swin transformer 总结
1. 背景介绍
原名:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
获奖:2021 ICCV Best Paper
2.文章介绍
2.1概括
Swin Transformer 是一种新型的transformer,可以用作视觉和语言处理的统一模型
- 特性
- 引出了一种具有层级的特征表达方式(基于self-attentation的shifted window)
- 具有线性的计算复杂度(和输入的图像尺寸相关) - 性能(state of the art)
- COCO目标检测
- ADE20K语义分割
2.2 创新点介绍
NLP和CV的不同点:
(1)CV包含不同的尺度,而NLP 把tokens作为transformer的基本元素。当前的cv中的transformer都是固定尺度的,不适合用作CV的任务。
(2)CV处理的是高分辨率的图像,而NLP处理的是位于文本段落中的单词。
2.2.1 层级特征图
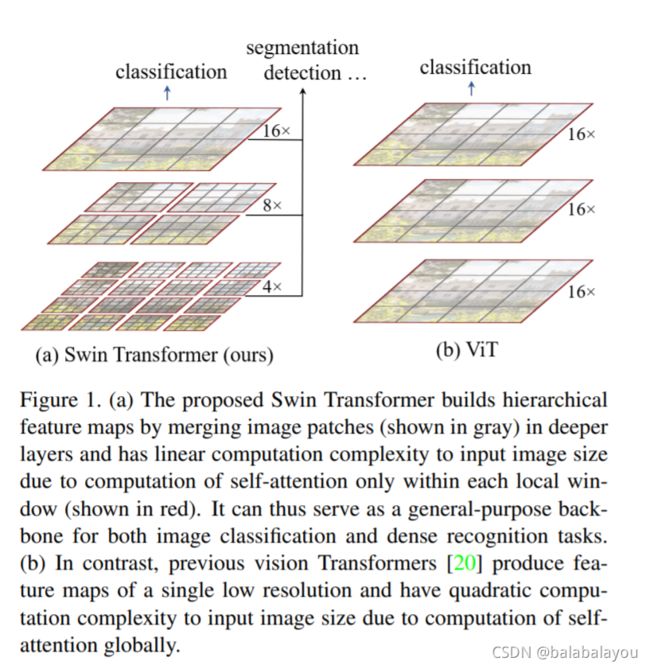
(a)Swin Transform 创建的是具有层级的特征图,通过合并深层的图像的patches,并且具有线性的计算复杂度(因为仅对每一个局部的window做self-attentation计算)。其中,windows之间是不重叠的,每个window中的patches的个数是固定的。
patch:灰色框的区域。每个patch都会当作一个“token”
local window:红色框的区域
(b) ViT 产生的是一个低分辨率的特征图,并且具有平方的计算复杂度(由于对输入图像尺寸做self-attentation)。
2.2.2 shifted window的提出
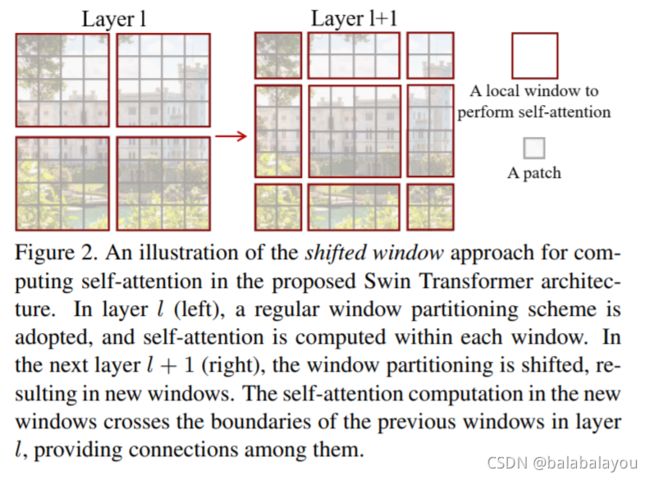
shifted window是跨接上一层的windows,提升了模型的性能。在同一个window中的query patches共享相同的key集合,这样提升了访问内存的效率。想反,之前的slide window的方式的self-attentation访问内存比较低效,因为不同的query 像素点有着不同的key集合。
Figure2中,左侧l(L的小写)层是平均分的local window,而l + 1层将windows的形状调整(shifted),有着新的分配方式的windows。在这些新的windows中,self-attentation将会跨越上一层(l层)的windows边界,使得这些windows之间有了连接。
2.2.3 Swin-Tiny的结构
2.3.3.1Swin-Tiny的整体结构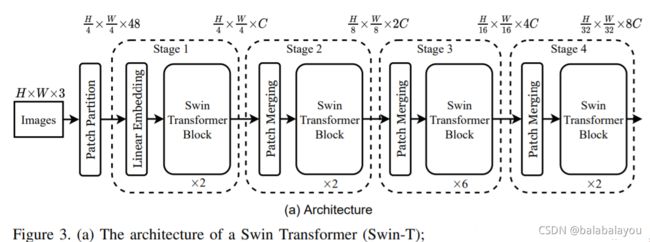
Figure3 (a) Swin-Tiny的结构
输入:是RGB图(维度HW3)。
Patch Partition:通过一个patch切分模块对输入图进行切分成一个没有重叠的patches。每个patch当作一个“token”,它的特征是原始RGB值的一个concatenation. 比如,patch是44,那么每个patch的特征的维度就是44*3 = 48。 其中,H * W * 3 = H/4 * W/4 * 48。
Stage 1: Linear Embeding + Swin Transformer Block
