数据仓库知识点总结(数仓分层建模、维度建模等)
数据仓库知识点总结
- 推荐学习《华为数据之道》《数据仓库工具箱-维度建模权威指南》两本书。
- 此文档是数据仓库建模的知识点总结文档,在持续更新中(2021-10-13)。
文章目录
- 数据仓库知识点总结
-
- 1.数据仓库分层理论
-
- 1.1数仓分层架构的好处
- 1.2 数据仓库核心分层
- 2.数据仓库建模方法论
-
- 2.1 ER模型
- 2.2 维度模型
- 2.3 Data Vault模型
- 2.4 Anchor 模型
- 3.维度建模方法论
-
- 3.1模型层次(数仓的分层理论)
- 3.2 模型实施过程
- 3.2 维度设计
- 3.3 事实表设计
- 4 数仓模型
-
- 4.1 数仓模型需要关注以下5点:
- 4.2 缓慢变化维与拉链表
- 4.3 星型模型与雪花模型
- 4.4.数据中台总体设计方案
- 5.数据治理
-
-
- 5.1 数据模型
- 5.2 数据质量
- 5.3 数据治理
-
- 5.3.1 数据治理之元数据管理
- 5.3.2 数据治理之数据质量管理
- 5.3.3 数据治理之数据标准管理
- 5.3.4 数据治理之数据资产管理
-
- 6 数据湖与数据中台的区别
- 7.维度建模
-
- 7.3 零售业务
-
- 7.3.1 维度模型设计的四步过程
- 7.3.2 事实表粒度
- 7.4 库存
-
- 7.4.1 半可加事实
- 7.4.2 事实表类型
- 7.4.3 一致性维度与事实
- 7.4.5 构建总线矩阵
- 7.5 采购
-
- 7.5.1 单一事务事实表与多事务事实表
- 7.5.2 缓慢变化维基础
- 7.6 订单管理
- 7.7 会计
-
- 7.7.1
- 7.7.2
- 8.范式建模
- 9.SQL案例
-
- 9.1 求用户的最大连续登陆天数
- 9.2 统计每个用户的累计访问次数
- 9.3 分组TopN
- 9.4 分组求TOP%N
- 9.5 求落在某一个区域的概率
- 9.6 行转列
- 9.7 列转行
- 10 其他的知识点
-
- 10.1 Hive 不支持记录级别的增删改,如何用Hive实现缓慢变化维。
- 10.2 暂无
- 10.3 代理键
- 10.4.数据分区与数据倾斜?
- 10.5 物化视图
1.数据仓库分层理论
1.1数仓分层架构的好处
- 1.清晰的数据结构:
每一个数据分层都有对应的作用域,在使用数据的时候能更方便的定位和理解(易定位与理解)
- 2.数据血缘追踪
当提供给业务系统或下游系统的数据服务中的数据异常时,清晰的血缘关系可以快速的定位问题所在,血缘管理也是元数据管理重要的部分。数据血缘关系管理
- 3.减少重复开发
遵循数据加工原则,下层包含了上层数据加工所需要的全量数据,避免重复造轮子
- 4.数据关系条理化
源系统之间存在着复杂的数据关系,例如当客户信息同时存在于多个系统时,数仓会把相同主题的数据进行统一建模,从而将复杂的数据关系变为清晰的数据模型。或者采用主数据管理系统对客户信息进行统一管理,抽象为一致性客户维度数据一致性
- 5.屏蔽原始数据影响
数据逐层加工原则,使得原始数据离应用层还有多层的数据加工,原始数据出问题,因为存在多个层级,也可以保持应用层的稳定性。
1.2 数据仓库核心分层
数仓分层方式,各有不同,但可以提炼出一下共性:
-
1)源系统归集到数仓的缓冲层,或为贴源层
-
2)具备数据标准化及合并全量数据的标准层
-
3)具备主题划分及明细数据整合的主题层
-
4)具备提供数据服务给下游系统使用的集市层,或称为应用层
数据仓库的核心分层为ODM贴源层、SDM标准层、FDM主题层、ADM应用层
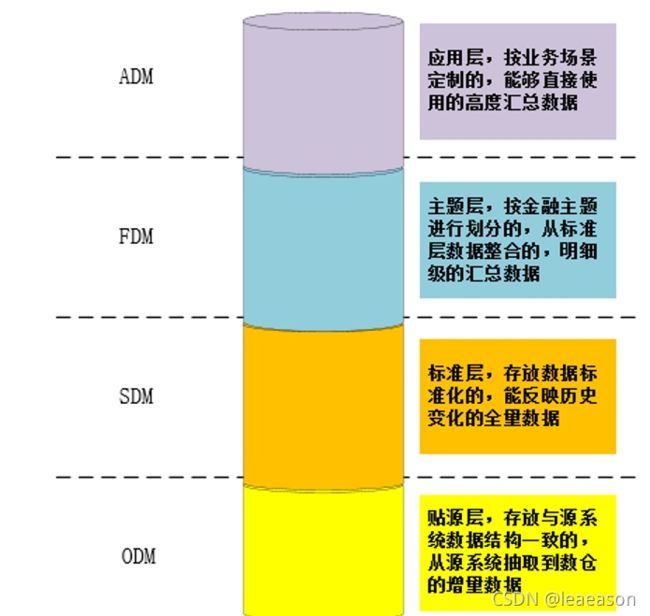
ODM
如何在ODM层保证数据正常入库:
-
1)数据入库的全流程校验机制(重要)
进行数据抽取时,将落地的文本数据与源系统抽取记录数进行比对,即可完成数据抽取的完整性校验。数据入库时,把入库的记录数与文本数据的记录进行匹配,既可完成数据入库的完整性校验。
-
2)使用元数据管理工具
定时同步源系统的数据结构到数仓进行比对,当发现差异及时预警。
-
3)处理好映射关系
将输入抽取及数据入库的处理流程固化,未来源系统出现新增活着吧变更需求时。处理好映射关系,无需重复开发处理流程。
-
4)建设预警机制
短信预警通知
-
数仓设计
-
数据资产
-
数据质量
-
指标系统
-
数据地图
2.数据仓库建模方法论
2.1 ER模型
数据仓库之父Bill lnmon提出,在范式理论上符合3NF。具有以下几个特点:
- 全面了解企业业务和数据
- 实施周期非常长
- 对建模人员能力要求非常高
2.2 维度模型
由Ralph Kimball提出,他的书:《数据仓库工具箱》是数据仓库建模的经典书籍 。维度建模从分析决策的需求出发构建模型,为分析需求服务。主要分为以下步骤:
- 选择业务过程
- 选择粒度,预判需要细分的程度
- 确定维度,选择好粒度之后,需要基于此粒度设计维表,包括维度属性,用于分析时进行分组和筛选
- 选择事实,确定分析需要衡量的指标
2.3 Data Vault模型
待补充
2.4 Anchor 模型
待补充
3.维度建模方法论
在不成熟、快速变化的业务面前,构建ER模型的风险非常大,不太适合去构建ER模型。所以在数据仓库的建设过程中,建议以Kimball的维度建模为核心理念去建设。
数据模型的维度设计主要以维度建模理论为基础,基于维度数据模型总线架构,构建一致性的维度和事实
3.1模型层次(数仓的分层理论)
数仓主要分为三层
-
操作数据层(ODS)
将操作系统数据几乎无处理地存放在数据仓库系统中
-
公共维度模型层(CDM)
明细数据层:DWD
汇总数据层:DWS,
采用维度退化,将维度退化到事实表中,减少事实表和维表的关联,提高明细数据表的易用性;同时在汇总数据层,加强指标的维度退化,采用更多的宽表化手段构建公共指标数据层,提升公共指标的复用性,减少重复加工
-
应用数据层(ADS)
3.2 模型实施过程
构建维度模型的四个阶段
- 高层模型设计
- 详细模型设计
- 模型审查、再设计和验证
- 详细设计文档,ETL设计和开发
