的学习不使用HA模式==
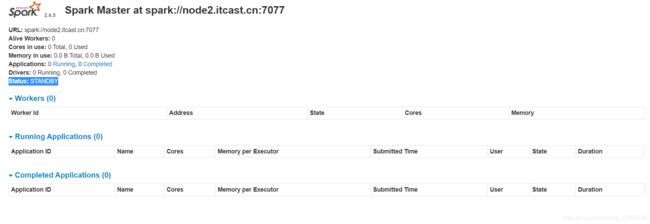
-
-
小结
-
实现Spark Standalone集群的Master HA的搭建测试
-
17:Spark程序:基本组成
-
目标:掌握Spark程序的基本组成
-
实施
-
架构组成
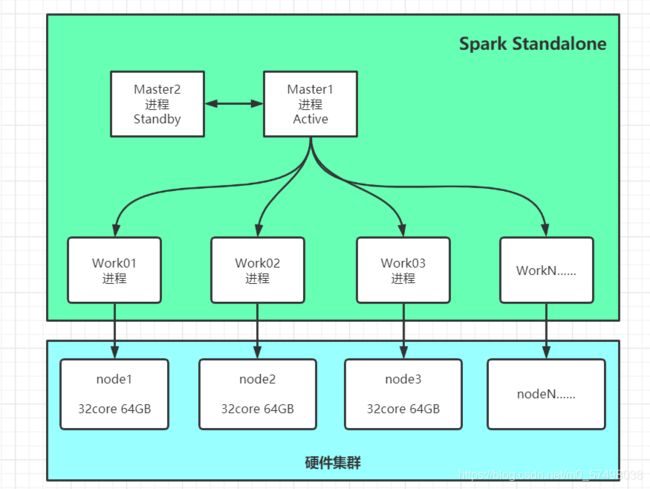
-
主从架构
-
主:Master:管理节点
-
接受客户端请求
-
管理从节点Worker节点
-
资源管理
-
-
从:Worker:计算节点
-
使用自己所在节点的资源运行Executor进程:给每个Executor分配一定的资源
-
假设
-
机器:32Core - 64GB
-
Worker:配置决定,16Core - 32GB
-
Executor:开发决定,2Core - 4GB
-
能并行启动8个Executor进程
-
-
-
-
-
-
程序组成
-
任何一个Spark程序都由两种进程构成
-
Driver进程
-
向主节点申请Executor资源,让主节点在从节点上根据需求配置启动对应的Executor
-
解析代码逻辑:将代码中的逻辑转换为Task
-
如果遇到RDD中的数据的使用:构建一个Job,触发Task的运行
-
-
将Task分配给Executor去运行
-
监控每个Executor运行的Task状态
-
-
Executor进程
-
运行在Worker上,使用Worker分配的资源等待运行Task
-
所有Executor启动成功以后会向Driver进行注册
-
Executor收到分配Task任务,运行Task
-
-
-
-
关系
-
Master负责管理所有Worker资源
-
Driver会向Master请求启动Executor
-
Worker上负责运行Executor进程
-
Driver负责解析、分配、监控所有Task线程在Executor中运行
-
-
-
小结
-
Master和Worker分别是什么?
-
Master:主节点
-
管理从节点
-
接受客户端请求
-
管理资源
-
-
Worker:从节点
-
运行Executor进程:分配资源给Executor
-
-
-
Driver和Executor分别是什么?
-
Driver:负责资源申请,Task的解析、调度、监控
-
Executor:运行Task
-
-
18:Spark程序:监控组件
-
目标:掌握Spark程序监控的使用
-
实施
-
Application:Spark的一个应用程序
-
每个Spark应用程序都会自带一个监控界面
-
端口从4040开始,如果被占用,不断+1
-
-
界面功能
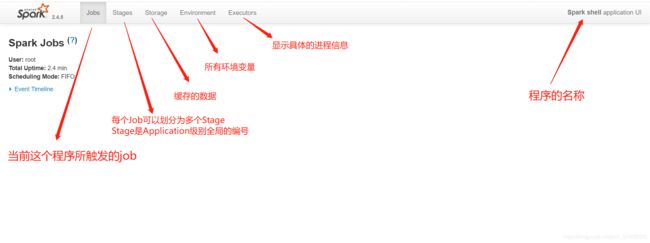
-
Job:当代码逻辑中出现了对RDD数据的使用时,触发job的构建
-
一个Application中可以有多个Job
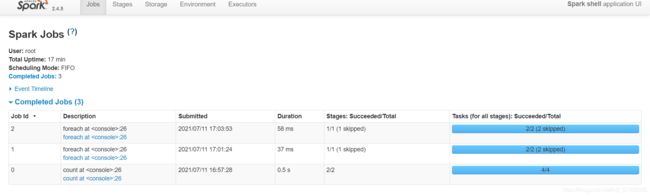
-
怎么将Job转为Task程序?
-
-
Stage:根据Job中使用RDD的依赖关系,通过回溯算法将一个job中的逻辑关系,构建Stage,得到DAG图
-
Stage的划分:按照是否产生shuffle,如果产生shuffle,就划分一个新的stage
-
执行每个Stage:从Stage编号最小的开始进行执行
-
将每个Stage转换为一个Task集合:Task集合中Task的个数由RDD的分区数据决定
-
-

