手把手教你用Centos7安装完全分布式Hadoop3.2.1
在mac的parallels desktop虚拟机软件里下载了三个centos7系统的虚拟机,用来搭建hadoop完全分布式集群,具体信息如下:
| IP地址 |
主机名 |
操作系统 |
角色 |
| 10.211.55.15/24 |
master |
Centos7 |
master(namenode1) |
| 10.211.55.12/24 |
slave1 |
Centos7 |
slave1(datanode1) |
| 10.211.55.14/24 |
slave2 |
Centos7 |
slave1(datanode1) |
搭建步骤如下:
一、设置ssh免密码登录
1、修改本地主机名hostname和主机名ip地址映射,方便辨认(输入hostname可查看主机名):
sudo vi /etc/hostname #把内容修改为想要命名的主机名
sudo vi /etc/hosts #修改ip与主机名映射
在hosts文件中添加如下内容(按照上述的配置信息填写):
10.211.55.15 master
10.211.55.12 slave1
10.211.55.14 slave2

(注意:127.0.0.1后面的主机名映射不要添加和新增加的映射同名的主机名,否则会使hdfs的data文件夹下没有东西)
2、确认ssh服务已经安装并打开:
3、打开文件sudo vi /etc/ssh/sshd_config
把以下选项的“#”去掉,“yes”改为“no”
#PermitRootLogin yes
#PasswordAuthentication yes
#UsePAM yes
把以下选项的“#”去掉
#AuthorizedKeysFile .ssh/authorized_keys
#PubkeyAuthentication yes
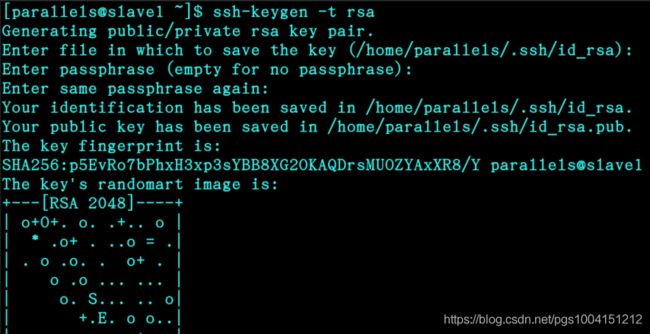
4、输入ssh-keygen -t rsa,然后一路回车,顺利生成秘钥文件:
5、将本主机自己的公钥放入文件authorized_keys中(这里如果没有authorized_keys文件会在下面的命令中自动创建):
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

6、调整文件夹和文件的权限:
先调整文件夹~/.ssh的权限:chmod 700 ~/.ssh
再调整文件~/.ssh/authorized_keys的权限:chmod 644 ~/.ssh/authorized_keys
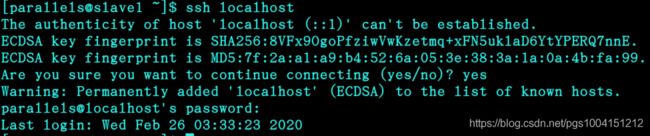
免密码登录:ssh localhost
注意:到这里本机的免密码登录已经完成。如果出现关闭终端后重新登录还需要密码的情况,可以尝试执行以下两条命令,再登录:
ssh-agent -s
ssh-add
二、设置多结点ssh免密码登录
由于这里是用虚拟机模拟多结点环境,用以下命令把各个主机的rsa公钥信息复制到别的机子的authorized_keys文件中:
ssh 其他结点用户名@其他结点主机名 cat /home/其他结点用户名/.ssh/id_rsa.pub >> /home/本地结点用户名/.ssh/authorized_keys

三、下载和配置Hadoop
1、官网下载hadoop-3.2.1.tar.gz版本 https://www.apache.org/dyn/closer.cgi/hadoop/common
2、下载完成后默认保存在当前用户目录下的Downloads文件夹下,将下载好的 hadoop-3.2.1.tar.gz 解压至安装目录 /usr/local:
sudo tar zxvf hadoop-3.2.1.tar.gz -C /usr/local/
(备注:centos7自带的jdk1.8.0不太完整,在配置JAVA_HOME等相关环境变量之前,需要用sudo yum install java-devel 命令来更新它,否则执行javac命令就会报错)
3、编辑 /etc/profile 配置文件,增加相关环境变量:sudo vi /etc/profile
在profile文件里添加或修改以下内容:
export HADOOP_HOME=/usr/local/hadoop-3.2.1
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
PATH=$PATH:$HOME/.local/bin:$HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$JRE_HOME/bin
(注意:centos7下JAVA_HOME环境变量配置细节参考https://www.cnblogs.com/lenmom/p/9494877.html)
使修改后的环境变量生效:source /etc/profile
4、这里可以使用如下命令把环境变量配置文件传输给另外的结点,不用反复配置。如:
sudo scp /etc/profile 另一个主机账户名@另一个主机名:/etc/profile
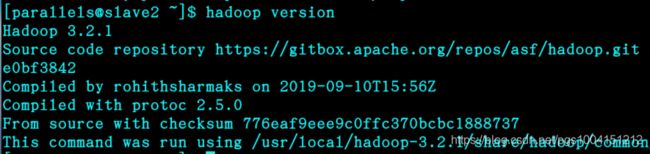
5、输入hadoop version命令看前面步骤是否成功:
6、关闭各个结点的防火墙:
systemctl status firewalld.service #查看防火墙状态
systemctl stop firewalld.service #关闭防火墙
systemctl disable firewalld.service #永久禁用防火墙服务
7、更改各个结点 /usr/local 的所有者:
sudo chown 当前账户名:当前账户名 -R /usr/local
8、namenode结点配置文件:
1)执行 sudo vi /usr/local/hadoop-3.2.1/etc/hadoop/hadoop-env.sh
在该文件里加入JAVA_HOME环境变量:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64
2)执行 sudo vi /usr/local/hadoop-3.2.1/etc/hadoop/core-site.xml
在
3)执行sudo vi /usr/local/hadoop-3.2.1/etc/hadoop/hdfs-site.xml
在
4)执行 sudo vi /usr/local/hadoop-3.2.1/etc/hadoop/mapred-site.xml
在
5)执行 sudo vi /usr/local/hadoop-3.2.1/etc/hadoop/yarn-site.xml
在
6)执行 sudo vi /usr/local/hadoop-3.2.1/etc/hadoop/workers
把里面内容修改为:
slave1
slave2
9、在namenode结点新建配置里提到的文件夹:
sudo mkdir -p /home/账户名/hadoop-3.2.1/tmp
sudo mkdir -p /usr/local/hadoop-3.2.1/hdfs/name
sudo mkdir -p /usr/local/hadoop-3.2.1/hdfs/data
10、配置slave结点:
把master结点已经配置好的/usr/local/hadoop-3.2.1文件夹复制一份到各个slave结点下就行了:
sudo scp -r /usr/local/hadoop-3.2.1 另一台结点帐户名@另一台结点主机名:/usr/local
11、启动集群
1)格式化HDFS文件系统(注意:只需要在第一次安装的时候格式化!),首先修改权限,否则格式化会报错:
sudo su #进入超级管理员账户
sudo chmod -R a+w /usr/local/hadoop-3.2.1 #修改权限,注意自己的安装路径!
exit #回到用户身份
cd /usr/local/hadoop-3.2.1/bin
hadoop namenode -format #格式化HDFS文件系统