3.2 维度设计
度量称为**“事实”,将环境描述为“维度”**。维度的作用一般是查询约束、分类汇总以及排序
作为维度建模的核心,在企业级数仓中必须保证维度的一致性
维度的基本设计方法:
- Step1:选择维度或者新建维度,
- Step2:确定主维表
- Step3:确定相关维表、
- Step4:确定维度属性
对于维度表的属性具有层次结构的情况,一般有两种处理方式:
规范化与反规范化:
-
规范化:
雪花模型,采用雪花模型,除了可以节约一部分存储空间外,对于OLAP系统来说,没有其他效用。出于易用性和性能的考虑,维度一般不做规范化处理。用空间换时间。
-
反规范化:
将维度的属性层次合并到单个维度中的操作称为反规范化,例如:星型模型
OLAP系统的主要目的是如何方便用户进行统计分析,若采用雪花模型,则用户在统计分析过程中需要大量的关联操作,使用复杂度高,同时查询性能也很差,这时候就需要采用反规范化处理,方便易用。
依据维度设计的原则,尽可能丰富维度属性,同时进行反规范化处理。
维度表的水平整合与垂直整合
既然有了整合也会有拆分
维度表的水平拆分与垂直拆分
- 依据维度的不同分类的属性差异情况
- 依据业务关联程度,关联性较低的维度没有必要放在一起
缓慢变化维应对维度的变化
在Kimball维度建模理论中,必须使用代理键作为每个维度表的主键,用于处理缓慢变化维。
- 但是在分布式计算系统里,不存在事务概念,对于每个表的记录生成稳定的全局唯一的代理键难度很大。
- 使用代理键会大大增加ETL的复杂性,对ETL任务的开发和维护成本很高
不使用代理键如何处理缓慢变化维的问题呢?
可以采用快照的方式,每天保留一份全量快照数据。按日做分区。
优点:
- 简单,有效,开发维护成本低
- 使用方便,理解性好
缺点:
- 存储极大的浪费,需要有对应的数据生命周期制度,清楚无用的历史数据
微型维度
枚举值
维度的层次
-
均衡层次结构
层次固定,例如地理信息
-
非均衡层次结构
层次不固定
层次结构扁平化
层次桥接表
不建议使用桥接表,很多时候,简单。直接的技术方案往往是最好的解决方案
行为维度
多值维度
多值属性:属性字段值/多表/联合主键
杂项维度
3.3 事实表设计
度量:
-
可加
与事实表关联的任意维度都可以进行汇总
-
半可加
只能按照部分维度汇总,不能对所有维度汇总。例如,库存可以按照商品和地点进行汇总,但是不能按照时间维度汇总
-
不可加
度量完全不具备可加性。例如比率型事实
事实表类型:
-
事务事实表
也称为原子事实表,用来描述业务过程
-
周期快照事实表
以时间间隔来记录事实,例如每天,每月,每年等
-
累积快照事实表
表示过程开始和结束之间的关键时间点,随着生命周期的不断变化,记录也会随着过程的变化而被修改。
事实表设计原则
- 1.将不可加的事实分解,例如订单的优惠率,可以分解为订单原价金额和订单优惠金额两个事实
- 2.在选择维度和事实之前必须声明粒度
- 3.在同一个事实表中的粒度必须相同
- 4.事实的单位要一致
- 5.对事实的NULL值要处理
- 6.使用退化维度提高事实的易用性
事实表设计方法
-
选择业务过程及确定事实表类型
-
声明粒度
最细粒度
-
确定维度
-
确定事实
-
冗余维度
在淘宝订单付款事务事实表中,通常会冗余大量维度字段,以及商品类目,卖家店铺信息等维度信息
单事务事实表,即针对每个业务过程设计一个事实表
多事务事实表,将不同的事实放入到同一个事实中,即同一个事实表包含不同的业务过程。
聚集型事实表
- 一致性
- 避免单一表设计
- 聚集粒度可不同
4 数仓模型
4.1 数仓模型需要关注以下5点:
- One Data:
数仓所有的数据只加工一次。对于维度:要保证维度一致性;对于明细层数据:保证相同粒度的度量只加工一次;对于汇总层的数据:相同粒度的指标只存一份,避免重复建设。
- OneIndex:
数仓指标具有唯一性,通过原子指标+派生指标来规范所有的指标系统,避免数据不一致的问题。
- OneService:
数据服务划清了数据和应用的边界,应用通过数据服务,直接获取计算结果,强制把公共计算逻辑下沉到数据层面,提高数据共享能力,避免通过不同层次获取数据导致的数据准确性和安全性问题。
- OneLine
最大程度保障数据流转的透明性,不同层级做不同层级的数据处理逻辑,不可逆向依赖,方便后续数据血缘关系、数据地图建立,避免数据杂乱,无法溯源。
- OneEntity
主要是模型方面的建设,同一个用户,在同一个模型中,可能存在重复的记录,如何识别两个ID是同一个用户,做到所有用户只有唯一的ID标识。
4.2 缓慢变化维与拉链表
说到缓慢变化维,就需要说明一下什么是维度。维度与事实是在Kimball《维度建模权威指南》里定义的,维度指的是上下文,而事实指的是度量。请见下图:
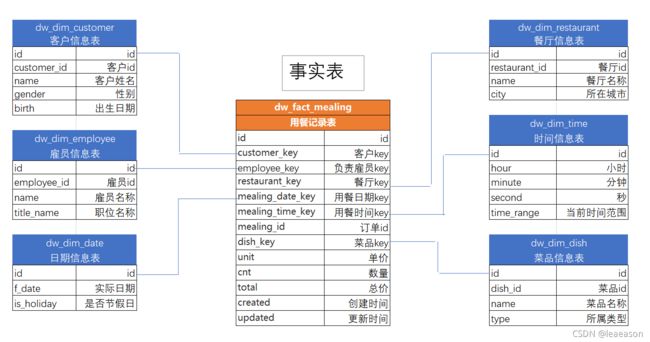
而拉链表则是针对数据仓库中表存储数据的方式而定义的,目的是为了记录历史数据的每个状态,记录一个事务从开始,一直到当前状态的所有变化信息。
因此,两者不能混为一谈。
拉链表的使用场景
- 1.数据量比较大
- 2.表中的部分字段会被更新
- 3.需要查看某一个时间点或时间段的历史快照信息,查看某一个订单在历史某一个时间节点的状态
例子:
有一张订单表,6月20号有3条记录:
| 订单创建日期 | 订单编号 | 订单状态 |
|---|---|---|
| 2012-06-20 | 001 | 创建订单 |
| 2012-06-20 | 002 | 创建订单 |
| 2012-06-20 | 003 | 支付完成 |
到6月21号,表中有5条记录:
| 订单创建日期 | 订单编号 | 订单状态 |
|---|---|---|
| 2012-06-20 | 001 | 支付完成(从创建到支付) |
| 2012-06-20 | 002 | 创建订单 |
| 2012-06-20 | 003 | 支付完成 |
| 2012-06-21 | 004 | 创建订单 |
| 2012-06-21 | 005 | 创建订单 |
到6月22号,表中有6条记录:
| 订单创建日期 | 订单编号 | 订单状态 |
