Kafka+采集用户信息行为+flume整合(鼠标停留时间)
Kafka+采集用户信息行为+flume(鼠标停留时间)
一、Kafka概述
与消息系统类似,是消息中间件的一种。能够订阅和发布流式数据,能够以容错的方式存储流式数据,当数据产生时就能够处理

生产者:数据产生者
消费者:数据使用者
中间件:进行数据缓冲
采集用户信息行为:
用户信息采集:页面上两个按钮、三个模块,当点击按钮的时候会显示点击那个按钮的日志,当鼠标滑过的时候显示鼠标在某个区域停留的时间
Log4j的代码如下:
| # 全局配置 -> DEBUG(调试) -> INFO(信息) ->ERROR(错误)
|
Jsp页面的代码如下:
| <%@ page contentType="text/html;charset=UTF-8" language="java" %> 引入jar包
|
Serverlet的代码如下:
| import org.apache.log4j.Logger;
|
kafka解决的问题
供求平衡
供大于求
数据产生快 - 使用较慢(数据计算) -> 多生产的数据如何存储/高效的对数据进行消费
供不应求 - 合理确定生产消费模式([推送]/拉取)产生一些数据就推送一些数据
Kafka容错性 - 多副本机制(leader) -> 进程异常终止会推选出新的leader -> 保证正常工作
容错性指的是多副本一个挂掉启用另外一个
Kafka就相当于篮子
二、部署和使用
前置环境:zookeeper
tar -zvxf zookeeper-3.4.12.tar.gz
vi ~/.bash_profile
export ZK_HOME=/home/bigdata/zookeeper-3.4.12
export PATH=$PATH:$ZK_HOME/bin
source ~/.bash_profile
cd $ZK_HOME/conf
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
dataDir=/home/bigdata/zookeeper
zkServer.sh start
kafka安装
tar -zvxf kafka_2.10-0.10.2.2.tgz
mv kafka_2.10-0.10.2.2 kafka-0.10.2.2
vi ~/.bash_profile
export KAFKA_HOME=/home/bigdata/kafka-0.10.2.2
PATH=$PATH:$KAFKA_HOME/bin
source ~/.bash_profile
mkdir ~/kafka //存放kafka的缓存日志
核心配置(server.properties)
# 不重复的整数,每个broker监听一个端口
broker.id
# 是否开启topic的删除
delete.topic.enble
# kafka日志文件:逗号分隔多个路径
log.dirs
# 分区数量
num.partitions
# zookeeper的地址
zookeeper.connect
1. 单节点单Broker
server-0.properties配置
mv $KAFKA_HOME/config/server.properties $KAFKA_HOME/config/server-0.properties
vi $KAFKA_HOME/conf/server-0.properties
broker.id=0 //每个broker监听一个端口,将数据保存log中
delete.topic.enble=ture
listeners=PLAINTEXT://SZ01:9092
log.dirs=/home/bigdata/kafka/logs-0
num.partitions=1
zookeeper.connect=SZ01:2181
启动kafka
kafka-server-start.sh -daemon $KAFKA_HOME/config/server-0.properties
2. 单节点多Broker
在单节点的server.properties配置基础上进行修改
cp $KAFKA_HOME/config/server-0.properties $KAFKA_HOME/config/server-1.properties
cp $KAFKA_HOME/config/server-0.properties $KAFKA_HOME/config/server-2.properties
cp $KAFKA_HOME/config/server-0.properties $KAFKA_HOME/config/server-3.properties
server-1.properties
broker.id=1
listeners=PLAINTEXT://SZ01:9093
log.dirs=/home/bigdata/kafka/logs-1
num.partitions=1
zookeeper.connect=SZ01:2181
server-2.properties
broker.id=2
listeners=PLAINTEXT://SZ01:9094
log.dirs=/home/bigdata/kafka/logs-2
num.partitions=1
zookeeper.connect=SZ01:2181
server-3.properties
broker.id=3
listeners=PLAINTEXT://SZ01:9095
log.dirs=/home/bigdata/kafka/logs-3
num.partitions=1
zookeeper.connect=SZ01:2181
启动kafka
kafka-server-start.sh -daemon $KAFKA_HOME/config/server-1.properties
kafka-server-start.sh -daemon $KAFKA_HOME/config/server-2.properties
kafka-server-start.sh -daemon $KAFKA_HOME/config/server-3.properties
停止Kafka
kafka-server-stop.sh
# 失效时使用如下脚本
kill -s TERM $(jps -l | grep 'kafka\.Kafka' | awk '{print $1}')
三、Kafka的使用
1. Topic操作
使用kafka-topics.sh
使用--zookeeper指定zookeeper地址
使用--replication-factor指定副本个数
使用--partitions指定分区数
使用--topic指定名称