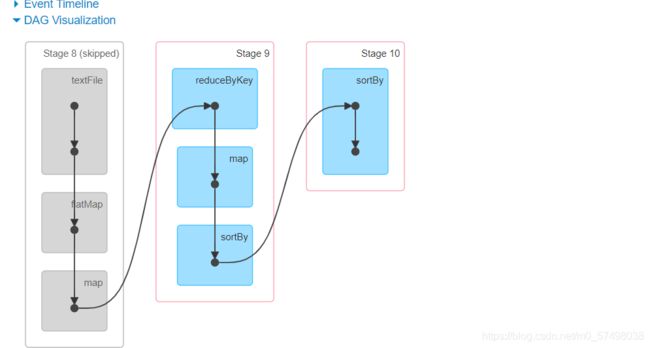
-
-
小结
-
掌握Spark程序监控的使用
-
附录一:导入Spark集群虚拟机
1、拷贝三台机器
2、导入三台机器

3、启动三台机器
-
==第二台、第三台启动会遇到这个报错,选择浏览==

-
==浏览中,选择第一台机器的vmx文件即可==
4、Windows配置映射
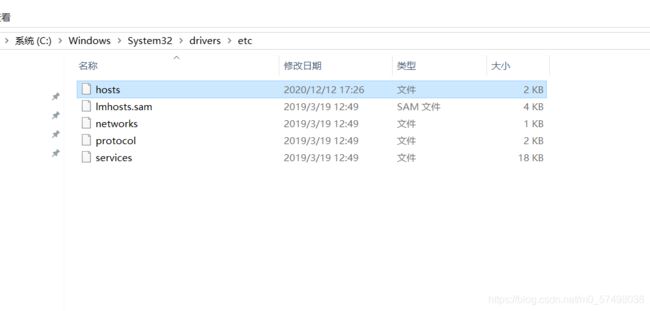
192.168.88.100 node1
192.168.88.101 node2
192.168.88.102 node3附录一:Spark Maven依赖
aliyun
http://maven.aliyun.com/nexus/content/groups/public/
cloudera
https://repository.cloudera.com/artifactory/cloudera-repos/
jboss
http://repository.jboss.com/nexus/content/groups/public
2.11.12
2.11
2.4.5
2.6.0-cdh5.16.2
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-core_${scala.binary.version}
${spark.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
target/classes
target/test-classes
${project.basedir}/src/main/resources
org.apache.maven.plugins
maven-compiler-plugin
3.0
1.8
1.8
UTF-8
net.alchim31.maven
scala-maven-plugin
3.2.0
compile
testCompile