|---|---|---|
| 2012-06-20 | 001 | 支付完成(从创建到支付) |
| 2012-06-20 | 002 | 创建订单 |
| 2012-06-20 | 003 | 已发货(从支付到发货) |
| 2012-06-21 | 004 | 创建订单 |
| 2012-06-21 | 005 | 支付完成(从创建到支付) |
| 2012-06-22 | 006 | 创建订单 |
如果不使用拉链表,则
- 1.只保留一份全量表,无法查看历史记录
- 2.每天一份全量,则造成数据冗余,存储空间浪费
- 3.设计成历史拉链表保存该表,则如下:
| 订单创建日期 | 订单编号 | 订单状态 | dw_begin_date | dw_end_date |
|---|---|---|---|---|
| 2012-06-20 | 001 | 创建订单 | 2012-06-20 | 2012-06-20 |
| 2012-06-20 | 001 | 支付完成 | 2012-06-21 | 9999-12-31 |
| 2012-06-20 | 002 | 创建订单 | 2012-06-20 | 9999-12-31 |
| 2012-06-20 | 003 | 支付完成 | 2012-06-20 | 2012-06-21 |
| 2012-06-20 | 003 | 已发货 | 2012-06-22 | 9999-12-31 |
| 2012-06-21 | 004 | 创建订单 | 2012-06-21 | 9999-12-31 |
| 2012-06-21 | 005 | 创建订单 | 2012-06-21 | 2012-06-21 |
| 2012-06-21 | 005 | 支付完成 | 2012-06-22 | 9999-12-31 |
| 2012-06-22 | 006 | 创建订单 | 2012-06-22 | 9999-12-31 |
说明:
- dw_begin_date表示该条记录的生命周期开始时间
- dw_end_date表示该条记录的生命周期结束时间
- dw_end_date=‘9999-12-31’ 表示该条记录目前处于有效状态
- 如果查询当前所有有效的记录,则select * from order_history where dw_end_date=‘9999-12-31’
- 如果查询2012-06-21的历史快照,则select * from order_history where dw_begin_date<=‘2012-06-21’ and dw_end_date>=‘2012-06-21’,这条语句会查询到以下记录:
| 订单创建日期 | 订单编号 | 订单状态 | dw_begin_date | dw_end_date |
|---|---|---|---|---|
| 2012-06-20 | 001 | 支付完成 | 2012-06-21 | 9999-12-31 |
| 2012-06-20 | 002 | 创建订单 | 2012-06-20 | 9999-12-31 |
| 2012-06-20 | 003 | 支付完成 | 2012-06-20 | 2012-06-21 |
| 2012-06-21 | 004 | 创建订单 | 2012-06-21 | 9999-12-31 |
| 2012-06-21 | 005 | 创建订单 | 2012-06-21 | 2012-06-21 |
和源表在6月21号的记录完全一致:
| 订单创建日期 | 订单编号 | 订单状态 |
|---|---|---|
| 2012-06-20 | 001 | 支付完成(从创建到支付) |
| 2012-06-20 | 002 | 创建订单 |
| 2012-06-20 | 003 | 支付完成 |
| 2012-06-21 | 004 | 创建订单 |
| 2012-06-21 | 005 | 创建订单 |
由此,拉链表即能满足对历史数据的需求,又能很大程度的节省存储资源。
Kimbal缓慢变化维一共有8种,但是只有三种被广泛使用
-
类型1 重写
与业务数据保持一致,直接update为最新的数据。缺点是无法保留历史痕迹。
-
类型2 增加新行
更新历史数据时间戳,新增行记录新值。
-
自然键第一次出现时
新增一行数据,created为业务系统的创建时间,updated为9999-12-31
-
类型2的维度发生变化时
将自然键当前记录的updated由9999-12-31刷新为最新时间
新增一行记录,记录最新数据,created为最新时间,updated为9999-12-31
-
-
类型3 增加新列
下面是不常用的几种类型
-
类型0 不做任何变化
-
类型4 微型维度
-
类型5 类型1+微型维度
增加当前微型维度主键,做为主维度的一个属性。从而避免主维度表行的爆炸性增长
-
类型6 类型1+类型2+类型3
-
类型7 双类型1+类型2
| SCD类型 | 维度表行动 | 对事实分析影响 |
|---|---|---|
| 类型0 | 属性值无变化 | 事实与原始值相关联 |
| 类型1 | 重写属性值 | 事实与当前值相关联 |
| 类型2 | 为新属性值增加新行 | 事实与发生时的有效值关联 |
| 类型3 | 增加新列来存储当前和原先值 | 事实与当前和先前值关联 |
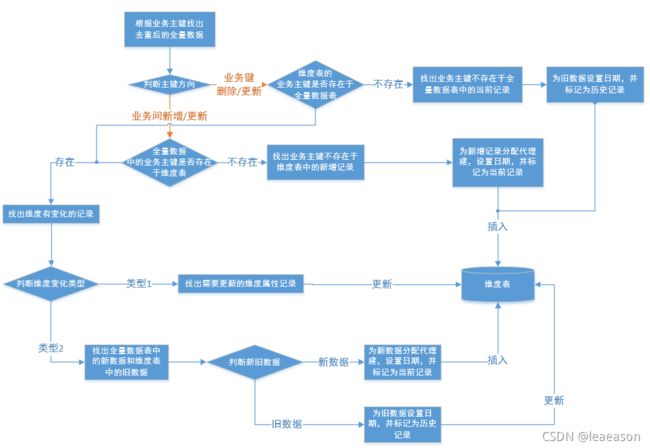
- 拉链表的实现流程
根据业务主键找出去重后的全量数据,判断业务主键是否存在于全量数据表。如果不存在,则找出新增记录,为新增记录分配代理键,并标记为当前记录 ,将数据插入维度表。如果存在,则列出维度变化类型。
判断维度表的业务主键是否存在于全量数据表
4.3 星型模型与雪花模型
雪花模型,在星型模型的基础上,维表上关联了其他维表。这种模型维护成本比较高,性能方面比较差,尤其是基于Hadoop体系构建数仓,减少Join就是减少Shuffle,性能差距会很大
4.4.数据中台总体设计方案
- 粒度性
- 模型易用性
- 模型的一致性
- 中性与共享性
- 历史性
明细数据与汇总数据
