hive分区操作partition——静态分区和动态分区语法、区别及使用场景
文章目录
-
- 一、hive分区概念(partition)
-
- 1.hive的概念
- 2.hive分区
- 3.分区的作用
- 二、静态分区与动态分区的语法
-
- 1.原文件
- 2.创建分区表语法
- 3.静态分区操作:增加或删除分区语法
- 4.静态分区引入数据
- 5.动态分区语法
- 三、静态分区和动态分区的区别及应用场景
-
- 1.静态分区和动态分区的区别
- 2.静态分区和动态分区的应用场景
一、hive分区概念(partition)
1.hive的概念
hive 是基于Hadoop的一个数据仓库工具,底层存储是基于 HDFS 进行存储,Hive 的计算底层是转换成 MapReduce任务进行计算,hive可以将结构化的数据文件映射为一张数据库表,并提供SQL查询功能。
简单来讲,①hive并不存储数据 ②提供类sql语法对文件进行操作
2.hive分区
hive分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
即表中的一个分区对应于表下的一个目录,所有的分区的数据都存储在对应的目录中。
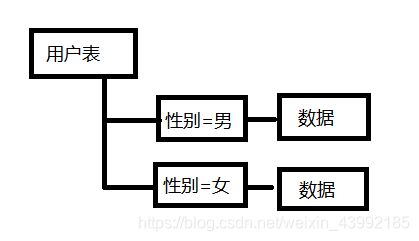
例如:总表(用户表)为一个文件夹根据性别分区,那么性别为男生成一个文件夹,性别为女生成一个文件夹,每个文件夹中存储相应数据。
3.分区的作用
分区主要用于提高性能
①分区列的值将表划分为一个个的文件夹
②查询时语法使用"分区"列和常规列类似
例如:select * from userinfo where sex ='男';
③查询时Hive会只从指定分区查询数据,提高查询效率
二、静态分区与动态分区的语法
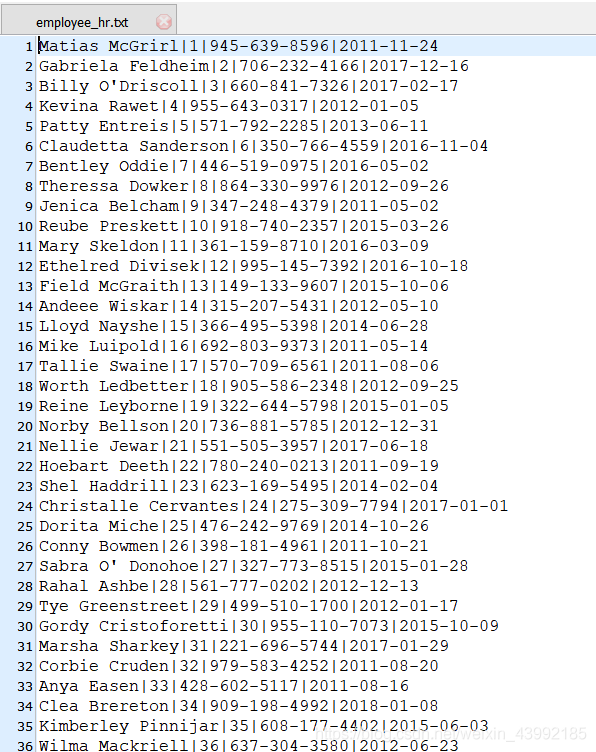
1.原文件
2.创建分区表语法
注意:分区的列最好不要与建表的列相同
year 为一级分区,month为二级分区
create table if not exists employee_partitioned (
`name` string,
`employee_id` int,
`number` string)
partitioned by (
`year` int,
`month` int)
row format delimited fields terminated by '|'
stored as textfile;
3.静态分区操作:增加或删除分区语法
-- 创建分区
//单个分区创建
alter table employee_partitioned add partition(year='2019',month='6') ;
//多个分区创建
alter table employee_partitioned add partition(year='2020',month='6') partition(year='2020',month='7');
-- 删除分区
//单个分区删除
alter table employee_partitioned drop partition (year='2019',month='6');
//多个分区删除
alter table employee_partitioned partition (year='2020','month=6'), partition (year='2020',month='7');
4.静态分区引入数据
①load