Linear Embeding层:人为设定维度。使得raw-valued feature 投射(project)到任意维度,图中用C表示。
Swin Transformer Block:保持tokens 的数目 = H/4 * W/4。
故,输出维度就是H/4 * W/4 * C。
Stage 2:patch merging + Swin Transformer Block
patch merging: 联结(concatenates)每组2 x 2的相邻的patches的特征,并且在4C维度的联结后的特征上应用用一个线性层。这降低了4倍的tokens数量,其中4 = 2x2,2是倍下采样的倍数。 concatenate之后,H/4 变成 H/8, W/4变成W/8
然后输出的维度被设置成2C。
接下来Swin Transformer Block用于特征转换(feature transformation),保持 H/8 * W/8。
Stage 3: 高宽 = H/16 * W/16
Stage 4: 高宽 = H/32 * W/32
2.2.3.2两个连续的Swin Transformer 块的解释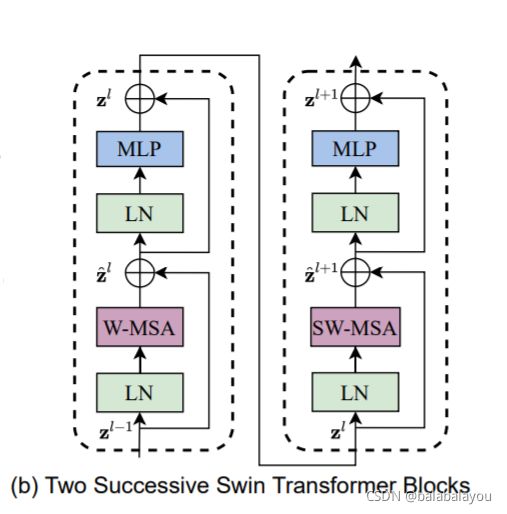
Figure3(b)两个连续的Swin-T块
LN: LayerNorm
MSA:多头注意力机制(multi-head self attention)
W:常规的window采样
SW:shifted的window采样
其中,MSA和W-MSA的计算复杂度见公式(1)、(2)。很明显,MSA是和图像的宽高的平方相关的;W-MSA是和宽高的线性相关的(默认设置M=7,即window大小)。
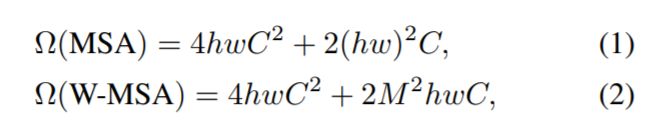
z ^ \hat{z} z^ 和 zl 分别代表 对块l分别做 (S)W-MSA和MLP之后的输出特征。
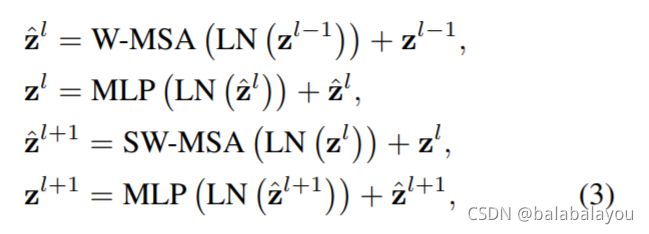
2.2.4 shifted windows
平均分成M x M大小的windows可以降低时间复杂度,由于没有重叠,导致缺乏跨windows之间的连接。为解决这个问题提出shifted window 划分方式,即变换两个连续的Swin Transformer blocks的划分方式。
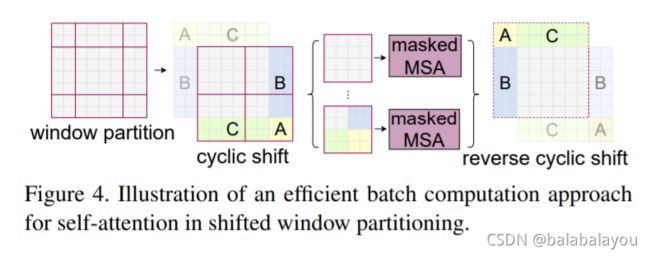
如图Figure4,window的划分方式,对于cyclic shift中,首先是浅色阴影As、Bs、
Cs三个sub windows,下一次选的时候是深色的Ad、Bd、Cd这三个sub windows(s:shallow,d:deep)。A、B、C组成了一个batch window,即每个batch window包含了若干个sub-windows。
这两组A、B、Csub-windows在feature map上是不相邻的。用masking 机制来限制
{As : Aq, Bs:Bq, Cs:Cq} 做self-attentation。
Relative position bias对Swin Transformer没啥作用,故舍去。
2.2.5几个版本
Swin-Tiny、Swin-Small、Swin-Base、Swin-Large。