汇总数据区DWS
轻度汇总区信息,支持数据集市的数据需求。避免DM模型频繁从基础层取数,汇总,需要对DW基础表所存储的详细数据做进一步加工统计。多表连接合并,求和、平均值等。
轻度汇总数据采用逆范式宽表设计,采用维度建模的方法。尽可能包含更多的属性(维度)和指标。
建设多维集市考虑使用多维数据库(Multi Dimensional DataBase,MDD)
ETL模型分为两种
-
同步架构
-
异步架构
ETL加载方式:
-
完全刷新
-
镜像增量
-
事件增量
-
镜像比较
变化数据获取(Changing data capture)。变化数据获取有时间戳、快照。触发器和日志四种。
大体可以分为两类:
-
侵入式的
侵入式的CDC操作会给源系统带来性能的影响。基于时间戳的CDC、基于触发器的CDC、基于快照的CDC是侵入性的。
-
非侵入式
基于日志的CDC是非侵入性的。例如Oracle Golden Gate(OGG)。
5.数据治理
-
数据标准
制定业务标准、技术标准、安全标准、资源管理标准,从而保障数据生产、管理、使用合规。
-
数据架构
提升模型灵活性,保障数据一致性,消除跨层引用和模型冗余等问题。
-
数据安全
加强敏感数据和数据共享环节的安全治理
-
元数据建设
打通从数据采集到构建再到应用的整条链路,并为数据使用人员提供数据地图、数据可视化等元数据应用产品,解决了“找数”,“取数”,“元数据变动影响评估”等难题。
5.1 数据模型
5.2 数据质量
5.3 数据治理
-
数据治理工作,一定要先摸清楚数据的家底,规划好路线图,切记一上来就搭平台。
-
数据治理即是技术部门的事,也是业务部门的事,一定要建立多方共同参与的组织架构和制度流程,数据治理的工作才能真正落实到人,不至于浮在表面。
-
数据治理不要贪图大而全,要从核心系统,重要的数据开始做起
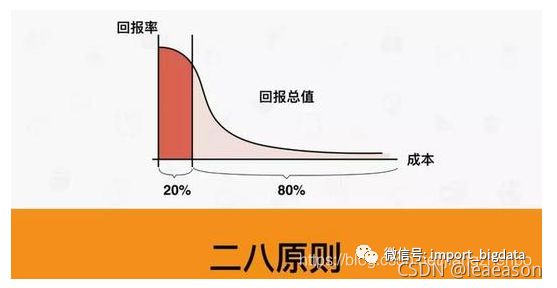
二八原则:8成的数据业务,其实是靠2成的数据在支撑;8成的数据质量问题,其实是由2成的系统和人产生的。在数据治理过程中,如果能找出这2成的数据和这2成的系统和人,将会起到事半功倍的效果。
-
不要过度迷恋与工具,组织架构,制度流程、现场的实施和运维也非常重要。数据治理是对人的行为的治理
-
数据标注难落地是数据治理中的普遍性问题,实施过程中要区分遗留系统和新建系统,分别来执行不同的落地策略
-
数据质量问题的解决,要形成每一个环节都有确定责任人的闭环机制和反馈机制
-
数据治理工作,一定从需求开始,想办法让客户直观地看到成果
5.3.1 数据治理之元数据管理
一、元数据的定义
-
元数据(Meta Data)是描述数据的数据
例如,要想描述清楚一个实际的数据,以某张表为例,需要知道表名、表别名、表的所有者、数据存储的物理位置、主键、索引、表字段、与其他表的关联关系。其实元数据就是数据的户口本
-
元数据管理,是数据治理的核心和基础
元数据相当于所有数据的一张地图
-
元数据是描述数据的数据,描述元数据的数据成为元模型(Meta Model)
下面是元模型、元数据、数据直接的关系

元数据本身的数据结构也是需要被定义和规范的,定义和规范元数据的就是元模型,国际上元模型的标准是CWM(Common Warehouse Metamodel,公共仓库元模型),一个成熟的元数据管理工具,需要支持CWM标准。
二、元数据从哪里来
元数据贯穿大数据平台数据流动的全过程,主要包括:
- 数据源元数据
- 数据加工处理过程元数据
- 数据主题库专题库元数据
- 服务层元数据
- 应用层元数据
请见下图:
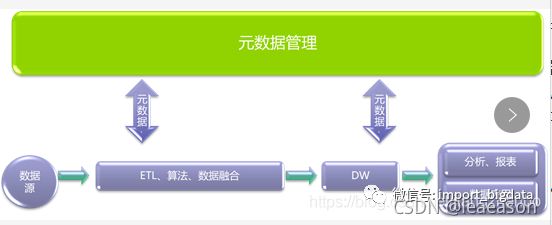
业内通常把元数据分为以下类型:
- 技术元数据:库表结构、字段约束、数据模型、ETL程序、SQL程序
- 业务元数据:业务指标、业务代码、业务术语
- 管理元数据:数据所有者、数据质量定责、数据安全等级
元数据采集方式:
在采集方式上,包括数据库直连,接口、日志文件等技术手段,对结构化数据的数据字典、非结构化数据的元数据信息、业务指标、代码、数据加工过程等元数据信息进行自动化和手动采集。
三、有了元数据,能做些什么
-
元数据查看
提升信息在组织内的共享
-
数据血缘和影响性分析
血缘分析:定位问题数据来源和加工流程
影响性分析:业务系统表结构变更,及时修改相应的分析应用表结构,将问题消灭在萌芽之中。
-
数据冷热度分析
冷热度分析主要是对数据表的被使用情况进行统计,如:表与ETL程序、表与分析应用、表与其他表的关系情况等,从访问频次和业务需求角度出发,进行数据冷热度分析,用图表的方式,展现表的重要性指数。
数据的冷热度分析对于用户有巨大的价值,典型应用场景:我们观察到某些数据资源处于长期闲置,没有被任何应用调用,也没有别的程序去使用的状态,这时候,用户就可以参考数据的冷热度报告,结合人工分析,对冷热度不同的数据做分层存储,以更好地利用HDFS资源,或者评估是否对失去价值的这部分数据做下线处理,以节省数据存储空间。
-
数据资产地图
全局视角对信息进行归并、整理,展现数据量、数据变化情况,数据存储情况,整理数据质量等信息,为数据管理部和决策者提供参考
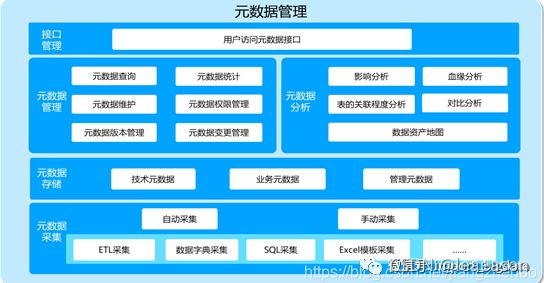
四、 总结
元数据相当于数据户口本和地图,是数据治理的核心和基础
元数据分为三类:技术元数据,业务元数据,管理元数据
元数据采集入库以后,可以产生
- 冷热度分析
- 血缘关系分析
- 影响性分析
- 数据资产地图
5.3.2 数据治理之数据质量管理
数据质量是数据质量的最终目的
一、数据质量管理的目标
通过可靠的数据,提升数据在使用中的价值,并最终为企业赢得经济效益
二、数据质量问题产生的根源
深究下去还是管理的问题,需要从业务角度着手解决数据质量问题,建立科学、可行的数据质量评估标准和管理流程。
三、数据质量评估的标准
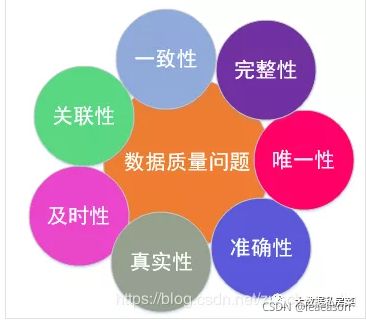
业界认可的数据质量标准:
-
准确性
数据准确性,描述数据是否与对应的客观实体特征相一致
-
完整性
描述数据是否存在缺失记录或者缺失字段
-
一致性