使用--list显示Topic列表
(1)创建Topic
单broker
理清topic创建的概念
Broker------相当于篮子
topic -> 多个副本(小于等于broker) -> 多个分区
每一个篮子可以装一个副本,每个副本分几个区
Partitions必须小于factor
删除Topic
1.配置文件中开启delete.topic.enble = true
2.通过命令执行删除操作 -> marked
kafka-topics.sh --delete --zookeeper hh:2181 --topic first_topic
3.停止Kafka进程
4.log.dir中的文件夹清空
5.启动Kafka进程
kafka-topics.sh --create --zookeeper hh:2181 --replication-factor 1 --partitions 1 --topic first_topic
多broker
kafka-topics.sh --create --zookeeper hh:2181 --replication-factor 3 --partitions 1 --topic myTopic
(2)查看Topic列表
kafka-topics.sh --list --zookeeper SZ01:2181
(3)删除Topic
kafka-topics.sh --delete --zookeeper SZ01:2181 --topic first_topic
# 标记删除后,删除对应目录下文件,重启kafka
(4)查看Topic描述
kafka-topics.sh --describe --zookeeper SZ01:2181 [--topic first_topic]
2. 消息测试
使用kafka-console-producer.sh生产消息
使用--broker-list指定broker列表
使用kafka-console-consumer.sh消费消息
使用--bootstrap-server指定需要连接的服务
使用--from-beginning指定从开始位置开始消费
(1)生产消息
单broker
kafka-console-producer.sh --broker-list hh:9092 --topic first_topic
hello kafka
多broker
kafka-console-producer.sh --broker-list SZ01:9093,SZ01:9094,SZ01:9095 --topic myTopic
hello kafka
(2)消费消息
单broker
kafka-console-consumer.sh --bootstrap-server hh:9092 --topic first_topic [--from-beginning]
多broker
kafka-console-consumer.sh --zookeeper hh:2181 --topic myTopic [--from-beginning]
3. 容错性
当topic下存在多个broker时,会选举出一个leader,当其他节点出现故障时,不影响使用。当leader出现故障时,如果当前topic下还有其他节点,会重新选举出leader,保证使用
以上使用的是脚本的方式进行测试,现在要做的是使用程序进行监控
四、Kafka的API编程
1. 开发环境
新建Scala项目
使用sbt构建
添加依赖
scalaVersion := "2.10.7"
libraryDependencies += "org.apache.kafka" % "kafka-clients" % "0.10.2.2"
2. 配置文件
在scala下新建两个配置文件
kafkaConsumer.properties
kafkaProducer.properties
Producer配置项
# 连接列表(数据存放主机)
bootstrap.servers=hh:9092
# 配置请求完成标准
acks=all
# 设置重试次数
retries=0
# 缓冲区大小(字节)
batch.size=16384
# 生产者发送消息时的等待时间(毫秒)
linger.ms=1
# 缓冲内存大小(字节)
buffer.memory=33554432
# key的序列化方式
key.serializer=org.apache.kafka.common.serialization.IntegerSerializer
# value的序列化方式
value.serializer=org.apache.kafka.common.serialization.StringSerializer
r
Consumer配置项
# 连接列表
bootstrap.servers=hh:9092
# 使用者所属组(唯一)
group.id=test
# 自动提交偏移量
enable.auto.commit=true
# 提交偏移量频率(毫秒)
auto.commit.interval.ms=1000
# key的反序列化方式
key.deserializer=org.apache.kafka.common.serialization.IntegerDeserializer
# value的反序列化方式
value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
工具类:(向程序中加载配置项的作用)
src\main\scala\com\qfedu\kakfa\util
| import java.io.IOException;
|
3.\main\scala\com\qfedu\kafka建立生产者消费者
生产者
import com.qfedu.util.PropertiesUtil
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
// 继承Thread
class KafkaMsgProducer extends Thread {
// 使用工具类读取配置
val properties = new PropertiesUtil("kafkaProducer.properties").getProperties()
// 初始化KafkaProducer
val producer = new KafkaProducer[Int, String](properties)
// 重写run方法
override def run() = {
for (i <- 0 until 100){
producer.send(new ProducerRecord[Int, String]("first_topic", i, s"msg:$i"))