local inpath 为本地文件路径 ,只有inpath 表示hdfs文件路径 ,将路径中的文件传到2020年6月的文件夹中,默认传入该路径的数据增加year=2020,month=6 两个字段,也可以将year=2020,month=6 理解为一种标签,原数据并没有发生改变,在查询2020年6月的数据时,就将该文件的数据展示出来
一般将已确认分区的数据传入相应的文件夹中
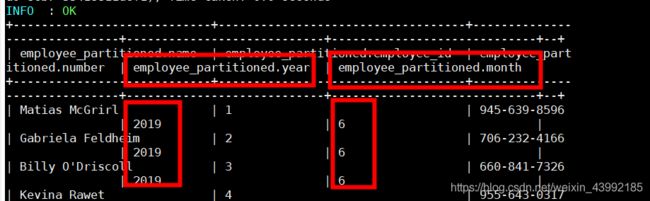
load data local inpath '/data/employee_hr.txt' into table employee_partitioned partition(year=2019,month=6);
②insert(常用)
insert into 将数据添加到表中
insert overwrite 会覆盖表中已有的数据
//将本地文件传入hdfs中
Hadoop dfs -put /data/employee_hr.txt /tmp/employee
//将文件映射为相应的表
create table if not exists employee_hr(
name string,
employee_id int,
number string,
start_date date)
row format delimited fields terminated by '|'
location '/data/employee_hr.txt';
//根据查询所得的结果传入相应的文件夹中
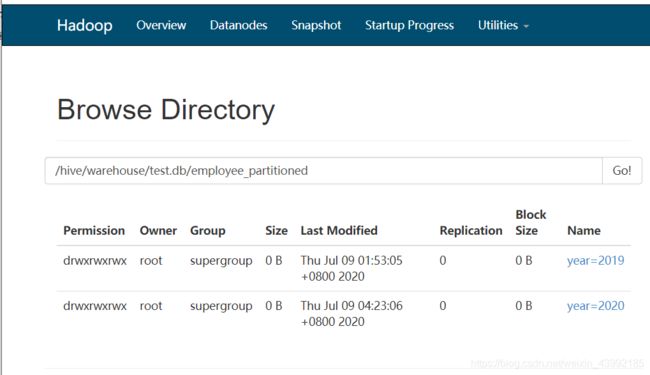
insert overwrite table employee_partitioned partition(year=2020,month=8)
select name,employee_id,number from employee_hr where year(start_date)=2020 and month(start_date)=8;
5.动态分区语法
①设定属性,打开自动分区,并设置分区模式为非严格模式
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
②动态分区建表语句与静态分区相同,这边就直接使用employee_partitioned表
③动态分区插入数据
根据文件内容,自动分区
insert into employee_partitioned
partition(year,month)
select name,employee_id,number,year(start_date),month(start_date)
from employee_hr;
三、静态分区和动态分区的区别及应用场景
1.静态分区和动态分区的区别
静态分区
①静态分区是在编译期间指定的指定分区名
②支持load和insert两种插入方式
load方式
会将分区字段的值全部修改为指定的内容
一般是确定该分区内容是一致的时候才会使用
insert方式
必须先将数据放在一个没有设置分区的普通表中
该方式可以在一个分区内存储一个范围的内容
从普通表中选出的字段不能包含分区字段
③适用于分区数少,分区名可以明确的数据
动态分区
①根据分区字段的实际值,动态进行分区
②是在sql执行的时候进行分区
③需要先将动态分区设置打开
④只能用insert方式
⑤通过普通表选出的字段包含分区字段,分区字段放置在最后,多个分区字段按照分区顺序放置
2.静态分区和动态分区的应用场景
静态分区:适合已经确认分区的文件,分区相对较少的,适合增量导入的应用场景
动态分区:适合根据时间线做分区,分区比较多的,适合全量导入的场景