描述同一实体的同一属性的值在不同的系统是否一致
-
有效性
是否满足定义的条件或在一定值域范围内
-
唯一性
是否存在重复记录
-
及时性
数据的产生和供应是否及时
-
稳定性
描述数据的波动是否稳定,是否在其有效范围内
总结
数据质量管理贯穿生命周期的全过程,覆盖质量评估、数据监控、数据探查、数据清洗、数据诊断等方面
5.3.3 数据治理之数据标准管理
5.3.4 数据治理之数据资产管理
数据资产管理的四个目标
-
可见
-
可懂
-
可用
-
可运营
四、数据质量管理的流程
五、数据质量管理的取舍
6 数据湖与数据中台的区别
数据湖:
-
统一、集中的存储全部的原始数据。
-
使用BI+AI的手段取分析数据
数据类型
- 结构化
- 半结构化
- 图片/音视频等
目的:
- 打破数据孤岛
- 基于统一的、集中的整个数据的收集,支持各种各样的计算
- 弹性,能够优化存储和计算的成本
- 为数据提供统一、集中的管理平台
理想的数据湖所具备的能力:
- 基于对象存储,大规模存储能力
- 大目录元数据操作能力
- 策略灵活的缓存加速能力
- 与计算打通优化的能力
- 支持数据湖新型表格存储的能力
- 归档/压缩/安全存储的能力
- 全面的大数据+AI生态支持
- 强大的迁移能力,甚至无缝迁移能力。
7.维度建模
设计数据仓库模型的步骤:
- 1.选择业务流程
- 2.声明粒度
- 3.确认维度
- 4.确认事实
7.3 零售业务
7.3.1 维度模型设计的四步过程
-
第一步,选择业务过程
-
第二步,声明粒度
精确定义每个事实表的每一行表示什么。粒度传递的是与事实表度量有关的细节级别。
粒度越细越好。粒度叫高的模型无法实现用户下钻细节的需求
-
第三步,确认维度
-
第四步,确定事实
只考虑数据来源建模数据,看似省力,其实不会成功
7.3.2 事实表粒度
避免事实表中出现空的外键,在事实表中用Unknown来替代。
维度表中属性的空值用Unknown来替代
退化维度通常在事实表的主键中起着重要的作用。
无事实的事实表。
代理键 _fk表示。维度表的主键用_pk。不要将自然键作为维度表的主键,因为一切都有可能变化。
数仓中的维度表与事实表的每个连接都应该基于无实际含义的整数代理键。应该避免使用自然键作为维度表的主键。
代理键的好处
-
1.为数仓缓冲操作型系统的变化
代理键可以隔离源系统的变化。例如,在源系统的用户账号不活跃,隔段时间以后,用户账号重新分配问题。如果仅依赖于操作型代码,可能会遇到键重叠的问题。
-
2.集成多个源系统
将多个自然键连接成为一个公共的代理键
-
3.改进性能
减少存储空间
-
4.处理空值或未知条件
-
5.支持维度属性变化跟踪
例如,缓慢变化维
支架维度,尽量还是不要使用。限制了用户在单一维度中浏览属性的能力。
7.4 库存
7.4.1 半可加事实
7.4.2 事实表类型
事实表的分类:
-
事务事实表
记录事务层面的事实,保存的是最原子的数据,也称“原子事实表”。一旦事务被提交,数据便不再进行更改,更新方式为增量更新。
-
周期快照事实表
周期快照以规律性的,可预见的时间间隔来记录事实,例如每天,每月,每年。典型的例如销售日快照,库存日快照表。
周期快照事实表的粒度比事务事实的粒度要粗,维度要比事务事实表要少,记录的事实要比事务事实表多。一旦插入便不再进行更改,更新方式为增量更新。
-
累计快照事实表
周期快照事实表记录的是确定周期的数据,而累积快照事实表记录的不确定的周期数据。
累积快照事实表代表的是完全覆盖一个事务或产品的生命周期的时间跨度,通常具有多个日期字段,用来记录生命周期的关键时间点。另外,还会有一个指示最后更新日期的附加日期字段,
由于事实表中许多日期在首次加载时不知道,所以必须用代理关键字来处理未定义的日期。在事实表数据加载完成之后,可以对它进行更新,来补充采集到的日期信息。
举个例子:
- 累计事实表:
| 订货日期 | 预定交货日期 | 实际发货日期 | 实际交货日期 | 最后更新日期 | 金额 | 数量 | 运费 |
|---|---|---|---|---|---|---|---|
| 2021-05-27 | 2021-06-01 | 未知 | 未知 | 2021-05-28 | 110 | 1010 |
在累计快照事实表中,记录的是购买货物的整个生命周期的数据
-
事务事实表
-
周期快照事实表
7.4.3 一致性维度与事实
构建一致性维度。
构建一致性维度的取舍。
一致性维度支持跨钻。
7.4.5 构建总线矩阵
设计数据仓库总线矩阵
机会/利益相关方矩阵
7.5 采购
采购涉及范围广泛的活动,从谈判合同到发起购买清单以及购买订单,到跟踪票据及授权付款。
采购事务的业务过程包含:采购请求、采购订单、托运通知、发票和付款等。
采购事务与总线矩阵
7.5.1 单一事务事实表与多事务事实表
多个采购事务来自于不同的源系统,购买系统负责提供购买需求和购买订单,仓库系统负责提供发货通知和仓库清单,账户支付系统负责处理供应商付款。多个事务类型具有不同的维度。
在整理这些新的细节时,可能会面对一个设计决策。是否应该建立一个包含用于观察所有采购事务的事务类型维度的混合事务事实表,或者为每个事务类型建立不同的事实表?
做为维度建模者,需要基于对业务需求的全面理解,并权衡源数据的现实情况,制定设计决策。
需要参考一下三点:
- 用户的分析需求是什么
- 的确存在多个独特的业务过程吗
- 多个源系统获取同样粒度的度量吗
- 事实的维度是什么?
这时候需要画出总线矩阵。
针对购买需求、购买订单、发货通知、仓库收据、供应商付款等业务构建了不同的事实表。这样选择的原因在于用户将这些活动视为不同的业务过程,数据来自不同的数据源,对不同事务类型有特定的维度。多个事实表能够保证具有丰富的、更具描述性的维度和属性。
单一事实表可能需要为同样的维度建立一般化的标号。例如购买订单日期和收获日期可以一般化为简单的事务日期。同样,购买主体和接收成员可能为雇员,这种一般化方法降低了产生的维度模型的易读性。
辅助采购快照
根据业务需求,开发了跨过程的累计快照事实表。
7.5.2 缓慢变化维基础
尽管维度表属性相对稳定,但不是一成不变的,尽管相当缓慢,属性值仍然会随时间发生变化。维度设计者与数据治理负责人共同努力,采用适当策略来应对发生的变化。
