初入自然语言处理,一些学习上的的理解
文章目录
- 学习自然语言处理,如何开始?
- 一.从模型谈起
-
- 1.模型的构建
-
- 1.1.encoder-decoder结构
-
- 1.1.1.encoder可以是什么
- 1.1.2.以及decoder
- 2.模型的运算过程
-
- 2.1.前向传播与反向传播
- 2.2.矩阵运算
- 二.接着是数据
-
- 1.数据的存在形式
- 2.数据的处理手法
- 三.总结
- 四.今后的展望
学习自然语言处理,如何开始?
万事开头难,面对互联网上繁杂而艰深的理论知识。我相信不少人(包括我自己)都曾陷入过迷茫的境地,从哪里开始学?哪部分内容重要?哪部分内容又可以先忽略。我在网上随意一搜,要学习自然语言处理深度学习需要具备哪些知识。很快就会出来一系列的思维导图。微积分求导你得会吧,矩阵变换你得懂吧,概率计算要算算吧。然后python的各种语法得熟悉吧,每一个大知识点下面又可以细分很多个小知识点。然而这些都还只是准备工作,数据需要预处理,模型需要构建,这时又不得不去使用一些成熟的深度学习框架,后期还有参数调整。按照这个方式学习,肯定大部分人得被劝退了。虽然这些知识内容确确实实全部都正在被应用在所有深度学习的人工智能上,但我个人觉得,在我们对每一个细节进行挖掘之前,还是应该先在整体架构上有一个宏观的了解。
一.从模型谈起
这里还得先说明一下,深度学习呢是属于机械学习的一种,近几年深度学习算法大火,让人们渐渐不再提起一些曾经用的其他机械学习的算法。像什么随机森林,支持向量机,这些机械学习的算法,虽然现在看来有点落伍了,但他们确实也依旧在某些领域发光发热。虽然我这里还是以深度学习算法为基础进行讨论的。
1.模型的构建
我们老是说,构建模型,构建模型,到底是在构建什么?特别宏观的去看,我们就是在构建一个函数Y=f(x),在自然语言处理中,x往往是我们要输入文本,Y 则各种各样,在翻译任务中,Y是对应另一种语言的单词,在文档分类任务中,Y输出的是它对应的类别。而我们就是在构建一个函数,让Y与x能够产生正确的联系,只不过这个函数特别复杂,我们没法一步做完,所以把它拓展为了一个所谓的模型。接下来我们拆开来看。模型有哪些组成。
1.1.encoder-decoder结构
我们打电话,声音如何传到千里之外的人耳朵里的?是先将声波信号转化为电信号,电信号传播千里,又转成了声波信号传入对方耳朵,这就是一个很经典的编码-解码的结构。自然语言处理也一样,机械无法理解文本信息里到底是什么内容,所以我们需要给文本进行转换,文本里的每一个字都用向量进行表示,这里词向量的相关知识就需要用上了,首先我们会用最基础的one-hot词向量去表示各个文字,接着会涉及到一些矩阵变换,将one-hot词向量映射到更加高维的空间去,即给它进行降维。这个过程这里我们不细谈,先知道有这么回事就行了。总体来说,我们通过encoder结构将文字变成了带有某些特征的词向量,接着我们通过decoder又将词向量变回了我们需要的输出文字或信息。其实这样说还是比较模糊,也许会有许多疑问,比如词向量是起到了什么作用?它中间经历了怎样的变换?这些可以留着以后慢慢思考,毕竟现在还只是在讲模型的结构。
1.1.1.encoder可以是什么
encoder也是一个比较暧昧的概念外壳,就像如果你外穿红裤衩做了拯救人类的事,我就可以叫你超人。我假设你事先了解过了CNN,RNN,LSTM,BI-LSTM等等一系列网络结构。那么,一个单纯的bilstm的网络结构就可以作为一个encoder了,当然在实际的使用中,会有一些其他的叠加结构,但你只要明白了所谓的encoder是做了什么事,那么,做了这件事的就应该都可以称为encoder
1.1.2.以及decoder
同理,近几年有个bilstm-crf模型挺火的样子,就以它为例吧,这个模型构造如图所示,我们可以简单的对其进行划分,bilstm是encoder,它的作用是获取了一系列可以表现出上下文关系的向量,crf是decoder,它的作用是通过将前一层获得的向量,其实输出的还是向量,只不过它自己定了一个idx转换成char的列表,以实体标注为例,假设有4中实体类型,那么输出向量为【1,5】维度的向量每个数字代表了idx-char表中对应实体类型的概率。数字最大,概率最高,我们就判断输出的实体类型是这个最大的数字所对应的实体类型。由此转化为了输出信息。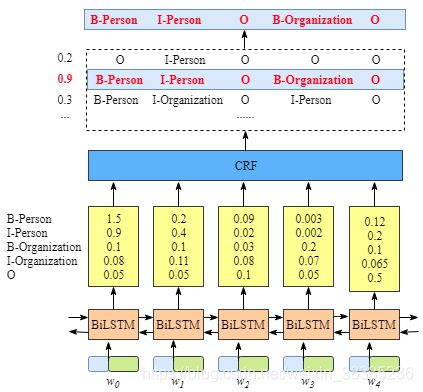