2)启动namenode结点:
cd /usr/local/hadoop-3.2.1/sbin
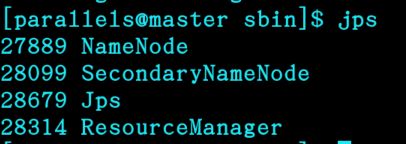
start-all.sh #启动namenode结点
jps #查看namenode已启动进程
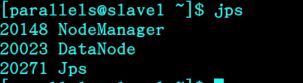
3)在slave结点输入:
jps
可以看到,namenode执行start-all.sh命令时,已经把slave相应的进程启动了!
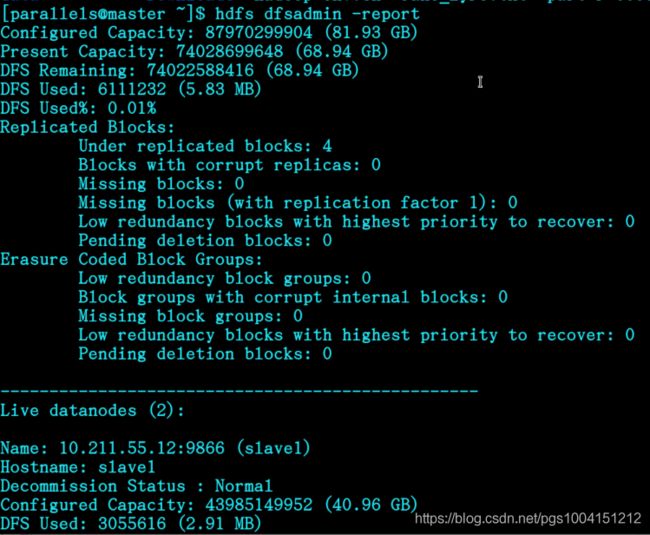
4)查看Hadoop集群状态:
hdfs dfsadmin -report
可以看到有多少个活跃的结点,如果数量对了,说明配置成功。
5)在namenode结点浏览器分别打开localhost:8088和localhost:9870,可以分别看到如下界面:
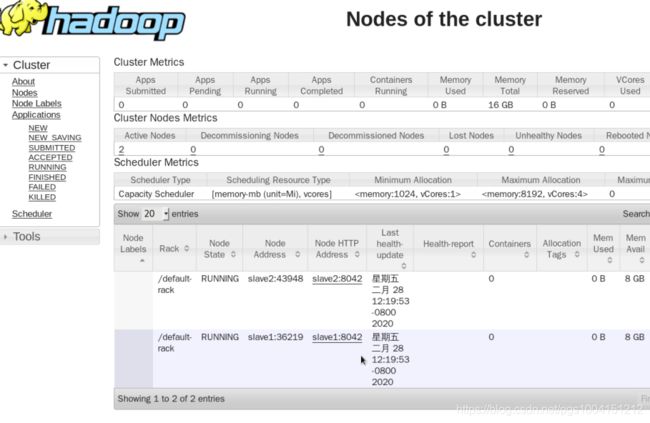
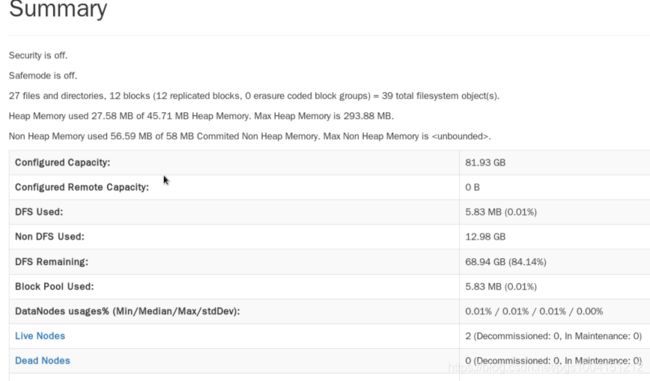
congratulation!基于centos的完全分布式Hadoop已经搭建完毕啦~