比较熟悉的SCD分类
-
类型 1
重写
-
类型2
增加新行
-
类型3
增加新列
-
类型4
增加微型维度
混合缓慢变化维度
类型0:保留原始值
例如:日期维度。不允许ETL对该维度进行更新。从某种意义上来说,国家维度也是
类型4:增加微型维度
| 代理键 | 产品统一编号(NK) | 产品描述 | 部门名称 |
|---|---|---|---|
| 12345 | ABC922-Z | 平板电脑A | 教育 |
混合缓慢变化维度技术
类型5:类型4微型维度与类型1支架表
类型5的命名仅仅是因为它来自类型1和类型4。因为1+4=5。
支架表的合并技术。
- 类型6:类型1属性增加到类型2维度
- 类型7:双重类型1与类型2维度
缓慢变化维总结:
| SCD类型 | 维度表行动 | 对事实分析的影响 |
|---|---|---|
| 类型0 | 属性值无变化 | 事实与属性的原始值关联 |
| 类型1 | 重写属性值 | 事实与属性的当前值关联 |
| 类型2 | 为新属性值增加新维度行 | 事实与将与事实发生时有效的属性值关联 |
| 类型3 | 增加新列来保存属性当前和原先的值 | 事实与当前和先前属性的交替值关联 |
| 类型4 | 增加包含快速变化属性的微型维度 | 事实与事实发生时有效的变化属性关联 |
| 类型5 | 增加类型4微型维度以及在基本维度中重写类型1微型维度键 | 事实与事实发生时有效的变化属性关联,加上当前快速变化的属性值 |
| 类型6 | 在类型2维度行中增加类型1重写属性值,并重写所有先前的维度行 | 事实将与事实发生时有效的属性值关联,加上当前值 |
| 类型7 | 增加包含新属性的类型2维度行,加上限于当前行和属性值的视图 | 事实将与事实发生时有效的属性值关联,加上当前值 |
这一张主要介绍了两个部分:
Part I
采购主要讨论了及几种处理采购数据的方法,有效地管理采购指标可以对组织的基线管理产生重要影响。
Part II
介绍了几种处理维度属性值变化的技术。一共有7种。可以分三类
-
第一类:什么也不做,即类型0。举例,时间维度,国家维度?。
-
第二类:重写值,类型1;增加新行,类型2;增加新列(属性),类型3
-
第三类:复杂的混合方法,类型5到类型7。
雪花型(snowflakes)、支架型(outtriggers)与桥型(bridges)的区别
-
雪花型
当维度表是雪花型的时候,可以消除冗余的多对一(many-to-one)属性被从独立的维度表中移除。例如,品牌(brand)和类别(type)原先都是产品维度表(prd_dim)中的列,现在把品牌和类别转换成单独的表并与产品维度表(prd_dim)连接。应用雪花模型,维度表被标准化为第三范式。
增加了ETL的负载和查询复杂度,不建议使用。
-
支架型
支架型类似于雪花型,通常是用来处理多对一的关系,但是也存在更多的限制。
支架型是指维度表之间的连接,并不是完全标准的雪花型,而是事实表中托生的一个以上的层次。
-
桥型
桥表通常在两种复杂的场景下使用。其一是当多对多关系不能只由事实表本身解决的时候“单事实度量值无法与维表中的多值对应,比如多客户与单银行账户关联时,事实表中的客户维度键无法有效分配给多个客户。因此需要使用包含双键的桥表,来匹配客户和账户的多对多关系,并用来连接事实表。
桥表也用来表示深度参差不齐或可变的层次关系,这种层次关系不能有效转型为简单的固定层次的具有多对一属性的维表。桥表应用来捕获完全的数据关系。
7.6 订单管理
-
维度角色扮演
事实表里有两个关于日期的维度外键,分别是订单日期维度、请求发货日期维度。通过对日期维度建立 视图的方式生成两个单独的物理日期维度表。
-
维度退化
-
订单表头,明细
-
多币种
7.7 会计
- 会计处理的总线矩阵片段
- 总账周期快照和记账事务
- 会计科目表
- 预算编制链
- 参差不齐的可变深度层次
- 固定深度的位置层次
- 采用桥接表和其他建模技术处理无法确定深度的不规则层次
- 随时间变化的不规则层次
- 通过合并多个业务过程度量的事实表整合
会计科目自然分解为两个维度:
- 总账科目
- 组织
7.7.1
7.7.2
8.范式建模
三范式:
-
原子不可分割
属性不可分割,例如集合、数组这样的属性就需要拆分
-
主键约束
表中要有主键,表中的其他字段依赖于主键
-
外键约束
在表中增加其他表的外键,通过外键去关联其他表中的字段
9.SQL案例
9.1 求用户的最大连续登陆天数
建表插入数据
create table tmp_continous
(
id STRING ,
time DATETIME
);
INSERT OVERWRITE TABLE tmp_continous
Select '201', '2017-01-01 00:00:00' union all
Select '201','2017-01-02 00:00:00' union all
Select '202','2017-01-02 00:00:00' union all
Select '202','2017-01-03 00:00:00' union all
Select '203','2017-01-03 00:00:00' union all
Select '201','2017-01-04 00:00:00' union all
Select '202','2017-01-04 00:00:00' union all
Select '201','2017-01-05 00:00:00' union all
Select '202','2017-01-05 00:00:00' union all
Select '201','2017-01-06 00:00:00' union all
Select '203','2017-01-06 00:00:00' union all
Select '203','2017-01-07 00:00:00';
思路:
-
Step1:用户登录日期去重
去重数据,保证每天有且仅有一条登陆数据
select id, time from tmp_continous group by id,time -