2.模型的运算过程
2.1.前向传播与反向传播
其实关于前向传播和反向传播,我这里不需要讲太多细节,我们需要知道反向传播是通过函数求导的方式计算损失值的(反向传播这里微积分用上了,计算损失值这里概率论用上了)。然后我们要明确我们反向传播更新的是什么?是模型各个层的参数。而不是数据。在学习模型的前向传播和反向传播的过程中,需要注意到神经元的区别,也就早就了那些rnn,lstm这些网络的根本的区别,它们分别适用于什么任务。然后可以思考什么时候用rnn网络好一些,什么时候用lstm网络好一些。
2.2.矩阵运算
模型中有成千上万个节点,每个节点都单独做运算,太慢,这个时候,我们就需要采用矩阵的方式进行计算了,(这里线性代数用上了)甚至是将全体相同位置的参数全体看做一个矩阵,采用自己的数学运算方式,加快计算速度,必要的时候,还可以让这个计算到GPU上进行。事实上还有许多细节,这里我们只需要知道的是神经网络参数的变更,是通过矩阵运算进行的。
二.接着是数据
要做实验需要的就是模型和数据,看了很多理论知识,还是不知道具体该怎么做,这个时候就体现了动手的重要性,网上公开的数据有很多。我们可以先将某个模型套用在自己的数据上,这个过程说的轻松,实际上也还是挺困难的,哪怕可以在github上找到别人的代码实现,也不一定能轻松的套用在自己的数据上。事实上,你对数据的处理很大程度上影响了模型的训练。
1.数据的存在形式
为什么么要提数据的存在形式,自然语言处理嘛,数据还不就是以文本形式存在啊,顶多也就是文件的后缀名不同而已。事实上也确实是这样没错,但我想讲的是最初的数据在输入模型的时候的存在形式,事实上,我们往往要把数据处理成一个字典(python里的数据结构的概念),内容主要包含了,原文信息,以及标签信息,有的会因为标注方式的原因,加入了一些其他的信息。通过标签的信息,模型能够知道我们预期输出是什么,然后训练阶段可以根据这个标签信息,进行反向传播损失值的计算。相信实际做实验的话,会体会到这些东西。
2.数据的处理手法
在我真正做实验之前,我看到了网上好多数据预处理的手法,英文数据需要去掉大写字母啊,词形还原啊,词干提取,停用词表啊。中文的数据还要进行分词等等,我一个个认真的看了过去,但后来我才发现,使用深度学习算法进行研究的话,相当多的预处理是不可以需要的,这些预处理方法是针对以前的一些机械学习算法来用的。深度学习算法事实上有时候应该是希望文本里包含一些看似无用的信息的。这也是我想在这提出来的原因,当我们看到一个概念时,网上可能会出现许多和它相关的其他概念,了解了解固然是好事,但它是否是我们所需要的知识,还得自己多做判断,避免陷入不必要的纠结。
三.总结
我从数据和模型两个方面宏观的讲了一些目前我眼中的自然语言处理要做的事的理解。事实上每个点单拉出来都可以写上好多好多的东西,从原理,到运算过程。事实上,我觉得我们在求学的初始阶段更应该抱着一种不求甚解的心态,当然这只是暂时的,想要学的好,最终它的原理必须清楚明白,不过这应该是一个漫长的过程,一上来就去弄明白太高深的东西,反而让知识框架越来越窄。我到现在也无法准确写出CRF的损失值的计算方式,但这并不妨碍我使用它。我经常碰到这种情况,学习了一个概念,或者一个算法,但我不知道如何使用它,或者说哪里能运用的上它。我想这就是我知识体系不完善的表现吧。今天你看完了我写的文章,也许依旧对自然语言处理不太了解。毕竟我写的特别粗略,但我主要想传递的思想就是。我们需要在脑海里重现整个过程,一项技术,一个算法的发明,解决了什么问题,还剩下什么问题,深度学习框架中的很多函数,算法都已经被封装好了,即使只是学会如何调用也够喝一壶的了。
四.今后的展望
这篇文章将作为我的起点,由于我现在也是在从事自然语言处理关系抽取方向的研究。我以后将会以关系抽取任务为中心,不管是描述自己遇到的坑也好,对关系抽取方面的论文进行精度也好。我会不定期更新自己的博客,希望你与我一同成长。对于我有什么意见或者建议,欢迎交流指正。