Thread.sleep(1000)
}
// 释放资源
producer.close
}
}
|
import com.qfedu.kakfa.util.PropertiesUtil
|
首先linux端启动消费者(前提kafka进程启动,topic已经建立)
kafka-console-consumer.sh --bootstrap-server hh:9092 --topic first_topic
启动程序上面
4. Consumer API
实际操作的代码
| import java.util
启动程序:
启动生产者:(前提如上) kafka-console-producer.sh --broker-list hh:9092 --topic first_topic |
flume与kafka的整合:
实现过程:
WebServer - Flume
Source : exec
channel : memory
sink : avro
DataServer - Flume
Source : avro
channel : memory
sink : Kafka
Flum监听web的日志放到data.log文件夹----flum读取到avro-----再次从avro中读取到first_topic
第一步:打包如上的web(鼠标滑动的)程序存放到linux的tomcat的 webapps
文件夹下------改名为ROOT.war
第二步配置flume的启动配置文件
WebServer端的配置文件example-file.conf
| mple.conf: A single-node Flume configuration
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1
# Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -f /home/hadoop/data.log # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname =hh a1.sinks.k1.port = 8888
# Use a channel which buffers events in memory a1.channels.c1.type = memory
# Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 |
DataServer端的flume的配置文件example-fileAvro.confkafka.conf
| mple.conf: A single-node Flume configuration
# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1
# Describe/configure the source a2.sources.r1.type = avro a2.sources.r1.bind = hh a2.sources.r1.port = 8888
# Describe the sink a2.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a2.sinks.k1.kafka.bootstrap.servers = hh:9092 a2.sinks.k1.kafka.topic = first_topic
# Use a channel which buffers events in memory a2.channels.c1.type = memory
# Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1 |
第三步启动tomcat
./startup.sh
第四步:启动两个flume
启动一个fileflum
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/example-file.conf &
flume-ng agent \
--name a2 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/example-fileAvro.confkafka.conf &
第五步启动kafka进程
kafka-server-start.sh -daemon $KAFKA_HOME/config/server-0.properties
开一个topic
kafka-topics.sh --create --zookeeper hh:2181 --replication-factor 1 --partitions 1 --topic first_topic
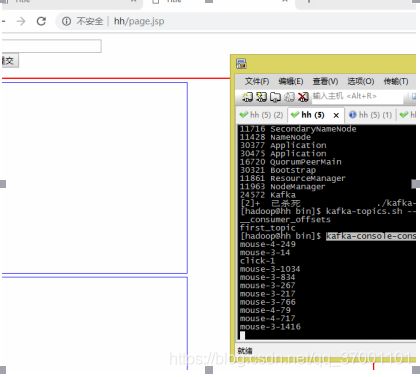
第六步开启一个消费者
查看topic
kafka-topics.sh --list --zookeeper hh:2181
__consumer_offsets
first_topic
开启消费者
kafka-console-consumer.sh --bootstrap-server hh:9092 --topic first_topic
第七步:测试:
时间段数据的统计:
Web阶段经过flum,再经过kafka 再kafka里面监听两个消费者一个是属于鼠标滑过求一个时间段内,在每个区域的总时间
另一个是监听一段时间内点击的数量
在Scala的项目中添加如下程序
main\scala\com\qfedu\kafka\consumer\MouseConsumer.scala
| package com.qfedu.kafka.consumer
|
main\scala\com\qfedu\kafka\consumer\ClickConsumer.scala
| package com.qfedu.kafka.consumer
|
在前一个例子都启动的前提下,在IDEA中启动这两个程序
不断的做点击按钮以及鼠标滑过的操作
等待2分钟后出现如下结果:
key:5,value:4522
key:4,value:7443
key:3,value:11462
key:2,value:11
key:1,value:13
提取数据 -> 两个消费者(click/mouse) -> 计算出最多的被浏览商品/被点击商品(2 * 60 * 1000)
15号当日的数据 -> 10 - 14日之间的所有的统计结果 -> 保存策略 -> 更新频率
数据采集(Flume-Kafka) -> 数据分析(数据接收 - 计算 - 历史结果合并 - 历史结果存放)
计算频率 - 1秒
最新结果 - 10秒