Step2:用窗口函数计数
-- 对数据进行排序处理 select id, time, ROW_NUMBER() OVER (PARTITION by id order by time) as order_sort from tmp_conti\nous -
Step3:日期减去计数值得到结果
通过对用户id分组后排序,用登陆日期减去序号rn。如果连续,则最终得到的日期会相同
利用登陆时间 - 排序得到的序列号,如果减去后得到的结果是同一天,则说明是连续的;否则是不连续的。这里需要仔细体会以下,也可以看下面这张图。
比如是2017-01-01 sort为1;2017-01-02 sort为2;减去sort之后都是 2016-12-31。如果出现一个 2017-01-04 sort为3,那么减去后的结果是2017-01-01那么就是不连续的 -
Step4:根据id和结果分组计算并count
-- Postgresql
select
id,
MAX (continous)
from
(
select
id,
count(same_day ) as continous
from
(
select
id,
time1,
order_sort,
(time1 + (order_sort* interval '1 day') ) as same_day--日期相同,则为连续登陆日期的开始日期,从而可以计算登录天数
from (
select
id,
time1,
cast(concat('-',cast(order_sort as varchar)) as INT) as order_sort
from (
select
id,
time1,
ROW_NUMBER() OVER (PARTITION by id order by time1) as order_sort
from ods_bw.tmp_continous t
) t1 -- 序号取负值,转换为int类型,与登录日期相加。
)t2 order by id,order_sort desc
) t3
group by id,same_day
) t4 group by id
需求在进一步,需要当前最大的连续登陆天数
方法是利用时间的由大到小排(刚才是由小到大排),然后同样得出排列号码,不过要在基础上减一,因为当天的date_add是 + 0 而不是跟上面那样减一
后续的操作跟上面一样。
--最大的连续登录日期,Postgresql写法
with w1 as (
SELECT
id,
time1
FROM ods_bw.tmp_continous
group by id,time1
)--对用户的登录天数进行去重,确保每个用户每天只登录一次
,w2 as (
select
id,
time1,
row_number() over(partition by id order by time1) as rn
from w1
)--将用户的登录时间降序排序
,w3 as (
select
id,
time1- rn*interval '1 day' as order_sort
from w2
)--用登陆的时间减去 排序序号*day。一旦登录时间连续,这个值:order_sort便会相同
,w4 as (
select
id,
count(order_sort) as count_order_sort
from w3 group by id,order_sort
),--同一个用户,连续的登录时间计数
select
id,
max(count_order_sort) as max_signin from w4
group by id--选择最大的登录天数即可
9.2 统计每个用户的累计访问次数
9.3 分组TopN
可参考第四条分组求TOPN
9.4 分组求TOP%N
求每个科目前百分之10的学生
--stuscore学生成绩表,姓名,科目,分数
-- Drop table
-- DROP TABLE ods_bw.stuscore;
CREATE TABLE ods_bw.stuscore (
"name" varchar NULL,
subject varchar NULL,
score int4 NULL
)
TABLESPACE ods_tablespace
DISTRIBUTED RANDOMLY;
-- Permissions
ALTER TABLE ods_bw.stuscore OWNER TO ur_uown_ods;
GRANT ALL ON TABLE ods_bw.stuscore TO ur_uown_ods;
INSERT INTO ods_bw.stuscore ("name",subject,score) VALUES
('Tom','English',100)
,('Luis','English',52)
,('Lee','English',50)
,('Jack','English',10)
,('Rose','History',100)
,('Tom','History',100)
,('Luis','History',90)
,('Quws','History',88)
,('Pig','History',68)
,('Cat','History',62)
;
INSERT INTO ods_bw.stuscore ("name",subject,score) VALUES
('Hors','History',60)
,('Lee','History',40)
,('Jerry','History',30)
,('Jous','History',22)
,('Dog','History',20)
,('Jack','History',0)
,('Tom','Math',100)
,('Rose','Math',100)
,('Lee','Math',100)
,('Cat','Math',91)
;
INSERT INTO ods_bw.stuscore ("name",subject,score) VALUES
('Luis','Math',81)
,('Jous','Math',81)
,('Hors','Math',80)
,('Jack','Math',70)
,('Quws','Math',67)
,('Dog','Math',55)
,('Pig','Math',47)
,('Jerry','Math',21)
,('Tom','Physi',100)
,('Rose','Physi',100)
;
INSERT INTO ods_bw.stuscore ("name",subject,score) VALUES
('Rose','Physi',100)
,('Jerry','Physi',99)
,('Dog','Physi',92)
,('Quws','Physi',87)
,('Cat','Physi',81)
,('Jerry','Physi',81)
,('Luis','Physi',79)
,('Hors','Physi',70)
,('Pig','Physi',57)
,('Hors','Physi',50)
;
INSERT INTO ods_bw.stuscore ("name",subject,score) VALUES
('Jous','Physi',44)
,('Jous','Physi',41)
,('Dog','Physi',41)
,('Pig','Physi',39)
,('Cat','Physi',34)
,('Jack','Physi',30)
,('Lee','Physi',30)
,('Quws','Physi',19)
;
代码
-- 分组求TOP%N
select
t1.name,
t1.subject ,
t1.score ,
t1.rn,--按分数降序排序的排名
t2.cnt--每一门科目的总人数
from (
select
name,--姓名
subject ,--科目
score ,--分数
row_number () over (partition by subject order by score desc ) as rn --按分数降序排序的排名
from ods_bw.stuscore t1
) t1
left join (
select
subject ,
count(subject) as cnt --每一门科目的总人数
from ods_bw.stuscore t1 group by subject
) t2 on t1.subject=t2.subject
where t1.rn <=t2.cnt*0.5
9.5 求落在某一个区域的概率
表 A
-- Drop table
-- DROP TABLE ods_bw.test1;
CREATE TABLE ods_bw.test1 (
id int4 NULL,
value numeric(5,2) NULL,
tag varchar NULL
)
TABLESPACE ods_tablespace
DISTRIBUTED RANDOMLY;
-- Permissions
ALTER TABLE ods_bw.test1 OWNER TO ur_uown_ods;
GRANT ALL ON TABLE ods_bw.test1 TO ur_uown_ods;
-- 数据
INSERT INTO ods_bw.newtable (id,value,tag) VALUES
(1,0.21,'0')
,(2,0.91,'1')
,(3,0.51,'1')
,(4,0.23,'0')
,(5,0.49,'0')
,(6,0.36,'0')
,(7,0.37,'1')
,(8,0.38,'1')
,(9,0.75,'1')
,(10,0.66,'0')
;
INSERT INTO ods_bw.newtable (id,value,tag) VALUES
(11,0.99,'1')
,(12,0.98,'0')
,(13,0.90,'0')
,(14,0.36,'1')
,(15,0.37,'1')
,(16,0.38,'1')
,(17,0.75,'1')
,(18,0.66,'0')
;
vaue为介于 0~1之间的小数(小数位为两位)
当
0=<value<=0.25 区域A
0.25=<value<=0.5 区域B
0.5=<value<=0.75 区域C
0.75=<value<=1 区域D
求各个区域中tag为1的概率
SQL代码,暂时想不到更好的解决办法
with
w1 as (
select
t1.id ,
case
when 0<=value and value<0.25 then 'A'
when 0.25<=value and value <0.50 then 'B'
when 0.50<=value and value <0.75 then 'C'
when 0.75<=value and value <1.00 then 'D'
end as value_area ,
t1.value ,
t1.tag
from ods_bw.newtable t1
)
select
t1.value_area,
t1.cnt,
t2.cnt,
SUM (t1.cnt)/SUM(t2.cnt)
from (
select
t1.value_area,
count(value_area) as cnt
from w1 t1
where tag='1'
group by value_area
) t1
inner join
(
select
value_area,
count(value_area) as cnt
from w1
group by value_area
) t2
on t1.value_area=t2.value_area group by t1.value_area,t1.cnt,t2.cnt
9.6 行转列
9.7 列转行
10 其他的知识点
10.1 Hive 不支持记录级别的增删改,如何用Hive实现缓慢变化维。
Hive中的缓慢变化维度表应该怎么设计。
10.2 暂无
10.3 代理键
待补充
10.4.数据分区与数据倾斜?
待补充
10.5 物化视图
物化视图说白了就是物理表,定期有程序会更新这张物理表